Recognition: unknown
OFlow: Injecting Object-Aware Temporal Flow Matching for Robust Robotic Manipulation
Pith reviewed 2026-05-10 04:47 UTC · model grok-4.3
The pith
OFlow unifies temporal flow matching with object-aware factorization inside VLAs to produce more reliable robotic actions under distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
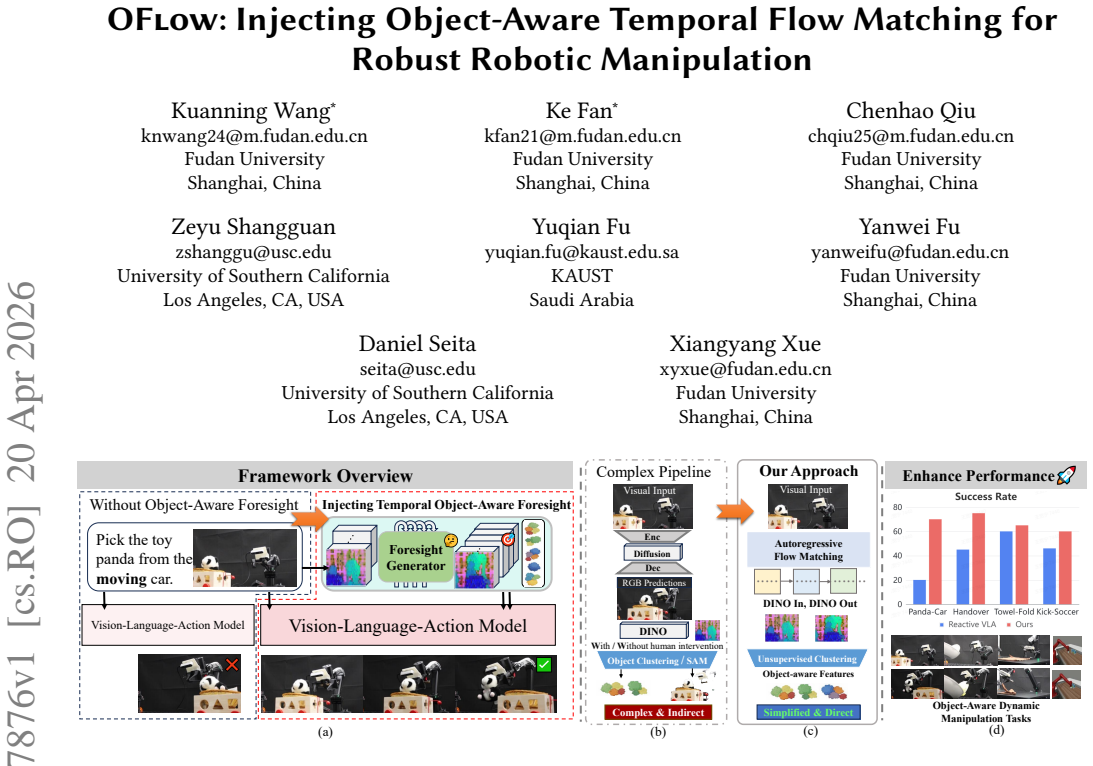
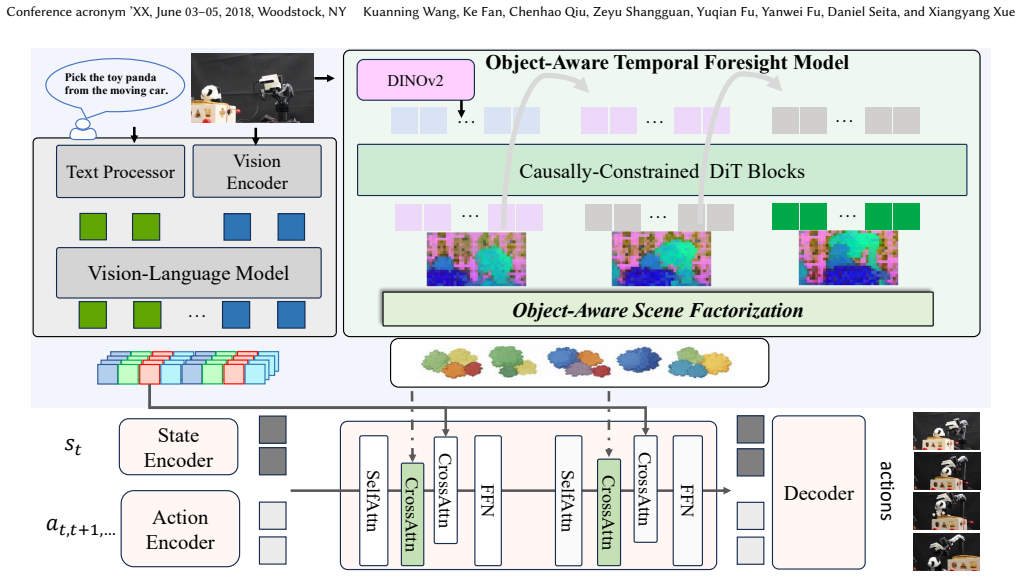
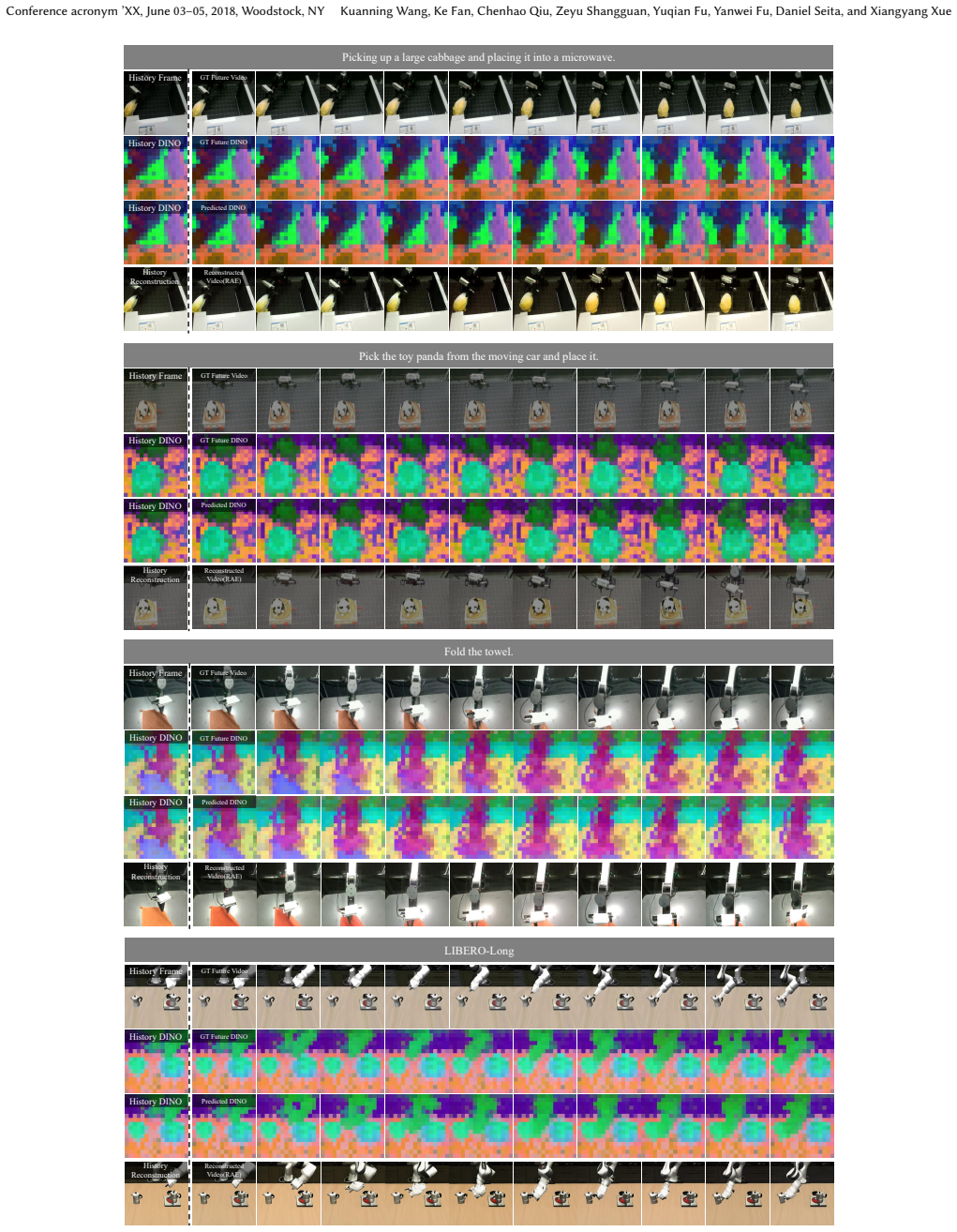
OFlow addresses the limitations by forecasting future latents with temporal flow matching, factorizing those latents into object-aware representations that emphasize physically relevant cues while filtering task-irrelevant variation, and conditioning continuous action generation on the resulting predictions, thereby enabling more reliable control under distribution shifts when the module is inserted into existing VLA pipelines.
What carries the argument
Object-aware temporal flow matching, which forecasts future latents in a shared semantic space and factorizes them into object-focused representations to guide action output.
If this is right
- VLA pipelines gain the ability to act on forecasted future object states instead of only the current frame.
- Object-aware factorization reduces the effect of task-irrelevant scene changes during action generation.
- Continuous actions are conditioned on a unified latent that already contains both temporal and object information.
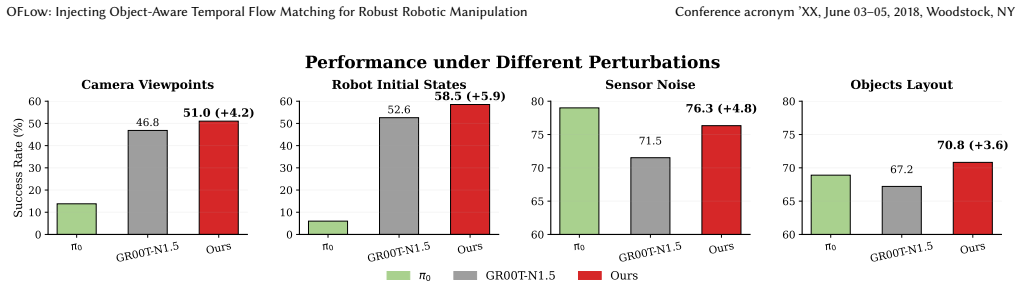
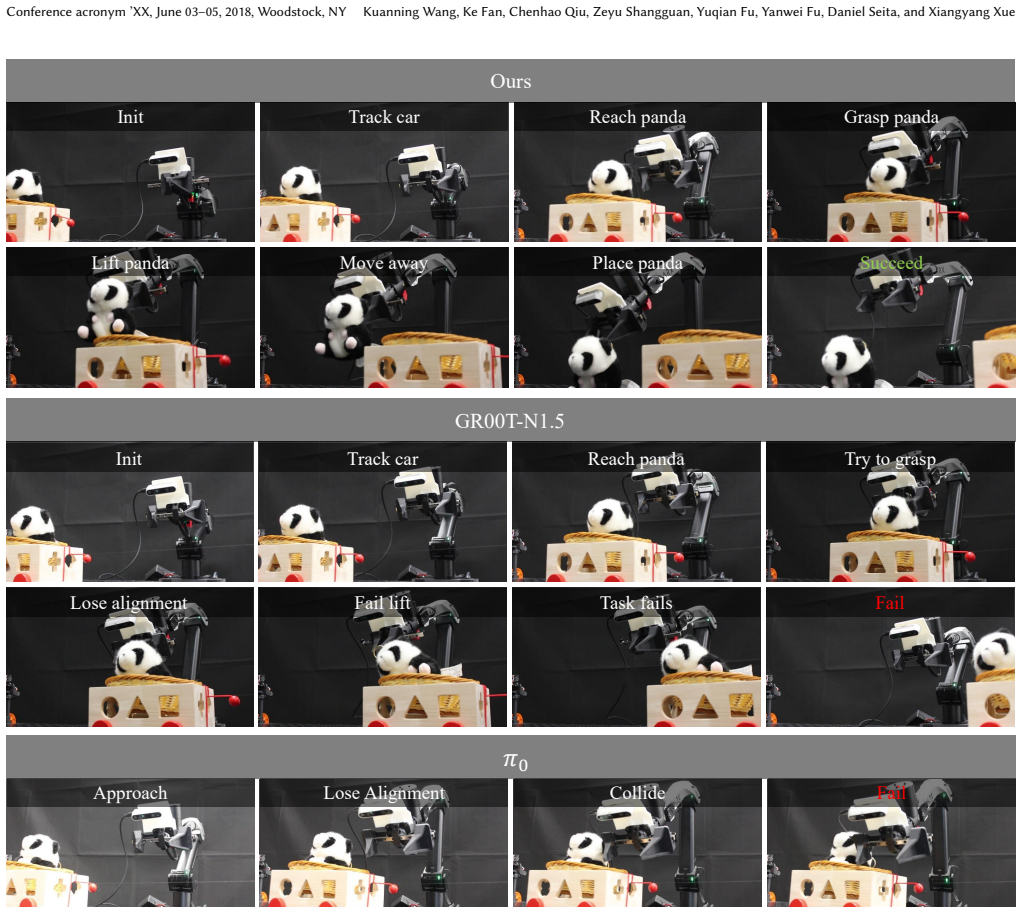
- Performance improves across LIBERO, LIBERO-Plus, MetaWorld, SimplerEnv, and real-world manipulation tasks.
Where Pith is reading between the lines
- The same unification of future prediction and object focus could be tested in other sequential control settings such as mobile navigation.
- Robots might achieve longer-horizon planning by extending the flow-matching horizon without adding separate prediction heads.
- If the factorization step proves stable, it could reduce the need for explicit object detectors in end-to-end policies.
Load-bearing premise
Factorizing the forecasted latents into object-aware pieces will reliably keep the physically important signals and drop the rest without losing details the robot still needs to generate correct actions.
What would settle it
Running the same VLA baseline and the OFlow-augmented version on LIBERO-Plus or SimplerEnv under controlled visual or object shifts and finding no increase, or a drop, in average success rate.
Figures









read the original abstract
Robust robotic manipulation requires not only predicting how the scene evolves over time, but also recognizing task-relevant objects in complex scenes. However, existing VLA models face two limitations. They typically act only on the current frame, while future prediction and object-aware reasoning are often learned in separate latent spaces. We propose OFlow (injecting Object-Aware Temporal Flow Matching into VLAs), a framework that addresses both limitations by unifying temporal foresight and object-aware reasoning in a shared semantic latent space. Our method forecasts future latents with temporal flow matching, factorizes them into object-aware representations that emphasize physically relevant cues while filtering task-irrelevant variation, and conditions continuous action generation on these predictions. By integrating OFlow into VLA pipelines, our method enables more reliable control under distribution shifts. Extensive experiments across LIBERO, LIBERO-Plus, MetaWorld, and SimplerEnv benchmarks and real-world tasks demonstrate that object-aware foresight consistently enhances robustness and success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OFlow, a framework that unifies temporal foresight and object-aware reasoning within VLA models for robotic manipulation. It forecasts future latents via temporal flow matching, factorizes the latents into object-aware representations to emphasize physically relevant cues while suppressing task-irrelevant variation, and conditions continuous action generation on the resulting predictions. The central claim is that this integration yields more reliable control under distribution shifts, supported by experiments on LIBERO, LIBERO-Plus, MetaWorld, SimplerEnv, and real-world tasks showing consistent gains in robustness and success rates.
Significance. If the core claims hold, the work provides a useful architectural unification of flow-based temporal prediction and object-centric reasoning inside existing VLA pipelines, which could improve generalization in manipulation tasks. The broad benchmark coverage and real-robot validation are strengths that allow direct comparison with prior VLA methods. The approach builds cleanly on established flow-matching and VLA components without introducing excessive new parameters.
major comments (2)
- [§3.2] §3.2 (Object-Aware Factorization): the description states that factorization 'emphasizes physically relevant cues while filtering task-irrelevant variation' without discarding information needed for action generation, yet no explicit mechanism (learned masks, attention routing, or clustering), no information-preservation bound, and no ablation isolating the factorization step under entangled-cue regimes are supplied. This step is load-bearing for the distribution-shift robustness claim.
- [§4] §4 (Experiments): success-rate improvements are reported across benchmarks, but the tables and text provide neither per-seed standard deviations, error bars, nor statistical significance tests for the gains under distribution shifts. Without these, it is difficult to judge whether the reported robustness advantage is reliable or could be explained by run-to-run variance.
minor comments (3)
- [§3.1] The flow-matching objective in §3.1 is introduced without an explicit equation for the velocity field or the conditioning on object-aware latents; adding the precise loss formulation would improve reproducibility.
- [Figure 2] Figure 2 (pipeline diagram) contains overlapping text labels on the factorization block; a revised caption or cleaner layout would aid readability.
- [Related Work] A few recent object-centric representation papers (e.g., on slot attention or object-centric world models) are not cited in the related-work section; adding 2–3 targeted references would strengthen context.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our paper. We address each of the major comments point by point below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Object-Aware Factorization): the description states that factorization 'emphasizes physically relevant cues while filtering task-irrelevant variation' without discarding information needed for action generation, yet no explicit mechanism (learned masks, attention routing, or clustering), no information-preservation bound, and no ablation isolating the factorization step under entangled-cue regimes are supplied. This step is load-bearing for the distribution-shift robustness claim.
Authors: We appreciate the referee pointing out the need for greater clarity and supporting evidence regarding the object-aware factorization. Upon review, the current manuscript describes the factorization at a high level but does not provide the requested details on the implementation mechanism or ablations. To address this, we will revise §3.2 to include a precise description of the factorization process, which utilizes a learned soft attention mechanism over object proposals to emphasize relevant cues. We will also add an analysis of information preservation, potentially using variational bounds, and conduct an ablation study on the factorization's impact under distribution shifts with entangled cues. These additions will be included in the revised manuscript. revision: yes
-
Referee: [§4] §4 (Experiments): success-rate improvements are reported across benchmarks, but the tables and text provide neither per-seed standard deviations, error bars, nor statistical significance tests for the gains under distribution shifts. Without these, it is difficult to judge whether the reported robustness advantage is reliable or could be explained by run-to-run variance.
Authors: We agree that including measures of variability and statistical significance would strengthen the experimental section. In the revised version, we will augment the tables with per-seed standard deviations and error bars for all reported success rates. Furthermore, we will include statistical significance tests, such as t-tests, comparing OFlow against baselines under the distribution shift conditions. We are currently re-running the experiments with additional random seeds to compute these statistics accurately. revision: yes
Circularity Check
No circularity: derivation builds on external flow matching and VLA components without reduction to inputs
full rationale
The paper's core claims rest on integrating temporal flow matching for future latent forecasting and subsequent factorization into object-aware representations, then conditioning action generation on them. No equations, fitted parameters, or self-citations are shown that reduce the robustness prediction to a post-hoc fit or self-definition. The factorization step is described as emphasizing relevant cues, but without explicit mechanism or guarantee that would make it tautological. The method is presented as an extension of existing VLA pipelines, with experimental validation on external benchmarks providing independent content. This is the common case of a self-contained architectural proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Temporal flow matching can produce accurate forecasts of future semantic latents from current observations
- ad hoc to paper Object-aware factorization of latents can separate physically relevant cues from task-irrelevant variation
invented entities (1)
-
OFlow framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Focusable Monocular Depth Estimation
FocusDepth is a prompt-conditioned framework that fuses SAM3 features into Depth Anything models via Multi-Scale Spatial-Aligned Fusion to improve target-region depth accuracy on the new FDE-Bench.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Federico Baldassarre, Josselin Somerville Roberts, Huy V Vo, Maxime Oquab, and Piotr Bojanowski. [n. d.]. A Clustering Baseline for Object-Centric Representa- tions. ([n. d.])
-
[3]
Johan Bjorck, Valts Blukis, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al
-
[4]
https://research.nvidia.com/labs/gear/gr00t-n1_5/
Gr00t N1.5: An Improved Open Foundation Model for Generalist Humanoid Robots. https://research.nvidia.com/labs/gear/gr00t-n1_5/. Accessed: 2025-09-09
2025
-
[5]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. 2025. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734(2025)
work page internal anchor Pith review arXiv 2025
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. 2024.𝜋 0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164(2024)
work page internal anchor Pith review arXiv 2024
-
[7]
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. 2024. Video generation models as world simulators. (2024). https://openai.com/research/video-generation-models-as-world-simulators
2024
-
[8]
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. 2025. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111(2025)
work page internal anchor Pith review arXiv 2025
-
[9]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision. 9650–9660
2021
-
[10]
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al . 2025. WorldVLA: Towards Autoregressive Action World Model.arXiv preprint arXiv:2506.21539(2025)
work page internal anchor Pith review arXiv 2025
- [11]
-
[12]
Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, et al. 2025. InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy.arXiv preprint arXiv:2510.13778(2025)
work page internal anchor Pith review arXiv 2025
-
[13]
Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, et al
- [14]
-
[15]
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burch- fiel, and Shuran Song. 2023. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion.ArXiv(2023)
2023
-
[16]
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. 2023. Vision transformers need registers.arXiv preprint arXiv:2309.16588(2023)
work page internal anchor Pith review arXiv 2023
-
[17]
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al
-
[18]
InProceedings of the 40th International Conference on Machine Learning
PaLM-E: an embodied multimodal language model. InProceedings of the 40th International Conference on Machine Learning. 8469–8488
-
[19]
Ke Fan, Zechen Bai, Tianjun Xiao, Tong He, Max Horn, Yanwei Fu, Francesco Locatello, and Zheng Zhang. 2024. Adaptive slot attention: Object discovery with dynamic slot number. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23062–23071
2024
-
[20]
Ke Fan, Zechen Bai, Tianjun Xiao, Dominik Zietlow, Max Horn, Zixu Zhao, Carl- Johann Simon-Gabriel, Mike Zheng Shou, Francesco Locatello, Bernt Schiele, et al
-
[21]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Unsupervised open-vocabulary object localization in videos. InProceedings of the IEEE/CVF International Conference on Computer Vision. 13747–13755
-
[22]
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. 2025. LIBERO-Plus: In-depth Robust- ness Analysis of Vision-Language-Action Models.arXiv preprint arXiv:2510.13626 (2025)
work page internal anchor Pith review arXiv 2025
-
[23]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. 2025. Mas- tering diverse control tasks through world models.Nature(2025), 1–7
2025
-
[24]
Taisei Hanyu, Nhat Chung, Huy Le, Toan Nguyen, Yuki Ikebe, Anthony Gun- derman, Duy Nguyen Ho Minh, Khoa Vo, Tung Kieu, Kashu Yamazaki, et al
-
[25]
Slotvla: Towards modeling of object-relation representations in robotic manipulation.arXiv preprint arXiv:2511.06754(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. [n. d.]. Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations. InForty- second International Conference on Machine Learning
- [27]
-
[28]
Ioannis Kakogeorgiou, Spyros Gidaris, Konstantinos Karantzalos, and Nikos Komodakis. 2024. Spot: Self-training with patch-order permutation for object- centric learning with autoregressive transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22776–22786
2024
-
[29]
Moo Jin Kim, Chelsea Finn, and Percy Liang. 2025. Fine-tuning vision-language- action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645 (2025)
work page internal anchor Pith review arXiv 2025
-
[30]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakr- ishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al
-
[31]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246(2024)
work page internal anchor Pith review arXiv 2024
- [32]
- [33]
-
[34]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al . 2024. Eval- uating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941(2024)
work page internal anchor Pith review arXiv 2024
-
[35]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[36]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36 (2023), 44776–44791
2023
-
[38]
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. 2024. Rdt-1b: a diffusion foundation model Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Kuanning Wang, Ke Fan, Chenhao Qiu, Zeyu Shangguan, Yuqian Fu, Yanwei Fu, Daniel Seita, and Xiangyang Xue for bimanual manipulation.arXiv preprint arXi...
work page internal anchor Pith review arXiv 2024
-
[39]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding dino: Marry- ing dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision. Springer, 38–55
2024
-
[40]
Xingchao Liu, Chengyue Gong, and Qiang Liu. 2022. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003(2022)
work page internal anchor Pith review arXiv 2022
-
[41]
Zhenyang Liu, Yongchong Gu, Sixiao Zheng, Yanwei Fu, Xiangyang Xue, and Yu-Gang Jiang. 2025. TriVLA: A Triple-System-Based Unified Vision-Language- Action Model with Episodic World Modeling for General Robot Control. https: //api.semanticscholar.org/CorpusID:282057970
2025
-
[42]
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahen- dran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf
-
[43]
Object-centric learning with slot attention.NeurIPS(2020)
2020
- [44]
-
[45]
Amir Mohammad Karimi Mamaghan, Samuele Papa, Karl Henrik Johansson, Stefan Bauer, and Andrea Dittadi. 2024. Exploring the effectiveness of object- centric representations in visual question answering: Comparative insights with foundation models.arXiv preprint arXiv:2407.15589(2024)
- [46]
-
[47]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2024. DINOv2: Learning Robust Visual Features without Supervision. Transactions on Machine Learning Research Journal(2024), 1–31
2024
-
[48]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[49]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. 2025. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747 (2025)
work page internal anchor Pith review arXiv 2025
-
[50]
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. 2024. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714(2024)
work page internal anchor Pith review arXiv 2024
- [51]
-
[52]
Gautam Singh, Yi-Fu Wu, and Sungjin Ahn. 2022. Simple unsupervised object- centric learning for complex and naturalistic videos.NeurIPS(2022)
2022
-
[53]
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. 2024. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213(2024)
work page internal anchor Pith review arXiv 2024
-
[54]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. 2023. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning. PMLR, 1723–1736
2023
- [56]
- [57]
-
[58]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al . 2024. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072(2024)
work page internal anchor Pith review arXiv 2024
-
[59]
Conference on Robot Learning , year=
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan C. Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. 2019. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning.ArXivabs/1910.10897 (2019). https://api.semanticscholar.org/CorpusID:204852201
-
[60]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid loss for language image pre-training. InProceedings of the IEEE/CVF inter- national conference on computer vision. 11975–11986
2023
-
[61]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional con- trol to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision. 3836–3847
2023
-
[62]
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, and Xin Jin. 2025. DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge.ArXivabs/2507.04447 (2025). https: //api.semanticscholar.org/CorpusID:280147743
-
[63]
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al . 2025. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference. 1702–1713
2025
-
[64]
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. 2025. Diffusion Transformers with Representation Autoencoders.arXiv preprint arXiv:2510.11690 (2025)
work page internal anchor Pith review arXiv 2025
-
[65]
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. 2021. ibot: Image bert pre-training with online tokenizer.arXiv preprint arXiv:2111.07832(2021)
work page internal anchor Pith review arXiv 2021
-
[66]
Yifeng Zhu, Zhenyu Jiang, Peter Stone, and Yuke Zhu. 2023. Learning Generaliz- able Manipulation Policies with Object-Centric 3D Representations. InConference on Robot Learning. Proceedings of Machine Learning Research
2023
-
[67]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. 2023. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning. PMLR, 2165–2183
2023
-
[68]
U-arm: Ultra low-cost general teleoperation interface for robot manipulation,
Yanwen Zou, Zhaoye Zhou, Chenyang Shi, Zewei Ye, Junda Huang, Yan Ding, and Bo Zhao. 2025. U-ARM: Ultra low-cost general teleoperation interface for robot manipulation.arXiv preprint arXiv:2509.02437(2025). OFlow: Injecting Object-Aware Temporal Flow Matching for Robust Robotic Manipulation Conference acronym ’XX, June 03–05, 2018, Woodstock, NY A Details...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.