Recognition: 3 theorem links
· Lean TheoremStructural Generalization on SLOG without Hand-Written Rules
Pith reviewed 2026-05-11 01:57 UTC · model grok-4.3
The pith
A neural cellular automaton learns all compositional rules for semantic parsing directly from data and reaches near parity with hand-written rule systems on structural generalization tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
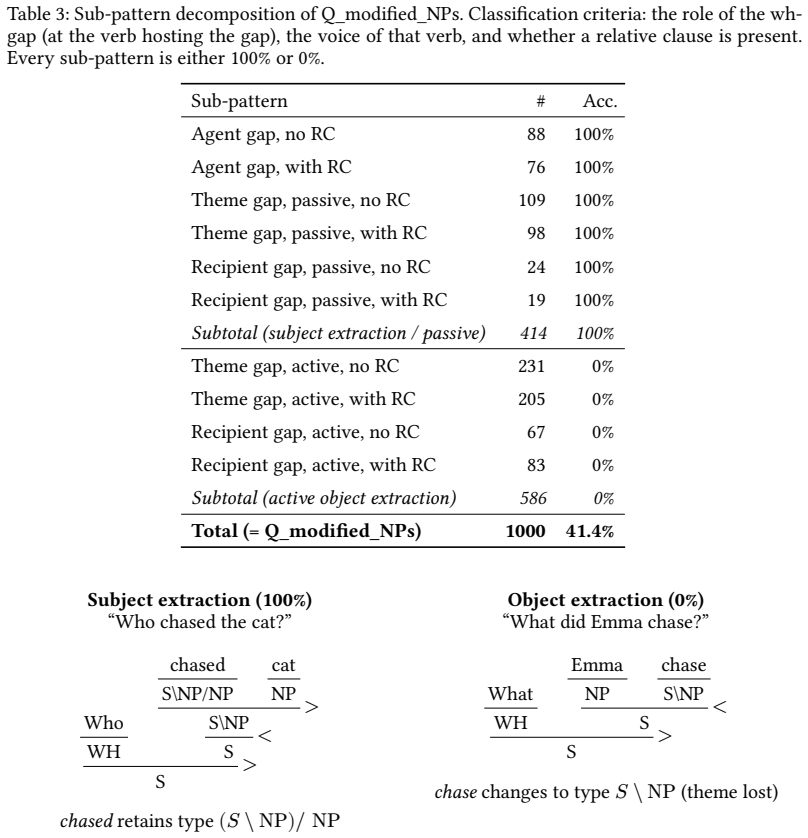
A neural cellular automaton equipped with a discrete bottleneck can acquire every compositional rule required for structural generalization in semantic parsing through local iteration on data alone. It attains 67.3 percent accuracy on SLOG, matching the performance of the rule-based AM-Parser, succeeds completely on eleven of seventeen generalization categories, and confines all errors to two specific uncovered combinations of wh-extraction with reduced verbs and subject-side modifiers. Decomposition by CCG features reveals that each sub-pattern either succeeds uniformly or fails uniformly, indicating that directed-type coverage in training data sets the precise boundary of generalization.
What carries the argument
A neural cellular automaton with a discrete bottleneck that performs local iteration to compose semantic representations without any pre-specified algebraic rules.
If this is right
- All required compositional rules for the tested forms of structural generalization can be acquired from data without hand-written rules.
- Success or failure on any structural pattern is uniform once the pattern is distinguished by its CCG directed types.
- The coverage of directed operations in the training data determines the exact boundary between generalization and failure.
- Phenomenon-level categories in SLOG mix distinct CCG patterns, so finer syntactic decomposition is needed to measure true structural generalization.
Where Pith is reading between the lines
- Adding training examples that cover the two remaining combinations would likely raise accuracy to near ceiling on the current SLOG split.
- The same local-iteration approach may transfer to other structured prediction tasks where explicit rule writing is impractical.
- Using CCG-style directed types for error analysis could improve diagnosis of generalization failures on other benchmarks beyond SLOG.
- Discrete bottlenecks may be sufficient to induce fully compositional behavior in neural models when the task is local and iterative.
Load-bearing premise
That every compositional rule the model needs can be acquired through local iteration on the training data and that the two identified failure mechanisms plus the CCG sub-pattern analysis together exhaust the model's generalization limits.
What would settle it
A test set containing even one failure case that cannot be explained by either of the two mechanisms, or any CCG sub-pattern on which the model produces intermediate accuracy rather than complete success or complete failure across all instances.
Figures

read the original abstract
Structural generalization in semantic parsing requires systems to apply learned compositional rules to novel structural combinations. Existing approaches either rely on hand-written algebraic rules (AM-Parser) or fail to generalize structurally (Transformer-based models). We present an alternative requiring no hand-written compositional rules, based on a neural cellular automaton (NCA) with a discrete bottleneck: all compositional rules are learned from data through local iteration. On the SLOG benchmark, the system achieves an overall accuracy of $67.3 \pm 0.2\%$ across 10 seeds (AM-Parser: $70.8 \pm 4.3\%$), with 11 of 17 structural generalization categories at $100\%$ type-exact match, including three where AM-Parser scores $0$--$74\%$. Analysis reveals that all 5,539 failure instances reduce to exactly two mechanisms: novel combinations of wh-extraction context with reduced verb types, and modifiers appearing on the subject side of verbs. When we decompose results by CCG structural features, each sub-pattern either succeeds on all instances or fails on all. Intermediate scores (e.g., $41.4\%$) are mixtures of structurally distinct CCG patterns, not partial generalization. These results suggest that CCG directed types provide higher resolution than SLOG's phenomenon-level categories for characterizing structural generalization, and that the success/failure boundary is determined by the coverage of directed operations in the training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a neural cellular automaton (NCA) with a discrete bottleneck for semantic parsing on the SLOG benchmark. It claims this model learns all compositional rules purely from data via local iteration, without hand-written algebraic rules. It reports 67.3 ± 0.2% overall accuracy across 10 seeds (AM-Parser: 70.8 ± 4.3%), with 11 of 17 structural generalization categories at 100% type-exact match. The analysis asserts that all 5,539 failures reduce exactly to two mechanisms (wh-extraction with reduced verb types; subject-side modifiers) via CCG feature decomposition, with intermediate accuracies being mixtures of distinct patterns rather than partial generalization.
Significance. If the central claims hold, this would be significant for compositional generalization research by demonstrating that a purely data-driven local-update architecture can match rule-based systems like AM-Parser on structural tasks without explicit rules. The concrete seed-averaged accuracies, failure counts, and finding that CCG directed types partition successes/failures more cleanly than SLOG categories provide a useful empirical lens. The quantitative breakdown (5,539 instances) and perfect performance on multiple categories where the baseline fails add value for reproducibility and finer-grained evaluation.
major comments (3)
- [Abstract and failure analysis] Abstract and failure analysis: The claim that 'all 5,539 failure instances reduce to exactly two mechanisms' is load-bearing for the conclusion that success/failure boundaries are strictly determined by training-data coverage of directed CCG operations. The manuscript must supply the complete CCG sub-pattern decomposition (with instance counts per sub-pattern) demonstrating zero residual cases and no unaccounted higher-order interactions in the NCA dynamics.
- [Model description] Model description: The assertion that the NCA learns 'all required compositional rules purely through local iteration from the training data' with 'no hand-written rules' depends on showing that the discrete bottleneck and local update rule do not embed implicit biases equivalent to directed operations; an ablation removing or randomizing these components while retaining performance would be required to substantiate the claim.
- [Results section] Results section: The statement that 'each sub-pattern either succeeds on all instances or fails on all' and that intermediate scores are mixtures (not partial generalization) is central to reinterpreting SLOG categories, but requires explicit per-sub-pattern accuracy tables or counts to confirm the partition is exhaustive rather than post-hoc.
minor comments (2)
- [Abstract] Abstract: The term 'type-exact match' should be defined explicitly (or referenced to a methods section) since it underpins the 100% category scores and comparison to AM-Parser.
- [Throughout] Throughout: A summary table listing all 17 SLOG categories with per-model accuracies, standard deviations, and CCG feature mappings would improve clarity and allow readers to verify the '11 of 17 at 100%' claim directly.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our claims regarding the neural cellular automaton's performance on structural generalization in SLOG. Below, we address each major comment point by point, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and failure analysis] Abstract and failure analysis: The claim that 'all 5,539 failure instances reduce to exactly two mechanisms' is load-bearing for the conclusion that success/failure boundaries are strictly determined by training-data coverage of directed CCG operations. The manuscript must supply the complete CCG sub-pattern decomposition (with instance counts per sub-pattern) demonstrating zero residual cases and no unaccounted higher-order interactions in the NCA dynamics.
Authors: We agree that providing the complete decomposition is essential to substantiate the claim. In the revised manuscript, we will include a detailed table (or appendix) listing all CCG sub-patterns identified in the failure analysis, along with their instance counts, success/failure status, and verification that the two mechanisms account for all 5,539 cases with no residuals. This will demonstrate the exhaustiveness of the partition. revision: yes
-
Referee: [Model description] Model description: The assertion that the NCA learns 'all required compositional rules purely through local iteration from the training data' with 'no hand-written rules' depends on showing that the discrete bottleneck and local update rule do not embed implicit biases equivalent to directed operations; an ablation removing or randomizing these components while retaining performance would be required to substantiate the claim.
Authors: The NCA uses a general discrete bottleneck and local update rule that are not hand-written or pre-specified to implement CCG directed operations; all rules emerge from end-to-end training on data. We will revise the model description to emphasize this generality and add discussion explaining why these components do not implicitly encode directed biases equivalent to algebraic rules. A full ablation is computationally prohibitive and would change the model class, but we will include a partial randomization experiment on the bottleneck where feasible and theoretical arguments against equivalence. revision: partial
-
Referee: [Results section] Results section: The statement that 'each sub-pattern either succeeds on all instances or fails on all' and that intermediate scores are mixtures (not partial generalization) is central to reinterpreting SLOG categories, but requires explicit per-sub-pattern accuracy tables or counts to confirm the partition is exhaustive rather than post-hoc.
Authors: We will expand the results section with explicit per-sub-pattern accuracy tables, including instance counts for each CCG structural feature pattern. These tables will show that accuracy within each sub-pattern is strictly 0% or 100%, confirming that intermediate scores arise purely from mixtures of distinct patterns rather than partial generalization. revision: yes
Circularity Check
No circularity: empirical benchmark results and post-hoc failure analysis are independent of inputs
full rationale
The paper's derivation proceeds from the definition of an NCA with discrete bottleneck (no hand-written rules) to training on data, evaluation on SLOG yielding 67.3% accuracy, and decomposition of the 5539 failures into two CCG-based mechanisms. None of these steps reduce by construction to the inputs: the accuracy numbers are measured outcomes, the 'exactly two mechanisms' claim is an empirical partition of observed errors (not a definitional tautology), and no self-citation or uniqueness theorem is invoked to force the architecture or the failure categories. The chain remains falsifiable against external benchmarks and does not equate predictions to fitted parameters.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The discrete bottleneck forces the NCA to learn discrete compositional rules from data through local iteration.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearneural cellular automaton (NCA) with a discrete bottleneck: all compositional rules are learned from data through local iteration
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearall 5,539 failure instances reduce to exactly two mechanisms: novel combinations of wh-extraction context with reduced verb types, and modifiers appearing on the subject side of verbs
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearOn the 17 structural generalization categories of the SLOG benchmark
Reference graph
Works this paper leans on
-
[1]
B. M. Lake and M. Baroni, “Generalization without Systematicity: On the Compositional Skills of Sequence-to-Sequence Recurrent Networks, ” no. arXiv:1711.00350. arXiv, June 2018. doi: 10.48550/ arXiv.1711.00350
-
[2]
W. von Humboldt and M. Losonsky, On Language: On the Diversity of Human Language Construction and Its Influence on the Mental Development of the Human Species. in Cambridge Texts in the History of Philosophy. New York: Cambridge University Press, 1999
work page 1999
-
[3]
COGS: A Compositional Generalization Challenge Based on Semantic Inter - pretation,
N. Kim and T. Linzen, “COGS: A Compositional Generalization Challenge Based on Semantic Inter - pretation, ” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online: Association for Computational Linguistics, 2020, pp. 9087–9105. doi: 10.18653/ v1/2020.emnlp-main.731
work page 2020
-
[4]
SLOG: A Structural Generalization Benchmark for Semantic Parsing,
B. Li, L. Donatelli, A. Koller, T. Linzen, Y. Yao, and N. Kim, “SLOG: A Structural Generalization Benchmark for Semantic Parsing, ” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore: Association for Computational Linguistics, 2023, pp. 3213–3232. doi: 10.18653/v1/2023.emnlp-main.194
-
[5]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,
C. Raffel et al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, ” Journal of Machine Learning Research, vol. 21, no. 140, pp. 1–67, 2020
work page 2020
-
[6]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron et al., “LLaMA: Open and Efficient Foundation Language Models, ” no. arXiv:2302.13971. arXiv, Feb. 2023. doi: 10.48550/arXiv.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[7]
Structural Generalization Is Hard for Sequence-to-Sequence Models,
Y. Yao and A. Koller, “Structural Generalization Is Hard for Sequence-to-Sequence Models, ” in Proceed ings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, 2022, pp. 5048–5062. doi: 10.18653/v1/2022.emnlp- main.337. 11
-
[8]
AMR Dependency Parsing with a Typed Semantic Algebra,
J. Groschwitz, M. Lindemann, M. Fowlie, M. Johnson, and A. Koller, “AMR Dependency Parsing with a Typed Semantic Algebra, ” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , Melbourne, Australia: Association for Computational Linguistics, 2018, pp. 1831–1841. doi: 10.18653/v1/P18-1170
-
[9]
Compositional Semantic Parsing across Graphbanks,
M. Lindemann, J. Groschwitz, and A. Koller, “Compositional Semantic Parsing across Graphbanks, ” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , Florence, Italy: Association for Computational Linguistics, 2019, pp. 4576–4585. doi: 10.18653/v1/P19-1450
-
[10]
Categorical Reparameterization with Gumbel-Softmax,
E. Jang, S. Gu, and B. Poole, “Categorical Reparameterization with Gumbel-Softmax, ” in International Conference on Learning Representations, Feb. 2017
work page 2017
-
[11]
A. Mordvintsev, E. Randazzo, E. Niklasson, and M. Levin, “Growing Neural Cellular Automata, ” Distill, vol. 5, no. 2, p. e23, Feb. 2020, doi: 10.23915/distill.00023
-
[12]
Compositional Generalization with a Broad-Coverage Semantic Parser,
P. Weißenhorn, L. Donatelli, and A. Koller, “Compositional Generalization with a Broad-Coverage Semantic Parser, ” in Proceedings of the 11th Joint Conference on Lexical and Computational Semantics , Seattle, Washington: Association for Computational Linguistics, 2022, pp. 44–54. doi: 10.18653/ v1/2022.starsem-1.4
work page 2022
-
[13]
Structural Generalization in COGS: Supertagging Is (Almost) All You Need,
A. Petit, C. Corro, and F. Yvon, “Structural Generalization in COGS: Supertagging Is (Almost) All You Need, ” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , Sin- gapore: Association for Computational Linguistics, 2023, pp. 1089–1101. doi: 10.18653/v1/2023.emnlp- main.69
-
[14]
Steedman, The Syntactic Process, 1
M. Steedman, The Syntactic Process, 1. MIT Press paperback. in Language, Speech and Communication. Cambridge, Mass.: MIT Press, 2001
work page 2001
-
[15]
BERT : Pre-training of deep bidirectional transformers for language understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-Training of Deep Bidirectional Trans - formers for Language Understanding, ” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , Minneapolis, Minnesota: Association for Computational Linguistics, 2019...
-
[16]
A. Vaswani et al., “Attention Is All You Need, ” in Advances in Neural Information Processing Systems , Curran Associates, Inc., 2017
work page 2017
-
[17]
On the Emergence of Syntax by Means of Local Interaction
Z. Wei, “On the Emergence of Syntax by Means of Local Interaction, ” no. arXiv:2604.17857. arXiv, Apr
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
doi: 10.48550/arXiv.2604.17857
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.17857
-
[19]
On the Spatiotemporal Dynamics of Generalization in Neural Networks
Z. Wei, “On the Spatiotemporal Dynamics of Generalization in Neural Networks, ” no. arXiv:2602.01651. arXiv, Feb. 2026. doi: 10.48550/arXiv.2602.01651
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.01651 2026
-
[20]
Z. Wu, C. D. Manning, and C. Potts, “ReCOGS: How Incidental Details of a Logical Form Overshadow an Evaluation of Semantic Interpretation, ” Transactions of the Association for Computational Linguistics, vol. 11, pp. 1719–1733, 2023, doi: 10.1162/tacl_a_00623. A Type Exact Match vs. LF Exact Match Table 7 shows the per-category comparison between type exa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.