Recognition: unknown
Weakly-Supervised Referring Video Object Segmentation through Text Supervision
Pith reviewed 2026-05-10 05:50 UTC · model grok-4.3
The pith
Referring video object segmentation models can be trained using only text expressions as supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
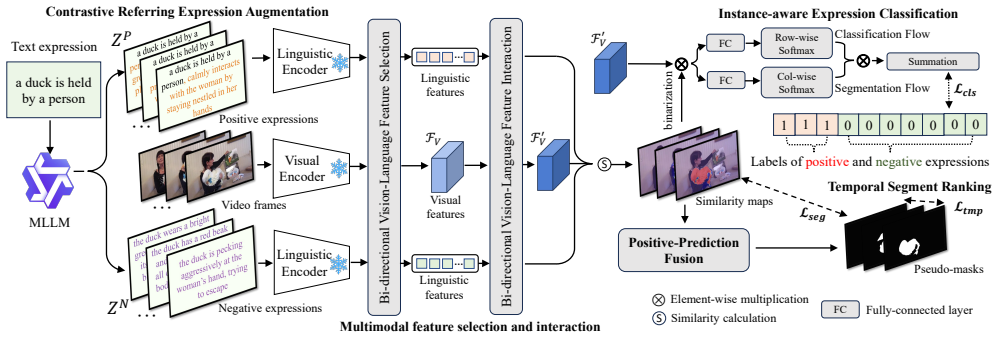
The authors establish that their WSRVOS framework trains referring video object segmentation models using only text expressions by first applying contrastive referring expression augmentation with a multimodal large language model to create positive and negative variants, then performing bi-directional vision-language feature selection and interaction for fine-grained alignment, applying instance-aware expression classification to separate positive from negative cases, generating high-quality pseudo-masks via positive-prediction fusion as additional supervision, and imposing a temporal segment ranking constraint so that mask overlaps between neighboring frames follow specific orders, which,
What carries the argument
The WSRVOS pipeline that augments text expressions contrastively with a multimodal large language model, aligns features bidirectionally, classifies expressions instance-by-instance, fuses positive predictions into pseudo-masks, and enforces temporal ranking on segments.
If this is right
- The model achieves competitive or superior results on A2D Sentences, J-HMDB Sentences, Ref-YouTube-VOS, and Ref-DAVIS17 without requiring mask annotations.
- Pseudo-masks from fused positive predictions supply effective extra supervision during training.
- The temporal segment ranking constraint maintains consistent object segmentation across neighboring video frames.
- Instance-aware expression classification improves the model's ability to identify the correct referring text among distractors.
Where Pith is reading between the lines
- If multimodal language models continue to improve, the quality of generated expressions and pseudo-masks could approach that of full supervision.
- The text-only training approach could extend to other video understanding tasks that currently depend on dense annotations.
- Lower annotation costs might allow construction of much larger training sets for language-guided video models.
- The method's reliance on generated expressions opens the possibility of handling referring expressions that were never seen during initial data collection.
Load-bearing premise
The multimodal large language model generates sufficiently accurate positive and negative expressions and the positive-prediction fusion produces reliable pseudo-masks that can substitute for ground-truth annotations without introducing systematic errors.
What would settle it
Measuring that the generated pseudo-masks on Ref-YouTube-VOS show systematically lower overlap with true object boundaries than the final model predictions, or that overall performance falls below prior box-supervised methods, would indicate the text-only supervision does not hold.
Figures


read the original abstract
Referring video object segmentation (RVOS) aims to segment the target instance in a video, referred by a text expression. Conventional approaches are mostly supervised learning, requiring expensive pixel-level mask annotations. To tackle it, weakly-supervised RVOS has recently been proposed to replace mask annotations with bounding boxes or points, which are however still costly and labor-intensive. In this paper, we design a novel weakly-supervised RVOS method, namely WSRVOS, to train the model with only text expressions. Given an input video and the referring expression, we first design a contrastive referring expression augmentation scheme that leverages the captioning capabilities of a multimodal large language model to generate both positive and negative expressions. We extract visual and linguistic features from the input video and generated expressions, then perform bi-directional vision-language feature selection and interaction to enable fine-grained multimodal alignment. Next, we propose an instance-aware expression classification scheme to optimize the model in distinguishing positive from negative expressions. Also, we introduce a positive-prediction fusion strategy to generate high-quality pseudo-masks, which serve as additional supervision to the model. Last, we design a temporal segment ranking constraint such that the overlaps between mask predictions of temporally neighboring frames are required to conform to specific orders. Extensive experiments on four publicly available RVOS datasets, including A2D Sentences, J-HMDB Sentences, Ref-YouTube-VOS, and Ref-DAVIS17, demonstrate the superiority of our method. Code is available at https://github.com/viscom-tongji/WSRVOS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents WSRVOS, a novel weakly-supervised method for referring video object segmentation (RVOS) that trains models using only text expressions instead of pixel-level masks. The approach involves contrastive referring expression augmentation using a multimodal large language model to create positive and negative expressions, bi-directional vision-language feature selection and interaction, instance-aware expression classification, positive-prediction fusion to generate pseudo-masks, and a temporal segment ranking constraint. Experiments on A2D Sentences, J-HMDB Sentences, Ref-YouTube-VOS, and Ref-DAVIS17 are said to show superiority over existing methods.
Significance. If the results hold, this could be significant for reducing the annotation burden in RVOS tasks, as text expressions are cheaper to obtain than masks. The integration of MLLMs for data augmentation and the fusion strategy for pseudo-labeling are potentially impactful contributions to weakly-supervised video segmentation. However, the significance depends on rigorous validation of the pseudo-supervision quality, which is not detailed in the provided abstract.
major comments (3)
- The positive-prediction fusion strategy is presented as generating high-quality pseudo-masks, but no quantitative metrics (e.g., IoU or Dice score against ground-truth) are reported to validate their fidelity. This is critical because any systematic error in the pseudo-masks could lead to the model learning incorrect alignments, undermining the weakly-supervised claim.
- The superiority is demonstrated on four datasets, but there is no ablation study or error analysis quantifying the impact of MLLM-generated expressions or the fusion step. Without this, it is unclear if the performance gains are due to the proposed components or other factors.
- The abstract claims 'high-quality pseudo-masks' but provides no supporting evidence or reference to tables/figures showing pseudo-mask quality, which is a load-bearing assumption for the entire approach.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional validation and analysis are needed to strengthen the claims regarding pseudo-mask quality and component contributions. We will revise the manuscript accordingly and address each major comment below.
read point-by-point responses
-
Referee: The positive-prediction fusion strategy is presented as generating high-quality pseudo-masks, but no quantitative metrics (e.g., IoU or Dice score against ground-truth) are reported to validate their fidelity. This is critical because any systematic error in the pseudo-masks could lead to the model learning incorrect alignments, undermining the weakly-supervised claim.
Authors: We acknowledge the importance of directly quantifying pseudo-mask fidelity. The current manuscript emphasizes end-to-end RVOS performance, but we agree this leaves a gap in validating the pseudo-supervision. In the revised manuscript, we will add a dedicated analysis section with IoU and Dice scores of the generated pseudo-masks against ground-truth on A2D Sentences and Ref-YouTube-VOS (where masks are available). This will include both aggregate metrics and per-dataset breakdowns to demonstrate the quality and identify any systematic issues. revision: yes
-
Referee: The superiority is demonstrated on four datasets, but there is no ablation study or error analysis quantifying the impact of MLLM-generated expressions or the fusion step. Without this, it is unclear if the performance gains are due to the proposed components or other factors.
Authors: We agree that isolating the contributions of the contrastive MLLM augmentation and positive-prediction fusion is necessary. While the manuscript includes overall comparisons, it lacks targeted ablations for these elements. In the revision, we will expand the experiments with ablation tables measuring performance when disabling the MLLM expression generation (replacing with random or no augmentation) and when removing the fusion step (using only classification loss). We will also add error analysis on cases where MLLM expressions or fusion may introduce noise, such as ambiguous referring phrases. revision: yes
-
Referee: The abstract claims 'high-quality pseudo-masks' but provides no supporting evidence or reference to tables/figures showing pseudo-mask quality, which is a load-bearing assumption for the entire approach.
Authors: We will revise the abstract to qualify the claim, for example by stating that the fusion strategy generates pseudo-masks that enable effective weakly-supervised training, and explicitly reference the new quantitative metrics and qualitative figures that will be added to the experiments section. This ensures the abstract is supported by evidence in the revised paper. revision: yes
Circularity Check
No circularity: empirical pipeline relies on external MLLM and benchmarks
full rationale
The paper describes an engineering pipeline (contrastive augmentation via MLLM, bi-directional interaction, instance-aware classification, positive-prediction fusion for pseudo-masks, and temporal ranking) whose performance is measured on four external public datasets. No equations or first-principles claims are presented that reduce by construction to fitted parameters or self-citations; the pseudo-mask step is a standard self-training heuristic whose fidelity is not asserted as a derived theorem but left to empirical validation. The method is therefore self-contained against external data and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal large language models can reliably generate positive and negative referring expressions that are semantically aligned with video content.
- domain assumption High-quality pseudo-masks can be obtained by fusing the model's own positive predictions without introducing label noise that harms training.
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3,
work page internal anchor Pith review arXiv
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 1, 3, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
One token to seg them all: Language instructed reasoning seg- mentation in videos.Advances in Neural Information Pro- cessing Systems, 37:6833–6859, 2024
Zechen Bai, Tong He, Haiyang Mei, Pichao Wang, Ziteng Gao, Joya Chen, Zheng Zhang, and Mike Zheng Shou. One token to seg them all: Language instructed reasoning seg- mentation in videos.Advances in Neural Information Pro- cessing Systems, 37:6833–6859, 2024. 3
2024
-
[4]
A closer look at referring expressions for video object segmentation
Miriam Bellver, Carles Ventura, Carina Silberer, Ioannis Kazakos, Jordi Torres, and Xavier Giro-i Nieto. A closer look at referring expressions for video object segmentation. Multimedia Tools and Applications, 82(3):4419–4438, 2023. 1, 2
2023
-
[5]
Weakly supervised deep detection networks
Hakan Bilen and Andrea Vedaldi. Weakly supervised deep detection networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2846– 2854, 2016. 5
2016
-
[6]
End-to-end referring video object segmentation with multi- modal transformers
Adam Botach, Evgenii Zheltonozhskii, and Chaim Baskin. End-to-end referring video object segmentation with multi- modal transformers. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 4985–4995, 2022. 1, 2, 6, 7
2022
-
[7]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean confer- ence on computer vision, pages 213–229. Springer, 2020. 2
2020
-
[8]
Dvin: Dynamic visual routing network for weakly supervised referring expression comprehension
Xiaofu Chen, Yaxin Luo, Gen Luo, Jiayi Ji, Henghui Ding, and Yiyi Zhou. Dvin: Dynamic visual routing network for weakly supervised referring expression comprehension. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14347–14357, 2025. 6, 7, 2, 3
2025
-
[9]
Samwise: Infusing wisdom in sam2 for text-driven video segmentation
Claudia Cuttano, Gabriele Trivigno, Gabriele Rosi, Carlo Masone, and Giuseppe Averta. Samwise: Infusing wisdom in sam2 for text-driven video segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3395–3405, 2025. 2
2025
-
[10]
Curriculum point prompting for weakly-supervised referring image segmentation
Qiyuan Dai and Sibei Yang. Curriculum point prompting for weakly-supervised referring image segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13711–13722, 2024. 6, 7
2024
-
[11]
Solving the multiple instance problem with axis-parallel rectangles.Artificial intelligence, 89(1-2):31– 71, 1997
Thomas G Dietterich, Richard H Lathrop, and Tom ´as Lozano-P´erez. Solving the multiple instance problem with axis-parallel rectangles.Artificial intelligence, 89(1-2):31– 71, 1997. 2, 5
1997
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021. 1
2021
-
[13]
Scribble-supervised video object segmentation via scribble enhancement.IEEE Transactions on Circuits and Systems for Video Technology, 2025
Xingyu Gao, Zuolei Li, Hailong Shi, Zhenyu Chen, and Peilin Zhao. Scribble-supervised video object segmentation via scribble enhancement.IEEE Transactions on Circuits and Systems for Video Technology, 2025. 6, 7
2025
-
[14]
Actor and action video segmentation from a sentence
Kirill Gavrilyuk, Amir Ghodrati, Zhenyang Li, and Cees GM Snoek. Actor and action video segmentation from a sentence. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5958–5966, 2018. 1, 2, 6
2018
-
[15]
Box supervised video segmentation pro- posal network.arXiv preprint arXiv:2202.07025, 2022
Tanveer Hannan, Rajat Koner, Jonathan Kobold, and Matthias Schubert. Box supervised video segmentation pro- posal network.arXiv preprint arXiv:2202.07025, 2022. 6
-
[16]
Decoupling static and hier- archical motion perception for referring video segmentation
Shuting He and Henghui Ding. Decoupling static and hier- archical motion perception for referring video segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13332–13341, 2024. 6, 7
2024
-
[17]
Chat-univi: Unified visual representation em- powers large language models with image and video un- derstanding
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation em- powers large language models with image and video un- derstanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700– 13710, 2024. 3
2024
-
[18]
Video object segmentation with language referring expressions
Anna Khoreva, Anna Rohrbach, and Bernt Schiele. Video object segmentation with language referring expressions. In Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Re- vised Selected Papers, Part IV 14, pages 123–141. Springer,
2018
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 3
work page Pith review arXiv 2024
-
[20]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 1, 3
2023
-
[21]
Box-supervised instance seg- mentation with level set evolution
Wentong Li, Wenyu Liu, Jianke Zhu, Miaomiao Cui, Xian- Sheng Hua, and Lei Zhang. Box-supervised instance seg- mentation with level set evolution. InEuropean conference on computer vision, pages 1–18. Springer, 2022. 6
2022
-
[22]
Chen Liang, Yu Wu, Yawei Luo, and Yi Yang. Clawcranenet: Leveraging object-level relation for text-based video seg- mentation.arXiv preprint arXiv:2103.10702, 2021. 1
-
[23]
Chen Liang, Yu Wu, Tianfei Zhou, Wenguan Wang, Zongxin Yang, Yunchao Wei, and Yi Yang. Rethinking cross-modal interaction from a top-down perspective for referring video object segmentation.arXiv preprint arXiv:2106.01061,
-
[24]
Referdino: Referring video object segmentation with visual grounding founda- tions
Tianming Liang, Kun-Yu Lin, Chaolei Tan, Jianguo Zhang, Wei-Shi Zheng, and Jian-Fang Hu. Referdino: Referring video object segmentation with visual grounding founda- tions. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 20009–20019, 2025. 2, 6, 7
2025
-
[25]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024. 7
2024
-
[26]
Glus: Global-local reasoning unified into a single large lan- guage model for video segmentation
Lang Lin, Xueyang Yu, Ziqi Pang, and Yu-Xiong Wang. Glus: Global-local reasoning unified into a single large lan- guage model for video segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8658–8667, 2025. 3
2025
-
[27]
Referring image segmentation using text supervision
Fang Liu, Yuhao Liu, Yuqiu Kong, Ke Xu, Lihe Zhang, Bao- cai Yin, Gerhard Hancke, and Rynson Lau. Referring image segmentation using text supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22124–22134, 2023. 3, 6, 7
2023
-
[28]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 3
2023
-
[29]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettle- moyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[30]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 1
2021
-
[31]
Video swin transformer
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3202–3211, 2022. 6
2022
-
[32]
Soc: Semantic-assisted object cluster for referring video object segmentation.Advances in Neural Information Processing Systems, 36:26425–26437, 2023
Zhuoyan Luo, Yicheng Xiao, Yong Liu, Shuyan Li, Yi- tong Wang, Yansong Tang, Xiu Li, and Yujiu Yang. Soc: Semantic-assisted object cluster for referring video object segmentation.Advances in Neural Information Processing Systems, 36:26425–26437, 2023. 6, 7, 1
2023
-
[33]
Point-vos: Pointing up video object segmentation
Sabarinath Mahadevan, Idil Esen Zulfikar, Paul V oigtlaen- der, and Bastian Leibe. Point-vos: Pointing up video object segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22217– 22226, 2024. 6, 7
2024
-
[34]
Semantic and sequential alignment for referring video object segmentation
Feiyu Pan, Hao Fang, Fangkai Li, Yanyu Xu, Yawei Li, Luca Benini, and Xiankai Lu. Semantic and sequential alignment for referring video object segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19067–19076, 2025. 1
2025
-
[35]
Holistic correction with object prototype for video object segmentation
Shengye Qiao, Changqun Xia, Yanjie Liang, Gongjin Lan, and Jia Li. Holistic correction with object prototype for video object segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6586–6593, 2025. 6
2025
-
[36]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[37]
Urvos: Unified referring video object segmentation network with a large-scale benchmark
Seonguk Seo, Joon-Young Lee, and Bohyung Han. Urvos: Unified referring video object segmentation network with a large-scale benchmark. InEuropean conference on computer vision, pages 208–223. Springer, 2020. 2, 6, 1
2020
-
[38]
Boxinst: High-performance instance segmentation with box annotations
Zhi Tian, Chunhua Shen, Xinlong Wang, and Hao Chen. Boxinst: High-performance instance segmentation with box annotations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5443–5452,
-
[39]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[40]
Weakly supervised referring video object segmentation with object-centric pseudo-guidance.IEEE Transactions on Multimedia, 27:1320–1333, 2024
Weikang Wang, Yuting Su, Jing Liu, Wei Sun, and Guangtao Zhai. Weakly supervised referring video object segmentation with object-centric pseudo-guidance.IEEE Transactions on Multimedia, 27:1320–1333, 2024. 2, 3, 6, 7
2024
-
[41]
Internvideo2: Scaling foundation models for mul- timodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for mul- timodal video understanding. InEuropean Conference on Computer Vision, pages 396–416. Springer, 2024. 4
2024
-
[42]
Instructseg: Unifying instructed visual segmentation with multi-modal large lan- guage models
Cong Wei, Yujie Zhong, Haoxian Tan, Yingsen Zeng, Yong Liu, Hongfa Wang, and Yujiu Yang. Instructseg: Unifying instructed visual segmentation with multi-modal large lan- guage models. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 20193–20203,
-
[43]
Onlinerefer: A simple online baseline for referring video object segmentation
Dongming Wu, Tiancai Wang, Yuang Zhang, Xiangyu Zhang, and Jianbing Shen. Onlinerefer: A simple online baseline for referring video object segmentation. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 2761–2770, 2023. 2
2023
-
[44]
Language as queries for referring video object seg- mentation
Jiannan Wu, Yi Jiang, Peize Sun, Zehuan Yuan, and Ping Luo. Language as queries for referring video object seg- mentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4974– 4984, 2022. 1, 2, 6, 7
2022
-
[45]
Visa: Reasoning video object segmentation via large language models
Cilin Yan, Haochen Wang, Shilin Yan, Xiaolong Jiang, Yao Hu, Guoliang Kang, Weidi Xie, and Efstratios Gavves. Visa: Reasoning video object segmentation via large language models. InEuropean Conference on Computer Vision, pages 98–115. Springer, 2024. 3
2024
-
[46]
Actor and action modular network for text-based video segmentation.IEEE Transactions on Image Processing, 31:4474–4489, 2022
Jianhua Yang, Yan Huang, Kai Niu, Linjiang Huang, Zhanyu Ma, and Liang Wang. Actor and action modular network for text-based video segmentation.IEEE Transactions on Image Processing, 31:4474–4489, 2022. 1, 2
2022
-
[47]
Boosting weakly supervised referring im- age segmentation via progressive comprehension.Advances in Neural Information Processing Systems, 37:93213–93239,
Zaiquan Yang, Yuhao Liu, Jiaying Lin, Gerhard Hancke, and Rynson W Lau. Boosting weakly supervised referring im- age segmentation via progressive comprehension.Advances in Neural Information Processing Systems, 37:93213–93239,
-
[48]
Referring segmentation in images and videos with cross-modal self-attention network.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3719– 3732, 2021
Linwei Ye, Mrigank Rochan, Zhi Liu, Xiaoqin Zhang, and Yang Wang. Referring segmentation in images and videos with cross-modal self-attention network.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3719– 3732, 2021. 1, 2
2021
-
[49]
Losh: Long-short text joint prediction network for referring video object segmentation
Linfeng Yuan, Miaojing Shi, Zijie Yue, and Qijun Chen. Losh: Long-short text joint prediction network for referring video object segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14001–14010, 2024. 2, 6, 7
2024
-
[50]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understand- ing.arXiv preprint arXiv:2501.13106, 2025. 7
work page internal anchor Pith review arXiv 2025
-
[51]
Wangbo Zhao, Kepan Nan, Songyang Zhang, Kai Chen, Dahua Lin, and Yang You. Learning referring video ob- ject segmentation from weak annotation.arXiv preprint arXiv:2308.02162, 2023. 3, 6, 7
-
[52]
Villa: Video reasoning segmentation with large language model.arXiv preprint arXiv:2407.14500, 2024
Rongkun Zheng, Lu Qi, Xi Chen, Yi Wang, Kun Wang, Yu Qiao, and Hengshuang Zhao. Villa: Video reasoning segmentation with large language model.arXiv preprint arXiv:2407.14500, 2024. 3
-
[53]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[54]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable trans- formers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 2 Weakly-Supervised Referring Video Object Segmentation through Text Supervision Supplementary Material Overview of supplementary material This supplementary material prov...
work page internal anchor Pith review arXiv 2010
-
[55]
additional ablation studies on Refer-YouTube-VOS [37]
-
[56]
more visualization results. S1. Details of Datasets A2D-Sentences [14] contains 3,754 videos, split into 3,017 for training and 737 for testing. Each video is anno- tated with three or five frames, providing pixel-wise seg- mentation masks for various target instances. In total, the dataset includes 6,655 referring expressions, each of which corresponds t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.