Recognition: unknown
OneDrive: Unified Multi-Paradigm Driving with Vision-Language-Action Models
Pith reviewed 2026-05-10 04:22 UTC · model grok-4.3
The pith
A pretrained vision-language model performs end-to-end driving by handling text, detection, and trajectories inside one causal decoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
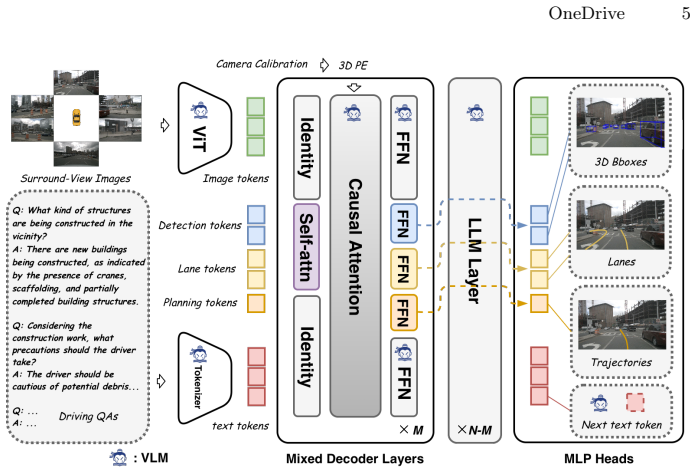
By organizing visual and structured query tokens within a single causal decoder, structured queries can naturally condition on visual context through the original attention mechanism. Textual and structured outputs therefore share a common attention backbone, enabling stable joint optimization across heterogeneous tasks. Trajectory planning is realized inside the same causal LLM decoder by introducing structured trajectory queries, so planning shares the pretrained attention backbone with images and perception tokens.
What carries the argument
The single causal transformer decoder that mixes visual tokens with structured query tokens and routes them through the pretrained attention mechanism.
Where Pith is reading between the lines
- The same token-mixing trick could be tested on other robotics domains that mix language commands with continuous control outputs.
- Minimal additional fine-tuning may be sufficient for new structured-prediction tasks once the attention backbone has been shown to transfer.
- Inference could be further accelerated by dynamically dropping token types that are not needed for a given driving scenario.
Load-bearing premise
Attention patterns learned during language pretraining transfer to structured driving outputs without interference or the need for major new architectural pieces.
What would settle it
An experiment in which adding trajectory queries either drops language-generation quality below the base VLM or fails to match separate-decoder baselines on nuScenes L2 error and collision rate.
Figures


read the original abstract
Vision-Language Models(VLMs) excel at autoregressive text generation, yet end-to-end autonomous driving requires multi-task learning with structured outputs and heterogeneous decoding behaviors, such as autoregressive language generation, parallel object detection and trajectory regression. To accommodate these differences, existing systems typically introduce separate or cascaded decoders, resulting in architectural fragmentation and limited backbone reuse. In this work, we present a unified autonomous driving framework built upon a pretrained VLM, where heterogeneous decoding behaviors are reconciled within a single transformer decoder. We demonstrate that pretrained VLM attention exhibits strong transferability beyond pure language modeling. By organizing visual and structured query tokens within a single causal decoder, structured queries can naturally condition on visual context through the original attention mechanism. Textual and structured outputs share a common attention backbone, enabling stable joint optimization across heterogeneous tasks. Trajectory planning is realized within the same causal LLM decoder by introducing structured trajectory queries. This unified formulation enables planning to share the pretrained attention backbone with images and perception tokens. Extensive experiments on end-to-end autonomous driving benchmarks demonstrate state-of-the-art performance, including 0.28 L2 and 0.18 collision rate on nuScenes open-loop evaluation and competitive results (86.8 PDMS) on NAVSIM closed-loop evaluation. The full model preserves multi-modal generation capability, while an efficient inference mode achieves approximately 40% lower latency. Code and models are available at https://github.com/Z1zyw/OneDrive
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OneDrive, a unified framework for end-to-end autonomous driving that adapts a pretrained Vision-Language Model (VLM) by placing visual tokens and structured query tokens (for perception and trajectory planning) inside a single causal transformer decoder. It claims that heterogeneous behaviors—autoregressive text generation, parallel object detection, and trajectory regression—can be reconciled without separate or cascaded decoders, because structured queries naturally condition on visual context via the original attention mechanism, enabling joint optimization and sharing of the pretrained backbone. The work reports state-of-the-art results including 0.28 L2 error and 0.18 collision rate on nuScenes open-loop evaluation and 86.8 PDMS on NAVSIM closed-loop evaluation, while preserving multi-modal generation and achieving ~40% lower latency in an efficient inference mode. Code and models are released.
Significance. If the central claim holds, the result would show that pretrained VLM attention transfers to structured driving outputs with minimal architectural change, reducing fragmentation in multi-task driving systems and allowing stable joint training across language and trajectory tasks. Notable strengths include the public release of code and models, concrete benchmark numbers on standard open- and closed-loop suites, and the explicit formulation of trajectory planning as structured queries inside the same causal decoder.
major comments (1)
- [Abstract] Abstract: The claim that 'structured queries can naturally condition on visual context through the original attention mechanism' inside a single causal decoder is load-bearing for the paper's central contribution of avoiding major architectural changes. In a standard causal transformer, appending multiple query tokens causes later tokens to attend to earlier ones via self-attention, creating ordering-dependent coupling. This conflicts with the independence required for parallel outputs such as multiple object detections or trajectory points. The abstract provides no description of causal-mask modifications, bidirectional attention within the query block, or query-independent factorization that would preserve the 'original' mechanism while enabling parallelism.
minor comments (2)
- [Abstract] Abstract: The reported benchmark numbers (0.28 L2, 0.18 collision rate, 86.8 PDMS) are given without error bars, standard deviations, or any indication of run-to-run variability, which weakens the strength of the SOTA claim.
- [Abstract] Abstract: The statement that an 'efficient inference mode achieves approximately 40% lower latency' lacks any description of the implementation (e.g., token pruning, early exit, or query reduction), making the efficiency claim difficult to evaluate.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The major comment correctly identifies that the abstract's description of the attention mechanism requires greater precision to support the central claim. We have revised the abstract to clarify token ordering and the use of the standard causal mask. Our point-by-point response is below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'structured queries can naturally condition on visual context through the original attention mechanism' inside a single causal decoder is load-bearing for the paper's central contribution of avoiding major architectural changes. In a standard causal transformer, appending multiple query tokens causes later tokens to attend to earlier ones via self-attention, creating ordering-dependent coupling. This conflicts with the independence required for parallel outputs such as multiple object detections or trajectory points. The abstract provides no description of causal-mask modifications, bidirectional attention within the query block, or query-independent factorization that would preserve the 'original' mechanism while enabling parallelism.
Authors: We agree the abstract is too brief on this point and thank the referee for noting it. In the manuscript (Section 3.2), visual tokens are placed first in the input sequence, followed by the structured query tokens. The decoder applies the unmodified causal mask inherited from the pretrained VLM: each query token attends to all preceding visual tokens (providing the desired conditioning) and to any earlier query tokens. Inter-query attention is retained because it supports feature sharing and joint optimization across tasks; output independence for parallel regression or detection is achieved downstream via separate task-specific heads rather than by altering the attention mask or introducing bidirectional attention within the query block. This design avoids cascaded decoders while using the original mechanism. We have revised the abstract to include the following clarifying sentence: 'Visual tokens precede the structured queries in the sequence, so that queries condition on visual context via the standard causal attention while task-specific heads produce independent parallel outputs.' This change directly addresses the load-bearing claim without architectural modifications. revision: yes
Circularity Check
Empirical unification of decoder tasks with no definitional or fitted reductions
full rationale
The paper describes an architectural unification of text, detection, and trajectory outputs inside one causal VLM decoder, validated empirically on nuScenes and NAVSIM benchmarks with released code. No equations, fitted parameters, or self-citations are presented that reduce the central claim ('structured queries can naturally condition on visual context through the original attention mechanism') to a tautology or input by construction. The work relies on external benchmarks and pretrained VLM transfer rather than internal redefinitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- structured query token embeddings and task-specific heads
axioms (2)
- domain assumption Pretrained VLM attention exhibits strong transferability beyond pure language modeling.
- domain assumption A single causal transformer decoder can stably optimize heterogeneous output types when inputs are tokenized uniformly.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: CVPR (2020)
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: CVPR (2020)
2020
-
[3]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Caesar, H., Kabzan, J., Tan, K.S., Fong, W.K., Wolff, E., Lang, A., Fletcher, L., Beijbom, O., Omari, S.: nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810 (2021)
work page internal anchor Pith review arXiv 2021
-
[4]
In: ECCV (2020)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: ECCV (2020)
2020
-
[5]
In: ECCV (2024)
Chen, J., Wu, Y., Tan, J., Ma, H., Furukawa, Y.: Maptracker: Tracking with strided memory fusion for consistent vector hd mapping. In: ECCV (2024)
2024
-
[6]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Chen,S.,Jiang,B.,Gao,H.,Liao,B.,Xu,Q.,Zhang,Q.,Huang,C.,Liu,W.,Wang, X.: Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv preprint arXiv:2402.13243 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, X., Huang, L., Ma, T., Fang, R., Shi, S., Li, H.: Solve: Synergy of language- vision and end-to-end networks for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12068–12077 (June 2025)
2025
-
[8]
In: ECCV
Chen, Y., Ding, Z.h., Wang, Z., Wang, Y., Zhang, L., Liu, S.: Asynchronous large language model enhanced planner for autonomous driving. In: ECCV. pp. 22–38. Springer (2025)
2025
-
[9]
arXiv preprint arXiv:2412.18607 , year=
Chen, Y., Wang, Y., Zhang, Z.: Drivinggpt: Unifying driving world model- ing and planning with multi-modal autoregressive transformers. arXiv preprint arXiv:2412.18607 (2024)
-
[10]
In: CVPR (2024)
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: CVPR (2024)
2024
-
[11]
arXiv preprint arXiv:2505.23757 (2025) 4
Chi, H., Gao, H.a., Liu, Z., Liu, J., Liu, C., Li, J., Yang, K., Yu, Y., Wang, Z., Li, W., et al.: Impromptu vla: Open weights and open data for driving vision- language-action models. arXiv preprint arXiv:2505.23757 (2025)
-
[12]
IEEE Trans- actions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: Transfuser: Imi- tation with transformer-based sensor fusion for autonomous driving. IEEE Trans- actions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
2022
-
[13]
Contributors, O.: Openscene: The largest up-to-date 3d occupancy predic- tion benchmark in autonomous driving.https://github.com/OpenDriveLab/ OpenScene(2023)
2023
-
[14]
Advances in neural information pro- cessing systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in neural information pro- cessing systems35, 16344–16359 (2022)
2022
-
[15]
Advances in Neural Information Processing Systems37, 28706–28719 (2025)
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschenski, I., Ivanovic, B., Pavone, M., et al.: Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. Advances in Neural Information Processing Systems37, 28706–28719 (2025)
2025
-
[16]
arXiv preprint arXiv:2601.13886 (2026) 16 Y.Zhang et al
Di, S., Zhai, Z., Xie, W.: Revisiting multi-task visual representation learning. arXiv preprint arXiv:2601.13886 (2026) 16 Y.Zhang et al
-
[17]
Fu, H., Zhang, D., Zhao, Z., Cui, J., Liang, D., Zhang, C., Zhang, D., Xie, H., Wang, B., Bai, X.: Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. arXiv preprint arXiv:2503.19755 (2025)
-
[18]
Han, J., Tian, M., Zhu, J., He, F., Zhang, H., Guo, S., Zhu, D., Tang, H., Xu, P., Guo, Y., et al.: Percept-wam: Perception-enhanced world-awareness-action model for robust end-to-end autonomous driving. arXiv preprint arXiv:2511.19221 (2025)
-
[19]
In: CVPR (2023)
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: CVPR (2023)
2023
-
[20]
In: CVPR
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: CVPR. pp. 17853– 17862 (2023)
2023
-
[21]
Huang, J., Huang, G., Zhu, Z., Du, D.: Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790 (2021)
-
[22]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Hwang, J.J., Xu, R., Lin, H., Hung, W.C., Ji, J., Choi, K., Huang, D., He, T., Cov- ington, P., Sapp, B., et al.: Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262 (2024)
work page internal anchor Pith review arXiv 2024
-
[23]
Jia, X., You, J., Zhang, Z., Yan, J.: Drivetransformer: Unified transformer for scalable end-to-end autonomous driving. arXiv preprint arXiv:2503.07656 (2025)
-
[24]
Jiang, B., Chen, S., Liao, B., Zhang, X., Yin, W., Zhang, Q., Huang, C., Liu, W., Wang, X.: Senna: Bridging large vision-language models and end-to-end au- tonomous driving. arXiv preprint arXiv:2410.22313 (2024)
-
[25]
In: ICCV (2023)
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang,C.,Wang,X.:Vad:Vectorizedscenerepresentationforefficientautonomous driving. In: ICCV (2023)
2023
-
[26]
In: ICCV
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang,C.,Wang,X.:Vad:Vectorizedscenerepresentationforefficientautonomous driving. In: ICCV. pp. 8340–8350 (2023)
2023
-
[27]
In: Artificial intelligence and statistics
Lee, C.Y., Xie, S., Gallagher, P., Zhang, Z., Tu, Z.: Deeply-supervised nets. In: Artificial intelligence and statistics. pp. 562–570. Pmlr (2015)
2015
-
[28]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Li, Y., Xiong, K., Guo, X., Li, F., Yan, S., Xu, G., Zhou, L., Chen, L., Sun, H., Wang, B., et al.: Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. arXiv preprint arXiv:2506.08052 (2025)
work page internal anchor Pith review arXiv 2025
-
[29]
arXiv preprint (2024)
Li, Z., Li, K., Wang, S., Lan, S., Yu, Z., Ji, Y., Li, Z., Zhu, Z., Kautz, J., Wu, Z., et al.: Hydra-mdp: End-to-end multimodal planning with multi-target hydra- distillation. arXiv preprint (2024)
2024
-
[30]
In: ECCV (2022)
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Qiao, Y., Dai, J.: Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotem- poral transformers. In: ECCV (2022)
2022
-
[31]
Li, Z., Yu, Z., Lan, S., Li, J., Kautz, J., Lu, T., Alvarez, J.M.: Is ego status all you need for open-loop end-to-end autonomous driving? In: CVPR. pp. 14864–14873 (2024)
2024
-
[32]
In: ICLR (2023)
Liao, B., Chen, S., Wang, X., Cheng, T., Zhang, Q., Liu, W., Huang, C.: Maptr: Structured modeling and learning for online vectorized hd map construction. In: ICLR (2023)
2023
-
[33]
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., et al.: Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. arXiv preprint arXiv:2411.15139 (2024)
-
[34]
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction,
Liao, B., Chen, S., Zhang, Y., Jiang, B., Zhang, Q., Liu, W., Huang, C., Wang, X.: Maptrv2: An end-to-end framework for online vectorized hd map construction. arXiv preprint arXiv:2308.05736 (2023) OneDrive 17
-
[35]
arXiv preprint arXiv:2203.05625 (2022)
Liu, Y., Wang, T., Zhang, X., Sun, J.: Petr: Position embedding transformation for multi-view 3d object detection. arXiv preprint arXiv:2203.05625 (2022)
-
[36]
Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D.L., Han, S.: Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation (2023)
2023
- [37]
-
[38]
DriveLM: Driving with graph visual question answering.arXiv preprint arXiv:2312.14150, 2023
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. arXiv preprint arXiv:2312.14150 (2023)
-
[39]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[40]
Sun, P., Jiang, Y., Xie, E., Shao, W., Yuan, Z., Wang, C., Luo, P.: What makes for end-to-end object detection? In: International Conference on Machine Learning. pp. 9934–9944. PMLR (2021)
2021
-
[41]
Tian,X.,Gu,J.,Li,B.,Liu,Y.,Hu,C.,Wang,Y.,Zhan,K.,Jia,P.,Lang,X.,Zhao, H.: Drivevlm: The convergence of autonomous driving and large vision-language models (2024)
2024
-
[42]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Tian,X.,Gu,J.,Li,B.,Liu,Y.,Hu,C.,Wang,Y.,Zhan,K.,Jia,P.,Lang,X.,Zhao, H.: Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289 (2024)
work page internal anchor Pith review arXiv 2024
-
[43]
Advances in Neural Information Processing Systems36, 18873–18884 (2023)
Wang, H., Li, T., Li, Y., Chen, L., Sima, C., Liu, Z., Wang, B., Jia, P., Wang, Y., Jiang, S., et al.: Openlane-v2: A topology reasoning benchmark for unified 3d hd mapping. Advances in Neural Information Processing Systems36, 18873–18884 (2023)
2023
-
[44]
Wang, J., Li, G., Huang, Z., Dang, C., Ye, H., Han, Y., Chen, L.: Vggdrive: Empow- ering vision-language models with cross-view geometric grounding for autonomous driving. arXiv preprint arXiv:2602.20794 (2026)
-
[45]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
In: ICCV (2023)
Wang, S., Liu, Y., Wang, T., Li, Y., Zhang, X.: Exploring object-centric temporal modeling for efficient multi-view 3d object detection. In: ICCV (2023)
2023
-
[47]
arXiv preprint arXiv:2405.01533 , year=
Wang, S., Yu, Z., Jiang, X., Lan, S., Shi, M., Chang, N., Kautz, J., Li, Y., Alvarez, J.M.: Omnidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning. arXiv preprint arXiv:2405.01533 (2024)
-
[48]
In: CVPR (2024)
Weng, X., Ivanovic, B., Wang, Y., Wang, Y., Pavone, M.: Para-drive: Parallelized architecture for real-time autonomous driving. In: CVPR (2024)
2024
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Weng, Y., Wu, Z., Ren, Y., Zhang, Y., Xu, Y., Liu, Y., Wang, Y., Chen, Y., Li, Y., Zhao, Y.: Para-drive: Parallelized architecture for real-time autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[50]
In: Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Pro- ceedings, Part I 16
Xia, Y., Zhang, Y., Liu, F., Shen, W., Yuille, A.L.: Synthesize then compare: Detecting failures and anomalies for semantic segmentation. In: Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Pro- ceedings, Part I 16. pp. 145–161. Springer (2020)
2020
-
[51]
Xing, S., Qian, C., Wang, Y., Hua, H., Tian, K., Zhou, Y., Tu, Z.: Openemma: Open-source multimodal model for end-to-end autonomous driving. arXiv preprint arXiv:2412.15208 (2024) 18 Y.Zhang et al
-
[52]
In: CVPR (2023)
Yang, C., Chen, Y., Tian, H., Tao, C., Zhu, X., Zhang, Z., Huang, G., Li, H., Qiao, Y., Lu, L., et al.: Bevformer v2: Adapting modern image backbones to bird’s-eye- view recognition via perspective supervision. In: CVPR (2023)
2023
-
[53]
Authorea Preprints (2025)
Yang, Y., Han, C., Mao, R., Wang, H., Chen, Z., Yang, Y., Ma, Q., Chen, X., Shi, S., Zhang, Z.: Survey of general end-to-end autonomous driving: A unified perspective. Authorea Preprints (2025)
2025
-
[54]
arXiv preprint arXiv:2408.03601 (2024) 13
Yuan, C., Zhang, Z., Sun, J., Sun, S., Huang, Z., Lee, C.D.W., Li, D., Han, Y., Wong, A., Tee, K.P., et al.: Drama: An efficient end-to-end motion planner for autonomous driving with mamba. arXiv preprint arXiv:2408.03601 (2024)
-
[55]
arXiv preprint (2023)
Zhai, J.T., Feng, Z., Du, J., Mao, Y., Liu, J.J., Tan, Z., Zhang, Y., Ye, X., Wang, J.: Rethinkingtheopen-loopevaluationofend-to-endautonomousdrivinginnuscenes. arXiv preprint (2023)
2023
-
[56]
Zhang, Y., Gao, J., Ge, F., Luo, G., Li, B., Zhang, Z.X., Ling, H., Hu, W.: Vq- map: Bird’s-eye-view map layout estimation in tokenized discrete space via vector quantization.Advancesin Neural Information Processing Systems37, 70453–70475 (2024)
2024
-
[57]
arXiv preprint arXiv:2601.09247 (2026)
Zhang, Y., Gao, J., Wang, H., Ge, F., Luo, G., Hu, W., Zhang, Z.: Integrating diverse assignment strategies into detrs. arXiv preprint arXiv:2601.09247 (2026)
-
[58]
In: ECCV (2024)
Zheng, W., Chen, W., Huang, Y., Zhang, B., Duan, Y., Lu, J.: Occworld: Learning a 3d occupancy world model for autonomous driving. In: ECCV (2024)
2024
-
[59]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Zheng, Y., Li, X., Li, P., Zheng, Y., Jin, B., Zhong, C., Long, X., Zhao, H., Zhang, Q.: Monoocc: Digging into monocular semantic occupancy prediction. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 18398– 18405. IEEE (2024)
2024
-
[60]
Zhou, Z., Cai, T., Zhao, S.Z., Zhang, Y., Huang, Z., Zhou, B., Ma, J.: Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. arXiv preprint arXiv:2506.13757 (2025)
work page internal anchor Pith review arXiv 2025
-
[61]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Duan, Y., Tian, H., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review arXiv 2025
-
[62]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020)
work page internal anchor Pith review arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.