Recognition: unknown
Evolutionary Negative Module Pruning for Better LoRA Merging
Pith reviewed 2026-05-10 05:13 UTC · model grok-4.3
The pith
Negative LoRA modules degrade merged performance and can be pruned with evolutionary search to achieve better results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The existence of negative modules -- specific LoRA layers that inherently degrade global performance upon merging -- is the central discovery. The paper shows that evolutionary search can effectively locate optimal pruning configurations in the discrete space of module choices, and that applying this pruning prior to merging consistently improves results over prior methods, reaching new state-of-the-art levels in language and vision domains.
What carries the argument
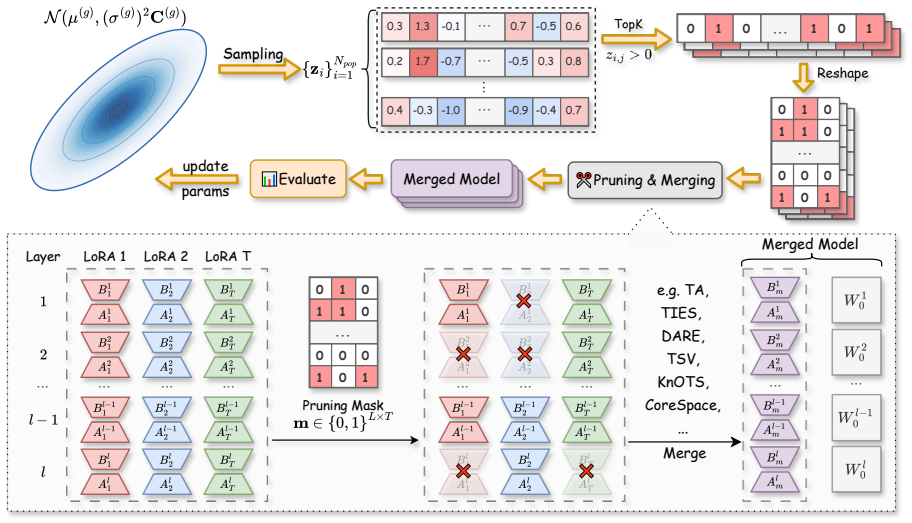
Evolutionary Negative Module Pruning (ENMP), a plug-and-play method that uses evolutionary search to identify and exclude detrimental LoRA modules before merging.
If this is right
- Existing merging algorithms such as weight interpolation or subspace alignment achieve higher accuracy when negative modules are removed first.
- The method delivers state-of-the-art merged model performance across both language and vision tasks.
- Pruning decisions found via evolution generalize within the tested setups without requiring retraining of the modules.
- Module selection becomes a searchable discrete problem rather than an all-or-nothing inclusion.
Where Pith is reading between the lines
- The approach implies that LoRA experts contain more redundant or conflicting information than previously modeled.
- Similar evolutionary pruning could be applied to other parameter-efficient methods beyond LoRA to improve merging.
- Future work might explore whether negative modules correlate with specific task types or layer positions in the network.
- Developers could integrate this pruning step into deployment pipelines for multi-task models to reduce interference automatically.
Load-bearing premise
Evolutionary search can accurately identify negative modules without losing essential task-specific knowledge or introducing bias from the search process itself.
What would settle it
If experiments on additional held-out task combinations show that the performance after ENMP pruning is no better than or worse than standard merging without pruning, the claimed benefit would be falsified.
Figures



read the original abstract
Merging multiple Low-Rank Adaptation (LoRA) experts into a single backbone is a promising approach for efficient multi-task deployment. While existing methods strive to alleviate interference via weight interpolation or subspace alignment, they rest upon the implicit assumption that all LoRA matrices contribute constructively to the merged model. In this paper, we uncover a critical bottleneck in current merging paradigms: the existence of $\textit{negative modules}$ -- specific LoRA layers that inherently degrade global performance upon merging. We propose $\textbf{E}$volutionary $\textbf{N}$egative $\textbf{M}$odule $\textbf{P}$runing ($\textbf{ENMP}$), a plug-and-play LoRA pruning method to locate and exclude these detrimental modules prior to merging. By leveraging an evolutionary search strategy, ENMP effectively navigates the discrete, non-differentiable landscape of module selection to identify optimal pruning configurations. Extensive evaluations demonstrate that ENMP consistently boosts the performance of existing merging algorithms, achieving a new state-of-the-art across both language and vision domains. Code is available at https://github.com/CaoAnda/ENMP-LoRAMerging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LoRA merging is limited by the existence of 'negative modules' (specific LoRA layers that degrade merged-model performance) and proposes Evolutionary Negative Module Pruning (ENMP), a plug-and-play evolutionary-search method to identify and prune them before merging. It reports that ENMP consistently improves existing merging algorithms and reaches new state-of-the-art results across language and vision benchmarks, with code released.
Significance. If the central claim holds, the work would be significant for efficient multi-task deployment: it challenges the implicit assumption that every LoRA module contributes positively and supplies a practical, search-based pruning step that can be inserted into existing pipelines. The public code release aids reproducibility and further testing.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Setup): the claim that ENMP isolates genuinely detrimental negative modules (rather than simply discovering high-performing discrete masks) rests on the untested assumption that evolutionary fitness on the evaluation distributions does not overfit to the reported test tasks. No ablation compares evolutionary selection against random pruning at identical ratios, greedy removal, or search performed on disjoint task splits; without these controls the performance lift cannot be attributed to the negative-module hypothesis.
- [§5] §5 (Results): the reported SOTA gains and consistent improvements lack error bars, full specification of evolutionary-search hyperparameters (population size, generations, mutation rate), and sensitivity analysis; the soundness of the central claim therefore remains partially opaque even though code is available.
- [§3] §3 (Method): the evolutionary fitness function is defined directly on downstream task metrics; this creates a circularity risk where the search optimizes the same quantities later used to claim superiority, rather than isolating a structural property of negative modules independent of the search procedure.
minor comments (2)
- [§3] Notation for LoRA modules and pruning masks could be introduced more formally with a single consistent symbol table.
- Figure captions should explicitly state the merging baselines and the exact pruning ratio used in each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important aspects for strengthening the paper's claims and reproducibility. We address each major comment point by point below and will incorporate revisions as indicated.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Setup): the claim that ENMP isolates genuinely detrimental negative modules (rather than simply discovering high-performing discrete masks) rests on the untested assumption that evolutionary fitness on the evaluation distributions does not overfit to the reported test tasks. No ablation compares evolutionary selection against random pruning at identical ratios, greedy removal, or search performed on disjoint task splits; without these controls the performance lift cannot be attributed to the negative-module hypothesis.
Authors: We agree that additional controls are required to more firmly attribute gains to the identification of negative modules rather than optimization of discrete masks. In the revised manuscript we will add ablations that compare ENMP against random pruning at identical ratios and against greedy removal. We will also perform the evolutionary search on disjoint validation splits (where task data permits) and report the resulting merged-model performance on held-out test sets. These experiments will be included in §4 and the appendix. While the current results already show consistent gains across multiple independent merging algorithms and both language and vision domains, we acknowledge that the proposed controls will provide stronger evidence for the negative-module hypothesis. revision: yes
-
Referee: [§5] §5 (Results): the reported SOTA gains and consistent improvements lack error bars, full specification of evolutionary-search hyperparameters (population size, generations, mutation rate), and sensitivity analysis; the soundness of the central claim therefore remains partially opaque even though code is available.
Authors: We accept this point on reproducibility. The revised §5 will report mean and standard deviation over at least three independent runs for all main results. We will also move the complete list of evolutionary-search hyperparameters (population size, generations, mutation rate, crossover rate, selection strategy, and early-stopping criteria) into the main text or a new appendix table. A sensitivity analysis subsection will be added showing performance variation when these hyperparameters are perturbed within reasonable ranges. These changes will make the experimental claims fully transparent. revision: yes
-
Referee: [§3] §3 (Method): the evolutionary fitness function is defined directly on downstream task metrics; this creates a circularity risk where the search optimizes the same quantities later used to claim superiority, rather than isolating a structural property of negative modules independent of the search procedure.
Authors: The fitness function is intentionally defined on the downstream metrics because the objective is to remove modules that degrade the merged model on those tasks. This design is not circular: the search occurs once, before any merging, and the final evaluation compares the pruned merged model against unpruned baselines on the same metrics. Nevertheless, we will revise §3 to explicitly articulate this rationale, to state that negative modules are defined operationally as those whose removal improves merged performance, and to add a short discussion of the design choice and its limitations. This clarification will distinguish ENMP from direct end-to-end optimization of the final model. revision: partial
Circularity Check
No circularity: empirical optimization method with external benchmarks
full rationale
The paper presents ENMP as a plug-and-play evolutionary search procedure applied to existing LoRA merging pipelines. No equations, derivations, or self-referential definitions are provided that reduce the reported performance gains to quantities fitted or defined by the method itself. The central claim rests on empirical comparisons against prior merging algorithms on language and vision benchmarks, with no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. The derivation chain is self-contained against external task metrics rather than internally forced.
Axiom & Free-Parameter Ledger
free parameters (1)
- evolutionary search hyperparameters
Reference graph
Works this paper leans on
-
[1]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Accurate and Efficient Low-Rank Model Merging in Core Space , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Ties-merging: Resolving interference when merging models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
European Conference on Computer Vision , pages=
Model breadcrumbs: Scaling multi-task model merging with sparse masks , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[4]
The Eleventh International Conference on Learning Representations , year=
Editing models with task arithmetic , author=. The Eleventh International Conference on Learning Representations , year=
-
[5]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Task singular vectors: Reducing task interference in model merging , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[6]
Forty-second International Conference on Machine Learning , year=
No Task Left Behind: Isotropic Model Merging with Common and Task-Specific Subspaces , author=. Forty-second International Conference on Machine Learning , year=
-
[7]
The Twelfth International Conference on Learning Representations , year=
Parameter-Efficient Multi-Task Model Fusion with Partial Linearization , author=. The Twelfth International Conference on Learning Representations , year=
-
[8]
Model merging with
George Stoica and Pratik Ramesh and Boglarka Ecsedi and Leshem Choshen and Judy Hoffman , booktitle=. Model merging with. 2025 , url=
2025
-
[9]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[10]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[11]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[12]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year=
2021
-
[13]
2016, arXiv e-prints, arXiv:1604.00772, doi: 10.48550/arXiv.1604.00772
The CMA evolution strategy: A tutorial , author=. arXiv preprint arXiv:1604.00772 , year=
-
[14]
Merging LoRAs like Playing LEGO: Pushing the Modularity of LoRA to Extremes Through Rank-Wise Clustering , author=
-
[15]
The Eleventh International Conference on Learning Representations , year=
Git Re-Basin: Merging Models modulo Permutation Symmetries , author=. The Eleventh International Conference on Learning Representations , year=
-
[16]
Forty-first International Conference on Machine Learning , year=
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch , author=. Forty-first International Conference on Machine Learning , year=
-
[17]
2025 , eprint=
Revisiting Weight Averaging for Model Merging , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[19]
Schelten and Amy Yang and Angela Fan and Anirudh Goyal and Anthony S
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and A. Schelten and Amy Yang and Angela Fan and Anirudh Goyal and Anthony S. Hartshorn and Aobo Yang and Archi Mitra and A. Sravankumar and A. Korenev and Arthur Hinsvark and Arun Rao and Aston Zhang and Aur'elien Rodriguez and A...
-
[20]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[21]
OpenAI and Josh Achiam and Steven Adler and Sandhini Agarwal and Lama Ahmad and Ilge Akkaya and Florencia Leoni Aleman and Diogo Almeida and Janko Altenschmidt and Sam Altman and Shyamal Anadkat and Red Avila and Igor Babuschkin and Suchir Balaji and Valerie Balcom and Paul Baltescu and Haiming Bao and Mohammad Bavarian and Jeff Belgum and Irwan Bello and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[23]
The Eleventh International Conference on Learning Representations , year=
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. The Eleventh International Conference on Learning Representations , year=
-
[24]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[25]
International Conference on Learning Representations , year=
Multitask Prompted Training Enables Zero-Shot Task Generalization , author=. International Conference on Learning Representations , year=
-
[26]
Dou, Shihan and Zhou, Enyu and Liu, Yan and Gao, Songyang and Shen, Wei and Xiong, Limao and Zhou, Yuhao and Wang, Xiao and Xi, Zhiheng and Fan, Xiaoran and Pu, Shiliang and Zhu, Jiang and Zheng, Rui and Gui, Tao and Zhang, Qi and Huang, Xuanjing. L o RAM o E : Alleviating World Knowledge Forgetting in Large Language Models via M o E -Style Plugin. Procee...
-
[27]
Mixture of Lo
Xun Wu and Shaohan Huang and Furu Wei , booktitle=. Mixture of Lo. 2024 , url=
2024
-
[28]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[29]
L ora R etriever: Input-Aware L o RA Retrieval and Composition for Mixed Tasks in the Wild
Zhao, Ziyu and Gan, Leilei and Wang, Guoyin and Zhou, Wangchunshu and Yang, Hongxia and Kuang, Kun and Wu, Fei. L ora R etriever: Input-Aware L o RA Retrieval and Composition for Mixed Tasks in the Wild. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.263
-
[30]
Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
A large annotated corpus for learning natural language inference , author=. Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
2015
-
[31]
Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long papers) , pages=
A broad-coverage challenge corpus for sentence understanding through inference , author=. Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long papers) , pages=
2018
-
[32]
A SICK cure for the evaluation of compositional distributional semantic models
Marelli, Marco and Menini, Stefano and Baroni, Marco and Bentivogli, Luisa and Bernardi, Raffaella and Zamparelli, Roberto. A SICK cure for the evaluation of compositional distributional semantic models. Proceedings of the Ninth International Conference on Language Resources and Evaluation ( LREC '14). 2014
2014
-
[33]
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel. GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP. 2018. doi:10.18653/v1/W18-5446
-
[34]
Proceedings of the AAAI conference on artificial intelligence , volume=
Scitail: A textual entailment dataset from science question answering , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[35]
Proceedings of the IEEE international conference on computer vision workshops , pages=
3d object representations for fine-grained categorization , author=. Proceedings of the IEEE international conference on computer vision workshops , pages=
-
[36]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Describing textures in the wild , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[37]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
2019
-
[38]
The 2011 international joint conference on neural networks , pages=
The German traffic sign recognition benchmark: a multi-class classification competition , author=. The 2011 international joint conference on neural networks , pages=. 2011 , organization=
2011
-
[39]
Proceedings of the IEEE , volume=
Remote sensing image scene classification: Benchmark and state of the art , author=. Proceedings of the IEEE , volume=. 2017 , publisher=
2017
-
[40]
International Journal of Computer Vision , volume=
Sun database: Exploring a large collection of scene categories , author=. International Journal of Computer Vision , volume=. 2016 , publisher=
2016
-
[41]
2011 , url=
Reading Digits in Natural Images with Unsupervised Feature Learning , author=. 2011 , url=
2011
-
[42]
LeCun, Yann and Cortes, Corinna , biburl =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.