Recognition: unknown
CoSearch: Joint Training of Reasoning and Document Ranking via Reinforcement Learning for Agentic Search
Pith reviewed 2026-05-10 05:11 UTC · model grok-4.3
The pith
Joint reinforcement learning trains both the reasoning agent and document ranker together, overcoming the fixed-retrieval bottleneck in agentic search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
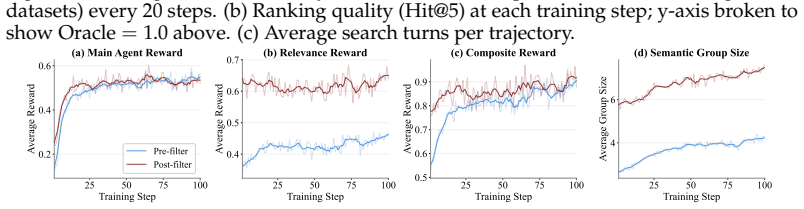
CoSearch jointly trains a reasoning agent and a generative document ranking model via Group Relative Policy Optimization, using a semantic grouping strategy that clusters sub-queries by token-level similarity to form valid optimization groups despite varying inputs across reasoning trajectories, together with a composite reward that supplies both ranking quality and trajectory-level outcome signals, producing consistent improvements over fixed-retrieval baselines on seven QA benchmarks.
What carries the argument
Semantic grouping strategy that clusters sub-queries by token-level similarity to create valid optimization groups for GRPO training of the ranker whose inputs vary with each reasoning trajectory.
Load-bearing premise
Clustering sub-queries by token-level similarity produces valid, unbiased optimization groups for GRPO without introducing selection artifacts that distort the ranker's learning signal.
What would settle it
A controlled run in which random instead of token-similarity clustering is used for grouping, after which the joint-training gains over fixed-retrieval baselines disappear or reverse.
Figures


read the original abstract
Agentic search -- the task of training agents that iteratively reason, issue queries, and synthesize retrieved information to answer complex questions -- has achieved remarkable progress through reinforcement learning (RL). However, existing approaches such as Search-R1, treat the retrieval system as a fixed tool, optimizing only the reasoning agent while the retrieval component remains unchanged. A preliminary experiment reveals that the gap between an oracle and a fixed retrieval system reaches up to +26.8% relative F1 improvement across seven QA benchmarks, suggesting that the retrieval system is a key bottleneck in scaling agentic search performance. Motivated by this finding, we propose CoSearch, a framework that jointly trains a multi-step reasoning agent and a generative document ranking model via Group Relative Policy Optimization (GRPO). To enable effective GRPO training for the ranker -- whose inputs vary across reasoning trajectories -- we introduce a semantic grouping strategy that clusters sub-queries by token-level similarity, forming valid optimization groups without additional rollouts. We further design a composite reward combining ranking quality signals with trajectory-level outcome feedback, providing the ranker with both immediate and long-term learning signals. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate consistent improvements over strong baselines, with ablation studies validating each design choice. Our results show that joint training of the reasoning agent and retrieval system is both feasible and strongly performant, pointing to a key ingredient for future search agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoSearch, a framework for jointly training a multi-step reasoning agent and a generative document ranking model in agentic search using Group Relative Policy Optimization (GRPO). It identifies fixed retrieval as a bottleneck (oracle gap up to +26.8% F1), introduces token-level similarity clustering to form GRPO groups for the ranker without extra rollouts, and a composite reward blending ranking signals with trajectory outcomes. Experiments on seven QA benchmarks report consistent gains over baselines, with ablations supporting the design choices.
Significance. If the empirical results prove robust, this work would be significant for agentic search by demonstrating that joint RL optimization of reasoning and retrieval is feasible and yields performance gains, addressing a clear scaling bottleneck. It provides credit for the empirical focus on ablations and the practical grouping strategy to enable GRPO on variable inputs.
major comments (3)
- [§4.2] §4.2 (semantic grouping strategy): The token-level similarity clustering for forming GRPO optimization groups on the ranker is load-bearing for the joint-training claim, yet the manuscript provides no analysis showing that token-similar sub-queries from distinct trajectories have comparable retrieval difficulty, context length, or reward contribution. If groups mix incomparable items, relative advantages in GRPO can bias the ranker's policy gradient toward spurious correlations rather than true ranking quality, as the composite reward does not automatically correct for grouping-induced variance.
- [§5] §5 (experiments and ablations): The abstract and results claim consistent improvements and validate each design choice, but the manuscript supplies no numerical tables with absolute scores, error bars, dataset sizes, or statistical significance tests across the seven benchmarks. This makes it impossible to assess whether the reported gains over strong baselines (e.g., Search-R1) are robust or sensitive to the grouping artifacts.
- [§3.3] §3.3 (composite reward): The design combines immediate ranking quality signals with long-term trajectory feedback, but no ablation isolates whether the ranking component receives a sufficiently clean learning signal when GRPO groups are formed solely by token similarity; the paper must demonstrate that downstream outcome rewards do not mask or amplify selection biases in the ranker updates.
minor comments (2)
- [Abstract] The abstract states a +26.8% relative F1 gap but does not specify the exact benchmarks or oracle setup; this detail should be moved to the main text with a reference to the preliminary experiment section.
- [§4.2] Notation for the generative ranker inputs (varying across trajectories) is introduced without a clear equation or diagram showing how clustering is applied before GRPO; a small illustrative figure would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate revisions to strengthen the empirical support and clarity of the joint-training claims.
read point-by-point responses
-
Referee: [§4.2] §4.2 (semantic grouping strategy): The token-level similarity clustering for forming GRPO optimization groups on the ranker is load-bearing for the joint-training claim, yet the manuscript provides no analysis showing that token-similar sub-queries from distinct trajectories have comparable retrieval difficulty, context length, or reward contribution. If groups mix incomparable items, relative advantages in GRPO can bias the ranker's policy gradient toward spurious correlations rather than true ranking quality, as the composite reward does not automatically correct for grouping-induced variance.
Authors: We agree that the semantic grouping strategy is central to the joint-training approach and that homogeneity of groups is important to avoid biasing the GRPO updates. The current manuscript motivates the token-level similarity clustering by its ability to form groups without extra rollouts and by empirical performance gains, but does not include explicit analysis of intra-group variance in retrieval difficulty or reward. In the revised manuscript we will add this analysis: we will report the variance of oracle F1 scores and composite reward values within versus across groups on a held-out set of sub-queries, together with context-length statistics, to demonstrate that token-similar groups are sufficiently comparable for relative advantage estimation. revision: yes
-
Referee: [§5] §5 (experiments and ablations): The abstract and results claim consistent improvements and validate each design choice, but the manuscript supplies no numerical tables with absolute scores, error bars, dataset sizes, or statistical significance tests across the seven benchmarks. This makes it impossible to assess whether the reported gains over strong baselines (e.g., Search-R1) are robust or sensitive to the grouping artifacts.
Authors: We acknowledge that the current presentation emphasizes relative gains and qualitative ablation trends rather than full numerical tables. This limits the ability to judge absolute performance and statistical robustness. In the revision we will expand §5 and the appendix with complete tables containing absolute F1 scores (mean ± standard deviation over three random seeds), dataset sizes, and two-sided t-test p-values against the Search-R1 baseline and other ablations. We will also add a short discussion of sensitivity to grouping hyperparameters. revision: yes
-
Referee: [§3.3] §3.3 (composite reward): The design combines immediate ranking quality signals with long-term trajectory feedback, but no ablation isolates whether the ranking component receives a sufficiently clean learning signal when GRPO groups are formed solely by token similarity; the paper must demonstrate that downstream outcome rewards do not mask or amplify selection biases in the ranker updates.
Authors: The composite reward is designed to supply both immediate ranking signals and trajectory-level feedback. We agree that an explicit ablation isolating the ranking component's learning signal under the token-similarity grouping is missing. In the revised manuscript we will add an ablation that trains the ranker with (i) only the ranking-quality term and (ii) the full composite reward while keeping the grouping strategy fixed. We will report the ranker's standalone ranking metrics (NDCG@10) and the magnitude of policy-gradient updates to show whether downstream trajectory rewards introduce measurable bias relative to the pure ranking signal. revision: yes
Circularity Check
No circularity: empirical RL framework validated on external benchmarks
full rationale
The paper presents an empirical method for joint RL training of a reasoning agent and generative ranker. It introduces a token-similarity clustering heuristic for GRPO groups and a composite reward, then reports performance gains on seven QA benchmarks with ablations. No derivation, equation, or claim reduces by construction to a fitted parameter or self-citation; all load-bearing steps are externally falsifiable via benchmark comparisons and do not rely on internal redefinition of the target metric.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://aclanthology.org/2020.coling-main.580/. 10 Preprint. Under review. Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. InThe Second Conference on Language Modeling (COLM), 2025. Mandar Joshi, Eunsol Cho...
-
[2]
Language Model Cascades: Token-Level Uncertainty and Beyond
Curran Associates Inc. ISBN 9781713829546. URL https://proceedings.neurips. cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html. Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models.CoRR, abs/2501.05366, 2025a. doi: 10.48550/ARXIV ...
work page internal anchor Pith review doi:10.48550/arxiv 2020
-
[3]
URLhttps://arxiv.org/abs/2212.03533. Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Monica Lam, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Fei-Fei Li, Lijuan Wang, Yejin Choi, and Manling Li. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement lea...
-
[5]
name": "search
EITHER: (A) <tool_call> ... </tool_call> OR (B) <answer> ... </answer> No other text is allowed outside these tags. Do NOT output <tool_response>. The environment will provide tool results separately. Allowed patterns: - <reason> ... </reason> <tool_call> ... </tool_call> - <reason> ... </reason> <answer> ... </answer> If you violate the format, your outp...
1997
-
[6]
</reason>
<reason> ... </reason>
-
[7]
</rerank> No other text is allowed outside these tags
<rerank> ... </rerank> No other text is allowed outside these tags. 16 Preprint. Under review. ============================================================ REASON BLOCK ============================================================ Inside <reason>, analyze the relevance of each candidate document. Consider whether the document provides factual evidence that...
1911
-
[8]
Bailey Island Library Hall
"Bailey Island Library Hall" Bailey Island Library Hall (locally just Library Hall) is a historic community building at 2167 Harpswell Island Road
-
[9]
Bumpkin Island
"Bumpkin Island" Bumpkin Island, also known as Round Island, Bomkin Island, Bumkin Island, or Ward's Island, is an island in the Hingham Bay area of the Bosto
-
[10]
Chocorua Island Chapel
"Chocorua Island Chapel" Although the camp had fallen into disrepair by that date, the chapel continued to provide worship services for visitors and area residents. Ev
-
[11]
Gooden Grant House
"Gooden Grant House" octagonal tower with turreted roof projects at the southwest corner, and a partially-enclosed single-story porch wraps around the west and south sides
-
[12]
Cherry Grove Community House and Theatre
"Cherry Grove Community House and Theatre" almost 400 other such sites have been identified as candidates. Cherry Grove Community House and Theatre The Cherry Grove Communit... ... [45 more candidates not shown] Output: <reason> The Initial Query asks for a town with an island that has a community building built in 1911-12. Passage [1] directly mentions a...
1911
-
[13]
New York (1916 film)
"New York (1916 film)" New York (1916 film) New York is a lost 1916 American silent comedy drama film directed by George Fitzmaurice and starring Florence Reed
1916
-
[14]
New York (1916 film)
"New York (1916 film)" thus Oliver King becomes a benedict, and Reel 3 contains two views of a nude model. New York is a lost 1916 American silent comedy drama film
1916
-
[15]
Lights of New York (1916 film)
"Lights of New York (1916 film)" Lights of New York is a 1916 American silent drama film directed by Van Dyke Brooke. Produced by the Vitagrap
1916
-
[16]
Lights of New York (1916 film)
"Lights of New York (1916 film)" with him anyway. Lights of New York (1916 film) Lights of New York is a 1916 American silent drama film directed by Van Dyke Brooke
1916
-
[17]
The Pride of New York
"The Pride of New York" German officer and nurse in room where bed is shown including taking nurse to room and excluding other young woman... ... [45 more candidates not shown] Output: <reason> The Initial Query asks whether Naked Obsession and New York (1916 Film) are from the same country. The Sub-Query targets New York (1916 Film). Passages [1] and [2]...
1916
-
[18]
Passage [5] discusses yet another unrelated film and ranks lowest
and [4] describe a different 1916 film (Lights of New York) that is also American but less directly relevant. Passage [5] discusses yet another unrelated film and ranks lowest. </reason> <rerank>[1] > [2] > [3] > [4] > [5]</rerank> B Two-Stage Retrieval System At each retrieval step t, the two-stage retrieval system takes the original query q0, the sub-qu...
1916
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.