Recognition: unknown
Sessa: Selective State Space Attention
Pith reviewed 2026-05-10 04:42 UTC · model grok-4.3
The pith
Sessa places attention inside recurrent feedback paths to produce power-law memory tails and distance-independent selective retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
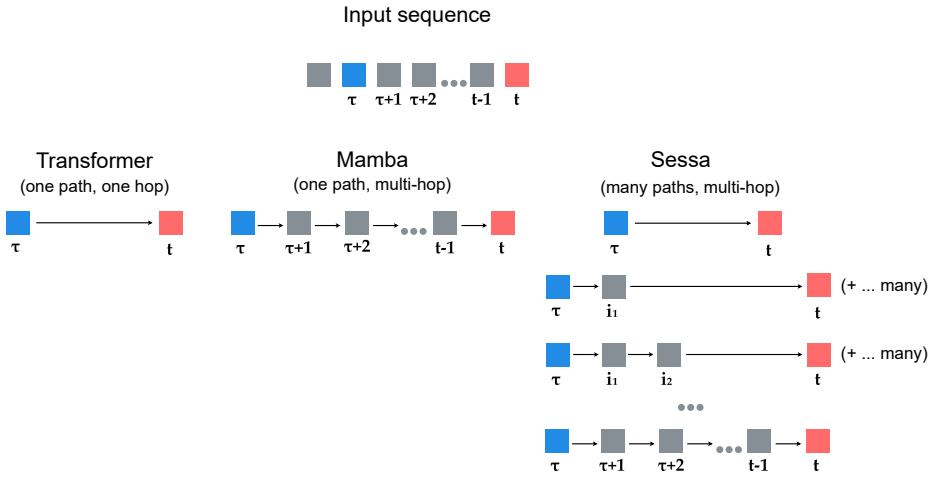
By placing attention inside a recurrent feedback path, Sessa creates many attention-based paths through which past tokens can influence future states, rather than relying on a single attention read or a single recurrent chain. Under explicit assumptions and matched regimes, Sessa admits power-law memory tails O(ℓ^{-β}) for 0 < β < 1 with slower decay than corresponding Transformer and Mamba-style baselines, and an explicit construction achieves this rate. Under the same assumptions Sessa is the only model class among those considered that realizes flexible selective retrieval, including profiles whose influence does not decay with distance.
What carries the argument
The Sessa decoder that places attention inside a recurrent feedback path to create multiple influence paths from past tokens to future states.
If this is right
- Memory influence from past tokens decays as a power law rather than exponentially, preserving distant information more effectively.
- Selective retrieval becomes possible with influence profiles that remain constant regardless of distance.
- Sessa records the strongest results on long-context benchmarks while staying competitive on short-context language modeling.
- Only Sessa among the examined classes achieves flexible selective retrieval under the stated assumptions.
Where Pith is reading between the lines
- Designers of new sequence models could adopt the same nested attention-recurrent pattern to obtain controllable memory decay rates.
- The approach points to a general route for overcoming both attention dilution and recurrent forgetting by multiplying the number of influence pathways.
- Empirical tests on real-world long documents could reveal how sensitive the observed power-law behavior is to the paper's modeling assumptions.
Load-bearing premise
The power-law memory tails and unique selective retrieval hold only under the paper's explicit assumptions and matched regimes.
What would settle it
Direct measurement of how token influence strength decays with distance in trained Sessa models on long sequences, checking whether the decay follows a power law with exponent between 0 and 1 rather than the faster decay of the baselines.
Figures

read the original abstract
Modern sequence modeling is dominated by two families: Transformers, whose self-attention can access arbitrary elements of the visible sequence, and structured state-space models, which propagate information through an explicit recurrent state. These mechanisms face different limitations on long contexts: when attention is diffuse, the influence of individual tokens is diluted across the effective support, while recurrent state propagation can lose long-range sensitivity unless information is actively preserved. As a result, both mechanisms face challenges in preserving and selectively retrieving information over long contexts. We propose Sessa, a decoder that places attention inside a recurrent feedback path. This creates many attention-based paths through which past tokens can influence future states, rather than relying on a single attention read or a single recurrent chain. We prove that, under explicit assumptions and matched regimes, Sessa admits power-law memory tails $O(\ell^{-\beta})$ for $0 < \beta < 1$, with slower decay than in the corresponding Transformer and Mamba-style baselines. We further give an explicit construction that achieves this power-law rate. Under the same assumptions, Sessa is the only model class among those considered that realizes flexible selective retrieval, including profiles whose influence does not decay with distance. Consistent with this theoretical advantage, across matched experiments, Sessa achieves the strongest performance on long-context benchmarks while remaining competitive with Transformer and Mamba-style baselines on short-context language modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Sessa, a decoder architecture that embeds attention mechanisms inside a recurrent feedback path, thereby creating multiple attention-based paths through which past tokens can influence future states. It proves that, under explicit assumptions and matched regimes, Sessa admits power-law memory tails O(ℓ^{-β}) for 0 < β < 1 with slower decay than corresponding Transformer and Mamba-style baselines, supplies an explicit construction achieving this rate, and is the only model class among those considered that realizes flexible selective retrieval including non-decaying influence profiles. Empirical results across matched experiments show Sessa achieving the strongest performance on long-context benchmarks while remaining competitive with baselines on short-context language modeling.
Significance. If the theoretical claims hold, the work offers a meaningful advance by providing a hybrid architecture with provable long-range memory advantages over both attention-only and recurrent-only families, together with an explicit construction and a uniqueness result for selective retrieval. These elements, if substantiated, could inform the design of efficient long-context models and address dilution and sensitivity issues in existing mechanisms.
major comments (1)
- [§3] §3 (theoretical analysis): the power-law tail result and the uniqueness claim for non-decaying selective retrieval are load-bearing; the manuscript should explicitly enumerate all assumptions, state the precise matched regimes used for the Transformer/Mamba comparisons, and discuss how restrictive those assumptions are for practical training regimes.
minor comments (3)
- [Abstract] The abstract refers to 'explicit assumptions' without listing them; a one-sentence summary of the key assumptions would improve accessibility.
- [§2] Notation for the memory tail O(ℓ^{-β}) should include an early definition of the distance variable ℓ and the range of β in the main text.
- [Experiments] Experimental section: more detail on how the 'matched regimes' are enforced across model classes (e.g., parameter count, training steps, context length) would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the constructive suggestion regarding the theoretical section. We address the major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the power-law tail result and the uniqueness claim for non-decaying selective retrieval are load-bearing; the manuscript should explicitly enumerate all assumptions, state the precise matched regimes used for the Transformer/Mamba comparisons, and discuss how restrictive those assumptions are for practical training regimes.
Authors: We agree that the power-law tail result and uniqueness claim are central, and that their supporting assumptions and comparison regimes merit explicit enumeration for clarity. In the revised manuscript we will add a dedicated paragraph (or short subsection) at the beginning of §3 that: (1) lists every assumption used in the proofs of the O(ℓ^{-β}) memory tails and the selective-retrieval uniqueness result; (2) states the precise matched regimes (parameter count, state dimension, sequence length, and architectural constraints) under which the Transformer and Mamba-style baselines are compared; and (3) discusses the restrictiveness of these assumptions for practical training, including any known relaxations and their implications for real-world deployment. These additions will not change the stated theorems but will make the scope of the claims fully transparent. revision: yes
Circularity Check
Derivation self-contained under explicit assumptions; no circularity
full rationale
The central claims consist of a proof of power-law memory tails O(ℓ^{-β}) (0<β<1) and an explicit construction for flexible selective retrieval, both stated to hold only under the paper's explicit assumptions and matched regimes. The abstract and described results frame these as derivations from the model definition (attention inside recurrent feedback) rather than reductions to fitted parameters, self-citations, or renamed inputs. No load-bearing step reduces by construction to its own outputs, and no self-citation chain is invoked for uniqueness or ansatz. The result is therefore independent of the target claims and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit assumptions on model regimes and memory dynamics that enable the power-law tail analysis
invented entities (1)
-
Sessa decoder class
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CoRR , volume =
On the Opportunities and Risks of Foundation Models , author =. CoRR , volume =. 2021 , eprint =
2021
-
[2]
Attention Is All You Need , author =. Advances in Neural Information Processing Systems 30 (NIPS 2017) , year =. doi:10.48550/arXiv.1706.03762 , url =. 1706.03762 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
-
[3]
Limitations of Normalization in Attention Mechanism,
Limitations of Normalization in Attention Mechanism , author =. 2025 , booktitle =. doi:10.48550/arXiv.2508.17821 , url =. 2508.17821 , archivePrefix =
-
[4]
Generating Long Sequences with Sparse Transformers
Generating Long Sequences with Sparse Transformers , author =. arXiv preprint arXiv:1904.10509 , year =. doi:10.48550/arXiv.1904.10509 , url =. 1904.10509 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.1904.10509 1904
-
[5]
Longformer: The Long-Document Transformer
Longformer: The Long-Document Transformer , author =. arXiv preprint arXiv:2004.05150 , year =. doi:10.48550/arXiv.2004.05150 , url =. 2004.05150 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.2004.05150 2004
-
[6]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi
Big Bird: Transformers for Longer Sequences , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2007.14062 , url =. 2007.14062 , archivePrefix =
-
[7]
LongNet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486,
LongNet: Scaling Transformers to 1,000,000,000 Tokens , author =. arXiv preprint arXiv:2307.02486 , year =. doi:10.48550/arXiv.2307.02486 , url =. 2307.02486 , archivePrefix =
-
[8]
and Staats, Charles , journal =
Rabe, Markus N. and Staats, Charles , journal =. Self-Attention Does Not Need. 2021 , eprint =
2021
-
[9]
Efficiently Modeling Long Sequences with Structured State Spaces
Efficiently Modeling Long Sequences with Structured State Spaces , author =. International Conference on Learning Representations (ICLR) , year =. doi:10.48550/arXiv.2111.00396 , url =. 2111.00396 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.2111.00396
-
[10]
Journal of Basic Engineering , year =
A New Approach to Linear Filtering and Prediction Problems , author =. Journal of Basic Engineering , year =
-
[11]
2006 , edition =
Linear Systems , author =. 2006 , edition =
2006
-
[12]
2012 , doi =
Matrix Analysis , author =. 2012 , doi =
2012
-
[13]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author =. Conference on Language Modeling (COLM) , year =. doi:10.48550/arXiv.2312.00752 , url =. 2312.00752 , archivePrefix =
-
[14]
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , note =. doi:10.48550/arXiv.2405.21060 , url =. 2405.21060 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.2405.21060 2024
-
[15]
Proceedings of the 42nd International Conference on Machine Learning , series =
Understanding Input Selectivity in Mamba: Impact on Approximation Power, Memorization, and Associative Recall Capacity , author =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , note =. doi:10.48550/arXiv.2506.11891 , url =. 2506.11891 , archivePrefix =
-
[16]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year =. doi:10.18653/v1/P19-1285 , url =. 1901.02860 , archivePrefix =
-
[17]
arXiv preprint arXiv:2002.09402 , year =
Addressing Some Limitations of Transformers with Feedback Memory , author =. arXiv preprint arXiv:2002.09402 , year =. doi:10.48550/arXiv.2002.09402 , url =. 2002.09402 , archivePrefix =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Block-Recurrent Transformers , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2203.07852 , url =. 2203.07852 , archivePrefix =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Recurrent Memory Transformer , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2207.06881 , url =. 2207.06881 , archivePrefix =
-
[20]
TransformerFAM: Feedback attention is working memory , author =. arXiv preprint arXiv:2404.09173 , year =. doi:10.48550/arXiv.2404.09173 , url =
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year =
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[22]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units , author =. IEEE/ACM Transactions on Audio, Speech, and Language Processing , year =. doi:10.1109/TASLP.2021.3122291 , note =
-
[23]
Chronos: Learning the Language of Time Series
Chronos: Learning the Language of Time Series , author =. Transactions on Machine Learning Research , year =. doi:10.48550/arXiv.2403.07815 , url =. 2403.07815 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.2403.07815
-
[24]
The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics , author =. Nature Methods , year =. doi:10.1038/s41592-024-02523-z , url =
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
International Conference on Learning Representations (ICLR) , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations (ICLR) , year =
-
[27]
WaveNet: A Generative Model for Raw Audio
WaveNet: A Generative Model for Raw Audio , author =. 9th ISCA Workshop on Speech Synthesis Workshop (SSW 9) , year =. doi:10.48550/arXiv.1609.03499 , url =. 1609.03499 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.1609.03499
-
[28]
Ke Tran, Arianna Bisazza, and Christof Monz
Sequence to Sequence Learning with Neural Networks , author =. Advances in Neural Information Processing Systems (NIPS 2014) , year =. doi:10.48550/arXiv.1409.3215 , url =. 1409.3215 , archivePrefix =
-
[29]
Layer Normalization , author =. 2016 , eprint =. doi:10.48550/arXiv.1607.06450 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.06450 2016
-
[30]
Gaussian Error Linear Units (GELUs)
Gaussian Error Linear Units (GELUs) , author =. 2016 , eprint =. doi:10.48550/arXiv.1606.08415 , url =
-
[31]
Transformer quality in linear time.arXiv preprint arXiv:2202.10447, 2022
Transformer Quality in Linear Time , author =. Proceedings of the 39th International Conference on Machine Learning (ICML) , year =. 2202.10447 , archivePrefix =
-
[32]
GLU Variants Improve Transformer
GLU Variants Improve Transformer , author =. 2020 , eprint =. doi:10.48550/arXiv.2002.05202 , url =
work page internal anchor Pith review doi:10.48550/arxiv.2002.05202 2020
-
[33]
RoFormer: Enhanced Transformer with Rotary Position Embedding
RoFormer: Enhanced Transformer with Rotary Position Embedding , author =. 2021 , eprint =. doi:10.48550/arXiv.2104.09864 , url =
work page internal anchor Pith review doi:10.48550/arxiv.2104.09864 2021
-
[34]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models , author =. 2023 , eprint =. doi:10.48550/arXiv.2302.13971 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[35]
GPT - N eo X -20 B : An open-source autoregressive language model
Black, Sidney and Biderman, Stella and Hallahan, Eric and Anthony, Quentin and Gao, Leo and Golding, Laurence and He, Horace and Leahy, Connor and McDonell, Kyle and Phang, Jason and Pieler, Michael and Prashanth, Usvsn Sai and Purohit, Shivanshu and Reynolds, Laria and Tow, Jonathan and Wang, Ben and Weinbach, Samuel , booktitle =. 2022 , month = may, ad...
-
[36]
International Conference on Learning Representations (ICLR) , year =
Are Transformers universal approximators of sequence-to-sequence functions? , author =. International Conference on Learning Representations (ICLR) , year =
-
[37]
Annals of Mathematical Statistics , year =
A Measure of Asymptotic Efficiency for Tests of a Hypothesis Based on the Sum of Observations , author =. Annals of Mathematical Statistics , year =
-
[38]
Journal of the American Statistical Association , year =
Probability Inequalities for Sums of Bounded Random Variables , author =. Journal of the American Statistical Association , year =
-
[39]
2011 , howpublished =
Lectures on Dynamic Systems and Control, Chapter 15: External Input-Output Stability , author =. 2011 , howpublished =
2011
-
[40]
2011 , howpublished =
Lectures on Dynamic Systems and Control, Chapter 27: Poles and Zeros of MIMO Systems , author =. 2011 , howpublished =
2011
-
[41]
2011 , howpublished =
Lectures on Dynamic Systems and Control, Chapter 30: Minimality and Stability of Interconnected Systems , author =. 2011 , howpublished =
2011
-
[42]
Journal of Mathematics and Physics , volume =
Some elementary inequalities relating to the gamma and incomplete gamma function , author =. Journal of Mathematics and Physics , volume =. 1959 , doi =
1959
-
[43]
Uber Funktionen, die auf einer abgeschlossenen Menge stetig sind , author =. Journal f\
\"Uber Funktionen, die auf einer abgeschlossenen Menge stetig sind , author =. Journal f\"ur die reine und angewandte Mathematik , volume =. 1915 , doi =
1915
-
[44]
Neural Networks , volume =
Multilayer feedforward networks are universal approximators , author =. Neural Networks , volume =. 1989 , doi =
1989
-
[45]
Neural Networks , volume =
Multilayer feedforward networks with a nonpolynomial activation function can approximate any function , author =. Neural Networks , volume =. 1993 , doi =
1993
-
[46]
Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
On Layer Normalization in the Transformer Architecture , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
-
[47]
On the parameterization and initialization of diagonal state space models
On the Parameterization and Initialization of Diagonal State Space Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2206.11893 , url =
-
[48]
International Conference on Learning Representations (ICLR) , year =
Long Range Arena: A Benchmark for Efficient Transformers , author =. International Conference on Learning Representations (ICLR) , year =
-
[49]
arXiv preprint arXiv:2501.14850 , year =
On the locality bias and results in the Long Range Arena , author =. arXiv preprint arXiv:2501.14850 , year =. doi:10.48550/arXiv.2501.14850 , url =. 2501.14850 , archivePrefix =
-
[50]
arXiv preprint arXiv:2504.09184 , year=
Parameterized Synthetic Text Generation with SimpleStories , author =. NeurIPS 2025 Datasets and Benchmarks Track , year =. doi:10.48550/arXiv.2504.09184 , eprint =
-
[51]
Zoology: Measuring and improving recall in efficient language models, 2024
Zoology: Measuring and Improving Recall in Efficient Language Models , author =. International Conference on Learning Representations (ICLR) , year =. 2312.04927 , archivePrefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.