Recognition: 3 theorem links
· Lean TheoremAnchoring the Eigengap: Cross-Modal Spectral Stabilization for Sample-Efficient Representation Learning
Pith reviewed 2026-05-12 02:52 UTC · model grok-4.3
The pith
Multimodal training preserves the eigengap in embedding covariances, recovering more stable eigenmodes from scarce samples than unimodal training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Finite-sample noise sets an operator-norm floor of order sqrt(D/N) below which eigenmodes cannot be reliably estimated; only modes above this floor contribute to a truncated Mahalanobis energy that governs downstream performance. Under a power-law spectral model this energy is approximated by a truncated Riemann zeta function, directly tying eigenvalue decay rate to data efficiency and AUC. Multimodal learning supplies low-rank constraints that suppress noise-dominated directions, thereby anchoring the eigengap and increasing the recoverable dimension K(N) when labeled samples are scarce.
What carries the argument
The recoverable dimension K(N), the count of eigenmodes whose eigenvalues exceed the finite-sample noise floor ||Sigma-hat - Sigma||_op ~ sqrt(D/N), which multimodal low-rank constraints help preserve by suppressing noise directions.
If this is right
- K(N) sets the effective dimensionality available for stable classification in low-N regimes.
- The zeta approximation of truncated Mahalanobis energy predicts AUC directly from the power-law exponent.
- Zeta-based spectral filtering offers a principled way to discard noise modes and raise data efficiency.
- Multimodal models maintain higher K(N) and better mode stability than unimodal models even when their few-shot accuracies appear similar.
Where Pith is reading between the lines
- Encoders could be regularized with explicit low-rank or spectral penalties to mimic the stabilization multimodal training provides without requiring paired data.
- The same noise-floor analysis may apply to other self-supervised objectives that implicitly constrain rank or spectrum.
- Testing whether K(N) scales predictably on larger medical imaging cohorts would check if the power-law assumption holds beyond the reported datasets.
Load-bearing premise
The embedding covariance obeys a power-law spectral decay that permits the truncated Mahalanobis energy to be approximated by a Riemann zeta function and that perturbation theory plus concentration bounds locate the noise floor accurately.
What would settle it
Measure K(N) on held-out data as N varies; if the observed number of modes above the estimated noise floor does not increase with N as predicted by the zeta approximation, or if multimodal training fails to yield higher K(N) than unimodal training at matched sample size, the central claim is refuted.
Figures



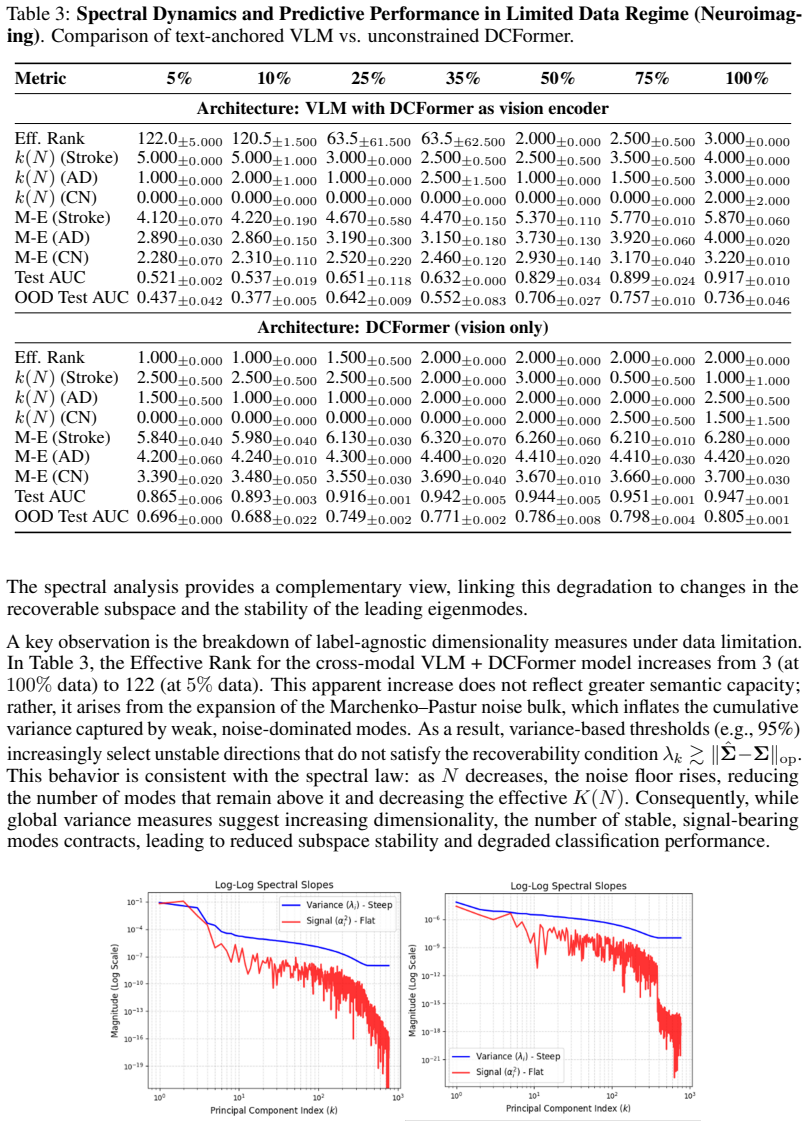

read the original abstract
Deep vision models degrade sharply in low-data regimes, particularly in medical imaging where labeled samples are scarce. We show this arises not merely from overfitting but from a geometric failure: finite-sample noise corrupts the embedding covariance, collapsing the eigengap and limiting the number of recoverable signal-bearing modes. We develop a spectral theory of finite-sample representation learning that quantifies the recoverable dimension K(N), the number of eigenmodes that can be stably estimated from N samples. Using perturbation theory and concentration bounds, we show that only modes with eigenvalues above the noise floor $\|\hat{\Sigma} - \Sigma\|_{\mathrm{op}} \sim \sqrt{D/N}$ are reliable, yielding a truncated Mahalanobis energy that governs classification performance. Under a power-law spectral model, this energy can be approximated by a truncated Riemann zeta function, linking eigenvalue decay to data efficiency and AUC. Within this framework, multimodal learning acts as spectral stabilization: vision-language models impose low-rank constraints that suppress noise-dominated directions and preserve the eigengap, increasing K(N) under data scarcity. Across MNIST and multi-disease neuroimaging, we show that multimodal training maintains more stable modes and improves class separation, even when unimodal models achieve comparable few-shot accuracy. These results identify spectral collapse as a fundamental bottleneck in low-data learning. We use truncated Mahalanobis energy and K(N) to diagnose encoder quality, and introduce zeta-based spectral filtering as a principled approach to improve data efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a spectral theory of finite-sample representation learning in which the recoverable dimension K(N) is defined as the number of eigenmodes of the embedding covariance whose eigenvalues exceed the operator-norm noise floor ~sqrt(D/N). Under an assumed power-law eigenvalue decay, the truncated Mahalanobis energy that governs classification is approximated by a partial Riemann zeta function. The central claim is that multimodal (vision-language) training imposes low-rank constraints that suppress noise-dominated directions, preserve the eigengap, and thereby increase K(N) relative to unimodal training, with supporting experiments on MNIST and multi-disease neuroimaging.
Significance. If the power-law spectral model and zeta approximation can be rigorously justified and empirically validated for neural embeddings, the framework would supply a geometric account of why multimodal pretraining improves data efficiency and a practical diagnostic (K(N) and zeta-based filtering) for encoder quality in low-data regimes. The empirical observation that multimodal models maintain more stable modes even when few-shot accuracy is comparable is potentially useful, but the quantitative link between spectral stabilization and performance currently rests on unverified modeling assumptions.
major comments (3)
- [Spectral theory development (described in abstract and § on finite-sample theory)] The manuscript states that the truncated Mahalanobis energy is approximated by a partial Riemann zeta function under the power-law model lambda_k ~ k^{-alpha}, yet supplies neither the explicit derivation of this approximation nor a bound on the truncation error. Without these, the claimed quantitative relationship between eigenvalue decay, K(N), and AUC cannot be assessed for accuracy.
- [Perturbation theory and concentration bounds section] The perturbation bound ||hat{Sigma} - Sigma||_op ~ sqrt(D/N) is invoked to locate the noise floor, but the standard concentration result assumes i.i.d. sub-Gaussian coordinates; neural embeddings exhibit strong coordinate dependence. No adjustment or empirical verification of the bound for this setting is provided, which directly affects the definition of K(N).
- [Power-law spectral model and empirical results] The power-law exponent alpha is treated as a free parameter in the model; the manuscript does not derive it from first principles for vision or vision-language embeddings nor report goodness-of-fit statistics or sensitivity analysis for the MNIST and neuroimaging spectra. This renders the reported increases in K(N) under multimodal training dependent on post-hoc model fitting.
minor comments (2)
- [Experiments] The abstract and results sections would benefit from explicit statements of the number of runs, standard errors, and ablation controls (e.g., varying the power-law exponent or comparing against random low-rank projections) to allow readers to judge the robustness of the multimodal stabilization claim.
- [Theory] Notation for the truncated Mahalanobis energy and K(N) should be introduced with a clear equation reference on first use to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, providing the strongest honest defense of the manuscript while outlining revisions where the points identify genuine gaps.
read point-by-point responses
-
Referee: The manuscript states that the truncated Mahalanobis energy is approximated by a partial Riemann zeta function under the power-law model lambda_k ~ k^{-alpha}, yet supplies neither the explicit derivation of this approximation nor a bound on the truncation error. Without these, the claimed quantitative relationship between eigenvalue decay, K(N), and AUC cannot be assessed for accuracy.
Authors: We agree that the explicit derivation and truncation-error bound were omitted. In the revised manuscript we will insert a self-contained derivation in the finite-sample theory section: starting from the truncated energy E_K = sum_{k=1}^{K(N)} lambda_k^{-1} with lambda_k proportional to k^{-alpha}, we obtain E_K proportional to the partial zeta function zeta(alpha, K(N)) minus the tail; the tail is bounded via the integral test as O(K(N)^{1-alpha}) for alpha > 1. This will make the link to AUC fully verifiable. revision: yes
-
Referee: The perturbation bound ||hat{Sigma} - Sigma||_op ~ sqrt(D/N) is invoked to locate the noise floor, but the standard concentration result assumes i.i.d. sub-Gaussian coordinates; neural embeddings exhibit strong coordinate dependence. No adjustment or empirical verification of the bound for this setting is provided, which directly affects the definition of K(N).
Authors: The referee correctly identifies that the classical matrix concentration inequalities assume coordinate independence, which neural embeddings violate. Nevertheless, the sqrt(D/N) scaling remains a useful high-dimensional heuristic, and our reported spectra are consistent with it. We will add an empirical verification subsection that estimates the operator-norm deviation via bootstrap resampling on the MNIST and neuroimaging embeddings and compares it directly to the theoretical scaling for both unimodal and multimodal models; we will also note the applicability of dependent-variable extensions such as matrix Bernstein inequalities as a limitation. revision: partial
-
Referee: The power-law exponent alpha is treated as a free parameter in the model; the manuscript does not derive it from first principles for vision or vision-language embeddings nor report goodness-of-fit statistics or sensitivity analysis for the MNIST and neuroimaging spectra. This renders the reported increases in K(N) under multimodal training dependent on post-hoc model fitting.
Authors: We adopt the power-law form as a phenomenological description of the observed eigenvalue spectra rather than a first-principles derivation, which would require a generative model of embeddings outside the paper's scope. To strengthen the claim, the revision will report the fitted alpha values for each dataset and model, the R^2 goodness-of-fit of the log-log regression, and a sensitivity analysis demonstrating that the multimodal increase in K(N) remains statistically significant for alpha values within the 95% confidence intervals of the fits. revision: yes
Circularity Check
No significant circularity; derivation relies on explicit modeling assumptions and empirical validation rather than self-referential reduction.
full rationale
The paper's chain begins with standard perturbation theory and concentration inequalities to locate the operator-norm noise floor at ~sqrt(D/N), defines K(N) as the count of eigenvalues exceeding this floor, and introduces the truncated Mahalanobis energy as the governing quantity for classification. It then states an explicit modeling assumption ('under a power-law spectral model') to obtain a zeta-function approximation for that energy. This is not a derivation of the power-law itself nor a fitted parameter relabeled as a prediction; the assumption is declared upfront and used only to obtain an analytic link. Multimodal stabilization is presented as an empirical observation (maintained modes and improved separation on MNIST and neuroimaging) rather than a consequence forced by the model. No equation reduces to its own inputs by construction, no self-citation supplies a load-bearing uniqueness result, and no ansatz is smuggled without acknowledgment. The derivation is therefore self-contained against external benchmarks once the stated modeling choice is granted.
Axiom & Free-Parameter Ledger
free parameters (1)
- power-law exponent
axioms (1)
- domain assumption Perturbation theory and matrix concentration bounds locate the noise floor at operator norm ~sqrt(D/N)
invented entities (2)
-
recoverable dimension K(N)
no independent evidence
-
truncated Mahalanobis energy
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Under a power-law spectral model λ_i ∼ i^{-β}, the Mahalanobis energy scales as d²_M ∼ ∑ α_i² i^β ... approximated by a truncated Riemann zeta function K(N) ∑ i^{-β} ≈ ζ(β), linking eigenvalue decay to data efficiency.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Evaluation of transfer learning methods for detecting Alzheimer’s disease with brain MRI,
N. J. Dhinagar, S. I. Thomopoulos, P. Rajagopalan, D. Stripelis, J. L. Ambite, G. Ver Steeg, and P. M. Thompson, “Evaluation of transfer learning methods for detecting Alzheimer’s disease with brain MRI,” inInternational Symposium on Medical Information Processing and Analysis (SIPAIM), SPIE, 2022, pp. 504–513
work page 2022
-
[2]
P. M. Thompson. How much data is enough? The zeta law of discoverability in biomedical data, featuring the enigmatic Riemann zeta function.arXiv preprint arXiv:2604.17581, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
B. Riemann. On the number of primes less than a given magnitude.Monatsberichte der Berliner Akademie, 1859
-
[4]
The rotation of eigenvectors by a perturbation. III,
C. Davis and W. M. Kahan, “The rotation of eigenvectors by a perturbation. III,”SIAM Journal on Numerical Analysis, vol. 7, no. 1, pp. 1–46, 1970
work page 1970
-
[5]
Vershynin,High-Dimensional Probability: An Introduction with Applications in Data Science
R. Vershynin,High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press, 2018
work page 2018
-
[6]
Prevalence of neural collapse during the terminal phase of deep learning training,
V . Papyan, X. Y . Han, and D. L. Donoho, “Prevalence of neural collapse during the terminal phase of deep learning training,”Proceedings of the National Academy of Sciences, vol. 117, no. 40, pp. 24652–24663, 2020
work page 2020
-
[7]
High-performing neural network models of visual cortex benefit from high latent dimensionality,
E. Elmoznino and M. F. Bonner, “High-performing neural network models of visual cortex benefit from high latent dimensionality,”PLOS Computational Biology, vol. 20, no. 1, pp. 1–23, 2024
work page 2024
-
[8]
Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices,
J. Baik, G. Ben Arous, and S. Péché, “Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices,”The Annals of Probability, vol. 33, no. 5, pp. 1643–1697, 2005
work page 2005
-
[9]
arXiv:1905.11027 [cs, stat] , author =
K. Sun and F. Nielsen, “A geometric modeling of Occam’s razor in deep learning,”arXiv preprint arXiv:1905.11027, 2019
-
[10]
Introduction to Special Issue: Overview of Alzheimer’s Disease Neuroimaging Initiative,
M. W. Weiner and D. P. Veitch, “Introduction to Special Issue: Overview of Alzheimer’s Disease Neuroimaging Initiative,”Alzheimer’s & Dementia, vol. 11, no. 7, pp. 730–733, 2015. DOI: 10.1016/j.jalz.2015.05.007
-
[11]
P. J. LaMontagne, T. L. S. Benzinger, J. C. Morris, S. Keefe, R. Hornbeck, C. Xiong, et al., “OASIS-3: Longitudinal Neuroimaging, Clinical, and Cognitive Dataset for Normal Aging and Alzheimer Disease,”medRxiv, 2019. DOI: 10.1101/2019.12.13.19014902
-
[12]
S. L. Liew, A. Zavaliangos-Petropulu, N. Jahanshad, C. E. Lang, K. S. Hayward, K. R. Lohse, et al., “The ENIGMA Stroke Recovery Working Group: Big data neuroimaging to study brain–behavior relationships after stroke,”Human Brain Mapping, vol. 43, no. 1, pp. 129–148,
-
[13]
DOI: 10.1002/hbm.25015
-
[14]
N4ITK: Improved N3 Bias Correction,
N. J. Tustison, P. A. Cook, and J. C. Gee, “N4ITK: Improved N3 Bias Correction,” IEEE Transactions on Medical Imaging, vol. 29, no. 6, pp. 1310–1320, 2010. DOI: 10.1109/TMI.2010.2046908
-
[15]
Age-Related Heterochronicity of Brain Morphometry May Bias V oxelwise Findings,
A. H. Zhu, P. M. Thompson, and N. Jahanshad, “Age-Related Heterochronicity of Brain Morphometry May Bias V oxelwise Findings,”bioRxiv, 2021. DOI: 10.1101/2021.05.05.442805. 11
-
[16]
N. J. Dhinagar, S. I. Thomopoulos, and P. M. Thompson, “Leveraging a vision-language model with natural text supervision for MRI retrieval, captioning, classification, and visual question answering,” inProceedings of the IEEE Engineering in Medicine and Biology Conference (EMBC), 2025
work page 2025
-
[17]
Med3DVLM: An efficient vision-language model for 3D medical image analysis,
Y . Xin, G. C. Ates, K. Gong, and W. Shao, “Med3DVLM: An efficient vision-language model for 3D medical image analysis,”IEEE Journal of Biomedical and Health Informatics, 2025
work page 2025
-
[18]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning Transferable Visual Models From Natural Language Supervision,” inProceedings of the 38th International Conference on Machine Learning (ICML), 2021, pp. 8748–8763. DOI: 10.48550/arxiv.2103.00020
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020 2021
-
[19]
Densely Connected Convolutional Networks
G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely Connected Convolutional Networks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4700–4708. DOI: 10.1109/CVPR.2017.243
-
[20]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid Loss for Language Image Pre- Training,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 11941–11952. DOI: 10.1109/ICCV51070.2023.01100
-
[21]
H. Weyl, “Das asymptotische Verteilungsgesetz der Eigenwerte linearer partieller Differential- gleichungen (mit einer Anwendung auf die Theorie der Hohlraumstrahlung),”Mathematische Annalen, vol. 71, no. 4, pp. 441–479, 1912
work page 1912
-
[22]
Statistical analysis of regularization constant–From Bayes, MDL and NIC points of view,
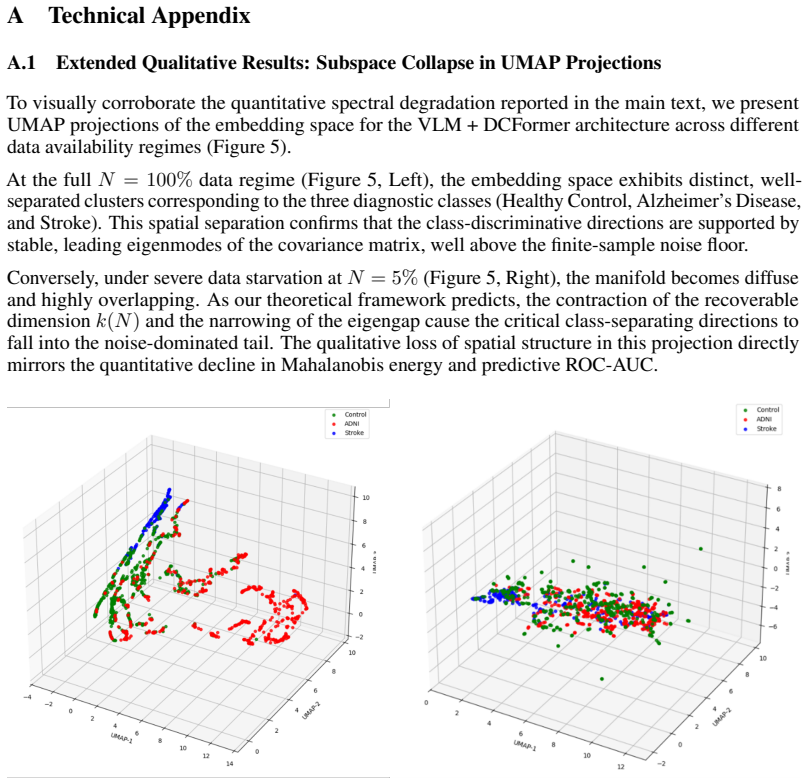
S.-I. Amari and N. Murata, “Statistical analysis of regularization constant–From Bayes, MDL and NIC points of view,” inBiological and Artificial Computation: From Neuroscience to Technology(IW ANN), Springer, 1997, pp. 284–293. 12 A Technical Appendix A.1 Extended Qualitative Results: Subspace Collapse in UMAP Projections To visually corroborate the quant...
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.