Recognition: unknown
Waking Up Blind: Cold-Start Optimization of Supervision-Free Agentic Trajectories for Grounded Visual Perception
Pith reviewed 2026-05-10 05:29 UTC · model grok-4.3
The pith
SPECTRA lets small vision-language models learn grounded agentic trajectories from environment interaction alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
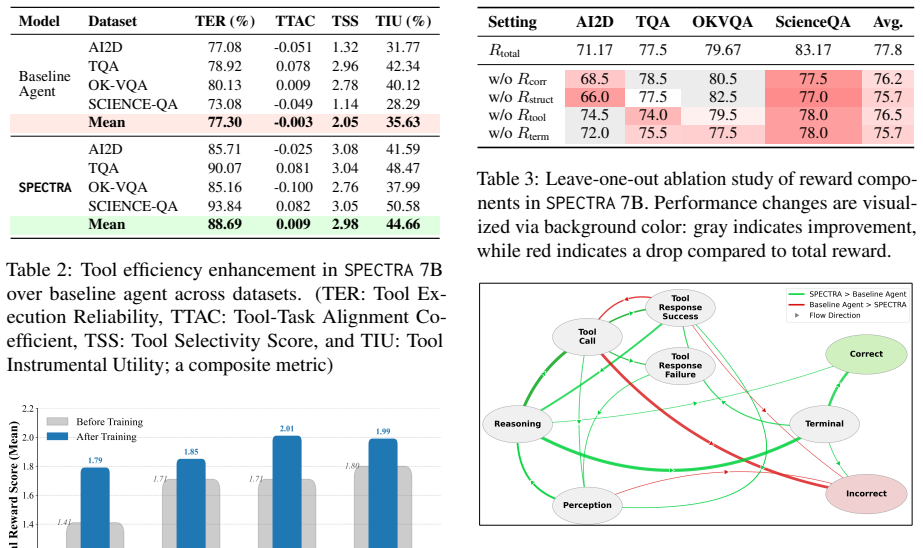
SPECTRA bootstraps agentic capabilities in SVLMs via Coldstart Reinforcement Learning by enforcing Soft Structured Multi-turn Rollouts that direct agents to sequence tool-derived evidence before synthesis. A multi-objective reward signal simultaneously maximizes task correctness, rollout structure, and tool utility, enabling the agent to self-discover robust behaviors without human preference labels. The framework further introduces Tool Instrumental Utility to quantify tool efficacy absent ground truth, yielding up to 5% higher task accuracy and 9% better tool efficiency across composite and MMMU-Pro benchmarks.
What carries the argument
Soft Structured Multi-turn Rollouts, a topological constraint that requires agents to explicitly sequence tool-derived visual evidence before any final synthesis or answer generation.
If this is right
- SVLMs can improve visual grounding and tool orchestration purely through environmental interaction.
- Expensive supervised trajectory tuning becomes unnecessary for achieving measurable gains in agentic performance.
- Structured rollout constraints produce more reliable sequencing of evidence before reasoning.
- Tool efficacy can be measured and optimized even when ground-truth answers are unavailable.
Where Pith is reading between the lines
- The same cold-start structure could reduce dependence on human feedback when training agents in non-visual domains.
- Topological constraints on reasoning steps may substitute for some forms of preference data in other multimodal settings.
- Combining SPECTRA with very small amounts of supervision could be tested to see if further gains appear.
Load-bearing premise
The multi-objective reward signal and soft structured rollout constraint suffice for the model to discover effective grounded behaviors without external labels or supervision.
What would settle it
Train an SVLM with SPECTRA and compare it head-to-head against the identical base model on the same visual tasks; if accuracy and tool efficiency show no gain or a decline, the central claim fails.
Figures












read the original abstract
Small Vision-Language Models (SVLMs) are efficient task controllers but often suffer from visual brittleness and poor tool orchestration. They typically require expensive supervised trajectory tuning to mitigate these deficits. In this work, we propose Self-supervised Perception Enabled by Cascaded Tool Rollout Alignment (SPECTRA), a supervision-free framework that bootstraps agentic capabilities via Coldstart Reinforcement Learning for SVLMs. SPECTRA enforces Soft Structured Multi-turn Rollouts, a topological constraint that directs agents to explicitly sequence tool derived evidence before synthesis, effectively grounding reasoning in visual observations. We employ a multi-objective reward signal that simultaneously maximizes task correctness, rollout structure, and tool utility, enabling agent to self-discover robust behaviors without human preference labels. We further introduce Tool Instrumental Utility (TIU), a novel metric to quantify tool efficacy in the absence of ground truth. Extensive evaluations across composite and out-of-distribution (MMMU-Pro) benchmarks demonstrate that SPECTRA boosts agentic trajectories, improving task accuracy by up to 5% and tool efficiency by 9%, enabling more efficient multimodal agents that learn effectively from environmental interaction alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPECTRA (Self-supervised Perception Enabled by Cascaded Tool Rollout Alignment), a supervision-free cold-start reinforcement learning framework for improving agentic capabilities in Small Vision-Language Models (SVLMs). It introduces Soft Structured Multi-turn Rollouts as a topological constraint to enforce sequencing of tool-derived evidence before synthesis, a multi-objective reward combining task correctness, rollout structure, and tool utility, and the Tool Instrumental Utility (TIU) metric to quantify tool efficacy without ground truth. Evaluations on composite benchmarks and out-of-distribution MMMU-Pro data report gains of up to 5% in task accuracy and 9% in tool efficiency.
Significance. If the central claims hold after verification, the work would be moderately significant for the field of multimodal agentic systems. It addresses visual brittleness and tool orchestration in efficient SVLMs without relying on expensive supervised trajectory data, potentially enabling more scalable self-supervised learning from environmental interaction. The TIU metric and structured rollout topology are presented as novel, but their impact depends on demonstrating they are not reducible to reward engineering. The reported gains are modest, so broader adoption would require strong ablations and reproducibility evidence.
major comments (3)
- [Abstract] Abstract: The specific claims of 'up to 5% task accuracy' and '9% tool efficiency' improvements are load-bearing for the central contribution but provide no details on baselines, statistical tests, number of runs, or variance. Without this, it is impossible to assess whether the gains exceed noise or are attributable to SPECTRA rather than implementation choices.
- [Abstract] Abstract and reward formulation (assumed §3): The multi-objective reward is described as maximizing 'task correctness, rollout structure, and tool utility' with no explicit equations or weight values provided. Since weights in the multi-objective signal are free parameters, the claim that agents 'self-discover robust behaviors without human preference labels' risks circularity; the structure and utility terms may be tuned to produce the reported outcomes.
- [Abstract] Abstract: TIU is introduced as a novel metric to 'quantify tool efficacy in the absence of ground truth,' yet no definition, correlation analysis with actual task performance, or validation against held-out ground truth is referenced. This is central to the supervision-free claim and requires explicit formulation and empirical checks.
minor comments (2)
- [Title] The title 'Waking Up Blind' does not appear to match the abstract content focused on SPECTRA; clarify or align the title with the proposed framework.
- [Abstract] The abstract mentions 'composite and out-of-distribution (MMMU-Pro) benchmarks' but does not list the specific composite benchmarks or dataset sizes; add these for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the valuable feedback on our manuscript. We address each of the major comments below and will incorporate revisions to enhance the clarity and rigor of the abstract and method descriptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The specific claims of 'up to 5% task accuracy' and '9% tool efficiency' improvements are load-bearing for the central contribution but provide no details on baselines, statistical tests, number of runs, or variance. Without this, it is impossible to assess whether the gains exceed noise or are attributable to SPECTRA rather than implementation choices.
Authors: We agree that the abstract would benefit from more context on the evaluation. The full manuscript details the baselines (including vanilla SVLM, standard RL without structured rollouts, and supervised methods), reports results over multiple runs with variance, and includes statistical tests in Section 4 and the associated tables. To address this directly in the abstract, we will revise it to note that the reported improvements are 'statistically significant across multiple runs with variance accounted for, as detailed in Section 4.' revision: yes
-
Referee: [Abstract] Abstract and reward formulation (assumed §3): The multi-objective reward is described as maximizing 'task correctness, rollout structure, and tool utility' with no explicit equations or weight values provided. Since weights in the multi-objective signal are free parameters, the claim that agents 'self-discover robust behaviors without human preference labels' risks circularity; the structure and utility terms may be tuned to produce the reported outcomes.
Authors: The explicit formulation of the multi-objective reward, including the equations for each term and the fixed weight values, is provided in Section 3 of the manuscript. The weights are predetermined and fixed across experiments to avoid task-specific tuning, allowing the agent to discover behaviors through the environmental interaction signal. We will revise the manuscript to include the reward equation prominently in the abstract or introduction for better accessibility and to explicitly state that weights are not optimized on the reported benchmarks. revision: yes
-
Referee: [Abstract] Abstract: TIU is introduced as a novel metric to 'quantify tool efficacy in the absence of ground truth,' yet no definition, correlation analysis with actual task performance, or validation against held-out ground truth is referenced. This is central to the supervision-free claim and requires explicit formulation and empirical checks.
Authors: The Tool Instrumental Utility (TIU) metric is formally defined in Section 3.3, with supporting correlation analysis to task performance and validation on held-out ground truth data presented in Section 4 and the appendix. This demonstrates its reliability as a supervision-free proxy. We will update the abstract to include a concise definition of TIU and a reference to the empirical validation results to strengthen the presentation of this contribution. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract describes SPECTRA as a supervision-free framework using a multi-objective reward and topological constraints for self-discovery of behaviors. However, no equations, specific reward formulations, rollout definitions, or derivation steps are provided in the accessible text. Without quoted paper content exhibiting reductions (e.g., a fitted parameter renamed as prediction or self-citation load-bearing the central claim), no circular steps can be identified per the strict criteria. The framework is presented as self-contained against benchmarks like MMMU-Pro, with claims of 5% accuracy and 9% efficiency gains treated as empirical outcomes rather than definitional.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights in multi-objective reward signal
axioms (2)
- domain assumption Reinforcement learning from environmental interaction alone can bootstrap robust agentic behaviors in SVLMs
- ad hoc to paper Topological constraints on multi-turn rollouts enforce grounding of reasoning in visual observations
invented entities (2)
-
Tool Instrumental Utility (TIU)
no independent evidence
-
SPECTRA framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On grpo collapse in search-r1: The lazy likelihood-displacement death spiral.Preprint, arXiv:2512.04220. Yu Du, Fangyun Wei, and Hongyang Zhang. 2024. Any- tool: Self-reflective, hierarchical agents for large- scale api calls.Preprint, arXiv:2402.04253. Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. 2024. Videoagent: A memory-a...
-
[2]
A Diagram Is Worth A Dozen Images
A diagram is worth a dozen images.Preprint, arXiv:1603.07396. Daesik Kim, Seonhoon Kim, and Nojun Kwak. 2019. Textbook question answering with multi-modal con- text graph understanding and self-supervised open- set comprehension.Preprint, arXiv:1811.00232. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, ...
work page Pith review arXiv 2019
-
[3]
Llava-plus: Learning to use tools for creating multimodal agents.Preprint, arXiv:2311.05437. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Ao- han Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, and 3 oth- ers. 2025. Agentbench: Eva...
-
[4]
GAIA: a benchmark for General AI Assistants
Gaia: a benchmark for general ai assistants. Preprint, arXiv:2311.12983. Microsoft, :, Abdelrahman Abouelenin, Atabak Ash- faq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, Dong Chen, Dong- dong Chen, Junkun Chen, Weizhu Chen, Yen-Chun Chen, Yi ling Chen, Qi Dai, and 57 others. 2025. P...
work page internal anchor Pith review arXiv 2025
-
[5]
Is reinforcement learning (not) for natural lan- guage processing: Benchmarks, baselines, and build- ing blocks for natural language policy optimization. Preprint, arXiv:2210.01241. Aymeric Roucher, Albert Villanova del Moral, Thomas Wolf, Leandro von Werra, and Erik Kaunismäki
-
[6]
Proximal Policy Optimization Algorithms
‘smolagents‘: a smol library to build great agentic systems. https://github.com/ huggingface/smolagents. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Prox- imal policy optimization algorithms.Preprint, arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
MMInA: Benchmarking multihop multi- modal internet agents
Mmina: Benchmarking multihop multimodal internet agents.Preprint, arXiv:2404.09992. Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multimodal llms. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9568–9578. Harsh Trivedi, Tushar Kho...
-
[8]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents,
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. Preprint, arXiv:2407.18901. Chenyu Wang, Weixin Luo, Sixun Dong, Xiaohua Xuan, Zhengxin Li, Lin Ma, and Shenghua Gao. 2025. Mllm-tool: A multimodal large language model for tool agent learning.Preprint, arXiv:2401.10727. Jize Wang, Ma Zerun, Yining Li, Songyang Z...
-
[9]
Contains T h e d i a g r a m s h o w s t h e M o o n o r b i t i n g E a r t h a s v i e w e d f r o m S p a c e a b o v e t h e N o r t h P o l e
dataset contains grade school level text- book style scientific diagrams paired with mul- tiple choice questions that evaluate diagram understanding and visual reasoning. Contains T h e d i a g r a m s h o w s t h e M o o n o r b i t i n g E a r t h a s v i e w e d f r o m S p a c e a b o v e t h e N o r t h P o l e . A t w h i c h t w o p o s i t i o n s...
2019
-
[10]
</think_reasoning> tags about the question and which tool to call if needed
Start by thinking inside <think_reasoning>... </think_reasoning> tags about the question and which tool to call if needed
-
[11]
name": <function-name>,
Then you can call tool or tools fromAvailable_tools. Tool call instructions: For each function call, return a json object with function name and arguments within <tool_call></tool_call>XML tags: <tool_call>{"name": <function-name>, "arguments": <args-json-object>} </tool_call> end of response. List of Available_tools: captioning_tool, ocr_tool, detection_...
-
[12]
After you have used the tools, you will see the tool outputs inside appropriate tags in the same order from the system
-
[13]
</think_perception>tags once
After getting tool_response, think Your thoughts on thetool_response inside <think_perception>... </think_perception>tags once. (think_perceptionstep only comes aftertool_responsetags)
-
[14]
</think_reasoning> tags again
Then resume your thought process inside<think_reasoning>... </think_reasoning> tags again. Try to think clearly, aloud and step-by-step so that you reach to the correct final answer. If needed also reflect on your thought process. All thinking must be inside<think_reasoning>... </think_reasoning>tags
-
[15]
type": "function
At the end you must always choose the most appropriate option and put answer inside: <answer>\boxed{(option)answer} </answer> tags, irrespective of the output of the tool being true or false or incorrect. You MUST provide an answer even if uncertain at the end. Figure 9: The structured rollout prompt for training and inference used inSPECTRA. You are prov...
2048
-
[16]
name": "None
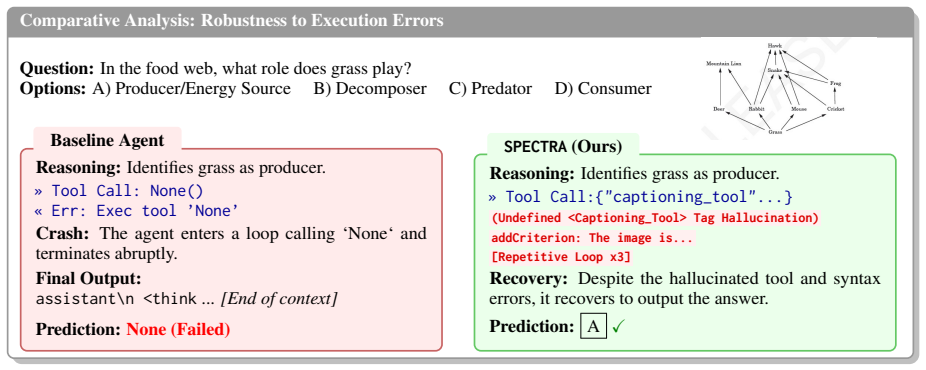
Grass is at the bottom of the food web, meaning it is the starting point for energy flow. 2. Arrows point from grass to other organisms, indicating that these organisms consume grass. 3. The organisms that consume grass are rabbits and mice, which are labeled as consumers in the food web. Given this information, grass plays the role of a producer in the f...
-
[17]
name": "perception_tool
**Identify the direct relationship with Plantain**: The Plantain is directly consumed by the mouse. Therefore, if the Plantain population is wiped out, the mouse population will be directly affected. 2. **Evaluate the impact on other populations**: - The grasshopper population is not directly connected to Plantain, so it will not be directly affected. - T...
-
[18]
F". Therefore, the correct answer should be associated with the label
The image shows a diagram of the human respiratory system, with the lungs labeled. 2. The left lung is typically positioned on the left side of the chest cavity. 3. In the diagram, the left lung is labeled with the letter ’D’. 4. The right lung is on the right side of the chest cavity and is labeled with the letter ’F’. Given this information, the label ’...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.