Recognition: unknown
RAVEN: Retrieval-Augmented Vulnerability Exploration Network for Memory Corruption Analysis in User Code and Binary Programs
Pith reviewed 2026-05-10 04:40 UTC · model grok-4.3
The pith
RAVEN uses LLM agents and retrieval to generate structured vulnerability reports from code samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
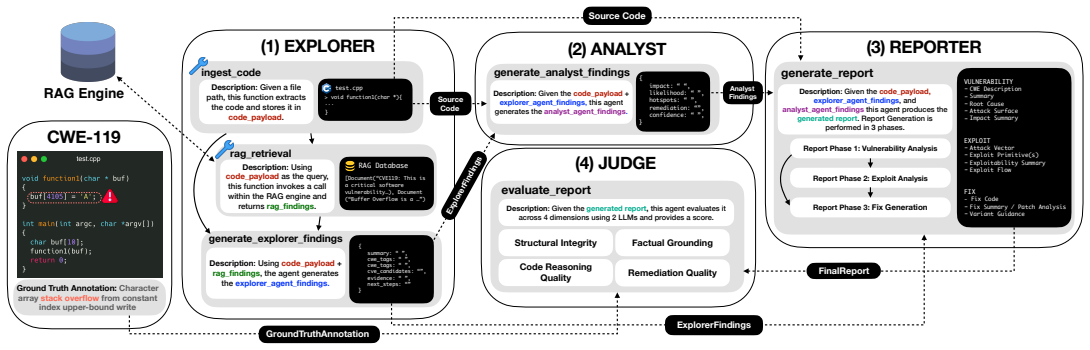
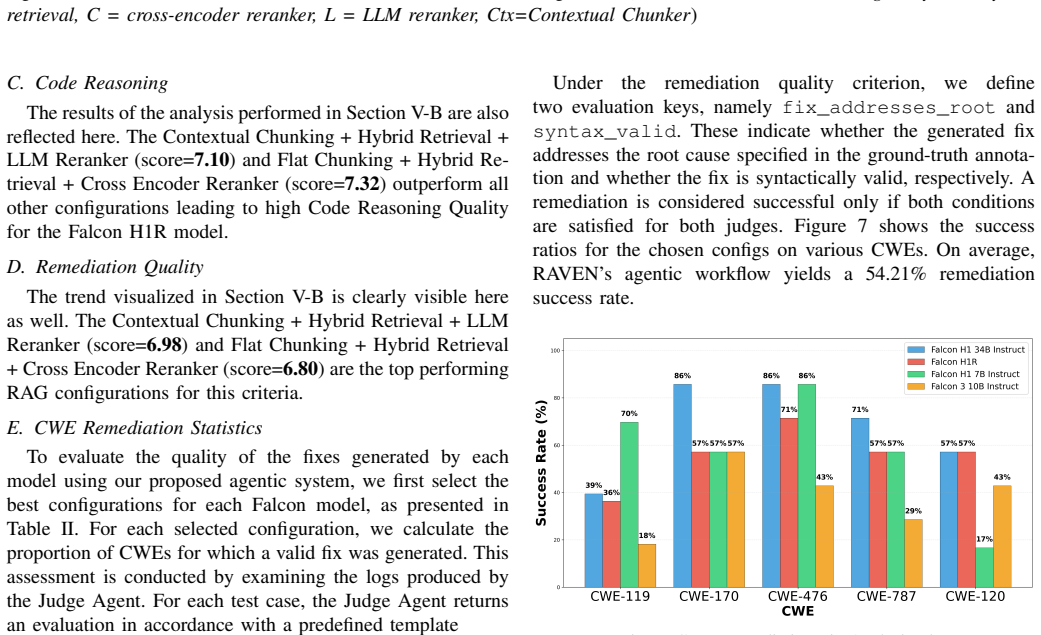
RAVEN deploys four coordinated modules—an Explorer agent for vulnerability identification, a RAG engine drawing from curated databases of Project Zero reports and CWE entries, an Analyst agent for impact and exploitation assessment, and a Reporter agent for structured output—followed by an LLM-based judge that scores reports on structural integrity, ground truth alignment, code reasoning quality, and remediation quality. Tested on 105 vulnerable code samples covering 15 CWE types, the system records an average quality score of 54.21 percent.
What carries the argument
The RAVEN multi-agent pipeline (Explorer, RAG engine, Analyst, Reporter) plus task-specific LLM Judge that evaluates generated reports against fixed criteria.
If this is right
- The framework can produce reports that follow an established Project Zero template for consistency across samples.
- It covers a range of 15 CWE types drawn from a public NIST dataset of vulnerable code.
- Quality evaluation breaks down into four measurable dimensions that can be tracked separately.
- The approach separates identification, analysis, and documentation steps into distinct agents.
- Results provide quantitative support for using retrieval to ground LLM outputs in known vulnerability knowledge.
Where Pith is reading between the lines
- The same agent-plus-retrieval structure could be tested on binary executables to address the memory-corruption focus in the title.
- Replacing or supplementing the LLM judge with human raters would provide a direct check on whether the 54 percent score reflects actual utility.
- Integration of RAVEN outputs into existing bug-tracking systems could reduce the time from discovery to documented report.
- Extending the RAG database beyond Project Zero and CWE entries might improve scores on less common vulnerability classes.
Load-bearing premise
An LLM judge can accurately score report quality on structure, alignment, reasoning, and remediation without human validation or comparison baselines.
What would settle it
Human security experts independently rating the same 105 reports and obtaining average scores materially below 54.21 percent.
Figures




read the original abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities across various cybersecurity tasks, including vulnerability classification, detection, and patching. However, their potential in automated vulnerability report documentation and analysis remains underexplored. We present RAVEN (Retrieval Augmented Vulnerability Exploration Network), a framework leveraging LLM agents and Retrieval Augmented Generation (RAG) to synthesize comprehensive vulnerability analysis reports. Given vulnerable source code, RAVEN generates reports following the Google Project Zero Root Cause Analysis template. The framework uses four modules: an Explorer agent for vulnerability identification, a RAG engine retrieving relevant knowledge from curated databases including Google Project Zero reports and CWE entries, an Analyst agent for impact and exploitation assessment, and a Reporter agent for structured report generation. To ensure quality, RAVEN includes a task specific LLM Judge evaluating reports across structural integrity, ground truth alignment, code reasoning quality, and remediation quality. We evaluate RAVEN on 105 vulnerable code samples covering 15 CWE types from the NIST-SARD dataset. Results show an average quality score of 54.21%, supporting the effectiveness of our approach for automated vulnerability documentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RAVEN, a multi-agent LLM framework with RAG modules (Explorer, RAG engine drawing from Project Zero and CWE databases, Analyst, Reporter) that takes vulnerable source code and produces structured vulnerability reports following the Google Project Zero Root Cause Analysis template. It evaluates the system on 105 NIST-SARD samples spanning 15 CWE types using a task-specific LLM judge that scores reports on structural integrity, ground truth alignment, code reasoning, and remediation, reporting an average quality score of 54.21%.
Significance. If the evaluation methodology were strengthened with human validation and baselines, the work could provide a useful template for automated vulnerability documentation pipelines. As presented, the headline metric does not yet constitute strong evidence of effectiveness because it lacks calibration against human experts or simpler non-RAG baselines.
major comments (2)
- [Abstract] Abstract and evaluation description: the effectiveness claim is supported solely by a 54.21% average LLM-judge score on 105 samples, yet the manuscript provides no baselines (e.g., zero-shot LLM generation without the Explorer/Analyst/RAG components), no statistical significance tests, no inter-rater agreement for the judge, and no human re-scoring of any subset. This renders the numerical result uninterpretable as evidence that RAVEN improves report quality.
- [Evaluation] Evaluation protocol (LLM Judge section): the judge itself is an LLM from the same model family as the generation agents and is never calibrated against human experts or compared to ground-truth human-written reports. Any systematic bias in the judge directly affects the reported 54.21% score, and the paper contains no ablation showing that the RAG or multi-agent modules raise judge scores above a plain LLM baseline.
minor comments (2)
- [Title] Title vs. content mismatch: the title emphasizes 'Memory Corruption Analysis in User Code and Binary Programs', yet the abstract, dataset (NIST-SARD source-code samples), and reported experiments address general vulnerability report generation without reference to binary analysis or memory-corruption-specific techniques.
- [Framework Description] Notation and module descriptions: the four-module architecture is described at a high level; a diagram or pseudocode showing the exact information flow between Explorer, RAG engine, Analyst, and Reporter would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the current evaluation lacks baselines and human calibration, which limits interpretability of the 54.21% score. Below we respond point-by-point and describe the revisions we will make to strengthen the evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the effectiveness claim is supported solely by a 54.21% average LLM-judge score on 105 samples, yet the manuscript provides no baselines (e.g., zero-shot LLM generation without the Explorer/Analyst/RAG components), no statistical significance tests, no inter-rater agreement for the judge, and no human re-scoring of any subset. This renders the numerical result uninterpretable as evidence that RAVEN improves report quality.
Authors: We acknowledge this limitation. The reported score reflects the LLM judge's assessment against the defined criteria (structural integrity, ground-truth alignment, code reasoning, and remediation), but without baselines it is difficult to attribute gains to the multi-agent RAG design. In the revised manuscript we will add a zero-shot LLM baseline (same model family, no Explorer/Analyst/RAG) and report the delta in judge scores. We will also include statistical significance testing (e.g., paired t-tests or Wilcoxon tests) on the per-sample scores. For human validation we will re-score a random subset of 20 reports with two independent human experts and compute inter-rater agreement (Cohen's kappa) between humans and between humans and the LLM judge; we will report these results and any discrepancies. The abstract will be updated to state that the 54.21% figure is an LLM-judge score and to note the new baseline comparison. revision: yes
-
Referee: [Evaluation] Evaluation protocol (LLM Judge section): the judge itself is an LLM from the same model family as the generation agents and is never calibrated against human experts or compared to ground-truth human-written reports. Any systematic bias in the judge directly affects the reported 54.21% score, and the paper contains no ablation showing that the RAG or multi-agent modules raise judge scores above a plain LLM baseline.
Authors: We agree that using an LLM judge from the same family introduces potential bias and that an ablation is necessary. We will add an explicit ablation section comparing (1) plain zero-shot generation, (2) single-agent generation without RAG, and (3) full RAVEN, all evaluated by the same judge. To address calibration we will conduct a human study on the 20-report subset mentioned above, comparing human-assigned quality scores to the LLM-judge scores and reporting correlation and mean absolute difference. While we cannot retroactively change the judge model family without re-running all experiments, we will discuss the bias risk explicitly and note that the structured rubric (with explicit rubrics for each dimension) was designed to reduce subjectivity. These additions will be included in the revised evaluation section. revision: yes
Circularity Check
No circularity: empirical framework with external evaluation dataset and no derivations or self-referential reductions
full rationale
The paper presents RAVEN as an LLM-agent + RAG framework for generating vulnerability reports following a Google Project Zero template, evaluated on 105 NIST-SARD samples across 15 CWE types. The reported 54.21% average quality score comes from a separate task-specific LLM judge assessing structural integrity, ground truth alignment, code reasoning, and remediation. No equations, parameters, or derivation chains exist that could reduce outputs to inputs by construction. The evaluation uses an external benchmark dataset and does not rely on self-citations, fitted predictions, or uniqueness theorems imported from prior author work. The judge is described as an independent quality module rather than a tautological re-use of the generator's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can perform vulnerability identification, impact assessment, and structured report generation when augmented with retrieved context from curated databases.
Reference graph
Works this paper leans on
-
[1]
Survey of different large language model architectures: Trends, benchmarks, and challenges,
M. Shaoet al., “Survey of different large language model architectures: Trends, benchmarks, and challenges,”IEEE Access, 2024
2024
-
[2]
From trace to line: Llm agent for real-world oss vulnerability localization,
H. Xiet al., “From trace to line: Llm agent for real-world oss vulnerability localization,”arXiv preprint arXiv:2510.02389, 2025
-
[3]
PentestGPT: Evaluating and harnessing large language models for automated penetration testing,
G. Denget al., “PentestGPT: Evaluating and harnessing large language models for automated penetration testing,” in33rd USENIX Security Symposium. USENIX Association, Aug. 2024, pp. 847–864
2024
-
[4]
A case study of llm for automated vulnerability repair: Assessing impact of reasoning and patch validation feedback,
U. Kulsumet al., “A case study of llm for automated vulnerability repair: Assessing impact of reasoning and patch validation feedback,” inProceedings of the 1st ACM International Conference on AI-Powered Software, ser. AIware 2024. ACM, 2024, p. 103–111
2024
-
[5]
An empirical evaluation of llms for solving offensive security challenges
M. Shaoet al., “An empirical evaluation of llms for solving offensive security challenges,”arXiv preprint arXiv:2402.11814, 2024
-
[6]
0-days In-the-Wild
Root Cause Analyses. 0-days In-the-Wild. [Online]. Available: https://googleprojectzero.github.io/0days-in-the-wild/rca.html
-
[7]
CodeBERT: A pre-trained model for programming and natural languages,
Z. Fenget al., “CodeBERT: A pre-trained model for programming and natural languages,” inFindings of the Association for Computational Linguistics: EMNLP 2020, T. Cohnet al., Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 1536–1547
2020
-
[8]
Graphcode{bert}: Pre-training code representations with data flow,
D. Guoet al., “Graphcode{bert}: Pre-training code representations with data flow,” inICLR, 2021
2021
-
[9]
Code llama: Open foundation models for code,
B. Rozi `ereet al., “Code llama: Open foundation models for code,”
-
[10]
Code Llama: Open Foundation Models for Code
[Online]. Available: https://arxiv.org/abs/2308.12950
work page internal anchor Pith review arXiv
-
[11]
Gosonar: Detecting logical vulnerabilities in memory safe language using inductive constraint reasoning,
M. S. Anwaret al., “Gosonar: Detecting logical vulnerabilities in memory safe language using inductive constraint reasoning,” in2025 IEEE Symposium on Security and Privacy (SP), 2025, pp. 758–773
2025
-
[12]
SV-TrustEval-C: Evaluating Structure and Semantic Reasoning in Large Language Models for Source Code Vulnerability Analysis ,
Y . Liet al., “ SV-TrustEval-C: Evaluating Structure and Semantic Reasoning in Large Language Models for Source Code Vulnerability Analysis ,” in2025 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, May 2025, pp. 3014–3032
2025
-
[13]
Benchmarking LLMs and LLM-based agents in practical vulnerability detection for code repositories,
A. Yildizet al., “Benchmarking LLMs and LLM-based agents in practical vulnerability detection for code repositories,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. ACL, Jul. 2025, pp. 30 848–30 865
2025
-
[14]
M2cvd: Enhancing vulnerability understanding through multi-model collaboration for code vulnerability detection,
Z. Wanget al., “M2cvd: Enhancing vulnerability understanding through multi-model collaboration for code vulnerability detection,”ACM Trans. Softw. Eng. Methodol., Oct. 2025
2025
-
[15]
Llmxcpg: context-aware vulnerability detection through code property graph-guided large language models,
A. Lekssayset al., “Llmxcpg: context-aware vulnerability detection through code property graph-guided large language models,” inPro- ceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USENIX Association, 2025
2025
-
[16]
Vulrepair: a t5-based automated software vulnerability repair,
M. Fuet al., “Vulrepair: a t5-based automated software vulnerability repair,” ser. ESEC/FSE 2022. ACM, 2022, p. 935–947
2022
-
[17]
Prompting is all you need: Automated android bug replay with large language models,
S. Fenget al., “Prompting is all you need: Automated android bug replay with large language models,” inICSE, 2024
2024
-
[18]
Out of sight, out of mind: Better automatic vulnerability repair by broadening input ranges and sources,
X. Zhouet al., “Out of sight, out of mind: Better automatic vulnerability repair by broadening input ranges and sources,” inProceedings of the IEEE/ACM 46th ICSE, ser. ICSE ’24. ACM, 2024
2024
-
[19]
Llm-assisted static analysis for detecting security vulner- abilities,
Z. Liet al., “Llm-assisted static analysis for detecting security vulner- abilities,” inICLR, 2025
2025
-
[20]
In: 44th IEEE Symposium on Security and Privacy, SP 2023, San Francisco, CA, USA, May 21-25, 2023
H. Pearceet al., “ Examining Zero-Shot Vulnerability Repair with Large Language Models ,” in2023 IEEE Symposium on Security and Privacy (SP), 2023, pp. 2339–2356. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/SP46215.2023.10179420
-
[21]
Pentestagent: Incorporating llm agents to automated penetration testing,
X. Shenet al., “Pentestagent: Incorporating llm agents to automated penetration testing,” inProceedings of the 20th ACM Asia Conference on Computer and Communications Security, ser. ASIA CCS ’25. As- sociation for Computing Machinery, 2025, p. 375–391
2025
-
[22]
arXiv preprint arXiv:2505.17107 , url=
M. Shao,et al., “Craken: Cybersecurity llm agent with knowledge-based execution,”arXiv preprint arXiv:2505.17107, 2025
-
[23]
TrojanLoC: Fine-grained hardware Trojan detection from Verilog code,
W. Xiaoet al., “Trojanloc: Llm-based framework for rtl trojan localiza- tion,”arXiv preprint arXiv:2512.00591, 2025
-
[24]
M. Udeshiet al., “D-cipher: Dynamic collaborative intelligent multi- agent system with planner and heterogeneous executors for offensive security,”arXiv preprint arXiv:2502.10931, 2025
-
[25]
Red-teaming LLM multi-agent systems via communication attacks,
P. Heet al., “Red-teaming LLM multi-agent systems via communication attacks,” inFindings of the ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: ACL, Jul. 2025, pp. 6726–6747. [Online]. Available: https://aclanthology.org/2025.finding s-acl.349/
2025
-
[26]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge,
D. Liet al., “From generation to judgment: Opportunities and challenges of LLM-as-a-judge,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: ACL, Nov. 2025, pp. 2757–2791. [Online]. Available: https://aclanthology.org/2025.emnlp-main.138/
2025
-
[27]
Can you really trust code copilot? evaluating large language models from a code security perspective,
Y . Mouet al., “Can you really trust code copilot? evaluating large language models from a code security perspective,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguistics, Jul....
2025
-
[28]
M. Shaoet al., “Towards effective offensive security llm agents: Hy- perparameter tuning, llm as a judge, and a lightweight ctf benchmark,” arXiv preprint arXiv:2508.05674, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
B. Chenet al., “Metacipher: A general and extensible reinforcement learning framework for obfuscation-based jailbreak attacks on black-box llms,”arXiv preprint arXiv:2506.22557, 2025
-
[30]
Is LLM-as-a-judge robust? investigating universal adversarial attacks on zero-shot LLM assessment,
V . Rainaet al., “Is LLM-as-a-judge robust? investigating universal adversarial attacks on zero-shot LLM assessment,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. ACL, Nov. 2024, pp. 7499–7517
2024
-
[31]
Crawl4ai: Open-source llm friendly web crawler & scraper,
UncleCode, “Crawl4ai: Open-source llm friendly web crawler & scraper,” 2024
2024
-
[32]
Common weakness enumeration (cwe) version 4.17,
MITRE Corporation, “Common weakness enumeration (cwe) version 4.17,” MITRE Corporation, Tech. Rep., Apr. 2025
2025
-
[33]
Chandra: Ocr model for complex documents,
Datalab, “Chandra: Ocr model for complex documents,” https://huggin gface.co/datalab-to/chandra, 2025
2025
-
[34]
[Online]
Contextual Retrieval in AI Systems. [Online]. Available: https: //www.anthropic.com/engineering/contextual-retrieval
-
[35]
SecureBERT 2.0: Advanced Language Model for Cybersecurity Intelligence,
E. Aghaeiet al., “SecureBERT 2.0: Advanced Language Model for Cybersecurity Intelligence,” Oct. 2025
2025
- [36]
-
[37]
Software Assurance Reference Dataset (SARD),
“Software Assurance Reference Dataset (SARD),”NIST, Feb. 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.