Recognition: unknown
Verbal Confidence Saturation in 3-9B Open-Weight Instruction-Tuned LLMs: A Pre-Registered Psychometric Validity Screen
Pith reviewed 2026-05-08 12:04 UTC · model grok-4.3
The pith
Seven 3-9B instruction-tuned LLMs fail to produce valid verbal confidence ratings that discriminate correct from incorrect answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
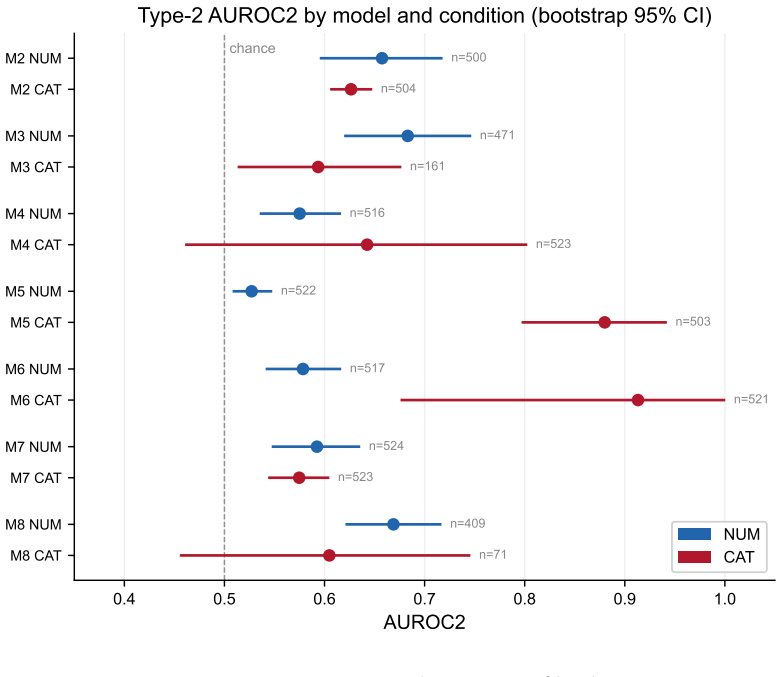
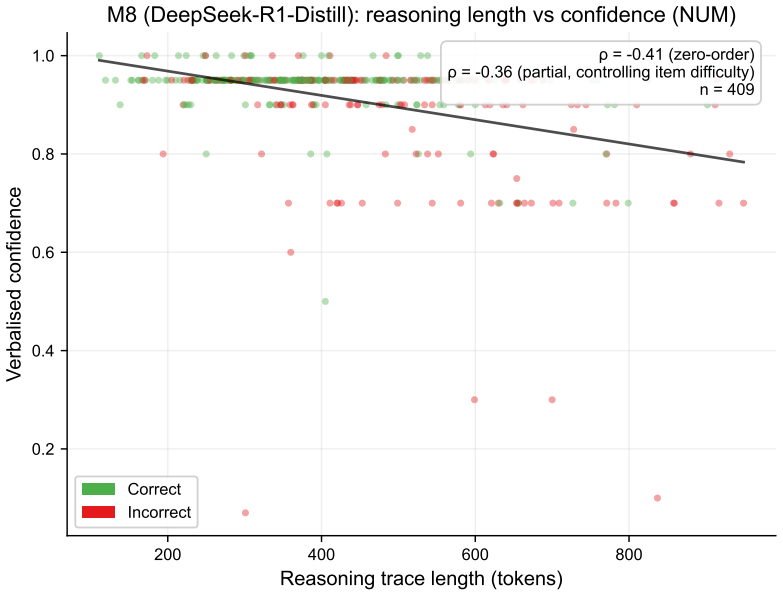
All seven instruction-tuned models were classified invalid on numeric confidence elicitation because of a mean ceiling rate of 91.7 percent, with categorical formats also failing to produce valid Type-2 discrimination and instead lowering task accuracy below 5 percent in six models. Token logprobabilities showed mean cross-validated R-squared below 0.01 when predicting verbal confidence, while reasoning-trace length in the distilled model correlated negatively with confidence at rho equal to -0.36.
What carries the argument
The pre-registered psychometric validity screen that checks for item-level Type-2 discrimination between correct and incorrect answers under numeric and categorical confidence formats.
If this is right
- Verbal confidence ratings from these models cannot be treated as reliable uncertainty estimates in applications without prior validity screening.
- Categorical confidence formats do not improve discrimination and can degrade overall task performance.
- Token logprobabilities do not serve as a useful proxy for verbalized confidence in high-variance output regimes.
- In reasoning-distilled models, longer reasoning traces are associated with lower verbal confidence ratings.
Where Pith is reading between the lines
- Non-verbal methods of extracting uncertainty may be required to access internal signals in models of this size.
- Confidence saturation may help explain why smaller LLMs produce overconfident errors in deployed settings.
- Repeating the screen on larger models or with varied decoding strategies could identify whether the failure is size-dependent.
Load-bearing premise
The chosen psychometric criteria for Type-2 discrimination, combined with numeric and categorical elicitation plus greedy decoding, are sufficient to detect whether internal uncertainty signals reach the verbal output.
What would settle it
A demonstration of statistically significant positive item-level correlations between verbal confidence ratings and answer accuracy in the same models, formats, and decoding conditions would falsify the invalidity result.
Figures

read the original abstract
Verbal confidence elicitation is widely used to extract uncertainty estimates from LLMs. We tested whether seven instruction-tuned open-weight models (3-9B parameters, four families) produce verbalised confidence that meets minimal validity criteria for item-level Type-2 discrimination under minimal numeric elicitation with greedy decoding. In a pre-registered study (OSF: osf.io/azbvx), 524 TriviaQA items were administered under numeric (0-100) and categorical (10-class) elicitation to eight models at Q5_K_M quantisation on consumer hardware, yielding 8,384 deterministic trials. A psychometric validity screen was applied to each model-format cell. All seven instruct models were classified Invalid on numeric confidence (H2 confirmed, 7/7 vs. predicted >=4/7), with a mean ceiling rate of 91.7% (H1 confirmed). Categorical elicitation did not rescue validity. Instead, it disrupted task performance in six of seven models, producing accuracy below 5% (H4 not confirmed). Token-level logprobability did not usefully predict verbalised confidence under the observed variance regime (H5 confirmed, mean cross-validated R^2 < 0.01). Within the reasoning-distilled model, reasoning-trace length showed a strong negative partial correlation with confidence (rho = -0.36, p < .001), consistent with the Reasoning Contamination Effect. These results do not imply that internal uncertainty representations are absent. They show that minimal verbal elicitation fails to preserve internal signals at the output interface in this model-size regime. Psychometric screening should precede any downstream use of such signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a pre-registered study (OSF: osf.io/azbvx) testing verbal confidence elicitation in seven 3-9B instruction-tuned open-weight LLMs across four families. Using 524 TriviaQA items under numeric (0-100) and categorical (10-class) formats with greedy decoding at Q5_K_M quantization (8,384 deterministic trials), the authors apply a psychometric validity screen for item-level Type-2 discrimination. All seven models are classified Invalid on numeric confidence (mean ceiling rate 91.7%), categorical elicitation disrupts accuracy below 5% in six models, token log-probabilities show near-zero predictive power (mean cross-validated R² < 0.01), and reasoning-trace length shows a negative partial correlation (rho = -0.36) with confidence in the reasoning-distilled model. The central claim is that minimal verbal elicitation fails to preserve internal uncertainty signals at the output interface, without implying absence of internal representations.
Significance. If the results hold, the work demonstrates that standard verbal confidence prompts do not meet basic metacognitive validity criteria in this model-size regime, with direct implications for uncertainty-aware applications of LLMs. Strengths include the pre-registered design, large deterministic trial count, explicit comparison to token log-probabilities, and the careful caveat distinguishing elicitation failure from internal representation absence. These elements provide falsifiable, non-circular support for the output-interface claim and support the recommendation for psychometric screening prior to downstream use.
major comments (1)
- The validity screen for item-level Type-2 discrimination (numeric and categorical formats) is load-bearing for the Invalid classification and the claim that signals are not preserved at the output interface. The manuscript should explicitly state the exact discrimination threshold, how it was pre-registered, and whether an ablation or simulation was performed to confirm the screen would detect preserved internal signals if present under greedy decoding.
minor comments (3)
- Abstract and results sections: specify which of the seven models is the 'reasoning-distilled model' when reporting the rho = -0.36 correlation with reasoning-trace length.
- Results for H5: report the exact mean cross-validated R² value and its range or standard deviation across the eight model-format cells rather than only the inequality < 0.01.
- Methods: clarify whether the 10-class categorical format used the same 0-100 numeric scale for scoring or a separate mapping, as this affects interpretation of the accuracy drop below 5%.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, recognition of the pre-registered design and other strengths, and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: The validity screen for item-level Type-2 discrimination (numeric and categorical formats) is load-bearing for the Invalid classification and the claim that signals are not preserved at the output interface. The manuscript should explicitly state the exact discrimination threshold, how it was pre-registered, and whether an ablation or simulation was performed to confirm the screen would detect preserved internal signals if present under greedy decoding.
Authors: We agree that the validity screen is central to the Invalid classification and the output-interface interpretation. The exact discrimination threshold is the pre-registered criterion for item-level Type-2 discrimination (a statistically significant positive association between verbal confidence and accuracy, with the precise statistical test and cutoff specified in the OSF protocol). We will revise the manuscript to state this threshold explicitly in the Methods section and to include a direct citation to the pre-registration (osf.io/azbvx). No ablation or simulation of the screen's sensitivity under hypothetical preserved signals and greedy decoding was performed, as the pre-registered protocol applied the screen directly to the empirical outputs of the tested models. The screen follows standard psychometric criteria for metacognitive sensitivity; the observed mean ceiling rate of 91.7% across models supplies indirect support for its appropriateness in this regime. We will add a brief note acknowledging the absence of such a simulation to the Limitations section. revision: partial
Circularity Check
No significant circularity: purely empirical pre-registered psychometric screen
full rationale
The paper reports a pre-registered empirical study (OSF: osf.io/azbvx) administering 524 TriviaQA items to seven LLMs under numeric and categorical confidence elicitation formats, applying standard psychometric validity criteria (item-level Type-2 discrimination) to classify models as Invalid or Valid. All claims rest on direct data outcomes such as 91.7% mean ceiling rate, accuracy drops below 5%, cross-validated R² < 0.01 with log-probabilities, and partial correlations, none of which are derived from or reduce to the paper's own definitions, fitted parameters, or self-citations. No mathematical derivation chain, ansatz, uniqueness theorem, or renaming of known results is present; the study is self-contained against external benchmarks and falsifiable hypotheses.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Psychometric validity for Type-2 discrimination requires above-chance accuracy in distinguishing correct from incorrect responses based on reported confidence.
- domain assumption Minimal verbal elicitation with greedy decoding is a fair test of whether internal uncertainty signals reach the output interface.
Forward citations
Cited by 1 Pith paper
-
Distilling Self-Consistency into Verbal Confidence: A Pre-Registered Negative Result and Post-Hoc Rescue on Gemma 3 4B
Fine-tuning Gemma 3 4B on unfiltered self-consistency targets produces a binary verbal correctness discriminator with AUROC 0.774 on TriviaQA, outperforming logit entropy after a modal-filtered pre-registration failed.
Reference graph
Works this paper leans on
-
[1]
Ben-Porath, Y. S. and Tellegen, A. (2020).MMPI-3: Manual for administration, scoring, and interpretation. University of Minnesota Press
2020
- [2]
- [3]
-
[4]
Cacioli, J. P. (2026c). The metacognitive monitoring battery: A cross-domain benchmark for LLM self-monitoring.arXiv:2604.15702
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Cacioli, J. P. (2026d). Before you interpret the profile: Validity scaling for LLM metacognitive self-report.arXiv:2604.17707
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Cacioli, J. P. (2026e). Screen before you interpret: A portable validity protocol for benchmark-based LLM confidence signals.arXiv:2604.17714
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Cacioli, J. P. (2026f). Concurrent criterion validation of a validity screen for LLM confidence signals via selective prediction.arXiv:2604.17716
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Cacioli, J. P. (2026g). AUROC2 is format-stable; M-ratio is not.arXiv:2604.08976. 9
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
-
[10]
S., and Zettlemoyer, L
Joshi, M., Choi, E., Weld, D. S., and Zettlemoyer, L. (2017). TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of ACL
2017
-
[11]
Kim, S. (2026). Knowing before speaking: In-computation metacognition precedes verbal confidence in large language models.Preprints.org, doi:10.20944/preprints202604.0078.v2
- [12]
-
[13]
Miao, N. and Ungar, L. (2026). Closing the confidence-faithfulness gap.arXiv:2603.25052
-
[14]
Morey, L. C. (1991).Personality Assessment Inventory professional manual. Psychological Assess- ment Resources
1991
-
[15]
(2021).Modern Psychometrics(4th ed.)
Rust, J., Kosinski, M., and Stillwell, D. (2021).Modern Psychometrics(4th ed.). Routledge
2021
-
[16]
Seo, J. et al. (2026). ADVICE: Answer-dependent verbalized confidence estimation. arXiv:2510.10913
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
and Peters, M
Steyvers, M. and Peters, M. A. K. (2025). Metacognition and uncertainty communication in humans and large language models.Current Directions in Psychological Science
2025
-
[18]
Steyvers, M., Belem, C., and Smyth, P. (2025). Calibration of LLM confidence. Manuscript
2025
- [19]
-
[20]
Wang, A. and Stengel-Eskin, E. (2026). Calibrating verbalized confidence with self-generated dis- tractors (DiNCo).arXiv:2509.25532
-
[21]
Xiong, M. et al. (2023). Can LLMs express their uncertainty?arXiv:2306.13063
work page internal anchor Pith review arXiv 2023
-
[22]
Yang, Z. (2024). Can LLMs express confidence? The impact of prompt and generation on verbalized confidence.arXiv:2412.14737
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.