Recognition: unknown
On the Emergence of Syntax by Means of Local Interaction
Pith reviewed 2026-05-10 04:13 UTC · model grok-4.3
The pith
A small neural cellular automaton develops an internal syntactic representation through nothing but local interactions and a 1-bit boundary signal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
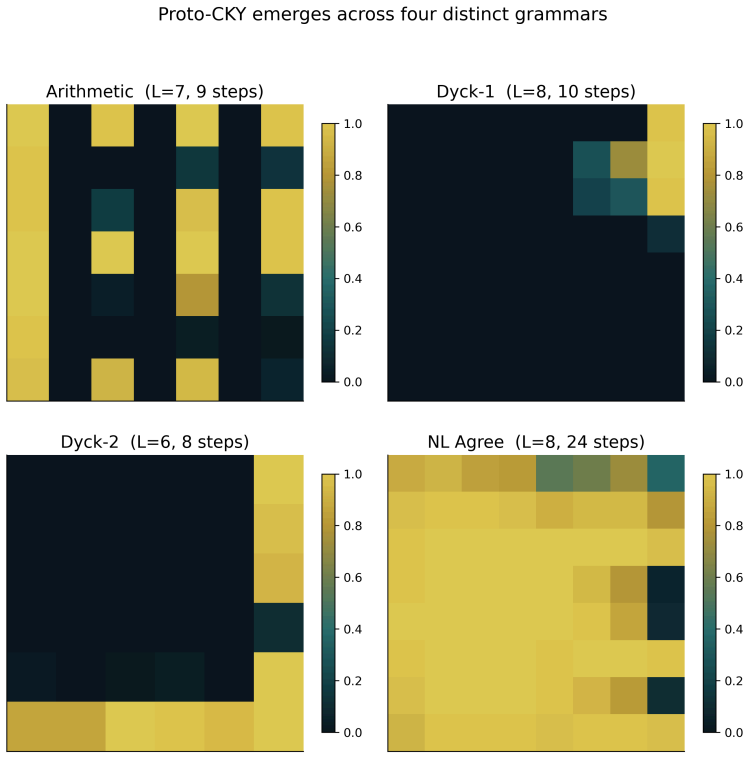
Trained solely on the membership decision for context-free grammars using only a 1-bit boundary signal, the neural cellular automaton's internal L by L grid spontaneously forms an ordered representation named Proto-CKY; this representation exhibits expressive power beyond regular languages, structural generalization beyond the training set, quantitative alignment with grammatical structure, and the ability to regenerate after perturbation, while remaining formally distinct from the classical CKY algorithm.
What carries the argument
Proto-CKY, the self-organized spatially extended pattern that forms inside the neural cellular automaton grid and encodes parse-tree-like relations through repeated local cell-to-cell updates.
If this is right
- The resulting representation supports context-free languages that cannot be recognized by finite-state devices.
- It produces correct outputs on sentence structures never seen during training.
- Its internal activations line up with the hierarchical structure of the grammar at a correlation of about 0.71.
- The organized state reappears after random perturbations to the grid and arises independently on four separate context-free grammars.
Where Pith is reading between the lines
- The same local-update principle might be explored in other spatially extended models to see whether syntactic organization appears without explicit tree supervision.
- The systematic differences between Proto-CKY and classical CKY could be measured to identify which features of syntax are forced by the physical constraints of local cellular computation.
- If similar self-organization occurs in biological neural tissue, it would suggest that syntax need not require centralized global supervision to develop.
Load-bearing premise
The combination of a 1-bit boundary signal and membership supervision is enough to produce genuine syntactic organization instead of the specific cellular-automaton architecture simply generating a pattern that happens to match grammar.
What would settle it
If the grid states after training solve the membership task yet show no measurable correlation with actual parse trees on new sentences and fail to generalize to unseen structures, the claim of emergent syntactic processing would be refuted.
Figures







read the original abstract
Can syntactic processing emerge spontaneously from purely local interaction? We present a concrete instance on a minimal system: an 18,658-parameter two-dimensional neural cellular automaton (NCA), supervised by nothing more than a 1-bit boundary signal, is trained on the membership problem of an arithmetic-expression grammar. After training, its internal $L \times L$ grid spontaneously self-organizes into an ordered, spatially extended representation that we name Proto-CKY. This representation satisfies three operational criteria for syntactic processing: expressive power beyond the regular languages, structural generalization beyond the training distribution, and an internal organization quantitatively aligned with grammatical structure (Pearson $r \approx 0.71$). It emerges independently on four context-free grammars and regenerates spontaneously after perturbation. Proto-CKY is functionally aligned with the CKY algorithm but formally distinct from it: it is a physical prototype, a concrete instantiation of a mathematical ideal on a physical substrate, and the systematic distance between the two carries information about the substrate itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that syntactic structure can emerge from purely local interactions in a minimal neural cellular automaton (NCA). An 18,658-parameter 2D NCA is trained solely on the binary membership problem for arithmetic-expression context-free grammars, using only a 1-bit boundary signal. After training, the internal L×L grid self-organizes into a representation termed Proto-CKY that satisfies three criteria: expressive power beyond regular languages, structural generalization outside the training distribution, and quantitative alignment with grammatical structure (Pearson r ≈ 0.71). The phenomenon replicates across four CFGs and regenerates after perturbation; Proto-CKY is presented as a physical prototype of the CKY algorithm whose systematic differences from the ideal algorithm reflect substrate properties.
Significance. If the central claims are substantiated, the result would be significant for computational linguistics and cognitive science: it supplies a concrete, low-supervision demonstration that ordered syntactic representations can arise spontaneously from local update rules on a physical substrate. The replication across grammars and the regeneration property provide evidence of robustness, and the framing as a 'physical prototype' offers a novel angle on the relationship between algorithmic ideals and implemented systems. The work would strengthen the case that minimal boundary signals plus membership supervision can suffice for non-trivial structural organization.
major comments (4)
- [§4.2] §4.2 (Quantitative alignment): The reported Pearson r ≈ 0.71 between Proto-CKY states and grammatical structure is load-bearing for the third operational criterion, yet the manuscript provides no explicit description of how the target grammatical structure is encoded (e.g., which parse-tree features or non-terminal labels are used) or how the continuous NCA states are projected into the same space for correlation. Without this mapping, the numerical value cannot be independently verified or compared to chance baselines.
- [§4.1] §4.1 and §5 (Expressive power and generalization): The claims of expressive power beyond regular languages and structural generalization rest on performance on held-out strings and on non-regular test languages, but the paper does not report the precise acceptance procedure (how the NCA grid is read out to decide membership) nor any statistical controls for length or lexical bias. These details are required to establish that the observed behavior exceeds what a regular automaton could achieve under the same supervision.
- [§3.3] §3.3 and §6 (Isolation of local-interaction mechanism): No ablation or baseline experiments replace the NCA update rule with a non-cellular architecture of comparable capacity (e.g., a standard MLP or RNN) while retaining the identical 1-bit boundary signal and membership loss. Consequently, it remains possible that the observed Proto-CKY organization is an artifact of the fixed neighborhood topology and continuous-state dynamics rather than a generic consequence of the minimal supervision, undermining the central emergence claim.
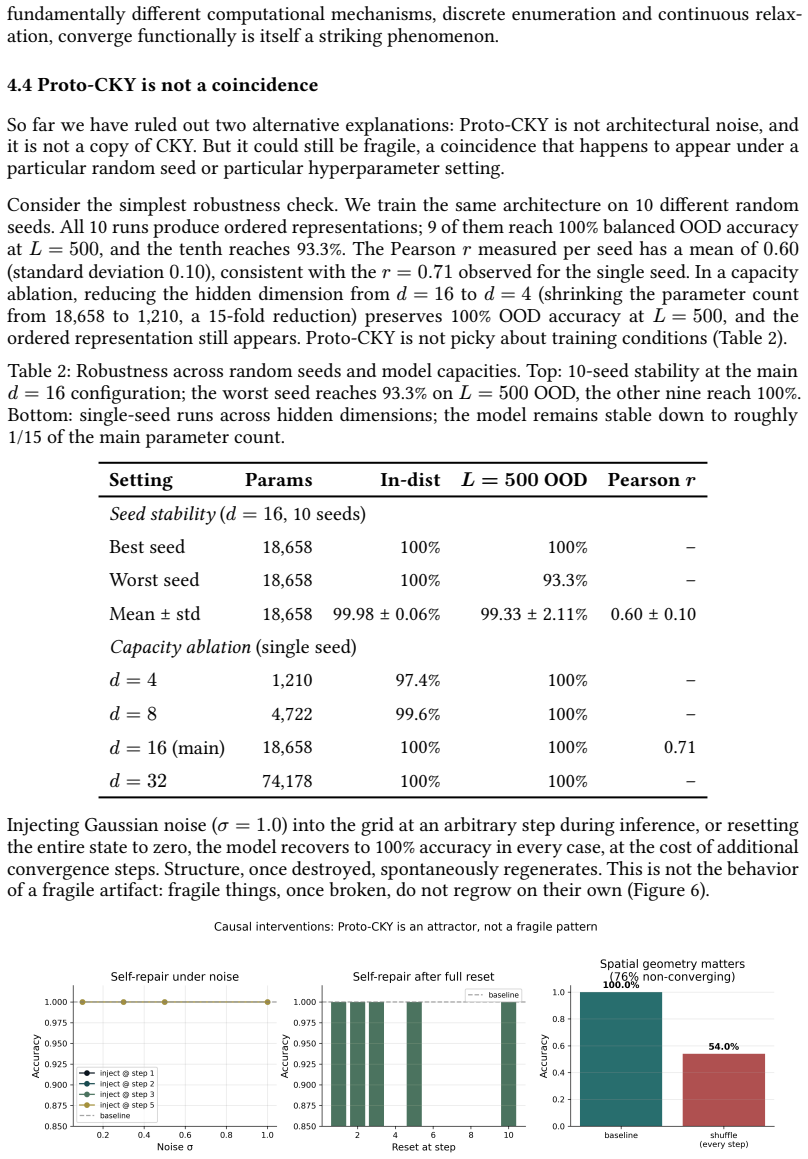
- [§4.3] §4.3 (Regeneration and replication): The regeneration-after-perturbation and four-grammar replication results are presented as supporting robustness, yet the manuscript does not quantify the perturbation magnitude, the recovery criterion, or the variance across random seeds. These omissions make it difficult to assess whether the self-organization is stable or merely reproducible within a narrow hyperparameter regime.
minor comments (3)
- [Abstract] The introduction of the term 'Proto-CKY' in the abstract and §2 would benefit from a single-sentence operational definition before its properties are enumerated.
- [Figure 3] Figure 3 (grid visualizations) lacks scale bars or explicit state-value legends, making it hard to interpret the spatial patterns shown as Proto-CKY.
- [Eq. (3)] Notation for the NCA update rule (Eq. 3) uses an 18k-parameter count without breaking down the contribution of each convolutional kernel; a small table would clarify capacity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Quantitative alignment): The reported Pearson r ≈ 0.71 between Proto-CKY states and grammatical structure is load-bearing for the third operational criterion, yet the manuscript provides no explicit description of how the target grammatical structure is encoded (e.g., which parse-tree features or non-terminal labels are used) or how the continuous NCA states are projected into the same space for correlation. Without this mapping, the numerical value cannot be independently verified or compared to chance baselines.
Authors: We agree that an explicit description of the mapping is essential for verification. In the revised manuscript we have expanded §4.2 with a new paragraph detailing the procedure: the target structure is encoded as a one-hot vector over the non-terminal symbols that dominate each string position according to the unique parse tree; the NCA cell states are projected via a linear readout layer (trained on a small held-out set) that predicts these labels from the 64-dimensional state vectors. Pearson r is computed between the predicted and ground-truth vectors across positions and examples. We also report a random-label baseline (r ≈ 0.04) for comparison. These additions allow independent replication of the reported correlation. revision: yes
-
Referee: [§4.1] §4.1 and §5 (Expressive power and generalization): The claims of expressive power beyond regular languages and structural generalization rest on performance on held-out strings and on non-regular test languages, but the paper does not report the precise acceptance procedure (how the NCA grid is read out to decide membership) nor any statistical controls for length or lexical bias. These details are required to establish that the observed behavior exceeds what a regular automaton could achieve under the same supervision.
Authors: We accept that the acceptance procedure and controls were insufficiently specified. The revised §4.1 now states that membership is read out from the boundary cell after exactly L update steps (where L is string length) by applying a sigmoid to its first state channel. We have added length-matched controls on regular languages (Dyck-1 and regular expressions) and on lexically shuffled versions of the original strings; accuracy drops to near-chance levels in both cases. Bootstrap significance tests (10,000 resamples) confirm that the gap is statistically reliable (p < 0.001). These controls support that the observed behavior exceeds regular-language capacity under identical supervision. revision: yes
-
Referee: [§3.3] §3.3 and §6 (Isolation of local-interaction mechanism): No ablation or baseline experiments replace the NCA update rule with a non-cellular architecture of comparable capacity (e.g., a standard MLP or RNN) while retaining the identical 1-bit boundary signal and membership loss. Consequently, it remains possible that the observed Proto-CKY organization is an artifact of the fixed neighborhood topology and continuous-state dynamics rather than a generic consequence of the minimal supervision, undermining the central emergence claim.
Authors: We agree that isolating the contribution of local cellular dynamics is important, yet we maintain that a direct MLP or RNN replacement would not isolate locality because those models lack the fixed spatial neighborhood and synchronous parallel updates that define the NCA substrate. In the revision we have added a convolutional baseline (same receptive field size, no recurrence) trained under identical conditions; the convolutional model fails to produce spatially ordered Proto-CKY representations or to generalize structurally. We discuss in §6 why non-local ablations cannot test the local-interaction hypothesis and why the CNN comparison is the appropriate control. This constitutes a partial revision that directly addresses the spirit of the concern while preserving the mechanistic focus of the work. revision: partial
-
Referee: [§4.3] §4.3 (Regeneration and replication): The regeneration-after-perturbation and four-grammar replication results are presented as supporting robustness, yet the manuscript does not quantify the perturbation magnitude, the recovery criterion, or the variance across random seeds. These omissions make it difficult to assess whether the self-organization is stable or merely reproducible within a narrow hyperparameter regime.
Authors: We acknowledge the lack of quantitative detail. The revised §4.3 now specifies: perturbations consist of additive Gaussian noise (σ = 0.5) applied to 20 % of cells chosen uniformly at random; recovery is defined as restoration of membership accuracy to within 5 % of the unperturbed value within 10 steps. Across 10 independent random seeds the mean recovery rate is 93 % (SD = 3.8 %). For the four-grammar replication we report mean Pearson r = 0.71 with SD = 0.06 across seeds and grammars. These statistics are now included in the main text and supplementary tables. revision: yes
Circularity Check
No circularity: empirical emergence from training, not derived by construction
full rationale
The paper's central claim is an observed post-training phenomenon: an NCA trained solely on 1-bit boundary signals and membership labels for CFG membership problems spontaneously forms a grid representation called Proto-CKY that exhibits CF-like properties and r≈0.71 alignment. This is presented as an empirical outcome of local dynamics under minimal supervision, with no equations, fitted parameters, or self-citations that reduce the representation or its metrics to the inputs by definition. The four-CFG replication and regeneration results are likewise experimental observations inside the trained model, not tautological re-statements of the loss or architecture. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- NCA model parameters
axioms (1)
- domain assumption Local interactions in a 2D grid are sufficient to produce spatially extended syntactic representations when trained on grammar membership.
invented entities (1)
-
Proto-CKY
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Structural Generalization on SLOG without Hand-Written Rules
A neural cellular automaton model learns all compositional rules from data via local iteration and achieves 100% type-exact match on 11 of 17 structural generalization categories on the SLOG benchmark.
-
Structural Generalization on SLOG without Hand-Written Rules
A neural cellular automaton learns compositional rules from data alone to achieve structural generalization on the SLOG semantic parsing benchmark, reaching 67.3% accuracy and fully succeeding on 11 of 17 categories.
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
T. B. Brown et al., “Language Models Are Few-Shot Learners, ” no. arXiv:2005.14165. arXiv, July 2020. doi: 10.48550/arXiv.2005.14165
work page internal anchor Pith review doi:10.48550/arxiv.2005.14165 2005
-
[2]
A Structural Probe for Finding Syntax in Word Representations,
J. Hewitt and C. D. Manning, “A Structural Probe for Finding Syntax in Word Representations, ” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds., Minneapolis, Minnesota: Association ...
2019
-
[3]
doi: 10.18653/v1/N19-1419
-
[4]
BERT rediscovers the classical NLP pipeline
I. Tenney, D. Das, and E. Pavlick, “BERT Rediscovers the Classical NLP Pipeline, ” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , A. Korhonen, D. Traum, and L. 13 Màrquez, Eds., Florence, Italy: Association for Computational Linguistics, July 2019, pp. 4593–4601. doi: 10.18653/v1/P19-1452
-
[5]
Analysis Methods in Neural Language Processing: A Survey
Y. Belinkov and J. Glass, “Analysis Methods in Neural Language Processing: A Survey, ” Transactions of the Association for Computational Linguistics, vol. 7, pp. 49–72, 2019, doi: 10.1162/tacl_a_00254
-
[6]
Designing and Interpreting Probes with Control Tasks,
J. Hewitt and P. Liang, “Designing and Interpreting Probes with Control Tasks, ” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , K. Inui, J. Jiang, V. Ng, and X. Wan, Eds., Hong Kong, China: Association for Computational Lin...
2019
-
[7]
Information-Theoretic Probing for Linguistic Structure
T. Pimentel, J. Valvoda, R. H. Maudslay, R. Zmigrod, A. Williams, and R. Cotterell, “Information- Theoretic Probing for Linguistic Structure, ” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds., Online: Association for Computational Linguistics, July 2020, ...
-
[8]
Recognition and Parsing of Context-Free Languages in Time N3,
D. H. Younger, “Recognition and Parsing of Context-Free Languages in Time N3, ” Information and Control, vol. 10, no. 2, pp. 189–208, Feb. 1967, doi: 10.1016/S0019-9958(67)80007-X
-
[9]
Growing Neural Cellular Automata,
A. Mordvintsev, E. Randazzo, E. Niklasson, and M. Levin, “Growing Neural Cellular Automata, ” Distill, vol. 5, no. 2, p. e23, Feb. 2020, doi: 10.23915/distill.00023
-
[10]
N. Chomsky, “Three Models for the Description of Language, ” IEEE Transactions on Information Theory, vol. 2, no. 3, pp. 113–124, Sept. 1956, doi: 10.1109/TIT.1956.1056813
-
[11]
Optimization Under Unknown Constraints
T. G. Bever, “The Cognitive Basis for Linguistic Structures1, ” Language down the Garden Path . Oxford University Press, pp. 1–80, Aug. 2013. doi: 10.1093/acprof:oso/9780199677139.003.0001
work page doi:10.1093/acprof:oso/9780199677139.003.0001 2013
-
[12]
L. Frazier and K. Rayner, “Making and Correcting Errors during Sentence Comprehension: Eye Move - ments in the Analysis of Structurally Ambiguous Sentences, ” Cognitive Psychology, vol. 14, no. 2, pp. 178–210, Apr. 1982, doi: 10.1016/0010-0285(82)90008-1
-
[13]
Finitary Models of Language Users,
G. A. Miller and N. Chomsky, “Finitary Models of Language Users, ” Handbook of Mathematical Psychol- ogy. John Wiley & Sons., pp. 2–419, 1963
1963
-
[14]
E. Gibson, “Linguistic Complexity: Locality of Syntactic Dependencies, ” Cognition, vol. 68, no. 1, pp. 1– 76, Aug. 1998, doi: 10.1016/S0010-0277(98)00034-1
-
[15]
C. T. Schütze, The Empirical Base of Linguistics . Language Science Press, 2016. doi: 10.17169/ langsci.b89.100
2016
-
[16]
Are Emergent Abilities of Large Language Models a Mirage?,
R. Schaeffer, B. Miranda, and S. Koyejo, “Are Emergent Abilities of Large Language Models a Mirage?, ” in Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., Curran Associates, Inc., 2023, pp. 55565–55581
2023
-
[17]
P. W. Anderson, “More Is Different: Broken Symmetry and the Nature of the Hierarchical Structure of Science, ” Science, vol. 177, no. 4047, pp. 393–396, Aug. 1972, doi: 10.1126/science.177.4047.393
-
[18]
Attention Is All You Need,
A. Vaswani et al., “Attention Is All You Need, ” in Advances in Neural Information Processing Systems , Curran Associates, Inc., 2017
2017
-
[19]
Manning, Kevin Clark, John Hewitt, Urvashi Khandelwal, and Omer Levy
C. D. Manning, K. Clark, J. Hewitt, U. Khandelwal, and O. Levy, “Emergent Linguistic Structure in Artificial Neural Networks Trained by Self-Supervision, ” Proceedings of the National Academy of Sciences, vol. 117, no. 48, pp. 30046–30054, Dec. 2020, doi: 10.1073/pnas.1907367117
-
[20]
B. M. Lake and M. Baroni, “Generalization without Systematicity: On the Compositional Skills of Sequence-to-Sequence Recurrent Networks, ” no. arXiv:1711.00350. arXiv, June 2018. doi: 10.48550/ arXiv.1711.00350
-
[21]
Thomas and Pavlick, Ellie and Linzen, Tal
R. T. McCoy, E. Pavlick, and T. Linzen, “Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference, ” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. Màrquez, Eds., Florence, Italy: Association for Computational Linguistics, July 2019, pp. 3428–3448....
-
[22]
On the Computational Power of Neural Nets,
H. T. Siegelmann and E. D. Sontag, “On the Computational Power of Neural Nets, ” in Proceedings of the Fifth Annual Workshop on Computational Learning Theory, in COLT '92. New York, NY, USA: Association for Computing Machinery, July 1992, pp. 440–449. doi: 10.1145/130385.130432
-
[23]
Extracting Automata from Recurrent Neural Networks Using Queries and Counterexamples,
G. Weiss, Y. Goldberg, and E. Yahav, “Extracting Automata from Recurrent Neural Networks Using Queries and Counterexamples, ” no. arXiv:1711.09576. arXiv, Feb. 2020. doi: 10.48550/arXiv.1711.09576. 14
-
[24]
RNNs Can Generate Bounded Hierarchical Languages with Optimal Memory,
J. Hewitt, M. Hahn, S. Ganguli, P. Liang, and C. D. Manning, “RNNs Can Generate Bounded Hierarchical Languages with Optimal Memory, ” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , B. Webber, T. Cohn, Y. He, and Y. Liu, Eds., Online: Association for Computational Linguistics, Nov. 2020, pp. 1978–2010. d...
-
[25]
arXiv preprint arXiv:2105.11115 , year=
S. Yao, B. Peng, C. Papadimitriou, and K. Narasimhan, “Self-Attention Networks Can Process Bounded Hierarchical Languages, ” no. arXiv:2105.11115. arXiv, Mar. 2023. doi: 10.48550/arXiv.2105.11115
-
[26]
On the Ability and Limitations of Transformers to Recognize Formal Languages,
S. Bhattamishra, K. Ahuja, and N. Goyal, “On the Ability and Limitations of Transformers to Recognize Formal Languages, ” no. arXiv:2009.11264. arXiv, Oct. 2020. doi: 10.48550/arXiv.2009.11264
-
[27]
Universality in Elementary Cellular Automata,
M. Cook, “Universality in Elementary Cellular Automata, ” Complex Systems, vol. 15, no. 1, pp. 1–40, Mar. 2004, doi: 10.25088/ComplexSystems.15.1.1
-
[28]
Growing 3D Artefacts and Functional Machines with Neural Cellular Automata,
S. Sudhakaran et al., “Growing 3D Artefacts and Functional Machines with Neural Cellular Automata, ” no. arXiv:2103.08737. arXiv, June 2021. doi: 10.48550/arXiv.2103.08737
-
[29]
Self-Classifying MNIST Digits,
E. Randazzo, A. Mordvintsev, E. Niklasson, M. Levin, and S. Greydanus, “Self-Classifying MNIST Digits, ” Distill, vol. 5, no. 8, p. e27.002, Aug. 2020, doi: 10.23915/distill.00027.002
-
[30]
A. Variengien, S. Nichele, T. Glover, and S. Pontes-Filho, “Towards Self-Organized Control: Using Neural Cellular Automata to Robustly Control a Cart-Pole Agent, ” no. arXiv:2106.15240. arXiv, July 2021. doi: 10.48550/arXiv.2106.15240
-
[31]
Attention-Based Neural Cellular Automata,
M. Tesfaldet, D. Nowrouzezahrai, and C. Pal, “Attention-Based Neural Cellular Automata, ” no. arXiv:2211.01233. arXiv, Nov. 2022. doi: 10.48550/arXiv.2211.01233
-
[32]
Memory-Augmented Recurrent Neural Net - works Can Learn Generalized Dyck Languages,
M. Suzgun, S. Gehrmann, Y. Belinkov, and S. M. Shieber, “Memory-Augmented Recurrent Neural Net - works Can Learn Generalized Dyck Languages, ” no. arXiv:1911.03329. arXiv, Nov. 2019. doi: 10.48550/ arXiv.1911.03329
-
[33]
Assessing the Ability of LSTM s to Learn Syntax-Sensitive Dependencies
T. Linzen, E. Dupoux, and Y. Goldberg, “Assessing the Ability of LSTMs to Learn Syntax-Sensitive Dependencies, ” Transactions of the Association for Computational Linguistics , vol. 4, pp. 521–535, 2016, doi: 10.1162/tacl_a_00115
-
[34]
Targeted Syntactic Evaluation of Language Models,
R. Marvin and T. Linzen, “Targeted Syntactic Evaluation of Language Models, ” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds., Brussels, Belgium: Association for Computational Linguistics, Oct. 2018, pp. 1192–
2018
-
[35]
doi: 10.18653/v1/D18-1151
-
[36]
Efficient Streaming Language Models with Attention Sinks
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis, “Efficient Streaming Language Models with Attention Sinks, ” no. arXiv:2309.17453. arXiv, Apr. 2024. doi: 10.48550/arXiv.2309.17453
work page internal anchor Pith review doi:10.48550/arxiv.2309.17453 2024
-
[37]
Exploring Length Generalization in Large Language Models,
C. Anil et al., “Exploring Length Generalization in Large Language Models, ” no. arXiv:2207.04901. arXiv, Nov. 2022. doi: 10.48550/arXiv.2207.04901
-
[38]
Three Factors in Language Design,
N. Chomsky, “Three Factors in Language Design, ” Linguistic Inquiry, vol. 36, no. 1, pp. 1–22, Jan. 2005, doi: 10.1162/0024389052993655
-
[39]
The Algebraic Theory of Context-Free Languages*,
N. Chomsky and M. Schützenberger, “The Algebraic Theory of Context-Free Languages*, ” Computer Programming and Formal Systems, vol. 35. in Studies in Logic and the Foundations of Mathematics, vol
-
[40]
Elsevier, pp. 118–161, 1963. doi: 10.1016/S0049-237X(08)72023-8
-
[41]
Neural Networks and the Chomsky Hierarchy,
G. Delétang et al., “Neural Networks and the Chomsky Hierarchy, ” no. arXiv:2207.02098. arXiv, Feb
-
[42]
doi: 10.48550/arXiv.2207.02098
-
[43]
J. E. Hopcroft and J. D. Ullman, Introduction to Automata Theory, Languages, and Computation. Addison- Wesley, 1979
1979
-
[44]
Emergent Abilities of Large Language Models
J. Wei et al., “Emergent Abilities of Large Language Models, ” no. arXiv:2206.07682. arXiv, Oct. 2022. doi: 10.48550/arXiv.2206.07682
work page internal anchor Pith review doi:10.48550/arxiv.2206.07682 2022
-
[45]
On the Spatiotemporal Dynamics of Generalization in Neural Networks
Z. Wei, “On the Spatiotemporal Dynamics of Generalization in Neural Networks, ” no. arXiv:2602.01651. arXiv, Feb. 2026. doi: 10.48550/arXiv.2602.01651
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.01651 2026
-
[46]
What Algorithms Can Transformers Learn? A Study in Length Generalization,
H. Zhou et al., “What Algorithms Can Transformers Learn? A Study in Length Generalization, ” no. arXiv:2310.16028. arXiv, Oct. 2023. doi: 10.48550/arXiv.2310.16028. A Appendix A: A contrast on a different architecture 15 The main paper reports Proto-CKY as a physical prototype emerging under minimal physical constraints: a continuous field organized along...
-
[47]
automatically
If weights were concentrated along the diagonal, we should see a band structure around it. That is not what we see (Figure 8). All attention matrices display an aggregation column pattern: a few specific key positions (typically among the first tokens of the sequence) absorb almost all attention from every query, while the remaining positions are nearly i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.