Recognition: unknown
Enhancing Glass Surface Reconstruction via Depth Prior for Robot Navigation
Pith reviewed 2026-05-10 03:54 UTC · model grok-4.3
The pith
A training-free fusion of depth foundation model priors with raw sensor data via local RANSAC alignment recovers accurate metric-scale depth on glass surfaces for robot navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
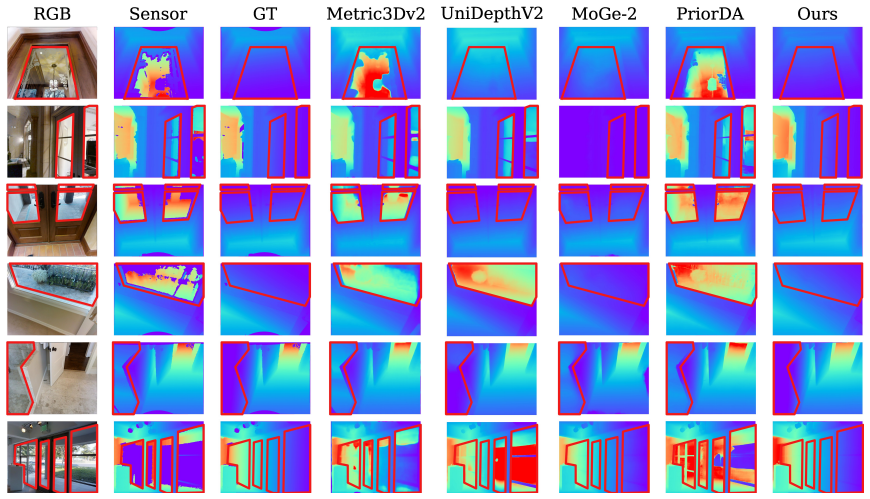
The paper establishes that a training-free framework can treat depth foundation models as structural priors and fuse them with raw sensor depth through robust local RANSAC alignment. This fusion recovers metric scale while excluding erroneous glass measurements, yielding depth maps that improve robot navigation performance. The claim is supported by the introduction of the GlassRecon dataset, which supplies ground truth for glass regions, and by experiments showing consistent gains over baselines under heavy sensor corruption.
What carries the argument
The local RANSAC-based alignment step that matches the depth prior to raw sensor measurements, computes an inlier scale correction, and produces a fused metric depth map that excludes glass-induced outliers.
If this is right
- Robots gain more reliable obstacle avoidance and path planning in glass-dominated indoor spaces without hardware changes.
- The absence of training allows immediate deployment on existing depth-sensor platforms.
- The GlassRecon dataset provides a standard benchmark for evaluating future glass-reconstruction techniques.
- Gains are largest precisely when raw depth data is most corrupted, matching the hardest real-world cases.
Where Pith is reading between the lines
- The same local-alignment idea could extend to other sensor-fooling surfaces such as mirrors or water.
- Combining this prior with existing SLAM pipelines might reduce drift in large glass environments.
- Testing on moving robots with dynamic glass reflections would reveal whether the static alignment assumption holds in motion.
Load-bearing premise
Depth foundation models supply reliable structural priors on glass regions while local RANSAC can robustly exclude erroneous glass measurements without introducing scale drift or new errors.
What would settle it
Run the method on a sequence with known glass ground truth and severe sensor corruption; if the fused depth error exceeds that of the raw sensor or of the unaligned prior, the claim is falsified.
Figures








read the original abstract
Indoor robot navigation is often compromised by glass surfaces, which severely corrupt depth sensor measurements. While foundation models like Depth Anything 3 provide excellent geometric priors, they lack an absolute metric scale. We propose a training-free framework that leverages depth foundation models as a structural prior, employing a robust local RANSAC-based alignment to fuse it with raw sensor depth. This naturally avoids contamination from erroneous glass measurements and recovers an accurate metric scale. Furthermore, we introduce \ti{GlassRecon}, a novel RGB-D dataset with geometrically derived ground truth for glass regions. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art baselines, especially under severe sensor depth corruption. The dataset and related code will be released at https://github.com/jarvisyjw/GlassRecon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free framework for reconstructing glass surfaces in RGB-D data to support indoor robot navigation. Depth foundation models supply structural priors that are aligned to raw sensor depth via local RANSAC; the fusion is claimed to recover metric scale while excluding erroneous glass measurements. A new RGB-D dataset (GlassRecon) with geometrically derived ground truth for glass regions is introduced, and the method is reported to outperform state-of-the-art baselines, particularly under severe sensor depth corruption.
Significance. If the central claims hold, the work addresses a concrete failure mode of depth sensors in common indoor environments and could improve navigation reliability. The training-free design and planned release of both dataset and code are positive contributions that support reproducibility and practical adoption. The introduction of geometrically derived ground truth for glass is also a useful resource for the community.
major comments (2)
- [Method (local RANSAC alignment)] Method section (local RANSAC alignment): the claim that the procedure 'naturally avoids contamination from erroneous glass measurements' rests on the assumption that every local window contains a sufficient number of reliable non-glass inliers for stable scale recovery. In glass-dense regions—the regime highlighted for superior performance—this minimum-inlier condition can easily be violated, producing either failed alignments or erroneous scale factors that propagate into the output depth map. No quantitative characterization of inlier counts, failure rates, or fallback behavior across corruption levels is provided.
- [Experiments] Experiments section: the abstract asserts 'extensive experiments demonstrate that our approach consistently outperforms state-of-the-art baselines, especially under severe sensor depth corruption,' yet the manuscript supplies no tabulated quantitative results, error bars, ablation studies on the RANSAC window size or inlier threshold, or per-scene breakdowns that would allow verification of the robustness claim. Without these data the central empirical assertion cannot be assessed.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction repeatedly use the phrase 'naturally avoids contamination' without a precise definition of what constitutes contamination or how it is measured; a short clarifying sentence would improve readability.
- [Dataset] Dataset description: the geometric derivation of ground truth for glass regions is mentioned but the exact procedure (e.g., multi-view consistency checks, plane fitting parameters) is not detailed enough for independent replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the robustness assumptions in our local RANSAC alignment and the need for more detailed quantitative experimental evidence. We address each major comment below and will revise the manuscript accordingly to strengthen these aspects.
read point-by-point responses
-
Referee: Method section (local RANSAC alignment): the claim that the procedure 'naturally avoids contamination from erroneous glass measurements' rests on the assumption that every local window contains a sufficient number of reliable non-glass inliers for stable scale recovery. In glass-dense regions—the regime highlighted for superior performance—this minimum-inlier condition can easily be violated, producing either failed alignments or erroneous scale factors that propagate into the output depth map. No quantitative characterization of inlier counts, failure rates, or fallback behavior across corruption levels is provided.
Authors: We agree that the local RANSAC procedure's ability to avoid erroneous glass measurements depends on the presence of sufficient non-glass inliers within each window, and that this assumption may be stressed in glass-dense regions. The method selects local patches expecting a mix of surfaces typical in indoor environments, with RANSAC providing robustness to outliers. However, the current manuscript does not include quantitative analysis of inlier statistics or failure modes. In the revision, we will add plots and tables characterizing inlier counts and ratios across corruption levels, report observed failure rates, and describe fallback strategies (e.g., reverting to the depth prior or raw measurements) to address this gap directly. revision: yes
-
Referee: Experiments section: the abstract asserts 'extensive experiments demonstrate that our approach consistently outperforms state-of-the-art baselines, especially under severe sensor depth corruption,' yet the manuscript supplies no tabulated quantitative results, error bars, ablation studies on the RANSAC window size or inlier threshold, or per-scene breakdowns that would allow verification of the robustness claim. Without these data the central empirical assertion cannot be assessed.
Authors: We acknowledge that while the manuscript presents qualitative results and some supporting metrics, the absence of tabulated quantitative results, error bars, ablations on RANSAC parameters (window size and inlier threshold), and per-scene breakdowns limits independent verification of the performance claims. In the revised version, we will incorporate comprehensive tables with error metrics under varying corruption levels, error bars from repeated evaluations, dedicated ablation studies on the mentioned hyperparameters, and per-scene breakdowns to substantiate the outperformance, particularly in severe corruption cases. revision: yes
Circularity Check
No circularity: procedural fusion of priors via RANSAC alignment
full rationale
The paper presents a training-free algorithmic pipeline that takes depth foundation model outputs as structural priors and fuses them with raw sensor depth through local RANSAC alignment. No parameters are fitted to data subsets and then used to 'predict' related quantities by construction. No self-citations are load-bearing for uniqueness theorems or ansatzes. The central claims about metric scale recovery and avoidance of glass contamination follow directly from the described alignment procedure without reducing to input definitions or renaming known results. The derivation chain is self-contained and externally verifiable through the released code and dataset.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Depth foundation models produce geometrically consistent structural priors even on transparent surfaces.
- domain assumption Local RANSAC alignment can robustly exclude glass-induced outliers while preserving metric scale.
Reference graph
Works this paper leans on
-
[1]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Detecting glass in simultaneous localisation and mapping,
X. Wang and J. Wang, “Detecting glass in simultaneous localisation and mapping,”Robot. and Auton. Syst., vol. 88, pp. 97–103, 2017
2017
-
[3]
Lidar-based 3-d glass detection and reconstruction in indoor environment,
L. Zhou, X. Sun, C. Zhang, L. Cao, and Y . Li, “Lidar-based 3-d glass detection and reconstruction in indoor environment,”IEEE Trans. Instrum. Meas., vol. 73, pp. 1–11, 2024
2024
-
[4]
3d reconstruction in the presence of glass and mirrors by acoustic and visual fusion,
Y . Zhang, M. Ye, D. Manocha, and R. Yang, “3d reconstruction in the presence of glass and mirrors by acoustic and visual fusion,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 8, pp. 1785–1798, 2017
2017
-
[5]
Glass segmentation using intensity and spectral polarization cues,
H. Mei, B. Dong, W. Dong, J. Yang, S. H. Baek, F. Heide, ..., and X. Yang, “Glass segmentation using intensity and spectral polarization cues,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 12 622–12 631, dOI:
2022
-
[6]
Glass segmentation with rgb-thermal image pairs,
D. Huo, J. Wang, Y . Qian, and Y . H. Yang, “Glass segmentation with rgb-thermal image pairs,”IEEE Trans. Image Process., vol. 32, pp. 1911–1926, 2023
1911
-
[7]
Transfusion: A novel slam method focused on transparent objects,
Y . Zhu, J. Qiu, and B. Ren, “Transfusion: A novel slam method focused on transparent objects,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 6019–6028, key=zhu2021
2021
-
[8]
Glass detection in simultaneous localization and mapping of mobile robot based on rgb-d camera,
Y . Zhao, H. Li, S. Jiang, H. Li, Z. Zhang, and H. Zhu, “Glass detection in simultaneous localization and mapping of mobile robot based on rgb-d camera,” inProc. IEEE Int. Conf. Mechatronics Autom.IEEE, aug 2023, pp. 549–556, dOI:. Fig. 8.Visualization of Reconstruction.(Top) ScanNet++, (Middle) Scene01, (bottom) Scene02. The top row is selected from Scan...
2023
-
[9]
Leveraging rgb-d data with cross-modal context mining for glass surface detection,
J. Lin, Y .-H. Yeung, S. Ye, and R. W. Lau, “Leveraging rgb-d data with cross-modal context mining for glass surface detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 5254–5261
2025
-
[10]
Monocular depth estimation for glass walls with context: a new dataset and method,
Y . Liang, B. Deng, W. Liu, J. Qin, and S. He, “Monocular depth estimation for glass walls with context: a new dataset and method,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 12, pp. 15 081– 15 097, 2023
2023
-
[11]
Monoglass3d: Monocular 3d glass detection with plane regression and adaptive feature fusion,
K. Zhang, G. Zhao, J. Shi, B. Liu, W. Qi, and J. Ma, “Monoglass3d: Monocular 3d glass detection with plane regression and adaptive feature fusion,”arXiv preprint arXiv:2509.05599, 2025
-
[12]
Towards robust monocular depth estimation: Mixing datasets for zero- shot cross-dataset transfer,
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V . Koltun, “Towards robust monocular depth estimation: Mixing datasets for zero- shot cross-dataset transfer,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 3, pp. 1623–1637, 2020
2020
-
[13]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2024, pp. 10 371–10 381, dOI:
2024
-
[14]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Adv. Neural Inf. Process. Syst., vol. 37, pp. 21 875–21 911, 2024
2024
-
[15]
Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,
M. Hu, W. Yin, C. Zhang, Z. Cai, X. Long, H. Chen, K. Wang, G. Yu, C. Shen, and S. Shen, “Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,”IEEE Trans. Pattern Anal. Mach. Intell., 2024
2024
-
[16]
Unidepthv2: Universal monocular metric depth estimation made simpler
L. Piccinelli, C. Sakaridis, Y .-H. Yang, M. Segu, S. Li, W. Abbeloos, and L. Van Gool, “Unidepthv2: Universal monocular metric depth estimation made simpler,”arXiv preprint arXiv:2502.20110, 2025
-
[17]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang, “Moge-2: Accurate monocular geometry with metric scale and sharp details,”arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review arXiv 2025
-
[18]
Depth anything with any prior.arXiv preprint arXiv:2505.10565, 2025
Z. Wang, S. Chen, L. Yang, J. Wang, Z. Zhang, H. Zhao, and Z. Zhao, “Depth anything with any prior,”arXiv preprint arXiv:2505.10565, 2025
-
[19]
Matterport3d: Learning from rgb-d data in indoor environments,
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”Int. Conf. 3D Vis., 2017
2017
-
[20]
Moge: Unlocking accurate monocular geometry estimation for open- domain images with optimal training supervision,
R. Wang, S. Xu, C. Dai, J. Xiang, Y . Deng, X. Tong, and J. Yang, “Moge: Unlocking accurate monocular geometry estimation for open- domain images with optimal training supervision,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2025, pp. 5261–5271
2025
-
[21]
Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,
C. Campos, R. Elvira, J. J. G. Rodriguez, J. M. M. Montiel, and J. D. Tardos, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,”IEEE Trans. Robot., vol. 37, no. 6, p. 1874–1890, Dec. 2021
2021
-
[22]
Frozen- recon: Pose-free 3d scene reconstruction with frozen depth models,
G. Xu, W. Yin, H. Chen, C. Shen, K. Cheng, and F. Zhao, “Frozen- recon: Pose-free 3d scene reconstruction with frozen depth models,” inProc. IEEE Int. Conf. Comput. Vis.IEEE, 2023, pp. 9276–9286
2023
-
[23]
Scannet++: A high-fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high-fidelity dataset of 3d indoor scenes,” inProc. IEEE Int. Conf. Comput. Vis., 2023, pp. 12–22
2023
-
[24]
nvblox: Gpu-accelerated incremental signed distance field mapping,
A. Millane, H. Oleynikova, E. Wirbel, R. Steiner, V . Ramasamy, D. Tingdahl, and R. Siegwart, “nvblox: Gpu-accelerated incremental signed distance field mapping,” inProc. IEEE Int. Conf. Robot. Autom. IEEE, 2024, pp. 2698–2705
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.