Recognition: unknown
SpaAct: Spatially-Activated Transition Learning with Curriculum Adaptation for Vision-Language Navigation
Pith reviewed 2026-05-07 04:57 UTC · model grok-4.3
The pith
Two auxiliary tasks on visual transitions let vision-language models navigate unseen 3D spaces more successfully.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
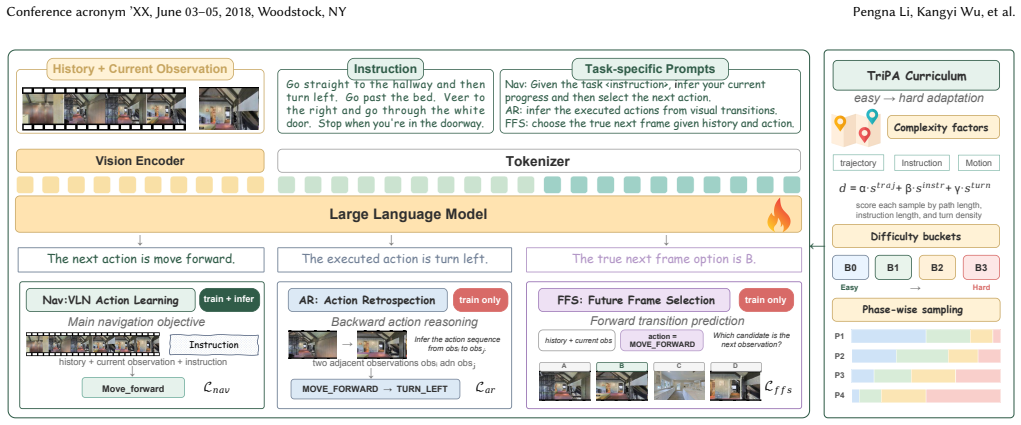
SpaAct activates dynamic spatial awareness in VLMs by training them on two complementary tasks: Action Retrospection, which requires inferring the executed action sequence from visual transitions, and Future Frame Selection, which requires predicting the next visual frame conditioned on history and action. These objectives are stabilized by TriPA, a tri-factor progressive adaptive curriculum that moves samples from easy basic locomotion to hard long-horizon reasoning. The resulting models achieve state-of-the-art performance on VLN-CE benchmarks.
What carries the argument
SpaAct framework consisting of the Action Retrospection and Future Frame Selection tasks together with the TriPA curriculum, which supplies lightweight supervision on backward and forward spatial transitions to build dynamic awareness in VLMs.
If this is right
- VLMs can be adapted to VLN using only lightweight transition supervision rather than full trajectory imitation.
- Progressive ordering of training samples from short to long horizons stabilizes adaptation and improves final navigation success.
- The same two tasks provide measurable gains across multiple VLM backbones on standard VLN-CE splits.
- Releasing code and models will allow direct replication and extension on other VLN-CE environments.
Where Pith is reading between the lines
- The same retrospection-plus-prediction pattern could be tested on other sequential embodied tasks such as instruction-guided manipulation.
- If the curriculum factors generalize, similar tri-factor ordering might speed adaptation of VLMs to long video or robotics datasets.
- The approach suggests that many VLM limitations in physical reasoning stem from missing transition modeling rather than from scale alone.
Load-bearing premise
That the two proposed spatial activation tasks plus the tri-factor curriculum are enough to give VLMs the dynamic spatial awareness needed for successful navigation in completely unseen environments.
What would settle it
An ablation study on the R2R-CE or RxR-CE test sets in which removing either Action Retrospection or Future Frame Selection leaves performance no better than a standard VLM fine-tuning baseline without the SpaAct tasks.
Figures



read the original abstract
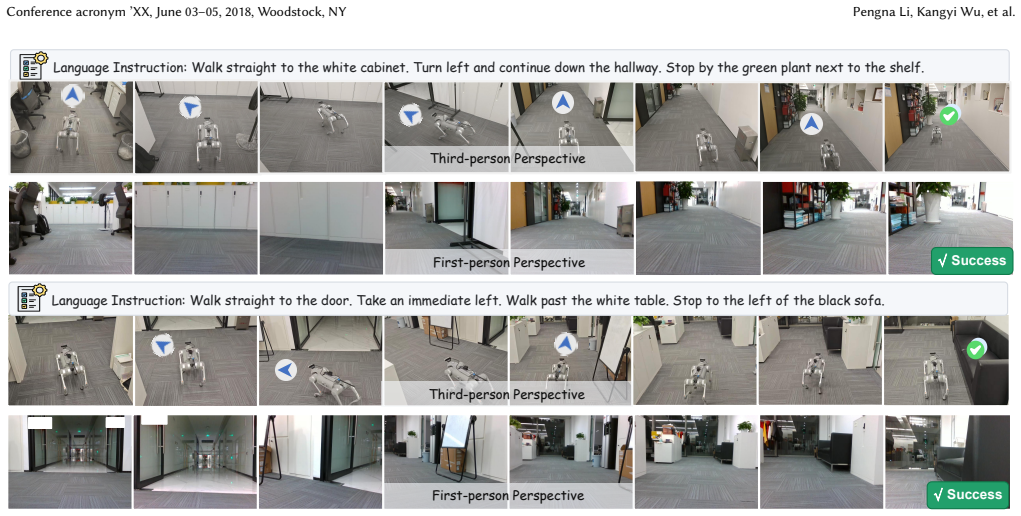
Vision-and-Language Navigation (VLN) aims to enable an embodied agent to follow natural-language instructions and navigate to a target location in unseen 3D environments. We argue that adapting VLMs to VLN requires endowing them with two complementary capabilities for acquiring such awareness, namely backward action reasoning (why) and forward transition prediction~(how). Based on this insight, we propose SpaAct, a simple yet effective training framework that activates the dynamic spatial awareness in VLMs. Specifically, SpaAct introduces two spatial activation tasks: Action Retrospection, which asks the model to infer the executed action sequence from visual transitions, and Future Frame Selection, which forces the model to predict the visual transitions conditioned on history and action. These two objectives provide lightweight supervision on both backward action reasoning and forward transition prediction, encouraging the model to build dynamic spatial awareness in a VLM-friendly way. To further stabilize adaptation, we design TriPA, a Tri-factor Progressive Adaptive curriculum learning method that organizes training samples from easy to hard, allowing the model to gradually acquire navigation skills from basic locomotion to long-horizon reasoning. Experiments on standard VLN-CE benchmarks show that SpaAct consistently improves VLM-based navigation and achieves state-of-the-art performance. We will release the code and models to support future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SpaAct, a training framework for adapting vision-language models (VLMs) to vision-and-language navigation (VLN) in unseen 3D environments. It introduces two spatial activation tasks—Action Retrospection (inferring executed action sequences from visual transitions) and Future Frame Selection (predicting future visual transitions conditioned on history and action)—to provide lightweight supervision for backward action reasoning and forward transition prediction. These are combined with TriPA, a tri-factor progressive adaptive curriculum that orders training samples from easy to hard. The central claim is that this combination endows VLMs with dynamic spatial awareness, yielding consistent improvements and state-of-the-art results on standard VLN-CE benchmarks.
Significance. If the reported gains hold and can be mechanistically attributed to the specific backward/forward spatial tasks rather than generic curriculum or optimization effects, the work would offer a practical, VLM-compatible route to improving generalization in embodied navigation. The complementary 'why' and 'how' supervision idea is conceptually sound and could influence subsequent adaptation strategies for large models in VLN and related embodied tasks.
major comments (3)
- [Abstract] Abstract: The assertion of achieving state-of-the-art performance on VLN-CE benchmarks is unsupported by any quantitative results, baseline comparisons, ablation tables, or error analysis. This omission makes it impossible to assess the magnitude of improvement or to verify whether the data support the central claim.
- [Experiments section] Experiments section: No ablation studies isolate the individual contributions of the Action Retrospection task and the Future Frame Selection task on the val-unseen split (as opposed to val-seen). Without such controls or comparisons to equivalent auxiliary losses, it remains unclear whether gains derive from the claimed dynamic spatial awareness or from curriculum-induced optimization benefits and longer effective training.
- [Method section] Method section: The training objectives for the two spatial activation tasks are described only at a conceptual level with no equations, loss formulations, or precise definitions of the supervision signals. This absence hinders assessment of novelty, reproducibility, and whether the objectives truly enforce the intended backward/forward reasoning.
minor comments (2)
- [Abstract] The abstract promises code and model release but provides no link or repository details; adding these would aid reproducibility.
- [Method section] The TriPA acronym is introduced without immediate expansion; spelling out 'Tri-factor Progressive Adaptive' on first use would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the clarity and evidential support in our manuscript. We address each major comment point by point below and will implement revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of achieving state-of-the-art performance on VLN-CE benchmarks is unsupported by any quantitative results, baseline comparisons, ablation tables, or error analysis. This omission makes it impossible to assess the magnitude of improvement or to verify whether the data support the central claim.
Authors: We acknowledge that the abstract's SOTA claim currently lacks direct quantitative backing within the manuscript's presented sections, which is a valid point that limits assessment of the improvements. In the revised version, we will expand the Experiments section with full quantitative results, baseline comparisons, ablation tables, and error analysis on VLN-CE benchmarks. We will also revise the abstract to include specific metrics (such as success rate and SPL gains on val-unseen) to make the claim self-supported. revision: yes
-
Referee: [Experiments section] Experiments section: No ablation studies isolate the individual contributions of the Action Retrospection task and the Future Frame Selection task on the val-unseen split (as opposed to val-seen). Without such controls or comparisons to equivalent auxiliary losses, it remains unclear whether gains derive from the claimed dynamic spatial awareness or from curriculum-induced optimization benefits and longer effective training.
Authors: We agree that more targeted ablations on the val-unseen split are necessary to isolate the effects of each task and rule out generic curriculum or optimization benefits. We will add new ablation experiments on val-unseen, including variants that disable Action Retrospection or Future Frame Selection individually, as well as comparisons against equivalent auxiliary losses (e.g., standard prediction objectives without spatial conditioning). These will be presented in updated tables to attribute gains specifically to the backward/forward reasoning. revision: yes
-
Referee: [Method section] Method section: The training objectives for the two spatial activation tasks are described only at a conceptual level with no equations, loss formulations, or precise definitions of the supervision signals. This absence hinders assessment of novelty, reproducibility, and whether the objectives truly enforce the intended backward/forward reasoning.
Authors: We recognize that the lack of formal equations and loss details hinders evaluation of the tasks' novelty and exact supervision. In the revised Method section, we will add precise mathematical formulations: the Action Retrospection objective as a cross-entropy loss over predicted action sequences from visual transition pairs, and the Future Frame Selection objective as a contrastive loss selecting the correct future frame from candidates conditioned on history and action. We will also explicitly define how supervision signals are extracted from navigation trajectories. revision: yes
Circularity Check
No circularity: empirical framework with auxiliary tasks validated on external benchmarks
full rationale
The paper defines SpaAct explicitly as a training framework consisting of two new auxiliary objectives (Action Retrospection for backward reasoning and Future Frame Selection for forward prediction) plus the TriPA curriculum. These components are introduced as design choices to endow VLMs with dynamic spatial awareness, and their effectiveness is measured solely by performance gains on standard external VLN-CE benchmarks (val-unseen splits). No equations, derivations, or first-principles results appear in the manuscript; there are no self-definitional loops where a claimed capability is defined in terms of the tasks themselves, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems that reduce the central claim to prior author work. The derivation chain is therefore self-contained: the method is a set of training interventions whose value is established by independent benchmark outcomes rather than by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models contain latent dynamic spatial awareness that can be activated by lightweight auxiliary supervision on action retrospection and transition prediction.
- domain assumption Organizing training samples from easy to hard via a tri-factor progressive curriculum improves stability and final performance for VLM adaptation to VLN.
invented entities (3)
-
Action Retrospection task
no independent evidence
-
Future Frame Selection task
no independent evidence
-
TriPA curriculum
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. 2024. Etpnav: Evolving topological planning for vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence(2024)
2024
- [3]
-
[4]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünder- hauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and- language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition. 3674–3683
2018
-
[5]
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. 2022. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19129–19139
2022
-
[6]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review arXiv 2023
-
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review arXiv 2025
-
[8]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review arXiv 2025
-
[9]
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. 2017. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158 (2017)
work page Pith review arXiv 2017
-
[10]
Jinyu Chen, Chen Gao, Erli Meng, Qiong Zhang, and Si Liu. 2022. Reinforced structured state-evolution for vision-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15450–15459
2022
-
[11]
Jiaqi Chen, Bingqian Lin, Xinmin Liu, Lin Ma, Xiaodan Liang, and Kwan-Yee K Wong. 2025. Affordances-oriented planning using foundation models for con- tinuous vision-language navigation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23568–23576
2025
-
[12]
Kehan Chen, Dong An, Yan Huang, Rongtao Xu, Yifei Su, Yonggen Ling, Ian Reid, and Liang Wang. 2025. Constraint-aware zero-shot vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025)
2025
-
[13]
Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. 2021. History aware multimodal transformer for vision-and-language navigation.Advances in neural information processing systems34 (2021), 5834–5847
2021
-
[14]
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. 2022. Think global, act local: Dual-scale graph transformer for vision- and-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16537–16547
2022
- [15]
-
[16]
Zedong Chu, Shichao Xie, Xiaolong Wu, Yanfen Shen, Minghua Luo, Zhengbo Wang, Fei Liu, Xiaoxu Leng, Junjun Hu, Mingyang Yin, Jia Lu, Yingnan Guo, Kai Yang, Jiawei Han, Xu Chen, Yanqing Zhu, Yuxiang Zhao, Xin Liu, Yirong Yang, Ye He, Jiahang Wang, Yang Cai, Tianlin Zhang, Li Gao, Liu Liu, Mingchao Sun, Fan Jiang, Chiyu Wang, Zhicheng Liu, Hongyu Pan, Hongl...
-
[17]
Daniel Fried, Ronghang Hu, Volkan Cirik, Anna Rohrbach, Jacob Andreas, Louis- Philippe Morency, Taylor Berg-Kirkpatrick, Kate Saenko, Dan Klein, and Trevor Darrell. 2018. Speaker-follower models for vision-and-language navigation. Advances in neural information processing systems31 (2018)
2018
-
[18]
Chen Gao, Xingyu Peng, Mi Yan, He Wang, Lirong Yang, Haibing Ren, Hongsheng Li, and Si Liu. 2023. Adaptive zone-aware hierarchical planner for vision-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14911–14920
2023
-
[19]
Georgios Georgakis, Karl Schmeckpeper, Karan Wanchoo, Soham Dan, Eleni Miltsakaki, Dan Roth, and Kostas Daniilidis. 2022. Cross-modal map learning for vision and language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15460–15470
2022
-
[20]
Jing Gu, Eliana Stefani, Qi Wu, Jesse Thomason, and Xin Wang. 2022. Vision- and-language navigation: A survey of tasks, methods, and future directions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7606–7623
2022
-
[21]
Pierre-Louis Guhur, Makarand Tapaswi, Shizhe Chen, Ivan Laptev, and Cordelia Schmid. 2021. Airbert: In-domain pretraining for vision-and-language navigation. InProceedings of the IEEE/CVF international conference on computer vision. 1634– 1643
2021
-
[22]
Yicong Hong, Cristian Rodriguez, Qi Wu, and Stephen Gould. 2020. Sub- instruction aware vision-and-language navigation. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 3360– 3376
2020
-
[23]
Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. 2022. Bridging the gap be- tween learning in discrete and continuous environments for vision-and-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15439–15449
2022
-
[24]
Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez-Opazo, and Stephen Gould
-
[25]
InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition
Vln bert: A recurrent vision-and-language bert for navigation. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 1643– 1653
-
[26]
Yicong Hong, Yang Zhou, Ruiyi Zhang, Franck Dernoncourt, Trung Bui, Stephen Gould, and Hao Tan. 2023. Learning navigational visual representations with semantic map supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision. 3055–3067
2023
- [27]
-
[28]
Muhammad Zubair Irshad, Niluthpol Chowdhury Mithun, Zachary Seymour, Han-Pang Chiu, Supun Samarasekera, and Rakesh Kumar. 2022. Semantically- aware spatio-temporal reasoning agent for vision-and-language navigation in continuous environments. In2022 26th International conference on pattern recog- nition (ICPR). IEEE, 4065–4071
2022
-
[29]
Jacob Krantz, Aaron Gokaslan, Dhruv Batra, Stefan Lee, and Oleksandr Maksymets. 2021. Waypoint models for instruction-guided navigation in contin- uous environments. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15162–15171
2021
-
[30]
Jacob Krantz and Stefan Lee. 2022. Sim-2-sim transfer for vision-and-language navigation in continuous environments. InEuropean conference on computer vision. Springer, 588–603
2022
-
[31]
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee
-
[32]
InEuropean Conference on Computer Vision
Beyond the nav-graph: Vision-and-language navigation in continuous environments. InEuropean Conference on Computer Vision. Springer, 104–120
- [33]
-
[34]
Jialu Li and Mohit Bansal. 2023. Improving vision-and-language navigation by generating future-view image semantics. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. 10803–10812
2023
-
[35]
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. 2026. Causal World Modeling for Robot Control. arXiv:2601.21998 [cs.CV] https://arxiv.org/ abs/2601.21998
work page internal anchor Pith review arXiv 2026
-
[36]
Pengna Li, Kangyi Wu, Jingwen Fu, and Sanping Zhou. 2025. REGNav: Room Expert Guided Image-Goal Navigation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 4860–4868
2025
-
[37]
Pengna Li, Kangyi Wu, Shaoqing Xu, Fang Li, Lin Zhao, Long Chen, Zhi-Xin Yang, and Nanning Zheng. 2026. Think before Go: Hierarchical Reasoning for Image-goal Navigation.arXiv preprint arXiv:2604.17407(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Zerui Li, Gengze Zhou, Haodong Hong, Yanyan Shao, Wenqi Lyu, Yanyuan Qiao, and Qi Wu. 2025. Ground-level viewpoint vision-and-language navigation in continuous environments. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 5266–5273
2025
-
[39]
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. 2024. Vila: On pre-training for visual language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 26689–26699
2024
-
[40]
Kunyang Lin, Peihao Chen, Diwei Huang, Thomas H Li, Mingkui Tan, and Chuang Gan. 2023. Learning vision-and-language navigation from youtube videos. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8317–8326
2023
- [41]
-
[42]
Haoran Liu, Weikang Wan, Xiqian Yu, Minghan Li, Jiazhao Zhang, Bo Zhao, Zhibo Chen, Zhongyuan Wang, Zhizheng Zhang, and He Wang. 2025. Na Vid-4D: SpaAct: Spatially-Activated Transition Learning with Curriculum Adaptation for Vision-Language Navigation Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Unleashing Spatial Intelligence in Egocentric RGB...
2025
- [43]
- [44]
-
[45]
Rui Liu, Xiaohan Wang, Wenguan Wang, and Yi Yang. 2023. Bird’s-eye-view scene graph for vision-language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 10968–10980
2023
- [46]
-
[47]
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. 2024. Deepseek-vl: towards real- world vision-language understanding.arXiv preprint arXiv:2403.05525(2024)
work page internal anchor Pith review arXiv 2024
-
[48]
Kailin Lyu, Kangyi Wu, Pengna Li, Xiuyu Hu, Qingyi Si, Cui Miao, Ning Yang, Zi- hang Wang, Long Xiao, Lianyu Hu, et al. 2026. HiMemVLN: Enhancing Reliability of Open-Source Zero-Shot Vision-and-Language Navigation with Hierarchical Memory System.arXiv preprint arXiv:2603.14807(2026)
- [49]
-
[50]
Chih-Yao Ma, Zuxuan Wu, Ghassan AlRegib, Caiming Xiong, and Zsolt Kira. 2019. The regretful agent: Heuristic-aided navigation through progress estimation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 6732–6740
2019
-
[51]
Steven D Morad, Roberto Mecca, Rudra PK Poudel, Stephan Liwicki, and Roberto Cipolla. 2021. Embodied visual navigation with automatic curriculum learning in real environments.IEEE Robotics and Automation Letters6, 2 (2021), 683–690
2021
-
[52]
Akhil Perincherry, Jacob Krantz, and Stefan Lee. 2025. Do visual imaginations improve vision-and-language navigation agents?. InProceedings of the Computer Vision and Pattern Recognition Conference. 3846–3855
2025
-
[53]
Zhangyang Qi, Zhixiong Zhang, Yizhou Yu, Jiaqi Wang, and Hengshuang Zhao
-
[54]
Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning. arXiv preprint arXiv:2506.17221(2025)
-
[55]
Yanyuan Qiao, Yuankai Qi, Yicong Hong, Zheng Yu, Peng Wang, and Qi Wu
-
[56]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hop: History-and-order aware pre-training for vision-and-language navi- gation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15418–15427
-
[57]
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, An- drew Westbury, Angel X Chang, et al. 2021. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238 (2021)
work page internal anchor Pith review arXiv 2021
-
[58]
Sonia Raychaudhuri, Saim Wani, Shivansh Patel, Unnat Jain, and Angel Chang
-
[59]
InProceedings of the 2021 conference on empirical methods in natural language processing
Language-aligned waypoint (law) supervision for vision-and-language navigation in continuous environments. InProceedings of the 2021 conference on empirical methods in natural language processing. 4018–4028
2021
-
[60]
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. 2011. A reduction of imi- tation learning and structured prediction to no-regret online learning. InPro- ceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 627–635
2011
-
[61]
Xinyu Sun, Peihao Chen, Jugang Fan, Jian Chen, Thomas Li, and Mingkui Tan
-
[62]
FGPrompt: fine-grained goal prompting for image-goal navigation.Ad- vances in Neural Information Processing Systems36 (2024)
2024
-
[63]
Hanqing Wang, Wei Liang, Luc Van Gool, and Wenguan Wang. 2023. Dreamwalker: Mental planning for continuous vision-language navigation. In Proceedings of the IEEE/CVF international conference on computer vision. 10873– 10883
2023
-
[64]
Shuo Wang, Yucheng Wang, Guoxin Lian, Yongcai Wang, Maiyue Chen, Kaihui Wang, Bo Zhang, Zhizhong Su, Yutian Zhou, Wanting Li, et al. 2025. Progress- Think: Semantic Progress Reasoning for Vision-Language Navigation.arXiv preprint arXiv:2511.17097(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Zihan Wang and Gim Hee Lee. 2025. g3d-lf: Generalizable 3d-language feature fields for embodied tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14191–14202
2025
-
[66]
Zun Wang, Jialu Li, Yicong Hong, Yi Wang, Qi Wu, Mohit Bansal, Stephen Gould, Hao Tan, and Yu Qiao. 2023. Scaling data generation in vision-and-language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 12009–12020
2023
-
[67]
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. 2023. Gridmm: Grid memory map for vision-and-language navigation. InProceedings of the IEEE/CVF International conference on computer vision. 15625–15636
2023
- [68]
-
[69]
Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqiang Yang, Delin Feng, Wenzhe Cai, Chenming Zhu, Tai Wang, Jiangmiao Pang, et al . 2025. Ground slow, move fast: A dual-system foundation model for generalizable vision-and- language navigation.arXiv preprint arXiv:2512.08186(2025)
- [70]
-
[71]
Kangyi Wu, Pengna Li, Kailin Lyu, Lin Zhao, Qingrong He, Jinjun Wang, and Jianyi Liu. 2026. Dual-Anchoring: Addressing State Drift in Vision-Language Navigation.arXiv preprint arXiv:2604.17473(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [72]
-
[73]
Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha
-
[74]
In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 5543–5550
-
[75]
Lu Yue, Yue Fan, Shiwei Lian, Yu Zhao, Jiaxin Yu, Liang Xie, and Feitian Zhang
- [76]
- [77]
- [78]
-
[79]
Jiwen Zhang, Jianqing Fan, Jiajie Peng, et al. 2021. Curriculum learning for vision- and-language navigation.Advances in Neural Information Processing Systems34 (2021), 13328–13339
2021
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.