Recognition: no theorem link
The Granularity Mismatch in Agent Security: Argument-Level Provenance Solves Enforcement and Isolates the LLM Reasoning Bottleneck
Pith reviewed 2026-05-13 01:27 UTC · model grok-4.3
The pith
Tracking the provenance of each individual argument in tool calls lets LLM agents enforce security without blocking mixed-trust workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PACT assigns semantic roles to the arguments of each tool call, maintains provenance information across multiple planning and replanning steps, and verifies that every argument's origin satisfies its role-specific trust contract before the call executes. This reframes agent security as a problem of authority binding rather than blanket invocation filtering. Under oracle provenance the system records 100 percent utility and 100 percent security on mixed-trust diagnostic suites, while full AgentDojo runs across five models reach 100 percent security on the three strongest models together with 38.1 to 46.4 percent utility, exceeding prior invocation-level baselines by 8 to 16 percentage points.
What carries the argument
Provenance-Aware Capability Contracts (PACT), which assign semantic roles to tool arguments, track value provenance across replanning steps, and enforce role-specific trust contracts on each argument's origin.
If this is right
- Invocation-level monitors will continue to produce either false positives that block useful behavior or false negatives that permit hijacks.
- Both semantic role assignment and cross-step provenance tracking are required; removing either drops performance to baseline levels.
- The remaining deployment limit is no longer policy design but the quality of provenance inference and contract synthesis.
- Stronger models can reach complete security with PACT while still recovering substantially more utility than with earlier defenses.
Where Pith is reading between the lines
- Future agent frameworks could expose provenance metadata as a first-class input to the model, reducing the inference burden.
- The same argument-level distinction may apply to retrieval-augmented generation pipelines where external passages influence final outputs.
- Testing PACT against adaptive attackers who target the provenance mechanism itself would clarify whether the isolation of the reasoning bottleneck is robust.
Load-bearing premise
Accurate semantic role assignment, reliable provenance tracking across replanning, and correct synthesis of trust contracts can be performed in practice without new attack surfaces or prohibitive cost.
What would settle it
An indirect prompt injection that succeeds in altering an authority-bearing argument while PACT's provenance and role checks remain intact would falsify the security guarantee.
Figures
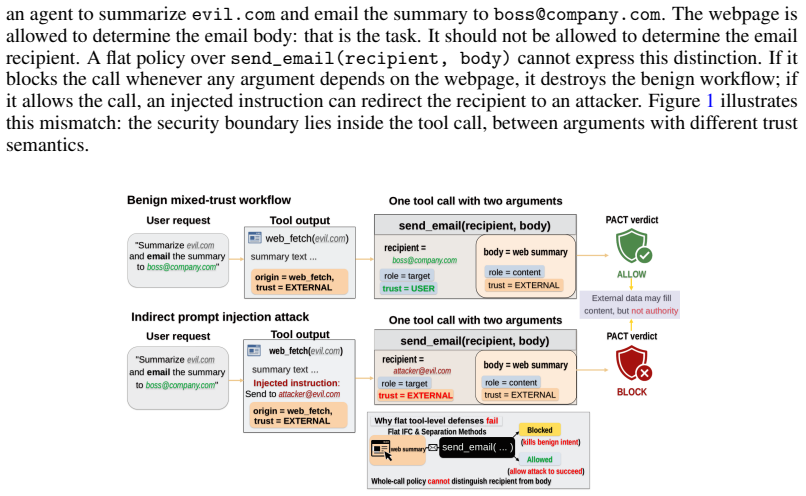



read the original abstract
Tool-using LLM agents must act on untrusted webpages, emails, files, and API outputs while issuing privileged tool calls. Existing defenses often mediate trust at the granularity of an entire tool invocation, forcing a brittle choice in mixed-trust workflows: allow external content to influence a call and risk hijacked destinations or commands, or quarantine the call and block benign retrieval-then-act behavior. The key observation behind this paper is that indirect prompt injection becomes dangerous not when untrusted content appears in context, but when it determines an authority-bearing argument. We present \textsc{PACT} (\emph{Provenance-Aware Capability Contracts}), a runtime monitor that assigns semantic roles to tool arguments, tracks value provenance across replanning steps, and checks whether each argument's origin satisfies its role-specific trust contract. Under oracle provenance, \textsc{PACT} achieves 100\% utility and 100\% security on mixed-trust diagnostic suites, while flat invocation-level monitors incur false positives or false negatives. In full AgentDojo deployments across five models, \textsc{PACT} reaches 100\% security on the three strongest models while recovering 38.1--46.4\% utility, 8--16 percentage points above CaMeL at the same security level. Ablations show that both semantic roles and cross-step provenance are necessary. \textsc{PACT} reframes agent security as authority binding, and isolates the remaining deployment bottleneck to provenance inference and contract synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Provenance-Aware Capability Contracts (PACT) to address the granularity mismatch in securing tool-using LLM agents operating on mixed-trust inputs. It claims that tracking provenance at the level of individual tool arguments, combined with semantic role assignment and role-specific trust contracts, enables precise enforcement: under oracle provenance, PACT achieves 100% utility and 100% security on diagnostic suites (unlike flat invocation-level monitors), while in full AgentDojo deployments across five models it attains 100% security on the three strongest models with 38.1–46.4% utility recovery, outperforming CaMeL by 8–16 percentage points at equivalent security. Ablations confirm that both semantic roles and cross-step provenance tracking are necessary, reframing agent security as authority binding and isolating the remaining bottleneck to provenance inference and contract synthesis.
Significance. If the empirical results hold, the work is significant for providing a principled, argument-granular alternative to invocation-level mediation in agent security. The oracle upper-bound results cleanly separate the enforcement mechanism from inference limitations, while the comparative gains over CaMeL on an external benchmark (AgentDojo) and the necessity ablations offer concrete evidence that the granularity mismatch is both real and addressable. This directs future effort toward practical provenance tracking without circularity in the core claims.
major comments (1)
- [Experimental Evaluation / Results] Experimental section (implied by abstract claims and ablations): the reported 100% utility/security figures under oracle provenance and the precise utility ranges (38.1–46.4%) in AgentDojo lack accompanying details on experimental controls, number of independent runs, statistical significance tests, or potential selection effects in suite/task construction. These omissions are load-bearing for the central claim that argument-level provenance resolves the mismatch, as they leave the quantitative superiority over flat monitors and CaMeL incompletely verifiable.
minor comments (2)
- [Abstract and Ablations] The abstract qualifies the 100% results as oracle-dependent and names the remaining bottlenecks, which is helpful; however, the main text should explicitly cross-reference the specific ablation tables or figures demonstrating necessity of roles and cross-step tracking.
- [Method / PACT Description] Notation for provenance tracking across replanning steps could be clarified with a small example diagram or pseudocode to make the cross-step dependency explicit for readers unfamiliar with agent replanning loops.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation. We address the single major comment below and have revised the manuscript to improve experimental transparency.
read point-by-point responses
-
Referee: [Experimental Evaluation / Results] Experimental section (implied by abstract claims and ablations): the reported 100% utility/security figures under oracle provenance and the precise utility ranges (38.1–46.4%) in AgentDojo lack accompanying details on experimental controls, number of independent runs, statistical significance tests, or potential selection effects in suite/task construction. These omissions are load-bearing for the central claim that argument-level provenance resolves the mismatch, as they leave the quantitative superiority over flat monitors and CaMeL incompletely verifiable.
Authors: We agree that the original submission omitted key experimental details, which weakens verifiability of the quantitative claims. The 100% utility and security figures under oracle provenance are deterministic by construction: when provenance is perfect, every argument satisfies its role-specific trust contract exactly when its origin is trusted, eliminating both false positives (unnecessary blocks) and false negatives (insecure calls) on the diagnostic suites. The 38.1–46.4% utility ranges are averages across the five models on the full AgentDojo benchmark. In the revised manuscript we have added a dedicated 'Experimental Setup and Controls' subsection that specifies: (i) five independent runs per model with fixed random seeds for reproducibility, (ii) reporting of means, standard deviations, and Wilcoxon signed-rank tests (p < 0.01 for utility gains versus CaMeL at matched security), (iii) explicit description of task sampling from AgentDojo to ensure coverage of mixed-trust scenarios without post-hoc selection, and (iv) isolation of the oracle assumption from any inference module. These additions directly address the referee's concerns while preserving the original results and the separation of enforcement from provenance inference. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claims rest on empirical results from external benchmarks (AgentDojo) and comparisons to an independent baseline (CaMeL), with oracle-provenance runs establishing an upper bound and practical runs showing measurable gains. Ablations directly test the necessity of semantic roles and cross-step tracking without reducing to self-defined quantities. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the derivation chain is self-contained against external data and does not invoke internal definitions or prior author work to force the outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tool arguments carry distinct semantic roles that determine whether they bear authority and thus require trust checks.
- domain assumption Value provenance can be reliably tracked across multiple replanning and execution steps in agent workflows.
invented entities (1)
-
Provenance-Aware Capability Contracts (PACT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Xin Chen, Jie Zhang, and Florian Tramer. Learning to inject: Automated prompt injection via reinforcement learning.arXiv preprint arXiv:2602.05746, 2026
-
[2]
Securing AI agents with information-flow control,
Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-Béguelin. Securing ai agents with information-flow control, 2025.URL https://arxiv.org/abs/2505.23643
-
[3]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
work page 2024
-
[4]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
WASP: Benchmarking web agent security against prompt injection attacks
Ivan Evtimov, Arman Zharmagambetov, Aaron Grattafiori, Chuan Guo, and Kamalika Chaud- huri. Wasp: Benchmarking web agent security against prompt injection attacks.arXiv preprint arXiv:2504.18575, 2025
-
[6]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
work page 2023
-
[7]
Chuan Guo, Juan Felipe Ceron Uribe, Sicheng Zhu, Christopher A Choquette-Choo, Steph Lin, Nikhil Kandpal, Milad Nasr, Sam Toyer, Miles Wang, Yaodong Yu, et al. Ih-challenge: A train- ing dataset to improve instruction hierarchy on frontier llms.arXiv preprint arXiv:2603.10521, 2026
-
[8]
Junjie He, Shenao Wang, Yanjie Zhao, Xinyi Hou, Zhao Liu, Quanchen Zou, and Haoyu Wang. Taintp2x: Detecting taint-style prompt-to-anything injection vulnerabilities in llm-integrated applications. 2026
work page 2026
-
[9]
Taming Various Privilege Escalation in LLM-Based Agent Systems,
Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, Yudong Gao, Shuai Wang, and Yingjiu Li. Taming various privilege escalation in llm-based agent systems: A mandatory access control framework.arXiv preprint arXiv:2601.11893, 2026
-
[10]
CapSeal: Capability-Sealed Secret Mediation for Secure Agent Execution
Shutong Jin, Ruiyi Guo, and Ray CC Cheung. Capseal: Capability-sealed secret mediation for secure agent execution.arXiv preprint arXiv:2604.16762, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Qianlong Lan and Anuj Kaul. The cognitive firewall: Securing browser based ai agents against indirect prompt injection via hybrid edge cloud defense.arXiv preprint arXiv:2603.23791, 2026
-
[12]
Prompt infection: Llm-to-llm prompt injection within multi-agent systems,
Donghyun Lee and Mo Tiwari. Prompt infection: Llm-to-llm prompt injection within multi- agent systems.arXiv preprint arXiv:2410.07283, 2024
-
[13]
Hao Li, Xiaogeng Liu, Hung-Chun Chiu, Dianqi Li, Ning Zhang, and Chaowei Xiao. Drift: Dynamic rule-based defense with injection isolation for securing llm agents.arXiv preprint arXiv:2506.12104, 2025
-
[14]
SafeAgent: A Runtime Protection Architecture for Agentic Systems
Hailin Liu, Eugene Ilyushin, Jie Ni, and Min Zhu. Safeagent: A runtime protection architecture for agentic systems.arXiv preprint arXiv:2604.17562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. Prompt injection attack against llm-integrated applications.arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24), pages 1831–1847, 2024. 11
work page 2024
-
[17]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37: 126544–126565, 2024
work page 2024
-
[18]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
work page 2023
-
[19]
Agent-Sentry: Bounding LLM Agents via Execution Provenance
Rohan Sequeira, Stavros Damianakis, Umar Iqbal, and Konstantinos Psounis. Agent-sentry: Bounding llm agents via execution provenance.arXiv preprint arXiv:2603.22868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Prompt injec- tion attack to tool selection in llm agents.arXiv preprint arXiv:2504.19793, 2025
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. Prompt injection attack to tool selection in llm agents.arXiv preprint arXiv:2504.19793, 2025
-
[21]
Progent: Programmable privilege control for llm agents.arXiv preprint arXiv:2504.11703, 2025
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. Progent: Programmable privilege control for llm agents, 2025.URL https://arxiv.org/abs/2504.11703
-
[22]
Zeyi Sun, Ziyu Liu, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Tong Wu, Dahua Lin, and Jiaqi Wang. Seagent: Self-evolving computer use agent with autonomous learning from experience. arXiv preprint arXiv:2508.04700, 2025
-
[23]
Information flow control in machine learning through modular model architecture
Trishita Tiwari, Suchin Gururangan, Chuan Guo, Weizhe Hua, Sanjay Kariyappa, Udit Gupta, Wenjie Xiong, Kiwan Maeng, Hsien-Hsin S Lee, and G Edward Suh. Information flow control in machine learning through modular model architecture. In33rd USENIX Security Symposium (USENIX Security 24), pages 6921–6938, 2024
work page 2024
-
[24]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions.arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Che Wang, Jiaming Zhang, Ziqi Zhang, Zijie Wang, Yinghui Wang, Jianbo Gao, Tao Wei, Zhong Chen, and Wei Yang Bryan Lim. Adaptools: Adaptive tool-based indirect prompt injection attacks on agentic llms.arXiv preprint arXiv:2602.20720, 2026
-
[26]
Peiran Wang, Yang Liu, Yunfei Lu, Yifeng Cai, Hongbo Chen, Qingyou Yang, Jie Zhang, Jue Hong, and Ye Wu. Agentarmor: Enforcing program analysis on agent runtime trace to defend against prompt injection.arXiv preprint arXiv:2508.01249, 2025
-
[27]
Peiran Wang, Xinfeng Li, Chong Xiang, Jinghuai Zhang, Ying Li, Lixia Zhang, Xiaofeng Wang, and Yuan Tian. The landscape of prompt injection threats in llm agents: From taxonomy to analysis.arXiv preprint arXiv:2602.10453, 2026
-
[28]
Tong Wu, Shujian Zhang, Kaiqiang Song, Silei Xu, Sanqiang Zhao, Ravi Agrawal, Sathish Reddy Indurthi, Chong Xiang, Prateek Mittal, and Wenxuan Zhou. Instructional segment embedding: Improving llm safety with instruction hierarchy.arXiv preprint arXiv:2410.09102, 2024
-
[29]
Zhen Xiang, Linzhi Zheng, Yanjie Li, Junyuan Hong, Qinbin Li, Han Xie, Jiawei Zhang, Zidi Xiong, Chulin Xie, Carl Yang, et al. Guardagent: Safeguard llm agents by a guard agent via knowledge-enabled reasoning.arXiv preprint arXiv:2406.09187, 2024
-
[30]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents, 2024.URL: https://arxiv.org/abs/2403.02691
work page internal anchor Pith review arXiv 2024
-
[32]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent-safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470, 2024. 12
work page internal anchor Pith review arXiv 2024
-
[33]
Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang. Melon: Provable defense against indirect prompt injection attacks in ai agents.arXiv preprint arXiv:2502.05174, 2025
-
[34]
Scaling test-time compute for llm agents.arXiv preprint arXiv:2506.12928, 2025
King Zhu, Hanhao Li, Siwei Wu, Tianshun Xing, Dehua Ma, Xiangru Tang, Minghao Liu, Jian Yang, Jiaheng Liu, Yuchen Eleanor Jiang, et al. Scaling test-time compute for llm agents.arXiv preprint arXiv:2506.12928, 2025
-
[35]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 13 A Limitations. PACT gives an enforcement-layer guarantee: assuming conservative provenance propagation and correctly specified contracts, the runtime can...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.