Recognition: unknown
How Much Data is Enough? The Zeta Law of Discoverability in Biomedical Data, featuring the enigmatic Riemann zeta function
Pith reviewed 2026-05-10 06:26 UTC · model grok-4.3
The pith
Biomedical model performance scales with data according to a zeta-like law derived from spectral covariance decay and signal alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
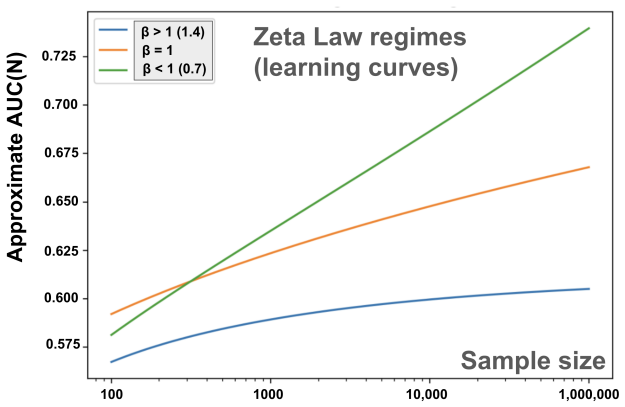
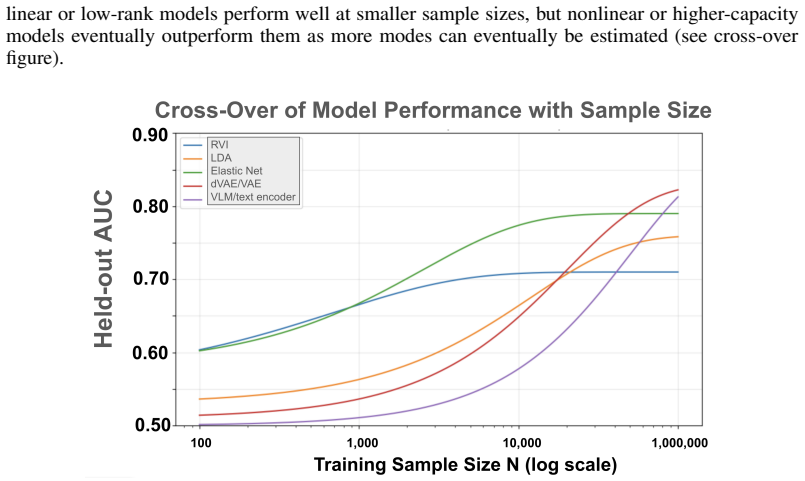
The central claim is that the discoverability of a biomedical signal is governed by a zeta-like scaling law: when covariance spectra and task-aligned energies both follow power-law decay, the total signal-to-noise energy collected up to a given data size N takes the form of a partial sum that approaches a Riemann zeta function value as N grows. Representation methods that steepen the spectral decay shift the curve leftward, so fewer samples suffice to reach a target performance level. The same framework predicts cross-over points where low-capacity models win at small N and high-capacity multimodal encoders win once later modes stabilize.
What carries the argument
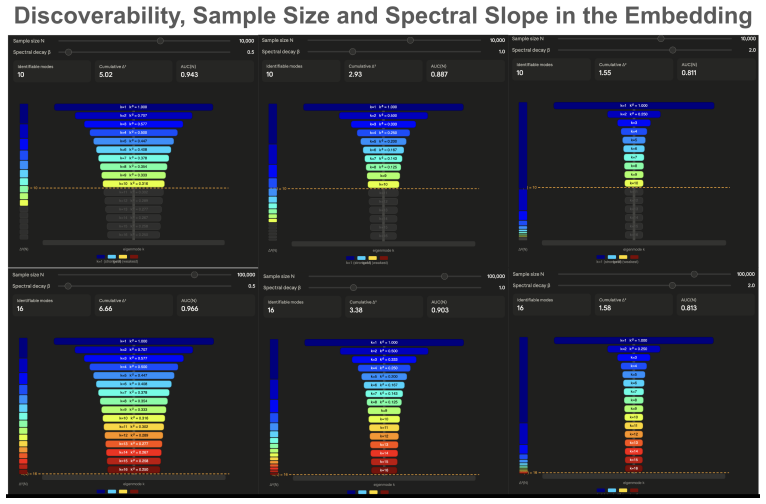
The zeta-like scaling law arising from cumulative signal-to-noise energy across power-law decaying spectral modes of the covariance operator and the cross-modal projection.
If this is right
- Simpler models outperform high-capacity ones at small sample sizes because later spectral modes remain unstable.
- Adding modalities or contrastive objectives improves efficiency by shifting signal energy into fewer early modes, flattening the required N.
- Cross-over regimes appear predictably: once data volume stabilizes additional degrees of freedom, multimodal encoders surpass unimodal ones.
- Topological or imaging-genetics tasks can be ranked by their effective spectral decay rates to decide data-collection priorities.
Where Pith is reading between the lines
- If the zeta law holds, experimental design in large cohorts could pre-allocate sample budgets by estimating the decay exponent from a pilot subset rather than running full scaling sweeps.
- The framework suggests a natural test: deliberately flatten or steepen covariance spectra via preprocessing and check whether the observed scaling curve shifts exactly as predicted.
- Neighbouring problems such as active learning or few-shot adaptation might inherit similar zeta forms once their selection criteria are expressed as spectral filters.
Load-bearing premise
Performance metrics such as AUC can be expressed directly as the sum of signal-to-noise contributions from ordered spectral modes of the data covariance and task alignment.
What would settle it
Measure AUC or equivalent performance on a fixed biomedical task across a wide range of dataset sizes N and plot the curve; if the increments do not follow the predicted zeta-like form once spectral decays are estimated from the same data, the scaling relation fails.
Figures


read the original abstract
How much data is enough to make a scientific discovery? As biomedical datasets scale to millions of samples and AI models grow in capacity, progress increasingly depends on predicting when additional data will substantially improve performance. In practice, model development often relies on empirical scaling curves measured across architectures, modalities, and dataset sizes, with limited theoretical guidance on when performance should improve, saturate, or exhibit cross-over behavior. We propose a scaling-law framework for cross-modal discoverability based on spectral structure of data covariance operators, task-aligned signal projections, and learned representations. Many performance metrics, including AUC, can be expressed in terms of cumulative signal-to-noise energy accumulated across identifiable spectral modes of an encoder and cross-modal operator. Under mild assumptions, this accumulation follows a zeta-like scaling law governed by power-law decay of covariance spectra and aligned signal energy, leading naturally to the appearance of the Riemann zeta function. Representation learning methods such as sparse models, low-rank embeddings, and multimodal contrastive objectives improve sample efficiency by concentrating useful signal into earlier stable modes, effectively steepening spectral decay and shifting scaling curves. The framework predicts cross-over regimes in which simpler models perform best at small sample sizes, while higher-capacity or multimodal encoders outperform them once sufficient data stabilizes additional degrees of freedom. Applications include multimodal disease classification, imaging genetics, functional MRI, and topological data analysis. The resulting zeta law provides a principled way to anticipate when scaling data, improving representations, or adding modalities is most likely to accelerate discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a scaling-law framework for cross-modal discoverability in biomedical AI, based on the spectral structure of data covariance operators and task-aligned signal projections. It claims that many performance metrics (including AUC) can be expressed as cumulative signal-to-noise energy across identifiable spectral modes; under mild assumptions on power-law decay of covariance spectra and aligned energy, this accumulation yields a zeta-like scaling law that naturally produces the Riemann zeta function. Representation learning techniques (sparse models, low-rank embeddings, multimodal contrastive objectives) are said to improve sample efficiency by concentrating signal into earlier modes and steepening decay. The framework predicts cross-over regimes where simpler models excel at small scales while higher-capacity or multimodal encoders dominate once additional modes stabilize. Applications to multimodal disease classification, imaging genetics, fMRI, and topological data analysis are outlined.
Significance. If the central derivation is sound, the work would supply a rare theoretical handle on data scaling in biomedical machine learning, moving beyond purely empirical curves to predict saturation, cross-overs, and the value of added modalities or capacity. The explicit link to the Riemann zeta function via spectral decay is unusual and potentially unifying, provided the discretization step is rigorous. The emphasis on falsifiable predictions (cross-over points, effects of representation choices) is a strength.
major comments (3)
- [§3] §3 (Framework and Derivation): The central claim that power-law decay of covariance spectra and aligned signal energy 'leads naturally to the appearance of the Riemann zeta function' is load-bearing but unsupported by an explicit construction. Continuous covariance operators on biomedical data possess continuous spectra; the manuscript must derive how eigenmodes are discretized, ordered by positive integers n, and projected such that the cumulative energy sum reduces exactly to a partial sum of ζ(s) rather than a generic integral or power-law form. Without this step, the zeta appearance risks being an imposed rather than emergent feature.
- [§2.2] §2.2 (Mild Assumptions on Performance Metrics): The assumption that AUC and similar metrics can be expressed as cumulative signal-to-noise energy across spectral modes of an encoder and cross-modal operator is stated without a supporting lemma or explicit functional form. This mapping is required for the subsequent scaling law; if it holds only under additional restrictions on the task-aligned operator or basis alignment, the 'mild' qualifier and the resulting zeta law must be qualified accordingly.
- [§4] §4 (Cross-over Regimes): The predicted cross-over between simpler and higher-capacity models at different sample sizes is presented as a direct consequence of the zeta law, yet no quantitative threshold (in terms of spectral exponent s or mode count) is derived or validated against the paper's own equations. This leaves the regime boundaries as qualitative statements rather than falsifiable predictions.
minor comments (2)
- [§2] Notation for spectral decay exponents and aligned energy should be introduced with a single consistent symbol set early in §2 to avoid later ambiguity when relating them to the zeta parameter s.
- [Abstract / §1] The abstract and introduction repeatedly use 'naturally' and 'mild assumptions' without a forward reference to the precise conditions under which the zeta reduction holds; a short 'assumptions box' would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments correctly identify points where the derivations require greater explicitness to support the central claims. We address each major comment below and will incorporate the requested clarifications and derivations in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Framework and Derivation): The central claim that power-law decay of covariance spectra and aligned signal energy 'leads naturally to the appearance of the Riemann zeta function' is load-bearing but unsupported by an explicit construction. Continuous covariance operators on biomedical data possess continuous spectra; the manuscript must derive how eigenmodes are discretized, ordered by positive integers n, and projected such that the cumulative energy sum reduces exactly to a partial sum of ζ(s) rather than a generic integral or power-law form. Without this step, the zeta appearance risks being an imposed rather than emergent feature.
Authors: We agree that the transition from the continuous spectral integral to the discrete zeta sum requires an explicit construction. In the revision we will add a new subsection in §3 that (i) truncates the continuous covariance operator to its leading eigenmodes via a spectral cutoff, (ii) orders the retained eigenvalues by positive integers n under the assumed power-law decay λ_n ∼ n^{-s}, and (iii) shows that the cumulative aligned signal energy then becomes a partial sum of the Riemann zeta function ζ(s) minus the tail. This step will be presented as a direct consequence of the power-law assumption rather than an additional imposition. revision: yes
-
Referee: [§2.2] §2.2 (Mild Assumptions on Performance Metrics): The assumption that AUC and similar metrics can be expressed as cumulative signal-to-noise energy across spectral modes of an encoder and cross-modal operator is stated without a supporting lemma or explicit functional form. This mapping is required for the subsequent scaling law; if it holds only under additional restrictions on the task-aligned operator or basis alignment, the 'mild' qualifier and the resulting zeta law must be qualified accordingly.
Authors: The referee is correct that the mapping from AUC (and related metrics) to cumulative signal-to-noise energy is stated rather than derived. We will insert a supporting lemma in §2.2 that explicitly constructs the functional form under the assumption that the task-aligned projection operator is diagonal in the eigenbasis of the data covariance. The lemma will also state the precise alignment condition required; we will replace the unqualified 'mild assumptions' phrasing with a clear statement of these conditions so that the scope of the zeta law is accurately delimited. revision: yes
-
Referee: [§4] §4 (Cross-over Regimes): The predicted cross-over between simpler and higher-capacity models at different sample sizes is presented as a direct consequence of the zeta law, yet no quantitative threshold (in terms of spectral exponent s or mode count) is derived or validated against the paper's own equations. This leaves the regime boundaries as qualitative statements rather than falsifiable predictions.
Authors: We acknowledge that the cross-over predictions remain qualitative in the current draft. In the revision we will derive an explicit expression for the critical sample size N* at which a higher-capacity model overtakes a simpler one, expressed in terms of the spectral exponent s and the number of stabilized modes. The derivation will equate the incremental zeta-sum contribution of the additional modes to the capacity-dependent regularization term already present in the manuscript equations. We will also add a short numerical validation using the paper's own spectral-decay parameters to illustrate the predicted N* values. revision: yes
Circularity Check
No significant circularity; zeta scaling presented as consequence of power-law assumptions without reduction to fitted inputs or self-definition.
full rationale
The abstract states that under mild assumptions the accumulation of signal-to-noise energy follows a zeta-like scaling law from power-law decay of covariance spectra and aligned signal energy. No equations, derivations, or self-citations appear in the provided text that would make the Riemann zeta function equivalent to its inputs by construction. The framework is positioned as predictive of cross-over regimes based on spectral structure, with no load-bearing step shown to rename a fit or import uniqueness from prior author work. This is the common honest outcome for a proposal paper whose central claim remains independent of its own fitted values.
Axiom & Free-Parameter Ledger
free parameters (1)
- spectral decay exponents
axioms (1)
- domain assumption Performance metrics such as AUC can be expressed in terms of cumulative signal-to-noise energy across spectral modes of an encoder and cross-modal operator.
Forward citations
Cited by 1 Pith paper
-
Anchoring the Eigengap: Cross-Modal Spectral Stabilization for Sample-Efficient Representation Learning
Finite-sample noise collapses the eigengap in representation covariances limiting recoverable modes K(N); multimodal learning stabilizes it via low-rank constraints, yielding better class separation quantified by trun...
Reference graph
Works this paper leans on
-
[1]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. (2021). Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, 8748–8763
2021
-
[2]
S., Ghosh, S
Margulies, D. S., Ghosh, S. S., Goulas, A., Falkiewicz, M., Huntenburg, J. M., Langs, G., Bezgin, G., Eickhoff, S. B., Castellanos, F. X., Petrides, M., Jefferies, E., and Smallwood, J. (2016). Situating the default-mode network along a principal gradient of macroscale cortical organization.Proceedings of the National Academy of Sciences, 113(44), 12574–12579
2016
-
[3]
Dvoretzky, A., Kiefer, J., and Wolfowitz, J. (1956). Asymptotic minimax character of the sample distribution function and of the classical multinomial estimator.Annals of Mathematical Statistics, 27(3), 642–669
1956
-
[4]
Massart, P. (1990). The tight constant in the Dvoretzky–Kiefer–Wolfowitz inequality.Annals of Probability, 18(3), 1269–1283
1990
-
[5]
and Kahan, W
Davis, C. and Kahan, W. M. (1970). The rotation of eigenvectors by a perturbation. III.SIAM Journal on Numerical Analysis, 7(1), 1–46
1970
-
[6]
L., Howell, A., Rosand, B., and others (2024)
Helmer, M., Warrington, S., Mohammadi-Nejad, A.-R., Ji, J. L., Howell, A., Rosand, B., and others (2024). On the stability of canonical correlation analysis and partial least squares with application to brain–behavior associations.Communications Biology, 7, 217. https://doi.org/10.1038/s42003-024-05869-4
- [7]
-
[8]
J., Jagad, C., Senthilkumar, P., Thomopoulos, S
Dhinagar, N. J., Jagad, C., Senthilkumar, P., Thomopoulos, S. I., Khan, M. H., Liew, S.-L., ENIGMA-Stroke Recovery Working Group, Banaj, N., Boric, M. R., Boyd, L. A., Brodtmann, A., Cassidy, J. M., Conforto, A. B., Cramer, S. C., Dula, A. N., Geranmayeh, F., Gregory, C. M., Hordacre, B., Jaywant, A., Kautz, S. A., Leech, K. A., Lotze, M., Mataró, M., Pir...
-
[9]
Hettwer, M. D., Larivière, S., Park, B. Y ., van den Heuvel, O. A., Schmaal, L., Andreassen, O. A., Ching, C. R. K., Hoogman, M., Buitelaar, J., van Rooij, D., Veltman, D. J., Stein, D. J., Franke, B., van Erp, T. G. M., ENIGMA ADHD Working Group, ENIGMA Autism Working Group, ENIGMA Bipolar Disorder Working Group, ENIGMA Major Depression Working Group, EN...
-
[10]
D., Saberi, A., Shafiei, G., Manoli, A., de Boer, A
Hettwer, M. D., Saberi, A., Shafiei, G., Manoli, A., de Boer, A. A. A., van den Heuvel, O. A., Schmaal, L., Pozzi, E., Andreassen, O. A., Ching, C. R. K., Lawrence, K., Kim, G., Buitelaar, J., Turner, J. A., van Erp, T. G. M., Stein, D. J., Pine, D. S., Winkler, A. M., Bas-Hoogendam, J. M., Zugman, A., van der Wee, N. J. A., Groenewold, N. A., ENIGMA Auti...
2026
-
[11]
Ruan, H., Chung, M. K., Bruin, W. B., Džinalija, N., Abe, Y ., Alonso, P., Anticevic, A., Balachander, S., Batistuzzo, M. C., Benedetti, F., Bertolín, S., Brem, S., Cho, Y ., Colombo, F., Couto, B., Eng, G. K., Ferreira, S., Feusner, J. D., Gruner, P., Hagen, K., Hansen, B., Hirano, Y ., Hoexter, M. Q., Ipser, J., Jaspers-Fayer, F., Kim, M., Kwon, J. S., ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.