Recognition: unknown
SafeAgent: A Runtime Protection Architecture for Agentic Systems
Pith reviewed 2026-05-10 06:03 UTC · model grok-4.3
The pith
SafeAgent protects LLM agents from propagating prompt-injection attacks by separating runtime execution governance from context-aware risk reasoning over persistent session state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
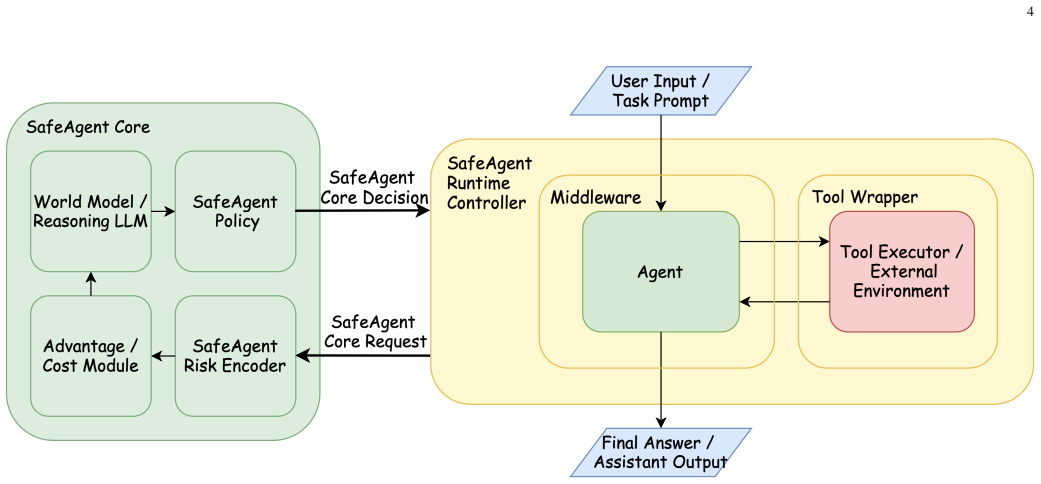
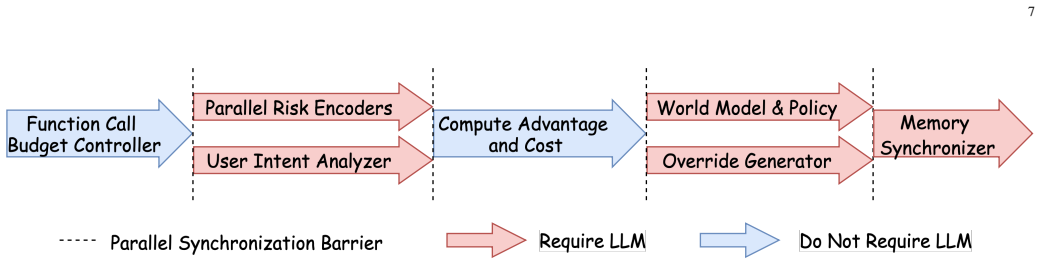
SafeAgent treats agent safety as a stateful decision problem over evolving interaction trajectories. It separates execution governance from semantic risk reasoning by coordinating a runtime controller that mediates actions around the agent loop with a context-aware decision core instantiated through operators for risk encoding, utility-cost evaluation, consequence modeling, policy arbitration, and state synchronization. This design enables detection and mitigation of attacks that propagate across tool interactions and persistent context.
What carries the argument
The runtime controller that mediates actions around the agent loop together with the context-aware decision core that operates over persistent session state using operators for risk encoding, utility-cost evaluation, consequence modeling, policy arbitration, and state synchronization.
Load-bearing premise
The separation of execution governance from semantic risk reasoning via a runtime controller and context-aware decision core will reliably detect and mitigate propagating prompt-injection attacks in multi-step workflows without excessive false positives or performance loss.
What would settle it
A specific multi-step task on Agent Security Bench in which a prompt-injection attack propagates and causes the agent to execute a harmful tool call despite mediation by the runtime controller and decisions from the context-aware core.
Figures


read the original abstract
Large language model (LLM) agents are vulnerable to prompt-injection attacks that propagate through multi-step workflows, tool interactions, and persistent context, making input-output filtering alone insufficient for reliable protection. This paper presents SafeAgent, a runtime security architecture that treats agent safety as a stateful decision problem over evolving interaction trajectories. The proposed design separates execution governance from semantic risk reasoning through two coordinated components: a runtime controller that mediates actions around the agent loop and a context-aware decision core that operates over persistent session state. The core is formalized as a context-aware advanced machine intelligence and instantiated through operators for risk encoding, utility-cost evaluation, consequence modeling, policy arbitration, and state synchronization. Experiments on Agent Security Bench (ASB) and InjecAgent show that SafeAgent consistently improves robustness over baseline and text-level guardrail methods while maintaining competitive benign-task performance. Ablation studies further show that recovery confidence and policy weighting determine distinct safety-utility operating points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SafeAgent, a runtime security architecture for LLM-based agentic systems vulnerable to propagating prompt-injection attacks in multi-step workflows and tool interactions. It separates execution governance from semantic risk reasoning via a runtime controller that mediates the agent loop and a context-aware decision core operating over persistent session state. The decision core is formalized as a context-aware advanced machine intelligence instantiated through five operators (risk encoding, utility-cost evaluation, consequence modeling, policy arbitration, and state synchronization). Experiments on Agent Security Bench (ASB) and InjecAgent benchmarks report consistent robustness gains over baselines and text-level guardrails while preserving competitive benign-task performance; ablation studies examine the effects of recovery confidence and policy weighting on safety-utility operating points.
Significance. If the experimental claims are supported by detailed results in the full manuscript, the work addresses a timely and important problem in AI safety by shifting from static filtering to stateful, trajectory-aware runtime protection. The explicit separation of governance and risk reasoning, combined with formalization of the decision core and ablation analysis, provides a concrete design pattern that could be adopted or extended in practical agent deployments. The use of two established benchmarks strengthens the evaluation, though the magnitude of gains and statistical robustness would determine broader impact.
minor comments (3)
- [Abstract] Abstract: The claim of 'consistent' robustness improvements and 'competitive' benign-task performance is stated without any quantitative metrics, confidence intervals, or table references, which reduces immediate clarity even if the full experiments section supplies them.
- [Section 3] Section 3 (formalization): The phrase 'context-aware advanced machine intelligence' for the decision core is non-standard and lacks a precise definition or reference to related formalisms (e.g., POMDPs or online decision processes); clarifying its relation to the five listed operators would improve precision.
- [Experiments] Experiments section: While ablation studies on recovery confidence and policy weighting are mentioned, the manuscript would benefit from explicit reporting of false-positive rates on benign tasks and any statistical tests for the robustness gains to allow readers to evaluate the safety-utility trade-off quantitatively.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of SafeAgent, the recognition of its timely contribution to runtime protection for LLM agents, and the recommendation for minor revision. The emphasis on stateful trajectory-aware protection and the formalization of the decision core aligns with our goals. No specific major comments were provided in the report.
Circularity Check
No significant circularity in architectural proposal or validation
full rationale
The paper describes SafeAgent as a runtime architecture with a controller and context-aware decision core instantiated via five operators (risk encoding, utility-cost evaluation, consequence modeling, policy arbitration, state synchronization). No mathematical derivations, equations, first-principles predictions, or fitted parameters presented as independent results appear in the abstract or description. Validation consists of empirical experiments on ASB and InjecAgent benchmarks demonstrating robustness gains with competitive benign performance; this is external evidence rather than a reduction to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. The design is self-contained as an engineering proposal.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
The Granularity Mismatch in Agent Security: Argument-Level Provenance Solves Enforcement and Isolates the LLM Reasoning Bottleneck
PACT achieves perfect security and utility under oracle provenance by enforcing argument-level trust contracts based on semantic roles and cross-step provenance tracking, outperforming invocation-level monitors in Age...
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[2]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “More than you’ve asked for: A comprehensive analysis of novel prompt injection threats to application-integrated large language models,”arXiv preprint arXiv:2302.12173, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
From prompt injections to protocol exploits: Threats in LLM-powered AI agents workflows,
M. A. Ferrag, N. Tihanyi, D. Hamouda, L. Maglaras, A. Lakas, and M. Debbah, “From prompt injections to protocol exploits: Threats in LLM-powered AI agents workflows,”ICT Express, 2025, available online 13 December 2025
2025
-
[4]
Instruction backdoor attacks against customized LLMs,
R. Zhang, H. Li, R. Wen, W. Jiang, Y . Zhang, M. Backes, Y . Shen, and Y . Zhang, “Instruction backdoor attacks against customized LLMs,” in 33rd USENIX Security Symposium (USENIX Security 24), Philadelphia, PA, USA, 2024
2024
-
[5]
A path towards autonomous machine intelligence,
Y . LeCun, “A path towards autonomous machine intelligence,” 2022, manuscript, version 0.9.2. Accessed: 2026-02-14. [Online]. Available: https://openreview.net/forum?id=BZ5a1r-kVsf
2022
-
[6]
JATMO: Prompt injection defense by task-specific finetuning,
J. Piet, M. Alrashed, C. Sitawarin, S. Chen, Z. Wei, E. Sun, B. Alomair, and D. Wagner, “JATMO: Prompt injection defense by task-specific finetuning,”arXiv preprint arXiv:2312.17673, 2024
-
[7]
RedVisor: Reasoning-aware prompt injection defense via zero-copy KV cache reuse,
M. Liu, S. Zhang, C. Long, and K.-Y . Lam, “RedVisor: Reasoning-aware prompt injection defense via zero-copy KV cache reuse,”arXiv preprint arXiv:2602.01795, 2026
-
[8]
PISanitizer: Preventing prompt injection to long-context LLMs via prompt sanitiza- tion,
R. Geng, Y . Wang, C. Yin, M. Cheng, Y . Chen, and J. Jia, “PISanitizer: Preventing prompt injection to long-context LLMs via prompt sanitiza- tion,”arXiv preprint arXiv:2511.10720, 2025
-
[9]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggine, and M. Khabsa, “Llama Guard: LLM-based input-output safeguard for human-AI conversations,”arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
LLM Guard: The security toolkit for LLM interactions,
Protect AI, “LLM Guard: The security toolkit for LLM interactions,” 2024, gitHub repository. Accessed: 2026-02-15. [Online]. Available: https://github.com/protectai/llm-guard
2024
-
[11]
GradSafe: Detecting Unsafe Prompts for LLMs via Safety-Critical Gradient Analysis
Y . Xie, M. Fang, R. Piet al., “GradSafe: Detecting jailbreak prompts for LLMs via safety-critical gradient analysis,”arXiv preprint arXiv:2402.13494, 2024
-
[12]
doi:10.48550/arXiv.2501.18492 , abstract =
Y . Liu, H. Gao, S. Zhaiet al., “GuardReasoner: Towards reasoning-based LLM safeguards,”arXiv preprint arXiv:2501.18492, 2025
-
[13]
arXiv preprint arXiv:2410.22770 , year=
H. Li and X. Liu, “InjecGuard: Benchmarking and mitigating over-defense in prompt injection guardrail models,”arXiv preprint arXiv:2410.22770, 2024
-
[14]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
E. Wallaceet al., “The instruction hierarchy: Training language models to prioritize privileged instructions,”arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
AgentSys: Secure and dynamic LLM agents through explicit hierarchical memory management,
R. Wen, H. Li, C. Xiao, and N. Zhang, “AgentSys: Secure and dynamic LLM agents through explicit hierarchical memory management,”arXiv preprint arXiv:2602.07398, 2026
-
[16]
H. An, J. Zhang, T. Du, C. Zhou, Q. Li, T. Lin, and S. Ji, “IPIGuard: A novel tool dependency graph-based defense against indirect prompt injection in LLM agents,”arXiv preprint arXiv:2508.15310, 2025
-
[17]
T. Rebedeaet al., “NeMo guardrails: A toolkit for controllable and safe LLM applications with programmable rails,”arXiv preprint arXiv:2310.10501, 2023
-
[18]
Introducing gpt-oss-safeguard,
OpenAI, “Introducing gpt-oss-safeguard,” 2025, product release, October 29, 2025. [Online]. Available: https://openai.com/index/ introducing-gpt-oss-safeguard/
2025
-
[19]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (ASB): Formalizing and bench- marking attacks and defenses in LLM-based agents,”arXiv preprint arXiv:2410.02644, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,”arXiv preprint arXiv:2403.02691, 2024
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.