Recognition: unknown
Modular Representation Compression: Adapting LLMs for Efficient and Effective Recommendations
Pith reviewed 2026-05-10 04:06 UTC · model grok-4.3
The pith
Explicit modularity control in LLMs overcomes final-layer degradation to enable efficient recommendation representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We identify Mid-layer Representation Advantage (MRA) where mid-layer LLM representations outperform final layers on recommendation tasks. Interpreting this as arising from spontaneous functional modularity that forces final-layer specialization in the proxy training task, we propose MARC. It uses Modular Adjustment to insert explicit compression and task-adaptation modules so the LLM functions strictly as a representation learner, and Modular Task Decoupling to separate tasks via information constraints and different network structures, yielding efficient representations validated in offline tests and an online A/B experiment.
What carries the argument
MARC, the two-part method of Modular Adjustment to insert compression and adaptation modules and Modular Task Decoupling via information constraints plus varied network structures to ground each module to its task.
If this is right
- LLM representations can be compressed to practical sizes for industrial recommendation systems without sacrificing effectiveness.
- Recommendation models gain access to higher-quality features by drawing from controlled mid-layer outputs rather than degraded final layers.
- The same modular approach supports real-time deployment in high-volume commercial scenarios such as search advertising.
- Existing final-layer compression techniques become more effective once the underlying modularity issue is handled explicitly.
Where Pith is reading between the lines
- The same modular adjustment pattern could be tested on LLMs for other transfer tasks where final layers underperform, such as ranking or retrieval.
- Training regimes that enforce modularity from the start might reduce the need for post-hoc fixes when adapting LLMs to multiple downstream applications.
- The decoupling mechanism suggests a route to parameter-efficient adaptation that preserves the model's original capabilities while adding new task-specific paths.
Load-bearing premise
LLMs develop spontaneous internal functional modularity that forces the final layer to specialize in the proxy training task and thereby degrade its representations for recommendation tasks.
What would settle it
A controlled experiment in which final-layer LLM representations after standard compression match or exceed mid-layer performance on recommendation metrics, or an online deployment of MARC that shows no measurable eCPM improvement.
Figures







read the original abstract
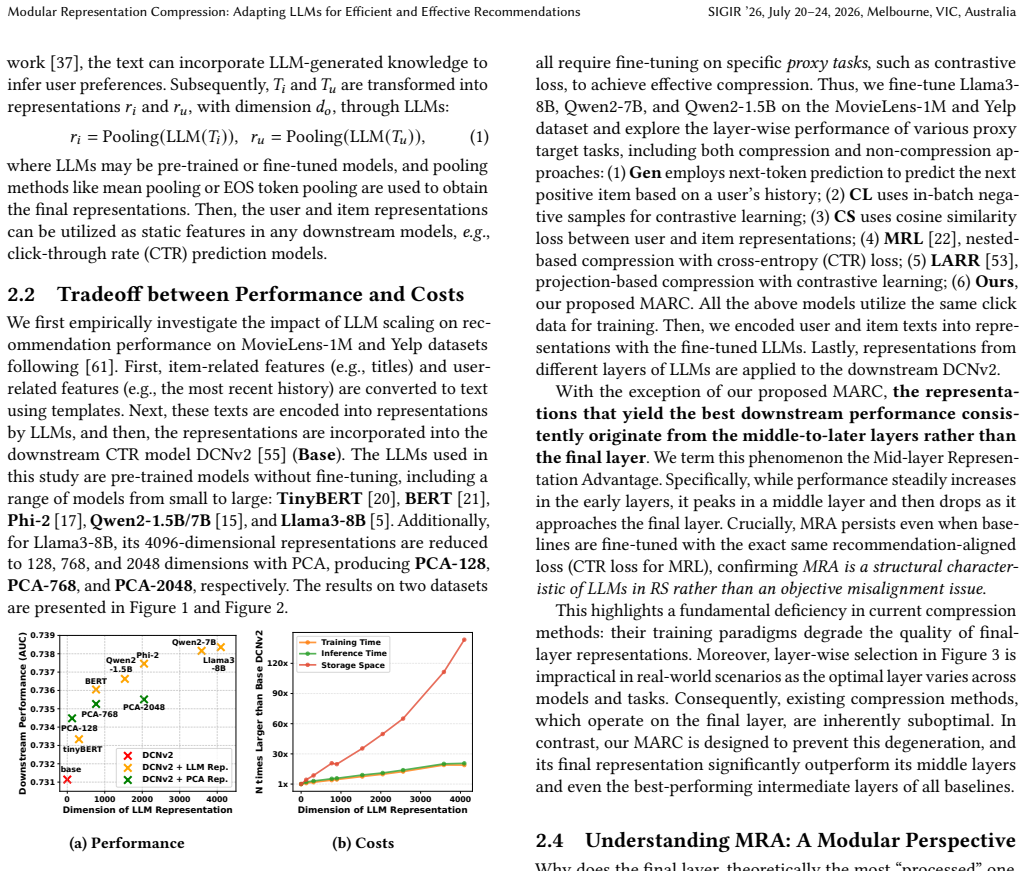
Recently, large language models (LLMs) have advanced recommendation systems (RSs), and recent works have begun to explore how to integrate LLMs into industrial RSs. While most approaches deploy LLMs offline to generate and pre-cache augmented representations for RSs, high-dimensional representations from LLMs introduce substantial storage and computational costs. Thus, it is crucial to compress LLM representations effectively. However, we identify a counterintuitive phenomenon during representation compression: Mid-layer Representation Advantage (MRA), where representations from middle layers of LLMs outperform those from final layers in recommendation tasks. This degraded final layer renders existing compression methods, which typically compress on the final layer, suboptimal. We interpret this based on modularity theory that LLMs develop spontaneous internal functional modularity and force the final layer to specialize in the proxy training task. Thus, we propose \underline{M}odul\underline{a}r \underline{R}epresentation \underline{C}ompression (MARC) to explicitly control the modularity of LLMs. First, Modular Adjustment explicitly introduces compression and task adaptation modules, enabling the LLM to operate strictly as a representation-learning module. Next, to ground each module to its specific task, Modular Task Decoupling uses information constraints and different network structures to decouple tasks. Extensive experiments validate that MARC addresses MRA and produces efficient representations. Notably, MARC achieved a 2.82% eCPM lift in an online A/B test within a large-scale commercial search advertising scenario.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a Mid-layer Representation Advantage (MRA) in LLMs for recommendation tasks, where middle-layer representations outperform final-layer ones. It attributes MRA to spontaneous internal functional modularity that causes the final layer to specialize in the proxy pre-training task. The authors propose Modular Representation Compression (MARC) with two components: Modular Adjustment (inserting explicit compression and task-adaptation modules so the LLM acts as a representation learner) and Modular Task Decoupling (using information constraints and distinct network structures to ground modules to their tasks). Extensive experiments are claimed to validate that MARC addresses MRA and yields efficient representations, with a reported 2.82% eCPM lift in an online A/B test on a large-scale commercial search advertising platform.
Significance. If the MRA phenomenon and its modularity-based explanation hold, and if MARC's gains are causally tied to explicit modularity control rather than added capacity, the work could enable more efficient deployment of LLMs in industrial recommendation systems by reducing high-dimensional representation storage and compute costs while maintaining or improving effectiveness. The online A/B test result provides a concrete indicator of practical impact in a production setting.
major comments (3)
- [Abstract / Introduction] The central motivation for MARC rests on the claim (Abstract and Introduction) that MRA arises specifically from spontaneous LLM internal functional modularity forcing final-layer specialization in the proxy task. No layer-probing, mutual-information, or representational similarity analyses are presented to test this mechanism against alternatives such as generic depth effects or optimization dynamics; without such evidence the specific design of Modular Adjustment and Modular Task Decoupling is not guaranteed to be the appropriate remedy.
- [Experiments / Online Evaluation] §5 (Experiments) and the online A/B test description report a 2.82% eCPM lift but supply no details on baseline systems, statistical testing, traffic allocation, or controls for confounding factors in the commercial search advertising scenario. This information is load-bearing for evaluating whether MARC's components, rather than extra parameters or training tricks, drive the observed improvement.
- [Experiments / Ablation Studies] The ablation studies claimed to validate that MARC addresses MRA lack quantitative isolation of the Modular Adjustment and Decoupling contributions (e.g., performance when only compression is added versus full MARC). If the gains are not shown to exceed those from generic capacity increases, the modularity-control hypothesis remains unconfirmed.
minor comments (2)
- [Method] Notation for the Modular Adjustment module and information constraints in the method section could be clarified with explicit equations or pseudocode to facilitate reproduction.
- [Related Work] The manuscript should include references to prior work on LLM layer-wise representation analysis and modularity in neural networks to situate the MRA interpretation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with clarifications on the existing evidence and commitments to strengthen the manuscript through targeted revisions.
read point-by-point responses
-
Referee: [Abstract / Introduction] The central motivation for MARC rests on the claim (Abstract and Introduction) that MRA arises specifically from spontaneous LLM internal functional modularity forcing final-layer specialization in the proxy task. No layer-probing, mutual-information, or representational similarity analyses are presented to test this mechanism against alternatives such as generic depth effects or optimization dynamics; without such evidence the specific design of Modular Adjustment and Modular Task Decoupling is not guaranteed to be the appropriate remedy.
Authors: We acknowledge that the current manuscript relies on empirical demonstration of MRA via layer-wise performance curves (Section 4) and the theoretical grounding from modularity literature rather than direct mechanistic probes such as mutual-information estimation or CKA-based representational similarity. The design of MARC is motivated by the consistent observation that final-layer representations underperform middle layers across multiple LLMs and datasets, which existing compression methods fail to address. In revision we will add a dedicated analysis subsection that includes layer-probing results, mutual-information estimates between layer representations and recommendation labels, and similarity metrics comparing middle vs. final layers to distinguish modularity effects from generic depth or optimization artifacts. This will provide stronger support for why the modular adjustment and decoupling components are the appropriate remedy. revision: yes
-
Referee: [Experiments / Online Evaluation] §5 (Experiments) and the online A/B test description report a 2.82% eCPM lift but supply no details on baseline systems, statistical testing, traffic allocation, or controls for confounding factors in the commercial search advertising scenario. This information is load-bearing for evaluating whether MARC's components, rather than extra parameters or training tricks, drive the observed improvement.
Authors: We agree that the online evaluation section requires substantially more detail to allow readers to assess causality. In the revised manuscript we will expand Section 5.4 with: explicit descriptions of all baseline systems (production RS, uncompressed LLM representations, and non-modular compression baselines); statistical testing methodology including p-values and confidence intervals for the reported 2.82% eCPM lift; traffic allocation (randomized 50/50 split with user-level randomization); and controls for confounding factors such as time-of-day, campaign effects, and user cohort balancing. These additions will clarify that the observed gains are attributable to MARC rather than incidental capacity or training differences. revision: yes
-
Referee: [Experiments / Ablation Studies] The ablation studies claimed to validate that MARC addresses MRA lack quantitative isolation of the Modular Adjustment and Decoupling contributions (e.g., performance when only compression is added versus full MARC). If the gains are not shown to exceed those from generic capacity increases, the modularity-control hypothesis remains unconfirmed.
Authors: The existing ablation studies (Section 5.2 and associated tables) compare full MARC against several variants and show consistent gains, but we recognize they do not fully isolate the individual contributions or rule out generic capacity effects. In revision we will augment the ablation suite with: (1) a compression-only variant (Modular Adjustment without task adaptation), (2) a capacity-matched baseline that adds equivalent parameters without the modular structure or information constraints, and (3) quantitative metrics tracking how each component reduces the MRA gap. These new results will be presented alongside the current tables to provide clearer isolation of the modularity-control mechanism. revision: yes
Circularity Check
No circularity: empirical observation drives method, validated externally
full rationale
The paper first reports an empirical observation (MRA: middle layers outperforming final layers on recommendation tasks), offers an interpretation drawn from modularity theory without reducing it to a fitted parameter or self-citation chain, then introduces MARC components (Modular Adjustment and Modular Task Decoupling) as an explicit intervention. Validation rests on separate experiments and a live A/B test reporting a 2.82% eCPM lift, none of which are shown to be tautological with the input data or definitions. No equations, predictions, or uniqueness claims collapse back to the inputs by construction, satisfying the requirement for independent content against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs develop spontaneous internal functional modularity
invented entities (3)
-
Mid-layer Representation Advantage (MRA)
no independent evidence
-
Modular Adjustment module
no independent evidence
-
Modular Task Decoupling
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He
- [2]
- [3]
- [4]
-
[5]
Qian Dong, Yiding Liu, Qingyao Ai, Zhijing Wu, Haitao Li, Yiqun Liu, Shuaiqiang Wang, Dawei Yin, and Shaoping Ma. 2024. Unsupervised large language model Modular Representation Compression: Adapting LLMs for Efficient and Effective Recommendations SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia alignment for information retrieval via contrastive fe...
2024
-
[6]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [7]
-
[8]
Binzong Geng, Zhaoxin Huan, Xiaolu Zhang, Yong He, Liang Zhang, Fajie Yuan, Jun Zhou, and Linjian Mo. 2024. Breaking the length barrier: Llm-enhanced CTR prediction in long textual user behaviors. InSIGIR’24. 2311–2315
2024
-
[9]
Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Schölkopf. 2005. Measuring statistical dependence with Hilbert-Schmidt norms. InInternational conference on algorithmic learning theory. Springer, 63–77
2005
- [10]
-
[11]
R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. 2018. Learning deep represen- tations by mutual information estimation and maximization.arXiv preprint arXiv:1808.06670(2018)
work page Pith review arXiv 2018
-
[12]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. 2024. Enhancing sequential recommendation via llm-based semantic embedding learning. InCompanion Proceedings of the ACM on Web Conference 2024. 103–111
2024
-
[14]
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. InProceedings of the 22nd ACM international conference on Information & Knowledge Management. 2333–2338
2013
-
[15]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: combining fea- ture importance and bilinear feature interaction for click-through rate prediction. InProceedings of the 13th ACM conference on recommender systems. 169–177
2019
-
[16]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review arXiv 2024
-
[17]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated Gain-Based Evaluation of IR Techniques.ACM Trans. Inf. Syst.(2002), 422–446
2002
-
[18]
Mojan Javaheripi, Sébastien Bubeck, Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio César Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al . 2023. Phi-2: The surprising power of small language models.Microsoft Research Blog1, 3 (2023), 3
2023
- [19]
-
[20]
Ting Jiang, Shaohan Huang, Zhongzhi Luan, Deqing Wang, and Fuzhen Zhuang
- [21]
- [22]
-
[23]
Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, Vol. 1. Minneapolis, Minnesota
2019
-
[24]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. 2022. Matryoshka representation learning.Advances in Neural Information Processing Systems35 (2022), 30233–30249
2022
- [25]
- [26]
-
[27]
Xianming Li and Jing Li. 2024. AoE: Angle-optimized embeddings for semantic textual similarity. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1825–1839
2024
-
[28]
Xianming Li and Jing Li. 2024. BeLLM: Backward Dependency Enhanced Large Language Model for Sentence Embeddings. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 792–804
2024
-
[29]
Zekun Li, Zeyu Cui, Shu Wu, Xiaoyu Zhang, and Liang Wang. 2019. Fi-gnn: Modeling feature interactions via graph neural networks for ctr prediction. In CIKM’19. 539–548
2019
-
[30]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature in- teractions for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763
2018
-
[31]
Jianghao Lin, Bo Chen, Hangyu Wang, Yunjia Xi, Yanru Qu, Xinyi Dai, Kangning Zhang, Ruiming Tang, Yong Yu, and Weinan Zhang. 2024. ClickPrompt: CTR models are strong prompt generators for adapting language models to CTR prediction. InProceedings of the ACM Web Conference 2024. 3319–3330
2024
-
[32]
Jianghao Lin, Xinyi Dai, Rong Shan, Bo Chen, Ruiming Tang, Yong Yu, and Weinan Zhang. 2025. Large language models make sample-efficient recommender systems.Frontiers of Computer Science19, 4 (2025), 194328
2025
-
[33]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, et al . 2025. How can recommender systems benefit from large language models: A survey.ACM Transactions on Information Systems43, 2 (2025), 1–47
2025
-
[34]
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, and Weinan Zhang. 2024. Rella: Retrieval-enhanced large language models for lifelong sequential behavior comprehension in recom- mendation. InProceedings of the ACM on Web Conference 2024. 3497–3508
2024
-
[35]
Chengkai Liu, Jianghao Lin, Hanzhou Liu, Jianling Wang, and James Caverlee
-
[36]
InProceedings of the 33rd ACM international conference on information and knowledge management
Behavior-dependent linear recurrent units for efficient sequential recom- mendation. InProceedings of the 33rd ACM international conference on information and knowledge management. 1430–1440
-
[37]
Chengkai Liu, Jianghao Lin, Jianling Wang, Hanzhou Liu, and James Caverlee
- [38]
- [39]
-
[40]
Qijiong Liu, Nuo Chen, Tetsuya Sakai, and Xiao-Ming Wu. 2024. Once: Boosting content-based recommendation with both open-and closed-source large language models. InWSDM’24. 452–461
2024
- [41]
- [42]
-
[43]
Wan-Duo Kurt Ma, JP Lewis, and W Bastiaan Kleijn. 2020. The HSIC bottleneck: Deep learning without back-propagation. InProceedings of the AAAI conference on artificial intelligence, Vol. 34. 5085–5092
2020
-
[44]
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. 2024. Fine- tuning llama for multi-stage text retrieval. InSIGIR’24. 2421–2425
2024
-
[45]
Andrzej Maćkiewicz and Waldemar Ratajczak. 1993. Principal components analysis (PCA).Computers & Geosciences19, 3 (1993), 303–342
1993
-
[46]
MindSpore Team. 2020. MindSpore: A new open source deep learning train- ing/inference framework that could be used for mobile, edge and cloud scenarios. https://www.mindspore.cn/ Accessed: 2026-04
2020
- [47]
-
[48]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, et al. 2019. Personalized re-ranking for recommendation. InRecsys’19. 3–11
2019
-
[50]
Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, and Lawrence Carin. 2016. Variational autoencoder for deep learning of images, labels and captions.Advances in neural information processing systems29 (2016)
2016
-
[51]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation learning with large language models for recommendation. InProceedings of WWW 2024. 3464–3475
2024
-
[52]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self- attentive neural networks. InProceedings of the 28th ACM international conference on information and knowledge management. 1161–1170
2019
-
[53]
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, and Li. 2024. Idgenrec: Llm-recsys alignment with textual id learning. InSIGIR’24’. 355–364
2024
-
[54]
Changxin Tian, Binbin Hu, Chunjing Gan, Haoyu Chen, Zhuo Zhang, Li Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, and Jiawei Chen. 2024. ReLand: Integrating Large Language Models’ Insights into Industrial Recommenders via a Controllable Reasoning Pool. InRecsys’24. 63–73
2024
-
[55]
Naftali Tishby and Noga Zaslavsky. 2015. Deep learning and the information bottleneck principle. In2015 IEEE Information Theory Workshop (ITW). IEEE, 1–5. https://doi.org/10.1109/ITW.2015.7133169 SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Yunjia Xi et al
-
[56]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Zhizhong Wan, Bin Yin, Junjie Xie, Fei Jiang, Xiang Li, and Wei Lin. 2024. LARR: Large Language Model Aided Real-time Scene Recommendation with Semantic Understanding. InProceedings of Recsys. 23–32
2024
-
[58]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[59]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InWWW’21. 1785–1797
2021
- [60]
-
[61]
Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, and Xiao Wang. 2024. Can Small Language Models be Good Reasoners for Sequential Recommendation?. InProceedings of the ACM on Web Conference 2024. 3876–3887
2024
-
[62]
Yasi Wang, Hongxun Yao, and Sicheng Zhao. 2016. Auto-encoder based dimen- sionality reduction.Neurocomputing184 (2016), 232–242
2016
- [63]
- [64]
- [65]
- [66]
- [67]
- [68]
-
[69]
Yunjia Xi, Weiwen Liu, Yang Wang, Ruiming Tang, Weinan Zhang, Yue Zhu, Rui Zhang, and Yong Yu. 2023. On-device integrated re-ranking with heteroge- neous behavior modeling. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5225–5236
2023
-
[70]
Yunjia Xi, Hangyu Wang, Bo Chen, Jianghao Lin, Menghui Zhu, Weiwen Liu, Ruiming Tang, Zhewei Wei, Weinan Zhang, and Yong Yu. 2025. Efficiency un- leashed: Inference acceleration for LLM-based recommender systems with spec- ulative decoding. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1891–1901
2025
- [71]
-
[72]
Yunjia Xi, Muyan Weng, Wen Chen, Chao Yi, Dian Chen, Gaoyang Guo, Mao Zhang, Jian Wu, Yuning Jiang, Qingwen Liu, et al. 2025. Bursting filter bubble: Enhancing serendipity recommendations with aligned large language models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5059–5070
2025
- [73]
- [74]
-
[75]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Jundong Li, and Zi Huang. 2023. Self-supervised learning for recommender systems: A survey.IEEE Transactions on Knowledge and Data Engineering(2023)
2023
-
[76]
Yisong Yue, Thomas Finley, Filip Radlinski, and Thorsten Joachims. 2007. A support vector method for optimizing average precision. InSIGIR’07. 271–278
2007
-
[77]
Chao Zhang, Shiwei Wu, Haoxin Zhang, Tong Xu, Yan Gao, Yao Hu, and En- hong Chen. 2024. NoteLLM: A Retrievable Large Language Model for Note Recommendation. InCompanion Proceedings of WWW. 170–179
2024
- [78]
-
[79]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448
2024
-
[80]
Zhi Zheng, Wenshuo Chao, Zhaopeng Qiu, Hengshu Zhu, and Hui Xiong. 2024. Harnessing large language models for text-rich sequential recommendation. In Proceedings of the ACM on Web Conference 2024. 3207–3216
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.