Recognition: unknown
SPENCE: A Syntactic Probe for Detecting Contamination in NL2SQL Benchmarks
Pith reviewed 2026-05-10 04:37 UTC · model grok-4.3
The pith
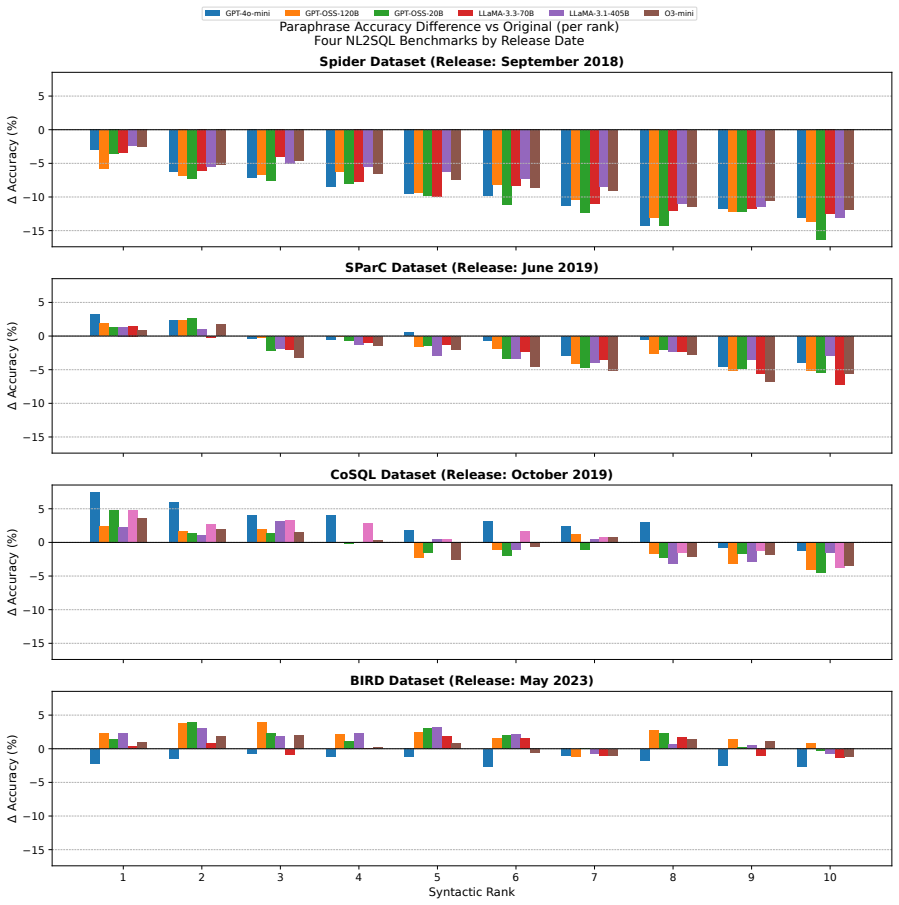
Syntactic probing reveals contamination in older NL2SQL benchmarks like Spider but not in newer ones like BIRD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
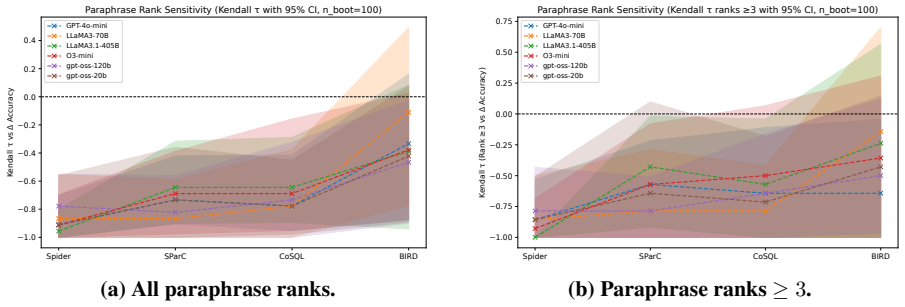
SPENCE generates syntactic variants of test queries and measures execution accuracy changes along with Kendall's tau rank sensitivity; when these robustness metrics are aligned with benchmark release dates, older datasets exhibit stronger negative trends indicating training leakage, while the recent BIRD dataset shows little sensitivity and appears uncontaminated.
What carries the argument
SPENCE framework that creates controlled syntactic variants of queries and quantifies model robustness via execution accuracy and rank correlation to detect contamination.
If this is right
- Older benchmarks such as Spider are more likely to have training leakage due to their strong negative robustness trends.
- Newer benchmarks like BIRD show minimal sensitivity, suggesting they are largely free of contamination.
- Execution-based scoring combined with syntactic divergence levels provides a reliable signal for contamination.
- Benchmark release dates serve as a useful indicator for the risk of data leakage in NL2SQL evaluation.
Where Pith is reading between the lines
- Similar syntactic probing could be used to check for contamination in other code generation or semantic parsing tasks.
- Future NL2SQL benchmarks should incorporate built-in variant testing to ensure they remain uncontaminated over time.
- Model training on diverse syntactic forms might reduce sensitivity even if some overlap exists.
Load-bearing premise
That performance drops on syntactically changed queries result from the original queries being absent from training data rather than from general challenges models face with syntactic variation.
What would settle it
Training a model exclusively on data released after the BIRD benchmark and observing no difference in sensitivity between BIRD and older benchmarks would contradict the contamination interpretation.
Figures






read the original abstract
Large language models (LLMs) have achieved strong performance on natural language to SQL (NL2SQL) benchmarks, yet their reported accuracy may be inflated by contamination from benchmark queries or structurally similar patterns seen during training. We introduce SPENCE (Syntactic Probing and Evaluation of NL2SQL Contamination Effects), a controlled syntactic probing framework for detecting and quantifying such contamination. SPENCE systematically generates syntactic variants of test queries for four widely used NL2SQL datasets-Spider, SParC, CoSQL, and the newer BIRD benchmark. We use SPENCE to evaluate multiple high-capacity LLMs under execution-based scoring. For each model, we measure changes in execution accuracy across increasing levels of syntactic divergence and quantify rank sensitivity using Kendall's tau with bootstrap confidence intervals. By aligning these robustness trends with benchmark release dates, we observe a clear temporal gradient: older benchmarks such as Spider exhibit the strongest negative values and thus the highest likelihood of training leakage, whereas the more recent BIRD dataset shows minimal sensitivity and appears largely uncontaminated. Together, these findings highlight the importance of temporally contextualized, syntactic-probing evaluation for trustworthy NL2SQL benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPENCE, a syntactic probing framework that generates syntactic variants of queries from four NL2SQL benchmarks (Spider, SParC, CoSQL, BIRD) and evaluates multiple LLMs using execution accuracy. It quantifies robustness via changes in accuracy across levels of syntactic divergence and Kendall's tau (with bootstrap CIs), then aligns the resulting negative correlations with benchmark release dates to claim a temporal gradient: older benchmarks exhibit stronger negative tau (indicating higher training leakage) while the recent BIRD benchmark shows minimal sensitivity and appears largely uncontaminated.
Significance. If the central claim holds after addressing confounds, SPENCE offers a useful controlled method for detecting potential contamination in NL2SQL benchmarks via syntactic divergence and rank correlation, which is valuable for improving trustworthy evaluation of LLMs. The framework's use of execution-based scoring rather than string matching and the inclusion of bootstrap confidence intervals for Kendall's tau are positive methodological features.
major comments (2)
- Abstract: The claim of a 'clear temporal gradient' in which older benchmarks like Spider show the 'strongest negative values' (highest contamination likelihood) while BIRD shows 'minimal sensitivity' rests on interpreting accuracy drops under syntactic divergence as evidence of training leakage. However, the abstract provides no description of how variants are generated, the number of divergence levels, statistical power, or controls ensuring semantic equivalence and comparable execution difficulty across datasets; without these, dataset-inherent differences (e.g., join count, nesting depth) could explain differential robustness independently of contamination.
- Abstract: The weakest assumption—that observed drops in execution accuracy on syntactically divergent variants are caused by absence from training data rather than general model difficulty with syntactic variation—is not isolated. No evidence is given that variants maintain equivalent difficulty or that the temporal correlation with release dates rules out other benchmark-specific factors, undermining the causal attribution to contamination.
minor comments (1)
- The abstract references 'bootstrap confidence intervals' for Kendall's tau but does not specify the number of bootstrap samples, the exact variant-generation procedure, or how many models and queries were tested, which affects reproducibility of the reported trends.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below, clarifying the methodology described in the full paper and making targeted revisions to strengthen the presentation of our claims and controls.
read point-by-point responses
-
Referee: Abstract: The claim of a 'clear temporal gradient' in which older benchmarks like Spider show the 'strongest negative values' (highest contamination likelihood) while BIRD shows 'minimal sensitivity' rests on interpreting accuracy drops under syntactic divergence as evidence of training leakage. However, the abstract provides no description of how variants are generated, the number of divergence levels, statistical power, or controls ensuring semantic equivalence and comparable execution difficulty across datasets; without these, dataset-inherent differences (e.g., join count, nesting depth) could explain differential robustness independently of contamination.
Authors: We agree the abstract is brief and omits key methodological details due to length constraints. The full manuscript (Section 3) specifies that SPENCE applies a fixed set of semantics-preserving syntactic transformations (e.g., join reordering, predicate restructuring, nesting adjustments) to produce variants at four discrete divergence levels, with semantic equivalence verified by identical execution results on the ground-truth databases. Statistical power is assessed via bootstrap confidence intervals on Kendall's tau. All four benchmarks are evaluated under identical models and protocols to reduce confounds from inherent differences such as join count or nesting depth. We have revised the abstract to include a concise description of variant generation, the number of levels, and the semantic-equivalence controls. revision: yes
-
Referee: Abstract: The weakest assumption—that observed drops in execution accuracy on syntactically divergent variants are caused by absence from training data rather than general model difficulty with syntactic variation—is not isolated. No evidence is given that variants maintain equivalent difficulty or that the temporal correlation with release dates rules out other benchmark-specific factors, undermining the causal attribution to contamination.
Authors: We acknowledge that fully isolating contamination from general syntactic difficulty is inherently challenging and that our evidence remains correlational. Variants are constructed to be semantically identical and executable on the same databases, with difficulty implicitly controlled by requiring exact execution matches; we further report consistent trends across multiple LLMs. The observed temporal gradient (stronger negative tau for older benchmarks) is presented as supporting evidence aligned with release dates rather than definitive causation. We have added a paragraph in the Discussion section explicitly noting that benchmark-specific factors (e.g., query complexity distributions) cannot be entirely excluded and that the results should be interpreted as a useful diagnostic probe rather than conclusive proof of leakage. revision: partial
Circularity Check
No circularity: measurements and correlations are independent of the contamination interpretation.
full rationale
The paper generates syntactic variants via SPENCE, evaluates LLMs with execution accuracy on external benchmarks (Spider, SParC, CoSQL, BIRD), computes Kendall's tau on divergence vs. accuracy drop, and aligns trends with release dates. No equations, fitted parameters, or self-citations reduce the reported temporal gradient or contamination likelihood to a quantity defined from the same data by construction. The derivation chain relies on independent inference runs and standard rank correlation; the interpretation linking sensitivity to leakage is an external inference, not a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Syntactic variants of a query preserve its intended semantics and produce equivalent execution results on the target database.
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL translation , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[2]
2024 , eprint=
ConStat: Performance-Based Contamination Detection in Large Language Models , author=. 2024 , eprint=
2024
-
[3]
SP ar C : Cross-Domain Semantic Parsing in Context
Yu, Tao and Zhang, Rui and Yasunaga, Michihiro and Tan, Yi Chern and Lin, Xi Victoria and Li, Suyi and Er, Heyang and Li, Irene and Pang, Bo and Chen, Tao and Ji, Emily and Dixit, Shreya and Proctor, David and Shim, Sungrok and Kraft, Jonathan and Zhang, Vincent and Xiong, Caiming and Socher, Richard and Radev, Dragomir. SP ar C : Cross-Domain Semantic Pa...
-
[4]
Yu, Tao and Zhang, Rui and Er, Heyang and Li, Suyi and Xue, Eric and Pang, Bo and Lin, Xi Victoria and Tan, Yi Chern and Shi, Tianze and Li, Zihan and Jiang, Youxuan and Yasunaga, Michihiro and Shim, Sungrok and Chen, Tao and Fabbri, Alexander and Li, Zifan and Chen, Luyao and Zhang, Yuwen and Dixit, Shreya and Zhang, Vincent and Xiong, Caiming and Socher...
-
[5]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Investigating Data Contamination in Modern Benchmarks for Large Language Models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[6]
arXiv preprint arXiv:2311.06233 , year =
Golchin, Shahriar and Surdeanu, Mihai , title =. arXiv preprint arXiv:2311.06233 , year =. doi:10.48550/arXiv.2311.06233 , abstract =
-
[7]
2024 , eprint=
Time Travel in LLMs: Tracing Data Contamination in Large Language Models , author=. 2024 , eprint=
2024
-
[8]
arXiv preprint arXiv:2310.17589 , year =
Li, Yucheng , title =. arXiv preprint arXiv:2310.17589 , year =. doi:10.48550/arXiv.2310.17589 , abstract =
-
[9]
Membership Inference Attacks against Language Models via Neighbourhood Comparison , booktitle =
Mattern, Justus and Mireshghallah, Fatemehsadat and Jin, Zhijing and Sch. Membership Inference Attacks against Language Models via Neighbourhood Comparison , booktitle =. 2023 , doi =
2023
-
[10]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and et al. , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[11]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and et al. , title =. arXiv preprint arXiv:2307.09288 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Oren, Yonatan and Meister, Nicole and Chatterji, Niladri S. and Ladhak, Faisal and Hashimoto, Tatsunori B. , title =. arXiv preprint arXiv:2310.17623 , year =. doi:10.48550/arXiv.2310.17623 , abstract =
-
[13]
2023 , howpublished =
Shi, Weijia , title =. 2023 , howpublished =
2023
-
[14]
Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
Shi, Weijia and Ajith, Anirudh and Xia, Mengzhou and Huang, Yangsibo and Liu, Daogao and Blevins, Terra and Chen, Danqi and Zettlemoyer, Luke , title =. arXiv preprint arXiv:2310.16789 , year =. doi:10.48550/arXiv.2310.16789 , abstract =
-
[15]
Xu, Ruijie and Wang, Zengzhi and Fan, Run-Ze and Liu, Pengfei , title =. arXiv preprint arXiv:2404.18824 , year =
-
[16]
Li, Haoyang and Zhang, Jing and Liu, Hanbing and Fan, Ju and Zhang, Xiaokang and Zhu, Jun and Wei, Renjie and Pan, Hongyan and Li, Cuiping and Chen, Hong , title =. Proc. ACM Manag. Data , month = may, articleno =. 2024 , issue_date =. doi:10.1145/3654930 , abstract =
-
[17]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[18]
CoRR , volume =
Victor Zhong and Caiming Xiong and Richard Socher , title =. CoRR , volume =
-
[19]
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-
Fangyu Lei and Jixuan Chen and Yuxiao Ye and Ruisheng Cao and Dongchan Shin and Hongjin SU and ZHAOQING SUO and Hongcheng Gao and Wenjing Hu and Pengcheng Yin and Victor Zhong and Caiming Xiong and Ruoxi Sun and Qian Liu and Sida Wang and Tao Yu , booktitle=. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-. 2025 , url=
2025
-
[20]
SQL -to-Text Generation with Graph-to-Sequence Model
Xu, Kun and Wu, Lingfei and Wang, Zhiguo and Feng, Yansong and Sheinin, Vadim. SQL -to-Text Generation with Graph-to-Sequence Model. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1112
-
[21]
Tao Yu and Chien-Sheng Wu and Xi Victoria Lin and bailin wang and Yi Chern Tan and Xinyi Yang and Dragomir Radev and richard socher and Caiming Xiong , booktitle=. Gra. 2021 , url=
2021
-
[22]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Torsten Scholak and Nathan Schucher and Dzmitry Bahdanau , title = ". Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021
2021
-
[24]
2017 , publisher=
spaCy: Industrial-strength Natural Language Processing in Python , author=. 2017 , publisher=
2017
-
[25]
Towards Complex Text-to- SQL in Cross-Domain Database with Intermediate Representation
Guo, Jiaqi and Zhan, Zecheng and Gao, Yan and Xiao, Yan and Lou, Jian-Guang and Liu, Ting and Zhang, Dongmei. Towards Complex Text-to- SQL in Cross-Domain Database with Intermediate Representation. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1444
-
[26]
Representing Schema Structure with Graph Neural Networks for Text-to- SQL Parsing
Bogin, Ben and Berant, Jonathan and Gardner, Matt. Representing Schema Structure with Graph Neural Networks for Text-to- SQL Parsing. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1448
-
[27]
RAT-SQL : Relation-Aware Schema Encoding and Linking for Text-to- SQL Parsers
Wang, Bailin and Shin, Richard and Liu, Xiaodong and Polozov, Oleksandr and Richardson, Matthew. RAT-SQL : Relation-Aware Schema Encoding and Linking for Text-to- SQL Parsers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.677
-
[28]
S hadow GNN : Graph Projection Neural Network for Text-to- SQL Parser
Chen, Zhi and Chen, Lu and Zhao, Yanbin and Cao, Ruisheng and Xu, Zihan and Zhu, Su and Yu, Kai. S hadow GNN : Graph Projection Neural Network for Text-to- SQL Parser. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.441
-
[29]
LGESQL : Line Graph Enhanced Text-to- SQL Model with Mixed Local and Non-Local Relations
Cao, Ruisheng and Chen, Lu and Chen, Zhi and Zhao, Yanbin and Zhu, Su and Yu, Kai. LGESQL : Line Graph Enhanced Text-to- SQL Model with Mixed Local and Non-Local Relations. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Paper...
-
[30]
Re-examining the Role of Schema Linking in Text-to- SQL
Lei, Wenqiang and Wang, Weixin and Ma, Zhixin and Gan, Tian and Lu, Wei and Kan, Min-Yen and Chua, Tat-Seng. Re-examining the Role of Schema Linking in Text-to- SQL. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.564
-
[31]
and Xie, Jinxia and Huang, Pengsheng
Gan, Yujian and Chen, Xinyun and Huang, Qiuping and Purver, Matthew and Woodward, John R. and Xie, Jinxia and Huang, Pengsheng. Towards Robustness of Text-to- SQL Models against Synonym Substitution. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Proce...
-
[32]
Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-
Shuaichen Chang and Jun Wang and Mingwen Dong and Lin Pan and Henghui Zhu and Alexander Hanbo Li and Wuwei Lan and Sheng Zhang and Jiarong Jiang and Joseph Lilien and Steve Ash and William Yang Wang and Zhiguo Wang and Vittorio Castelli and Patrick Ng and Bing Xiang , booktitle=. Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-
-
[33]
and Huang, Fei and Cheng, Reynold and Li, Yongbin , title =
Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and Zhou, Xuanhe and Ma, Chenhao and Li, Guoliang and Chang, Kevin C.C. and Huang, Fei and Cheng, Reynold and Li, Yongbin , title =. Proceedings of the 37th International Conference on Neural Information Proce...
2023
-
[34]
Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval
Chen, Peter Baile and Zhang, Yi and Roth, Dan. Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.148
-
[35]
Cafarella, Çagatay Demiralp, and Michael Stonebraker
BEAVER: An Enterprise Benchmark for Text-to-SQL. arXiv e-prints , keywords =. doi:10.48550/arXiv.2409.02038 , archivePrefix =. 2409.02038 , primaryClass =
work page internal anchor Pith review doi:10.48550/arxiv.2409.02038
-
[36]
Know What I don ' t Know: Handling Ambiguous and Unknown Questions for Text-to- SQL
Wang, Bing and Gao, Yan and Li, Zhoujun and Lou, Jian-Guang. Know What I don ' t Know: Handling Ambiguous and Unknown Questions for Text-to- SQL. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.352
-
[37]
Benchmarking and Improving Text-to- SQL Generation under Ambiguity
Bhaskar, Adithya and Tomar, Tushar and Sathe, Ashutosh and Sarawagi, Sunita. Benchmarking and Improving Text-to- SQL Generation under Ambiguity. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.436
-
[38]
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and Zhang, Zilin and Radev, Dragomir. S pider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to- SQL Task. Proceedings of the 2018 Conference on Empirical...
-
[39]
Advances in Neural Information Processing Systems , volume=
Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
ATHENA++: natural language querying for complex nested SQL queries , year =
Sen, Jaydeep and Lei, Chuan and Quamar, Abdul and \". ATHENA++: natural language querying for complex nested SQL queries , year =. Proc. VLDB Endow. , month = jul, pages =. doi:10.14778/3407790.3407858 , abstract =
-
[41]
Transactions of the Association for Computational Linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[42]
arXiv preprint arXiv:2309.12871 , url=
AnglE-optimized Text Embeddings , author=. arXiv preprint arXiv:2309.12871 , year=
-
[43]
2023 , eprint=
UNITE: A Unified Benchmark for Text-to-SQL Evaluation , author=. 2023 , eprint=
2023
-
[44]
Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021) , pages=
Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data , author=. Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021) , pages=
2021
-
[45]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Semantic evaluation for text-to-SQL with distilled test suites , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[46]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Re-examining the Role of Schema Linking in Text-to-SQL , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[47]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Towards general text embeddings with multi-stage contrastive learning , author=. arXiv preprint arXiv:2308.03281 , year=
work page internal anchor Pith review arXiv
-
[48]
Achiam et al. , title = ". arXiv e-prints , keywords =. doi:10.48550/arXiv.2303.08774 , archivePrefix =. 2303.08774 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[49]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
International Conference on Machine Learning , pages=
Large language models struggle to learn long-tail knowledge , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[51]
K aggle DBQA : Realistic Evaluation of Text-to- SQL Parsers
Lee, Chia-Hsuan and Polozov, Oleksandr and Richardson, Matthew. K aggle DBQA : Realistic Evaluation of Text-to- SQL Parsers. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.176
-
[52]
Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval
Chen, Peter Baile and Zhang, Yi and Roth, Dan. Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[53]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , url = "https://arxiv.org/abs/2407.21783v2", year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Gao, Dawei and Wang, Haibin and Li, Yaliang and Sun, Xiuyu and Qian, Yichen and Ding, Bolin and Zhou, Jingren , title =. Proc. VLDB Endow. , month =. 2024 , issue_date =. doi:10.14778/3641204.3641221 , abstract =
-
[55]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[56]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[57]
2025 , eprint=
Recent Advances in Large Langauge Model Benchmarks against Data Contamination: From Static to Dynamic Evaluation , author=. 2025 , eprint=
2025
-
[58]
2025 , eprint=
A Survey on Data Contamination for Large Language Models , author=. 2025 , eprint=
2025
-
[59]
2025 , eprint=
A Comprehensive Survey of Contamination Detection Methods in Large Language Models , author=. 2025 , eprint=
2025
-
[60]
2024 , eprint=
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author=. 2024 , eprint=
2024
-
[61]
Singh, Jyotika , year =. Natural Language Processing in the Real World: Text Processing, Analytics, and Classification , ISBN =. doi:10.1201/9781003264774 , publisher =
-
[62]
Singh, Jyotika and Sun, Weiyi and Agarwal, Amit and Krishnamurthy, Viji and Benajiba, Yassine and Ravi, Sujith and Roth, Dan. Can LLM s Narrate Tabular Data? An Evaluation Framework for Natural Language Representations of Text-to- SQL System Outputs. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. 20...
-
[63]
2024 , month = jul, note =
OpenAI , title =. 2024 , month = jul, note =
2024
-
[64]
2025 , month = jan, note =
OpenAI , title =. 2025 , month = jan, note =
2025
-
[65]
2025 , month = aug, note =
OpenAI , title =. 2025 , month = aug, note =
2025
-
[66]
SIAM Journal on Computing , volume=
Simple fast algorithms for the editing distance between trees and related problems , author=. SIAM Journal on Computing , volume=. 1989 , publisher=
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.