Recognition: unknown
How to quantify direct correlations between variables
Pith reviewed 2026-05-10 04:39 UTC · model grok-4.3
The pith
Jensen-Shannon regularization yields bounded [0,1] measures of direct correlation for distributional-shift and do-calculus families.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing the Kullback-Leibler divergence with its Jensen-Shannon counterpart in both the distributional-shift family and the do-calculus family, the resulting regularized measures of direct correlation take values in the interval [0,1], are free from singularities, and have explicit upper bounds determined by the alphabet sizes under the observed marginal distribution p(x,z).
What carries the argument
Jensen-Shannon regularization applied to Kullback-Leibler-based direct correlation measures from the distributional-shift and do-calculus families.
If this is right
- The scale of direct correlation is set by an upper bound strictly below 1 that depends on the variable alphabet sizes.
- Numerical values from the measures can be directly compared across different variable pairs without normalization issues.
- The approach applies to empirical data with uncertainty estimates via bootstrapping, as demonstrated on survival and income datasets.
- Direct and indirect correlations can be distinguished more reliably in the presence of confounders.
Where Pith is reading between the lines
- Such measures might help in building more interpretable causal graphs by attaching quantitative direct strengths to edges.
- The upper bound analysis highlights the need for alphabet-aware normalization when alphabets are small.
- Future work could test these measures in continuous variable settings by suitable discretization or kernel approximations.
- Different applications may favor one family over the other depending on whether associational or interventional semantics are preferred.
Load-bearing premise
The Jensen-Shannon regularized analogues retain the intended interpretation of direct correlation as defined by the original Kullback-Leibler constructions in the two families.
What would settle it
A joint distribution over discrete variables where the regularized measure exceeds its derived upper bound under the fixed marginal p(x,z), or where it reports positive direct correlation despite known independence after conditioning on confounders.
Figures






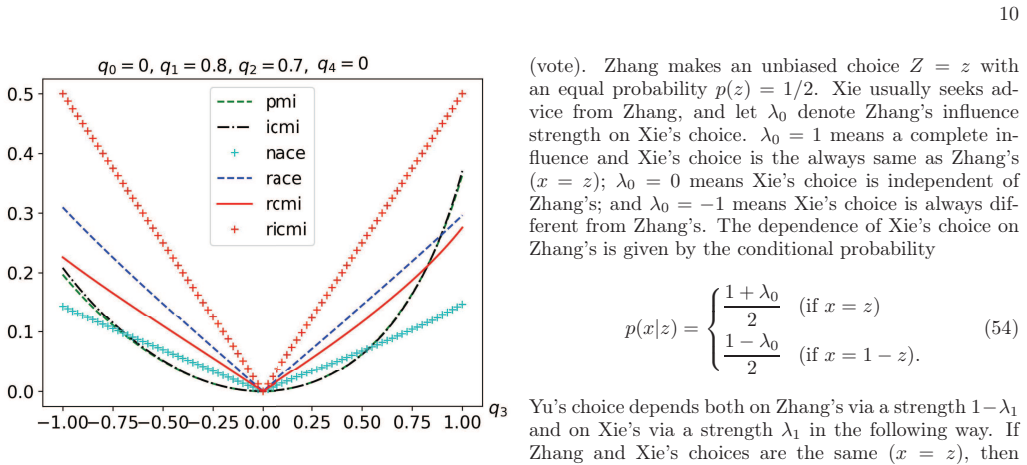



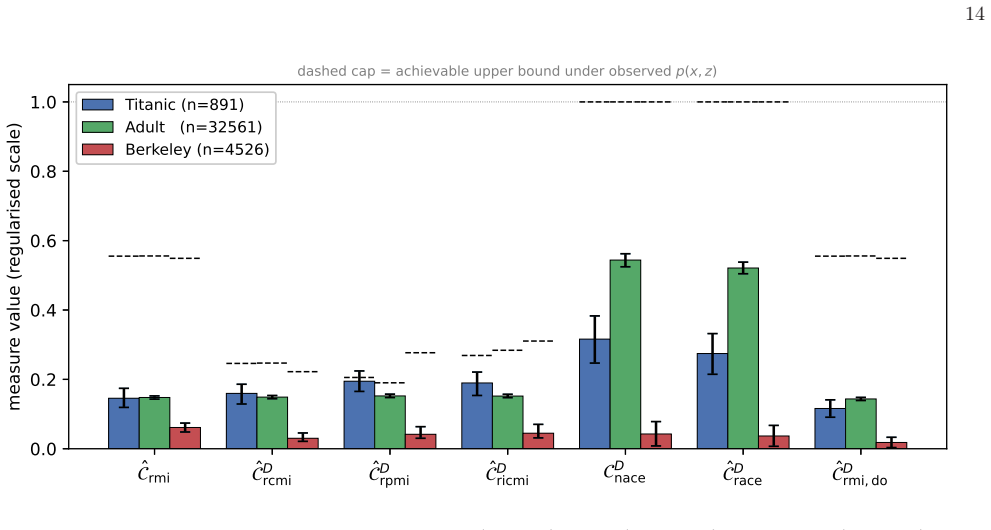
read the original abstract
Analyzing correlation between variables is often both the tool and the goal of modern science. A crucial question is whether the correlation between two variables is a direct correlation or only an indirect correlation through a confounder. We review the existing measures of direct correlation and organize them into two families, each corresponding to a systematic construction: (i) removing the direct correlation from the original joint distribution and quantifying the resulting distributional shift, and (ii) intervening on one variable via do-calculus and quantifying how the distribution of the other variable responds. For every Kullback--Leibler-based measure in either family, we propose a Jensen--Shannon-based regularized analogue. Since the square root of the Jensen--Shannon divergence is a bounded metric, the regularized measures take values in $[0,1]$ and are free of the singularity of the Kullback--Leibler divergence. We further analyze the achievable upper bound of each regularized measure under the observed marginal $p(x,z)$, which depends on the alphabet size and is in general strictly below $1$; this sets the correct scale against which observed values should be read. The properties and the differences of the proposed measures are illustrated on a decision-making toy model and on three public real datasets: Titanic survival, UCI Adult (Census Income), and the UC~Berkeley 1973 graduate admissions. Bootstrap $95\%$ confidence intervals are reported for every numerical value.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reviews measures of direct correlation between variables and organizes them into two families: (i) distributional-shift constructions that remove direct correlation from the joint and quantify the shift via divergences, and (ii) do-calculus constructions that intervene on one variable and quantify the response of the other. For every KL-based measure in either family the authors propose a Jensen-Shannon regularized analogue; because sqrt(JS) is a metric the new quantities lie in [0,1] and avoid KL singularities. They derive the achievable upper bound of each regularized measure under the observed marginal p(x,z), showing that the bound depends on alphabet size and is typically strictly less than 1. The measures are illustrated on a decision-making toy model and on the Titanic, UCI Adult, and UC Berkeley admissions datasets, with bootstrap 95% confidence intervals reported for all numerical values.
Significance. If the upper-bound derivations and semantic preservation hold for both families, the work supplies a practical, bounded scale for quantifying direct versus indirect correlation that is directly usable in applied causal and statistical analyses. The combination of theoretical regularization, explicit upper-bound analysis, and empirical demonstration with confidence intervals strengthens the contribution for methodology journals.
major comments (2)
- [Section 4] Section 4 (upper-bound analysis): the claim that the achievable upper bound of each regularized measure is characterized under the observed marginal p(x,z) does not uniformly apply to the do-calculus family. Interventional distributions p(·|do(·)) are fixed by the causal mechanism, not solely by the observational marginal; maximizing only over joints consistent with p(x,z) may therefore produce bounds that are either unattainable or not the least upper bound under the actual interventional semantics. This directly affects the recommended scaling interpretation for the do-calculus regularized measures.
- [Section 3] Section 3 (regularization construction): while the JS analogues are shown to be bounded and singularity-free, the manuscript does not verify that they preserve the original KL measures' invariance properties or direct-correlation semantics under the two distinct constructions. A short proof or counter-example check that the ordering or zero/non-zero behavior is retained would be needed to confirm the analogues remain faithful to the intended interpretation.
minor comments (2)
- [Methods / Experiments] The bootstrap procedure (number of replicates, handling of discrete alphabet size, and whether resampling respects the marginal constraint) is mentioned but not detailed; adding a short algorithmic description or pseudocode would improve reproducibility.
- [Notation] Notation for the two families is introduced clearly in the abstract but the transition between distributional-shift and do-calculus notation in the main text occasionally re-uses symbols (e.g., p(x,z) for both observational and interventional contexts); a brief reminder table would reduce reader confusion.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We address each major comment below and will revise the manuscript to incorporate the necessary clarifications and additions.
read point-by-point responses
-
Referee: [Section 4] Section 4 (upper-bound analysis): the claim that the achievable upper bound of each regularized measure is characterized under the observed marginal p(x,z) does not uniformly apply to the do-calculus family. Interventional distributions p(·|do(·)) are fixed by the causal mechanism, not solely by the observational marginal; maximizing only over joints consistent with p(x,z) may therefore produce bounds that are either unattainable or not the least upper bound under the actual interventional semantics. This directly affects the recommended scaling interpretation for the do-calculus regularized measures.
Authors: We agree with the referee that the upper-bound derivation does not apply uniformly. The bounds were obtained by maximizing over joints consistent with the observed marginal p(x,z), but interventional distributions in the do-calculus family are fixed by the causal mechanisms, which are not identifiable from p(x,z) alone. This means the reported bounds may not be attainable or tight under the interventional semantics. We will revise Section 4 to distinguish the two families explicitly, state the limitation for the do-calculus measures, and qualify the scaling interpretation as the best achievable under the observational marginal without further assumptions on the structural causal model. revision: yes
-
Referee: [Section 3] Section 3 (regularization construction): while the JS analogues are shown to be bounded and singularity-free, the manuscript does not verify that they preserve the original KL measures' invariance properties or direct-correlation semantics under the two distinct constructions. A short proof or counter-example check that the ordering or zero/non-zero behavior is retained would be needed to confirm the analogues remain faithful to the intended interpretation.
Authors: We acknowledge that explicit verification of semantic preservation was omitted. Because the Jensen-Shannon divergence satisfies D_JS(P||Q)=0 if and only if P=Q, the regularized measures are zero precisely when the original KL-based measures are zero, thereby retaining the zero/non-zero behavior that identifies absence of direct correlation in each construction. Invariance to relabeling of categories is inherited directly from the divergence and the shared functional form of the constructions. We will add a short appendix containing these arguments together with numerical checks on the decision-making toy model confirming that the relative ordering of values is preserved across the examples. This will establish that the analogues remain faithful to the intended interpretations. revision: yes
Circularity Check
No circularity: derivations rest on standard divergences and do-calculus without self-referential reductions
full rationale
The paper organizes existing KL-based direct-correlation measures into distributional-shift and do-calculus families, then explicitly constructs JS-regularized analogues using the standard square-root JS metric. Upper bounds are derived mathematically under the fixed observational marginal p(x,z) as a separate analysis step. No equation reduces a proposed measure to a fitted parameter, a self-definition, or a prior result by the same authors that itself lacks independent verification. Self-citations, if present, are not load-bearing for the central constructions or bounds. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The variables under study are discrete with finite alphabets
- domain assumption Do-calculus interventions correctly isolate direct effects in the observed joint distribution
Reference graph
Works this paper leans on
-
[1]
How to quantify direct correlations between variables
5% of the 2691 male applicants but only 30. 4% of the 1835 female applicants were admitted, an apparent 14- point gender gap. Broken down by the six largest depart- ments, however, the admission rates are close for the two sexes and in four of the six departments in fact slightly favour women; the overall gap arises because women ap- plied disproportionat...
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[2]
how correlated is correlated
58 and p(Y =1|do(Pclass=3))≈ 0. 26 (computed under strategy (b) using the observed p(sex)). B. Dataset II: UCI Adult (Census Income) The UCI Adult dataset [39] contains n = 32561 records extracted from the 1994 US Census, with income di- chotomised at $50 000/year. We take X as the education level binned into four ordinal groups (0: at most 12th grade, 1:...
1994
-
[3]
P. J. Bickel, E. A. Hammel, J. W. O’Connell, Sex bias in graduate admissions: data from Berkeley, Science 187 (4175) (1975) 398–404. doi:10.1126/science.187.4175.398. URL https://vincentarelbundock.github.io/ Rdatasets/csv/datasets/UCBAdmissions.csv
-
[4]
URL https://www.kaggle.com/c/titanic Training-split CSV (used in this paper) mir- rored at https://raw.githubusercontent.com/ datasciencedojo/datasets/master/titanic.csv
Kaggle, Inc., Titanic — Machine Learning from Disaster, online competition, 2012. URL https://www.kaggle.com/c/titanic Training-split CSV (used in this paper) mir- rored at https://raw.githubusercontent.com/ datasciencedojo/datasets/master/titanic.csv. Passenger-level details compiled originally from Ency- clopedia Titanica and Eaton & Haas, Titanic: Triu...
2012
-
[5]
E. H. Simpson, The interpretation of interaction in con- tingency tables, Journal of the Royal Statistical Soci- ety, Series B 13 (2) (1951) 238–241. doi:10.1111/j. 2517-6161.1951.tb00088.x
work page doi:10.1111/j 1951
-
[6]
Sedgwick, Spearman’s rank correlation coefficient, BMJ 349 (2014) g7327
P. Sedgwick, Spearman’s rank correlation coefficient, BMJ 349 (2014) g7327. doi:10.1136/bmj.g7327
-
[7]
C. E. Shannon, A mathematical theory of communica- tion, The Bell system technical journal 27 (3) (1948) 379–423
1948
-
[8]
C. E. Shannon, A mathematical theory of communica- tion, The Bell system technical journal 27 (4) (1948) 623–656
1948
-
[9]
The Annals of Mathe- matical Statistics22(1), 79–86 (1951) https://doi.org/10.1214/aoms/1177729694
S. Kullback, R. A. Leibler, On information and suffi- ciency, Annals of Mathematical Statistics 22 (1) (1951) 79–86. doi:10.1214/aoms/1177729694
-
[10]
G. J. Székely, M. L. Rizzo, N. K. Bakirov, Measuring and testing dependence by correlation of distances, The Annals of Statistics 35 (6) (2007) 2769–2794
2007
-
[11]
M. R. Kosorok, On Brownian distance covariance and high dimensional data, Annals of Applied Statistics 3 (4) (2009) 1266–1269. doi:10.1214/09-AOAS312B
-
[12]
D. N. Reshef, Y. A. Reshef, H. K. Finucane, S. R. Grossman, G. McVean, P. J. Turnbaugh, E. S. Lander, M. Mitzenmacher, P. C. Sabeti, Detecting novel associa- tions in large data sets, Science 334 (6062) (2011) 1518– 1524
2011
-
[13]
J. B. Kinney, G. S. Atwal, Equitability, mutual informa - tion, and the maximal information coefficient, Proceed- ings of the National Academy of Sciences 111 (9) (2014) 3354–3359
2014
-
[14]
Measuring statistical dependence with Hilbert-Schmidt norms
A. Gretton, O. Bousquet, A. Smola, B. Schölkopf, Measuring statistical dependence with Hilbert-Schmidt norms, in: Algorithmic Learning Theory, Vol. 3734 of Lecture Notes in Computer Science, Springer, 2005, pp. 63–77. doi:10.1007/11564089_7
-
[15]
N. Altman, M. Krzywinski, Points of significance: assoc i- ation, correlation and causation, Nature Methods 12 (10) (2015) 899–900. doi:10.1038/nmeth.3587
-
[16]
Reichenbach, The Direction of Time, University of California Press, Berkeley, 1956
H. Reichenbach, The Direction of Time, University of California Press, Berkeley, 1956
1956
-
[17]
D. M. Hausman, J. Woodward, Independence, invariance and the causal markov condition, The British journal for the philosophy of science 50 (4) (1999) 521–583
1999
-
[18]
Geiger, J
D. Geiger, J. Pearl, On the logic of causal models, in: R. D. Shachter, T. S. Levitt, L. N. Kanal, J. F. Lemmer (Eds.), Uncertainty in Artificial Intelligence, Vol. 9 of Machine Intelligence and Pattern Recogni- tion, North-Holland, 1990, pp. 3–14. doi:10.1016/ B978-0-444-88650-7.50006-8 . 15
1990
-
[19]
S. L. Lauritzen, A. P. Dawid, B. N. Larsen, H.-G. Leimer, Independence properties of directed markov fields, Net- works 20 (5) (1990) 491–505
1990
-
[20]
Verma, J
T. Verma, J. Pearl, Equivalence and synthesis of causal models, in: Proceedings of the Sixth Conference on Un- certainty in Artificial Intelligence (UAI’90), Cambridge, MA, 1990, pp. 220–227
1990
-
[21]
Koller, N
D. Koller, N. Friedman, Probabilistic graphical model s: Principles and techniques, MIT press, 2009
2009
-
[22]
De La Fuente, N
A. De La Fuente, N. Bing, I. Hoeschele, P. Mendes, Dis- covery of meaningful associations in genomic data us- ing partial correlation coefficients, Bioinformatics 20 (18 ) (2004) 3565–3574
2004
-
[23]
J. M. Stuart, E. Segal, D. Koller, S. K. Kim, A gene- coexpression network for global discovery of conserved genetic modules, Science 302 (5643) (2003) 249–255
2003
-
[24]
Zhang, X.-M
X. Zhang, X.-M. Zhao, K. He, L. Lu, Y. Cao, J. Liu, J.-K. Hao, Z.-P. Liu, L. Chen, Inferring gene regulatory net- works from gene expression data by path consistency al- gorithm based on conditional mutual information, Bioin- formatics 28 (1) (2012) 98–104
2012
-
[25]
K.-C. Liang, X. Wang, Gene regulatory network reconstruction using conditional mutual information, EURASIP Journal on Bioinformatics and Systems Bi- ology 2008 (2008) 253894. doi:10.1155/2008/253894
-
[26]
Zhang, J
X. Zhang, J. Zhao, J.-K. Hao, X.-M. Zhao, L. Chen, Conditional mutual inclusive information enables accu- rate quantification of associations in gene regulatory net- works, Nucleic Acids Research 43 (5) (2015) e31–e31
2015
-
[27]
J. Zhao, Y. Zhou, X. Zhang, L. Chen, Part mutual in- formation for quantifying direct associations in networks , Proceedings of the National Academy of Sciences 113 (18) (2016) 5130–5135
2016
-
[28]
J. Shi, J. Zhao, X. Liu, L. Chen, T. Li, Quantifying direc t dependencies in biological networks by multiscale associ- ation analysis, IEEE/ACM Transactions on Computa- tional Biology and Bioinformatics 17 (2) (2020) 449–458. doi:10.1109/TCBB.2018.2846536
-
[29]
M. Zhao, Y. Chen, Q. Liu, S. Wu, Quantifying direct as- sociations between variables, Fundamental Research 5 (4) (2025) 1538–1546. doi:10.1016/j.fmre.2023.06.012
-
[30]
Pearl, Probabilistic reasoning in intelligent syst ems: networks of plausible inference, Morgan Kaufmann, 1988
J. Pearl, Probabilistic reasoning in intelligent syst ems: networks of plausible inference, Morgan Kaufmann, 1988
1988
-
[31]
Pearl, Causality, Cambridge University Press, 2009
J. Pearl, Causality, Cambridge University Press, 2009
2009
-
[32]
Pearl, Causal inference in statistics: An overview, Statistics Surveys 3 (2009) 96–146
J. Pearl, Causal inference in statistics: An overview, Statistics Surveys 3 (2009) 96–146
2009
-
[33]
Pearl, Direct and indirect effects, in: H
J. Pearl, Direct and indirect effects, in: H. Geffner, R. Dechter, J. Y. Halpern (Eds.), Probabilistic and Causal Inference: The Works of Judea Pearl, ACM Books, 2022, pp. 373–392. doi:10.1145/3501714. 3501736
-
[34]
P. W. Holland, Statistics and causal inference, Journa l of the American Statistical Association 81 (396) (1986) 945–960. doi:10.1080/01621459.1986.10478354
-
[35]
Janzing, D
D. Janzing, D. Balduzzi, M. Grosse-Wentrup, B. Schölkopf, Quantifying causal influences, The Annals of Statistics 41 (5) (2013) 2324–2358
2013
-
[36]
D. A. Freedman, Statistical models: theory and practic e, Cambridge University Press, 2009
2009
-
[37]
McNamee, Confounding and confounders, Occupa- tional and Environmental Medicine 60 (3) (2003) 227– 234
R. McNamee, Confounding and confounders, Occupa- tional and Environmental Medicine 60 (3) (2003) 227– 234
2003
-
[38]
Peters, D
J. Peters, D. Janzing, B. Schölkopf, Elements of Causal Inference: Foundations and Learning Algorithms , MIT Press, Cambridge, MA, 2017
2017
-
[39]
J. Lin, Divergence measures based on the Shannon en- tropy, IEEE Transactions on Information Theory 37 (1) (1991) 145–151. doi:10.1109/18.61115
-
[40]
D. M. Endres, J. E. Schindelin, A new metric for proba- bility distributions, IEEE Transactions on Information Theory 49 (7) (2003) 1858–1860. doi:10.1109/TIT. 2003.813506
work page doi:10.1109/tit 2003
-
[41]
R. Kohavi, B. Becker, Adult Data Set (Census In- come), UCI Machine Learning Repository (1996). doi:10.24432/C5XW20. URL https://archive.ics.uci.edu/ml/ machine-learning-databases/adult/adult.data
-
[42]
The Annals of Statistics7(1), 1–26 (1979) https://doi.org/10.1214/aos/1176344552
B. Efron, Bootstrap methods: another look at the jack- knife, Annals of Statistics 7 (1) (1979) 1–26. doi: 10.1214/aos/1176344552
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.