Recognition: 1 theorem link
· Lean TheoremFocusable Monocular Depth Estimation
Pith reviewed 2026-05-13 05:39 UTC · model grok-4.3
The pith
Prompts allow monocular depth models to prioritize accuracy on user-specified regions while preserving global scene geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
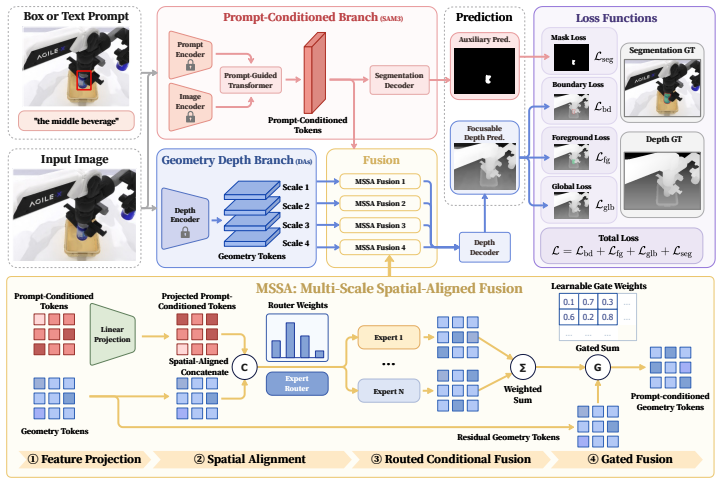
FocusDepth conditions a monocular relative depth estimator on a target region given by box or text prompt. It does so by spatially aligning multi-scale features extracted from a segmentation model to the features of a depth foundation model and then injecting the aligned cues through scale-specific gated conditional fusion. This produces depth maps that are more accurate inside the prompted region and along its boundaries while the global geometric structure of the scene remains unchanged.
What carries the argument
Multi-Scale Spatial-Aligned Fusion (MSSA), which spatially aligns multi-scale segmentation features to depth features and injects them via scale-specific gated conditional fusion to enable prompt-guided focus without breaking geometric consistency.
If this is right
- Depth accuracy improves most in the prompted foreground and at its boundaries.
- Global scene geometry remains coherent even after the prompt cue is added.
- The same gains appear whether the prompt is supplied as a bounding box or as text.
- Performance exceeds that of globally fine-tuned depth baselines on the target-centric benchmark.
Where Pith is reading between the lines
- The same alignment-plus-gated-fusion pattern could be tested on video depth estimation to check whether prompt focus improves frame-to-frame consistency in moving objects.
- Interactive tools that let users click or describe a region and immediately receive refined depth could be built on top of the method.
- The approach may transfer to other dense prediction tasks such as surface-normal estimation or semantic segmentation when selective region emphasis is desired.
Load-bearing premise
Multi-scale features from a segmentation model can be spatially aligned to depth-model features and injected via gated fusion without disrupting the depth model's geometric representations.
What would settle it
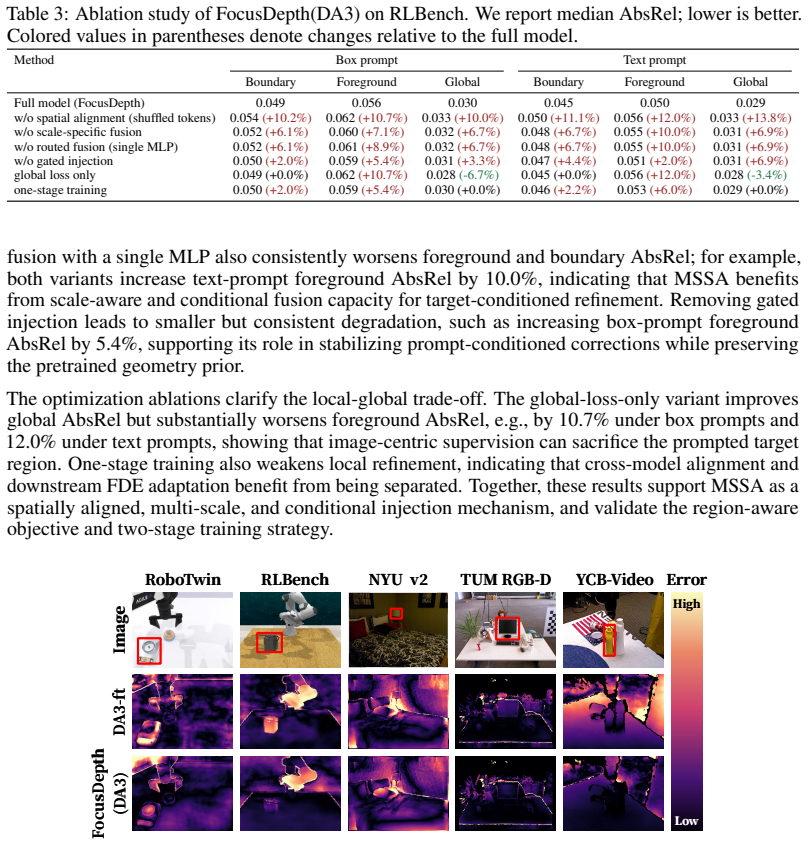
An experiment on FDE-Bench in which removing the spatial-alignment step causes the error in target-boundary and foreground regions to rise to the level of the globally fine-tuned baseline would falsify the claim that alignment is required for the observed gains.
Figures







read the original abstract
Monocular depth foundation models generalize well across scenes, yet they are typically optimized with uniform pixel-wise objectives that do not distinguish user-specified or task-relevant target regions from the surrounding context. We therefore introduce Focusable Monocular Depth Estimation (FDE), a region-aware depth estimation task in which, given a specified target region, the model is required to prioritize foreground depth accuracy, preserve sharp boundary transitions, and maintain coherent global scene geometry. To prioritize task-critical region modeling, we propose FocusDepth, a prompt-conditioned monocular relative depth estimation framework that guides depth modeling to focus on target regions via box/text prompts. The core Multi-Scale Spatial-Aligned Fusion (MSSA) in FocusDepth spatially aligns multi-scale features from Segment Anything Model 3 to the Depth Anything family and injects them through scale-specific, gated conditional fusion. This enables dense prompt cue injection without disrupting geometric representations, thereby endowing the depth estimation model with focused perception capability. To study FDE, we establish FDE-Bench, a target-centric monocular relative depth benchmark built from image-target-depth triplets across five datasets, containing 252.9K/72.5K train/val triplets and 972 categories spanning real-world and embodied simulation environments. On FDE-Bench, FocusDepth consistently improves over globally fine-tuned DA2/DA3 baselines under both box and text prompts, with the largest gains appearing in target boundary and foreground regions while preserving global scene geometry. Ablations show that MSSA's spatial alignment is the key design factor, as disrupting prompt-geometry correspondence increases AbsRel by up to 13.8%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Focusable Monocular Depth Estimation (FDE), a region-aware monocular depth task where models must prioritize accuracy and sharp boundaries in user-specified target regions (via box or text prompts) while preserving global scene geometry. It proposes FocusDepth, a framework that spatially aligns multi-scale features from SAM3 to Depth Anything (DA2/DA3) models and injects them via scale-specific gated conditional fusion (MSSA). A new target-centric benchmark FDE-Bench is constructed from five datasets (252.9K/72.5K train/val triplets across 972 categories). Experiments report consistent gains over globally fine-tuned DA baselines on FDE-Bench, largest in boundaries/foreground, with an ablation showing that disrupting spatial alignment raises AbsRel by up to 13.8%.
Significance. If the central claims hold, the work is significant for extending depth foundation models to interactive, task-specific use cases in robotics, AR, and embodied AI. The MSSA design offers a practical way to condition depth models on prompts without retraining from scratch or sacrificing global consistency. The new FDE-Bench provides a standardized testbed for region-aware depth, and the ablation supplies direct evidence linking the alignment mechanism to performance. These elements position the paper as a useful contribution to promptable perception.
major comments (2)
- [Ablation Study] The ablation linking spatial alignment to performance (AbsRel increase of up to 13.8% when disrupted) is load-bearing for the MSSA contribution. The exact procedure used to break prompt-geometry correspondence must be specified (e.g., feature shifting, module removal, or permutation) so readers can confirm it isolates alignment rather than introducing unrelated distribution shifts.
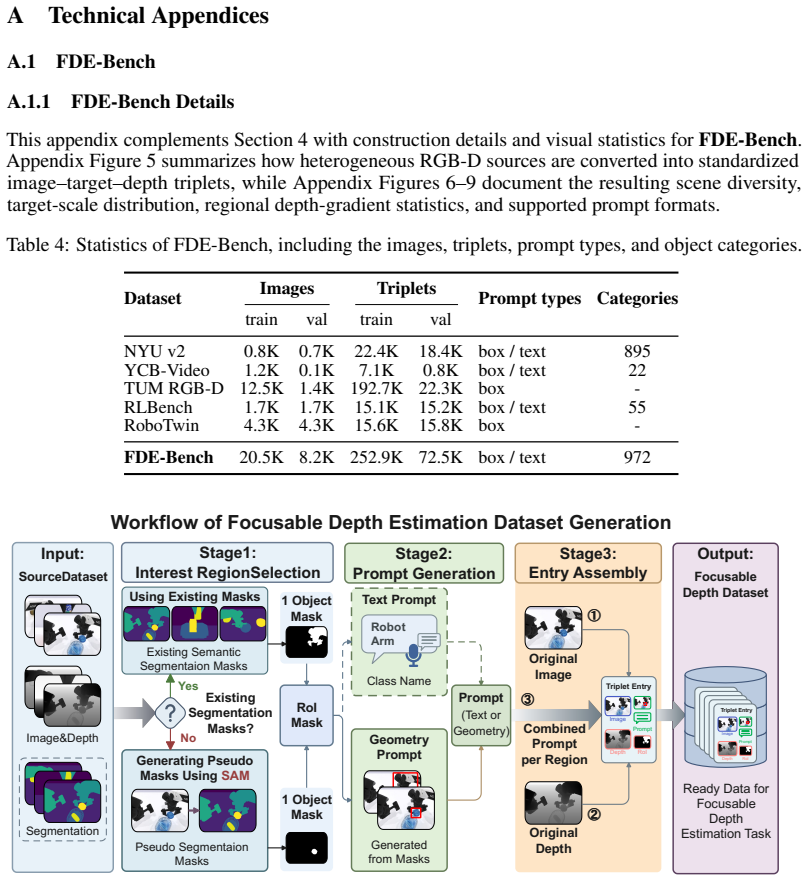
- [Benchmark Construction] Construction details for FDE-Bench are central to the evaluation claim. The manuscript must describe the sampling strategy for the 252.9K/72.5K triplets, prompt generation process, and how target regions are defined across the five source datasets to allow assessment of curation bias or data leakage that could affect the reported gains versus globally fine-tuned baselines.
minor comments (2)
- [Experiments] Quantitative support for the claim of 'preserving global scene geometry' should be added (e.g., global AbsRel, edge consistency, or depth smoothness metrics outside the target region) rather than relying primarily on qualitative description.
- [Method] Notation for the gated fusion (scale-specific gates, conditioning inputs) should be formalized with equations to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. The comments are helpful for improving the clarity of the paper. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Ablation Study] The ablation linking spatial alignment to performance (AbsRel increase of up to 13.8% when disrupted) is load-bearing for the MSSA contribution. The exact procedure used to break prompt-geometry correspondence must be specified (e.g., feature shifting, module removal, or permutation) so readers can confirm it isolates alignment rather than introducing unrelated distribution shifts.
Authors: We agree that detailing the disruption procedure is essential for validating the ablation. In the experiments, prompt-geometry correspondence was disrupted by randomly permuting the spatial coordinates of the extracted SAM3 multi-scale features (while preserving feature values and channel statistics) prior to the gated fusion step; a secondary variant applied a fixed 20% feature-map shift in both x and y directions. We will add an explicit description of these procedures, including pseudocode and the precise hyper-parameters, to the ablation subsection of the revised manuscript. revision: yes
-
Referee: [Benchmark Construction] Construction details for FDE-Bench are central to the evaluation claim. The manuscript must describe the sampling strategy for the 252.9K/72.5K triplets, prompt generation process, and how target regions are defined across the five source datasets to allow assessment of curation bias or data leakage that could affect the reported gains versus globally fine-tuned baselines.
Authors: We acknowledge the importance of these construction details. The 252.9K/72.5K triplets were obtained via stratified sampling across the five source datasets to maintain category balance (972 classes) and scene-type diversity; target regions were defined from ground-truth instance masks (or SAM-generated masks where unavailable) and converted to box prompts, while text prompts were produced by a fixed template augmented with category labels. We will expand the FDE-Bench section with the full sampling algorithm, prompt-generation templates, and an explicit statement that the train/val splits are disjoint from the pre-training corpora of the Depth Anything models, thereby ruling out leakage. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces FDE as a new task and FocusDepth with MSSA fusion as a design that spatially aligns external SAM3 features to DA2/DA3 backbones via gated injection. No equations or derivation steps are shown that reduce claimed improvements or predictions to fitted parameters, self-definitions, or self-citation chains by construction. The benchmark is newly constructed from existing datasets, and ablations isolate the alignment component without circular reduction. The method remains self-contained against external pre-trained models and direct empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Features from Segment Anything Model 3 can be spatially aligned to Depth Anything family features at multiple scales for gated fusion.
Reference graph
Works this paper leans on
-
[1]
Vasileios Arampatzakis, George Pavlidis, Nikolaos Mitianoudis, and Nikos Papamarkos. Monoc- ular depth estimation: A thorough review.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2396–2414, 2023
work page 2023
-
[2]
Monocular depth estimation: A survey.arXiv preprint arXiv:1901.09402, 2019
Amlaan Bhoi. Monocular depth estimation: A survey.arXiv preprint arXiv:1901.09402, 2019
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Deep ordinal regression network for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Batmanghelich, and Dacheng Tao. Deep ordinal regression network for monocular depth estimation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2002–2011, 2018
work page 2002
-
[8]
Unsupervised monocular depth estimation with left-right consistency
Clément Godard, Oisin Mac Aodha, and Gabriel J Brostow. Unsupervised monocular depth estimation with left-right consistency. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 270–279, 2017
work page 2017
-
[9]
Digging into self-supervised monocular depth estimation
Clément Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. InProceedings of the IEEE/CVF international conference on computer vision, pages 3828–3838, 2019
work page 2019
-
[10]
Depthfm: Fast generative monocular depth estimation with flow matching
Ming Gui, Johannes Schusterbauer, Ulrich Prestel, Pingchuan Ma, Dmytro Kotovenko, Olga Grebenkova, Stefan Andreas Baumann, Vincent Tao Hu, and Björn Ommer. Depthfm: Fast generative monocular depth estimation with flow matching. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 3203–3211, 2025
work page 2025
-
[11]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10579–10596, 2024
work page 2024
-
[12]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2): 3019–3026, 2020
work page 2020
-
[14]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Kon- rad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9492–9502, 2024
work page 2024
-
[15]
Amodal depth anything: Amodal depth estimation in the wild
Zhenyu Li, Mykola Lavreniuk, Jian Shi, Shariq Farooq Bhat, and Peter Wonka. Amodal depth anything: Amodal depth estimation in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9673–9682, 2025. 11
work page 2025
-
[16]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Prompting depth anything for 4k reso- lution accurate metric depth estimation
Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, and Bingyi Kang. Prompting depth anything for 4k reso- lution accurate metric depth estimation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17070–17080, 2025
work page 2025
-
[18]
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. Evo-0: Vision-language-action model with implicit spatial understanding.arXiv preprint arXiv:2507.00416, 2025
-
[19]
arXiv preprint arXiv:2511.04555 (2025)
Tao Lin, Yilei Zhong, Yuxin Du, Jingjing Zhang, Jiting Liu, Yinxinyu Chen, Encheng Gu, Ziyan Liu, Hongyi Cai, Yanwen Zou, et al. Evo-1: Lightweight vision-language-action model with preserved semantic alignment.arXiv preprint arXiv:2511.04555, 2025
-
[20]
Bridging geometric and semantic foundation models for generalized monoc- ular depth estimation
Sanggyun Ma, Wonjoon Choi, Jihun Park, Jaeyeul Kim, Seunghun Lee, Jiwan Seo, and Sunghoon Im. Bridging geometric and semantic foundation models for generalized monoc- ular depth estimation. In2026 International Conference on Electronics, Information, and Communication (ICEIC), pages 1–6. IEEE, 2026
work page 2026
-
[21]
Deep learning for monocular depth estimation: A review.Neurocomputing, 438:14–33, 2021
Yue Ming, Xuyang Meng, Chunxiao Fan, and Hui Yu. Deep learning for monocular depth estimation: A review.Neurocomputing, 438:14–33, 2021
work page 2021
-
[22]
Robotwin: Dual-arm robot benchmark with genera- tive digital twins
Yao Mu, Tianxing Chen, Zanxin Chen, Shijia Peng, Zhiqian Lan, Zeyu Gao, Zhixuan Liang, Qiaojun Yu, Yude Zou, Mingkun Xu, et al. Robotwin: Dual-arm robot benchmark with genera- tive digital twins. InProceedings of the computer vision and pattern recognition conference, pages 27649–27660, 2025
work page 2025
-
[23]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10106–10116, 2024
work page 2024
-
[24]
Unidepthv2: Universal monocular metric depth estimation made simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mattia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[25]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020
work page 2020
-
[26]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InEuropean conference on computer vision, pages 746–760. Springer, 2012
work page 2012
-
[27]
A benchmark for the evaluation of rgb-d slam systems
Jürgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard, and Daniel Cremers. A benchmark for the evaluation of rgb-d slam systems. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 573–580. IEEE, 2012
work page 2012
-
[28]
Kuanning Wang, Ke Fan, Yuqian Fu, Siyu Lin, Hu Luo, Daniel Seita, Yanwei Fu, Yu-Gang Jiang, and Xiangyang Xue. Ocra: Object-centric learning with 3d and tactile priors for human-to-robot action transfer.arXiv preprint arXiv:2603.14401, 2026
-
[29]
OFlow: Injecting Object-Aware Temporal Flow Matching for Robust Robotic Manipulation
Kuanning Wang, Ke Fan, Chenhao Qiu, Zeyu Shangguan, Yuqian Fu, Yanwei Fu, Daniel Seita, and Xiangyang Xue. Oflow: Injecting object-aware temporal flow matching for robust robotic manipulation.arXiv preprint arXiv:2604.17876, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Task-aware monocular depth estimation for 3d object detection
Xinlong Wang, Wei Yin, Tao Kong, Yuning Jiang, Lei Li, and Chunhua Shen. Task-aware monocular depth estimation for 3d object detection. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 12257–12264, 2020. 12
work page 2020
-
[31]
Depth anything with any prior.arXiv preprint arXiv:2505.10565, 2025
Zehan Wang, Siyu Chen, Lihe Yang, Jialei Wang, Ziang Zhang, Hengshuang Zhao, and Zhou Zhao. Depth anything with any prior, 2025. URLhttps://arxiv.org/abs/2505.10565
-
[32]
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
Yu Xiang, Tanner Schmidt, Venkatraman Narayanan, and Dieter Fox. Posecnn: A convo- lutional neural network for 6d object pose estimation in cluttered scenes.arXiv preprint arXiv:1711.00199, 2017
work page Pith review arXiv 2017
-
[33]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
work page 2024
-
[34]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
work page 2024
-
[35]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9043–9053, 2023
work page 2023
-
[36]
Egonight: Towards egocentric vision understanding at night with a challenging benchmark
Deheng Zhang, Yuqian Fu, Runyi Yang, Yang Miao, Tianwen Qian, Xu Zheng, Guolei Sun, Ajad Chhatkuli, Xuanjing Huang, Yu-Gang Jiang, et al. Egonight: Towards egocentric vision understanding at night with a challenging benchmark.arXiv preprint arXiv:2510.06218, 2025
-
[37]
Ning Zhang, Francesco Nex, George V osselman, and Norman Kerle. Lite-mono: A lightweight cnn and transformer architecture for self-supervised monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18537–18546, 2023
work page 2023
-
[38]
Chaoqiang Zhao, Qiyu Sun, Chongzhen Zhang, Yang Tang, and Feng Qian. Monocular depth estimation based on deep learning: An overview.Science China Technological Sciences, 63(9): 1612–1627, 2020
work page 2020
-
[39]
Chaoqiang Zhao, Youmin Zhang, Matteo Poggi, Fabio Tosi, Xianda Guo, Zheng Zhu, Guan Huang, Yang Tang, and Stefano Mattoccia. Monovit: Self-supervised monocular depth esti- mation with a vision transformer. In2022 international conference on 3D vision (3DV), pages 668–678. IEEE, 2022. 13 A Technical Appendices A.1 FDE-Bench A.1.1 FDE-Bench Details This app...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.