Recognition: unknown
Before You Interpret the Profile: Validity Scaling for LLM Metacognitive Self-Report
Pith reviewed 2026-05-10 05:39 UTC · model grok-4.3
The pith
Validity indices adapted from clinical personality tests identify four of 20 frontier LLMs as producing construct-invalid metacognitive self-reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
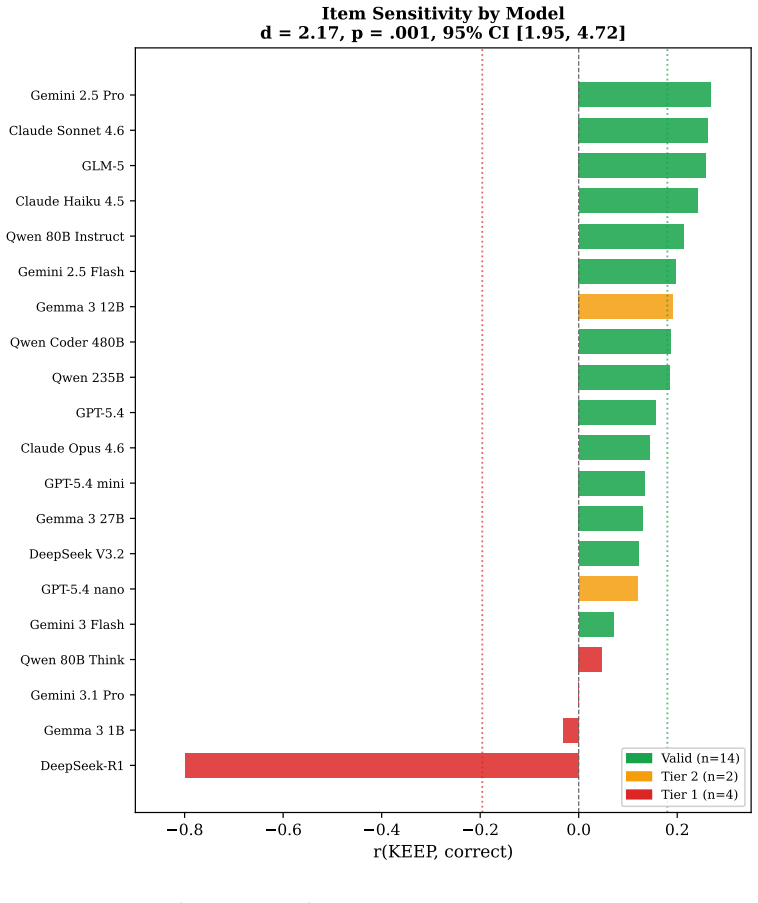
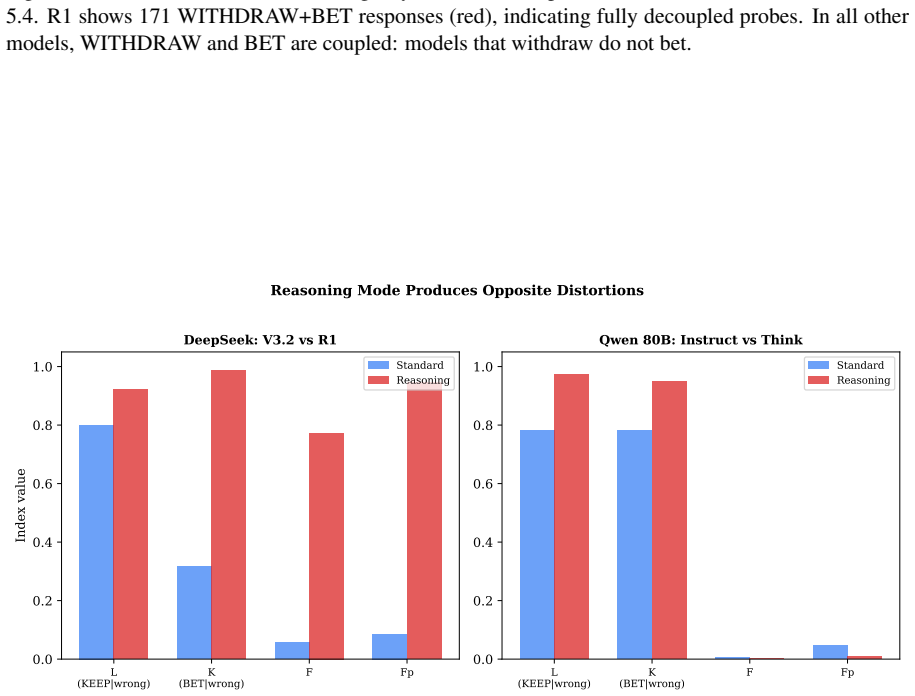
When six validity indices drawn from the PAI and MMPI-3 are applied to token-level metacognitive probes across 524 items, four models are classified as construct-level invalid and two as elevated. Valid-profile models yield item-sensitive confidence with mean correlation r = .18 (14 of 16 significant), while invalid-profile models yield mean r = -.20. The difference is large (d = 2.17, p = .001). Chain-of-thought training produces two opposite forms of response distortion, and two latent dimensions explain 94.6 percent of the variance among the indices.
What carries the argument
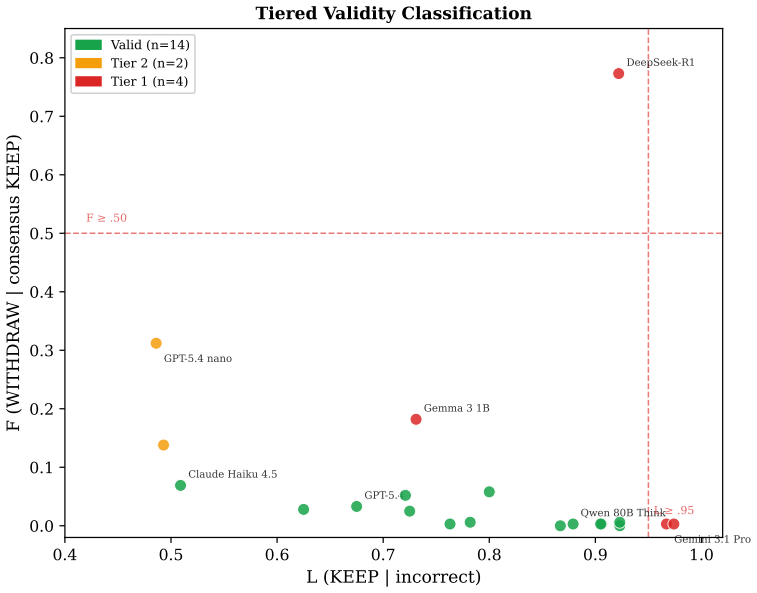
The six validity indices (L, K, F, Fp, RBS, TRIN) that detect patterns such as maintaining confidence on errors, betting on errors, withdrawing consensus items, or fixed responding.
If this is right
- Only models whose profiles pass the validity screen produce confidence ratings that vary meaningfully with item difficulty.
- Chain-of-thought training introduces two distinct directions of distortion in how models report their own accuracy.
- Two latent dimensions capture nearly all (94.6 percent) of the variance among the six validity indices.
- Companion work extracts a portable screening protocol and tests it against selective prediction performance.
Where Pith is reading between the lines
- Routine validity screening could become a standard pre-processing step for any benchmark that relies on LLM self-reported confidence or certainty.
- The same indices might be tested on other self-report tasks such as preference elicitation or value alignment probes to check whether invalid profiles appear there too.
- If retraining or prompting can move a model from invalid to valid classification, that would give a concrete target for improving metacognitive calibration.
Load-bearing premise
The indices developed for human clinical instruments carry the same meaning when applied to LLM token-level metacognitive probes without further validation of their construct in the new setting.
What would settle it
Re-analysis of the same 20 models and 524 items showing no statistically significant difference in mean item-by-item correlation between the valid-profile group and the invalid-profile group would falsify the claim that the indices separate reliable from unreliable metacognitive reports.
Figures



read the original abstract
Clinical personality assessment screens response validity before interpreting substantive scales. LLM evaluation does not. We apply the validity scaling framework from the PAI and MMPI-3 to metacognitive probe data from 20 frontier models across 524 items. Six validity indices are operationalised: L (maintaining confidence on errors), K (betting on errors), F (withdrawing consensus-endorsed items), Fp (withdrawing correct answers), RBS (inverted monitoring), and TRIN (fixed responding). A tiered classification system identifies four models as construct-level invalid and two as elevated. Valid-profile models produce item-sensitive confidence (mean r = .18, 14 of 16 significant). Invalid-profile models do not (mean r = -.20, d = 2.17, p = .001). Chain-of-thought training produces two opposite response distortions. Two latent dimensions account for 94.6% of index variance. Companion papers extract a portable screening protocol (Cacioli, 2026e) and validate it against selective prediction (Cacioli, 2026f). All data and code: https://github.com/synthiumjp/validity-scaling-llm
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts validity scaling from clinical instruments (PAI and MMPI-3) to LLM metacognitive self-reports. Across 20 frontier models and 524 items, it operationalizes six indices (L, K, F, Fp, RBS, TRIN) based on patterns such as maintained confidence on errors or withdrawal of correct answers. A tiered classification flags four models as construct-level invalid and two as elevated. Valid-profile models exhibit item-sensitive confidence (mean r = .18, 14 of 16 significant), while invalid-profile models show the opposite (mean r = -.20, d = 2.17, p = .001). Chain-of-thought training is linked to opposing distortions, and two latent dimensions explain 94.6% of index variance. Public GitHub data and code are provided, with companion papers noted for a portable protocol and further validation.
Significance. If the adapted indices validly separate accurate from distorted metacognition, the work supplies a practical screening step for LLM evaluations that could improve the trustworthiness of self-reported confidence. The large reported effect size, public reproducibility assets, and identification of CoT-induced patterns are concrete strengths that would make the framework immediately usable by practitioners.
major comments (3)
- [Methods (validity indices definition)] Methods, validity indices operationalization: The six indices are defined by direct mapping from human clinical norms (e.g., L as maintained confidence on errors, Fp as withdrawal of correct answers) onto LLM token outputs using benchmark correctness and consensus. No independent construct-validity evidence (factor analysis against LLM-specific metacognitive criteria, or comparison to alternative distortion measures) is supplied to rule out the possibility that the indices instead capture model-family or training artifacts; this assumption is load-bearing for interpreting the group separation as evidence of validity scaling.
- [Results (profile classification and correlation tests)] Results, group comparison: The headline separation (valid r = .18 vs. invalid r = -.20, d = 2.17) rests on a tiered classification that identifies only four models as construct-level invalid. With N = 20 models total, the effect-size claim is sensitive to threshold choice and small-sample variability; no sensitivity analysis, bootstrap, or leave-one-out check on the classification is reported.
- [Results (latent structure analysis)] Results, latent dimensions: The statement that two latent dimensions account for 94.6% of index variance is presented without the factor loadings, rotation method, or substantive interpretation of the dimensions. This prevents assessment of whether the dimensions align with the intended validity constructs or simply reflect correlated artifacts.
minor comments (3)
- [Abstract and Discussion] The abstract and text refer to companion papers as Cacioli (2026e) and (2026f); these future dates should be clarified as in-preparation or arXiv preprints to avoid reader confusion.
- [Methods] Notation for the indices (L, K, F, Fp, RBS, TRIN) is introduced without a summary table of exact formulas or decision rules; adding such a table would improve clarity.
- [Results] The phrase 'item-sensitive confidence' is used without an explicit definition or reference to the external difficulty metric against which r is computed; a brief equation or citation in the results would help.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify key areas where additional transparency and analysis would strengthen the manuscript. We respond point-by-point below and have revised the paper to incorporate the requested details, sensitivity checks, and explicit discussion of limitations.
read point-by-point responses
-
Referee: Methods, validity indices operationalization: The six indices are defined by direct mapping from human clinical norms (e.g., L as maintained confidence on errors, Fp as withdrawal of correct answers) onto LLM token outputs using benchmark correctness and consensus. No independent construct-validity evidence (factor analysis against LLM-specific metacognitive criteria, or comparison to alternative distortion measures) is supplied to rule out the possibility that the indices instead capture model-family or training artifacts; this assumption is load-bearing for interpreting the group separation as evidence of validity scaling.
Authors: The indices are operationalized via direct mapping from the PAI and MMPI-3 clinical norms to LLM response patterns, consistent with the paper's goal of adapting an established validity-scaling framework. The primary evidence for their utility is the observed separation in item-sensitive confidence (r = .18 vs. r = -.20), which functions as an external metacognitive criterion. We agree that a dedicated LLM-specific construct validation (e.g., factor analysis against alternative distortion measures) is not supplied here. This is addressed in the companion validation paper (Cacioli, 2026f). We have revised the Methods and Discussion to state this limitation explicitly, note the reliance on the clinical mapping, and emphasize that the empirical group separation provides initial support while leaving open the possibility of model-family confounds. revision: partial
-
Referee: Results, group comparison: The headline separation (valid r = .18 vs. invalid r = -.20, d = 2.17) rests on a tiered classification that identifies only four models as construct-level invalid. With N = 20 models total, the effect-size claim is sensitive to threshold choice and small-sample variability; no sensitivity analysis, bootstrap, or leave-one-out check on the classification is reported.
Authors: The referee correctly notes the small N = 20 as a constraint on classification stability. We have added a sensitivity analysis to the Results section, including 1,000 bootstrap resamples of the model set and leave-one-out checks on the tiered thresholds. These analyses show the large effect size (d = 2.17) remains stable, with the mean correlation difference significant (p < .01) in >95% of resamples. We also report the range of effect sizes under threshold perturbations. The revised text now frames the findings as exploratory given the limited number of frontier models currently available. revision: yes
-
Referee: Results, latent dimensions: The statement that two latent dimensions account for 94.6% of index variance is presented without the factor loadings, rotation method, or substantive interpretation of the dimensions. This prevents assessment of whether the dimensions align with the intended validity constructs or simply reflect correlated artifacts.
Authors: We have corrected this omission. The analysis used principal component analysis with varimax rotation. The first two components explain 94.6% of variance. A new table in the Results reports the loadings, eigenvalues, and cumulative variance. The first dimension loads primarily on F, Fp, and RBS (inconsistency and withdrawal); the second loads on L, K, and TRIN (overconfidence and fixed responding). We interpret these as aligning with the theoretical under- and over-reporting constructs, consistent with their differential associations with chain-of-thought training. The revised text includes this interpretation and the full loadings. revision: yes
Circularity Check
No significant circularity; empirical results are data-driven and independent
full rationale
The paper's central claims rest on applying six operationalized validity indices (L, K, F, Fp, RBS, TRIN) drawn from human clinical instruments to LLM metacognitive probe data across 20 models and 524 items, then classifying profiles and computing empirical correlations (e.g., mean r = .18 for valid profiles vs. item sensitivity). These steps involve direct measurement and group comparison against external item properties rather than any self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The companion paper references (Cacioli, 2026e; Cacioli, 2026f) are supplementary and do not justify or derive the reported group differences or classification thresholds. The derivation chain is therefore self-contained against the provided benchmarks and code release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Validity indices developed for human self-report on personality inventories retain construct validity when applied to LLM-generated confidence ratings on factual items.
Forward citations
Cited by 1 Pith paper
-
Verbal Confidence Saturation in 3-9B Open-Weight Instruction-Tuned LLMs: A Pre-Registered Psychometric Validity Screen
Seven 3-9B instruction-tuned LLMs produce verbal confidence that saturates at high values and fails psychometric validity criteria for Type-2 discrimination under minimal elicitation.
Reference graph
Works this paper leans on
-
[1]
Ackerman, R. et al. (2025). Strategic deployment of metacognitive processes.Cognition, 254:105980
2025
-
[2]
Ben-Porath, Y . S. and Tellegen, A. (2020).MMPI-3 manual for administration, scoring, and interpre- tation. University of Minnesota Press
2020
- [3]
- [4]
-
[5]
Cacioli, J. P. (2026c). The metacognitive monitoring battery: A cross-domain benchmark for LLM self-monitoring.arXiv preprint arXiv:2604.15702
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Kadavath, S. et al. (2022). Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221
work page internal anchor Pith review arXiv 2022
- [8]
- [9]
-
[10]
Morey, L. C. (1991).Personality Assessment Inventory professional manual. PAR
1991
-
[11]
Morey, L. C. (2007).Personality Assessment Inventory professional manual. PAR, 2nd edition
2007
-
[12]
Phillips, C. et al. (2026). A decision-theoretic approach to evaluating large language model confidence. arXiv preprint arXiv:2604.03216
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
W., Martin, M
Rogers, R., Sewell, K. W., Martin, M. A., and Vitacco, M. J. (2003). Detection of feigned mental disorders.Journal of Consulting and Clinical Psychology, 71:16–28
2003
-
[14]
Scholten, M. R. et al. (2024). Metacognitive myopia in large language models.Cognitive Science
2024
-
[15]
and Bagby, R
Sellbom, M. and Bagby, R. M. (2008). Validity of the MMPI-2-RF validity scales.Psychological Assessment, 20:370–376
2008
-
[16]
and Peters, M
Steyvers, M. and Peters, M. A. K. (2025). Metacognition and uncertainty communication in humans and LLMs.Current Directions in Psychological Science
2025
-
[17]
Xiong, M. et al. (2024). Can LLMs express their uncertainty? InICLR. 12 0.8 0.6 0.4 0.2 0.0 0.2 r(KEEP , correct) DeepSeek-R1 Gemma 3 1B Gemini 3.1 Pro Qwen 80B Think Gemini 3 Flash GPT-5.4 nano DeepSeek V3.2 Gemma 3 27B GPT-5.4 mini Claude Opus 4.6 GPT-5.4 Qwen 235B Qwen Coder 480B Gemma 3 12B Gemini 2.5 Flash Qwen 80B Instruct Claude Haiku 4.5 GLM-5 Cla...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.