Recognition: unknown
Towards Optimal Agentic Architectures for Offensive Security Tasks
Pith reviewed 2026-05-10 03:58 UTC · model grok-4.3
The pith
Agentic security audits reveal a non-monotonic cost-quality frontier across coordination topologies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
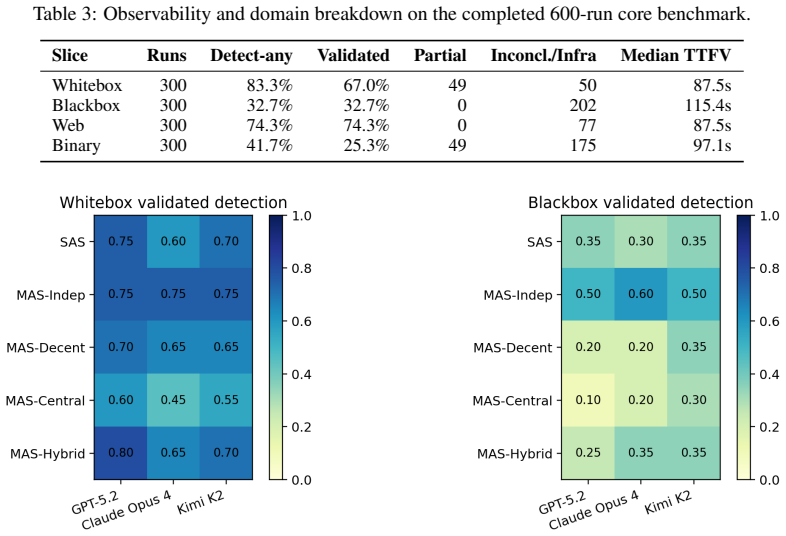
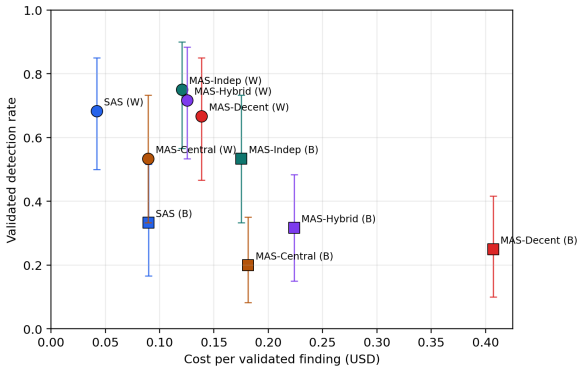
Across 600 runs on 20 targets, validated detection reaches 49.8 percent overall. MAS-Indep attains 64.2 percent validated detection while SAS sets the efficiency baseline at 0.058 dollars per validated finding. Whitebox mode outperforms blackbox (67.0 percent versus 32.7 percent) and web targets outperform binary (74.3 percent versus 25.3 percent). Bootstrap intervals confirm that domain and observability dominate, producing a non-monotonic cost-quality frontier where broader coordination improves coverage but does not dominate once latency, token cost, and exploit-validation difficulty are included.
What carries the argument
Controlled benchmark of 20 interactive targets with endpoint-reachable ground-truth vulnerabilities, executed across five architecture families in whitebox and blackbox modes to measure validated detection rate and cost per finding.
If this is right
- Whitebox access yields materially higher validated detection than blackbox access.
- Web and API targets prove substantially easier than binary targets under the same architectures.
- Some leading whitebox topologies remain statistically close, so topology choice is secondary to observability and domain.
- Broader coordination improves coverage only up to the point where added latency and token cost exceed the marginal gain in validated findings.
Where Pith is reading between the lines
- Production deployments may benefit from adaptive selection among topologies rather than committing to one family in advance.
- The cost-quality frontier implies that real-world pipelines could monitor per-target latency and validation difficulty to switch architectures dynamically.
- The gap between any-detection and validated-detection rates highlights the practical importance of automated exploit confirmation steps that current benchmarks treat as separate.
Load-bearing premise
The 20 chosen targets and the binary definition of validated detection accurately represent the distribution and difficulty of real-world offensive security tasks.
What would settle it
Repeating the experiments on a substantially larger or differently distributed set of targets, or replacing the binary validated-detection label with a graded exploit-success score, would show whether the non-monotonic frontier still holds.
Figures


read the original abstract
Agentic security systems increasingly audit live targets with tool-using LLMs, but prior systems fix a single coordination topology, leaving unclear when additional agents help and when they only add cost. We treat topology choice as an empirical systems question. We introduce a controlled benchmark of 20 interactive targets (10 web/API and 10 binary), each exposing one endpoint-reachable ground-truth vulnerability, evaluated in whitebox and blackbox modes. The core study executes 600 runs over five architecture families, three model families, and both access modes, with a separate 60-run long-context pilot reported only in the appendix. On the completed core benchmark, detection-any reaches 58.0% and validated detection reaches 49.8%. MAS-Indep attains the highest validated detection rate (64.2%), while SAS is the strongest efficiency baseline at $0.058 per validated finding. Whitebox materially outperforms blackbox (67.0% vs. 32.7% validated detection), and web materially outperforms binary (74.3% vs. 25.3%). Bootstrap confidence intervals and paired target-level deltas show that the dominant effects are observability and domain, while some leading whitebox topologies remain statistically close. The main result is a non-monotonic cost-quality frontier: broader coordination can improve coverage, but it does not dominate once latency, token cost, and exploit-validation difficulty are taken into account.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper treats choice of agent coordination topology as an empirical systems question for LLM-based offensive security auditing. It introduces a controlled benchmark of 20 interactive targets (10 web/API, 10 binary), each with one endpoint-reachable ground-truth vulnerability, and reports results from 600 runs across five architecture families, three model families, and whitebox/blackbox access modes (plus a 60-run long-context pilot in the appendix). Core findings are an overall validated detection rate of 49.8% (MAS-Indep highest at 64.2%), SAS as the strongest efficiency baseline ($0.058 per validated finding), large gaps favoring whitebox over blackbox (67.0% vs 32.7%) and web over binary (74.3% vs 25.3%), supported by bootstrap confidence intervals and paired target-level deltas. The central claim is a non-monotonic cost-quality frontier: broader coordination can improve coverage but does not dominate once latency, token cost, and exploit-validation difficulty are accounted for.
Significance. If the benchmark is representative, the work supplies one of the first systematic, multi-architecture comparisons in this domain, with concrete, statistically supported metrics that can guide practical deployment of tool-using LLM agents for security tasks. The reporting of bootstrap CIs, target-level paired deltas, and explicit cost-quality trade-offs is a clear strength that moves beyond single-topology case studies. The non-monotonic frontier result, if robust, directly informs when additional agents add net value versus overhead.
major comments (2)
- [§3] Benchmark construction (§3, Target Selection and Evaluation Protocol): The non-monotonic cost-quality frontier and the relative ranking of MAS-Indep versus SAS rest on the assumption that the 20 targets and the binary 'validated detection' success criterion faithfully sample real-world difficulty, observability, and validation cost. The manuscript provides no quantitative comparison of target difficulty distribution, vulnerability types, or observability characteristics against broader offensive-security corpora, nor any sensitivity analysis to post-hoc exclusion rules. This is load-bearing for the central claim.
- [§5] Statistical interpretation of topology rankings (§5, Results): The paper notes that some leading whitebox topologies remain statistically close, yet still presents MAS-Indep as attaining the highest validated detection rate. No formal multiple-comparison correction or power analysis is reported for the 600-run design, leaving open whether the observed ordering (and therefore the non-monotonic frontier) is robust to small changes in the target set or success threshold.
minor comments (3)
- [Abstract and §4] The abstract and §4 introduce acronyms (MAS-Indep, SAS) without immediate expansion; define all architecture families on first use in the main text.
- [Appendix] The 60-run long-context pilot is relegated to the appendix; a one-paragraph summary of its implications for the cost-quality frontier should be added to the main discussion or conclusion.
- [Figures] Figure(s) depicting the cost-quality frontier would benefit from explicit annotation of the non-monotonic inflection points and error bars derived from the bootstrap intervals.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments on benchmark representativeness and statistical robustness are well-taken and will improve the manuscript. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3] Benchmark construction (§3, Target Selection and Evaluation Protocol): The non-monotonic cost-quality frontier and the relative ranking of MAS-Indep versus SAS rest on the assumption that the 20 targets and the binary 'validated detection' success criterion faithfully sample real-world difficulty, observability, and validation cost. The manuscript provides no quantitative comparison of target difficulty distribution, vulnerability types, or observability characteristics against broader offensive-security corpora, nor any sensitivity analysis to post-hoc exclusion rules. This is load-bearing for the central claim.
Authors: We agree that demonstrating the benchmark's representativeness strengthens the central claims. No standardized public corpus of interactive targets with endpoint-reachable ground-truth vulnerabilities currently exists for direct quantitative matching, which precludes a full comparative analysis. We will revise Section 3 to add an explicit discussion of target selection criteria, diversity across domains and access modes, and limitations on generalizability. We will also perform and report a sensitivity analysis varying the validated-detection threshold and target subsets to test robustness of the topology rankings and non-monotonic frontier. revision: partial
-
Referee: [§5] Statistical interpretation of topology rankings (§5, Results): The paper notes that some leading whitebox topologies remain statistically close, yet still presents MAS-Indep as attaining the highest validated detection rate. No formal multiple-comparison correction or power analysis is reported for the 600-run design, leaving open whether the observed ordering (and therefore the non-monotonic frontier) is robust to small changes in the target set or success threshold.
Authors: We appreciate the call for additional statistical safeguards. The existing bootstrap CIs and paired target-level deltas already indicate that top whitebox topologies are close. In the revision we will add a power analysis for the primary detection-rate comparisons and apply a multiple-comparison correction (Bonferroni) to the paired statistical tests. These changes will clarify robustness without changing the reported ordering or the cost-quality frontier conclusion. revision: yes
- Quantitative comparison of the 20-target difficulty distribution and observability characteristics against broader offensive-security corpora, as no directly comparable public datasets exist.
Circularity Check
No significant circularity in empirical measurement study
full rationale
The paper conducts a controlled empirical benchmark with 600 runs across five architecture families on 20 fixed targets, reporting observed detection rates, costs, and a non-monotonic frontier directly from the experimental data. There are no derivations, equations, fitted parameters renamed as predictions, or self-citations that reduce the central claims to quantities defined inside the paper. The benchmark targets, whitebox/blackbox modes, and validated-detection metric are defined independently of the results, so the reported outcomes remain self-contained measurements rather than tautological restatements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Each of the 20 targets exposes exactly one endpoint-reachable ground-truth vulnerability that defines success.
Forward citations
Cited by 1 Pith paper
-
Patch2Vuln: Agentic Reconstruction of Vulnerabilities from Linux Distribution Binary Patches
An agentic pipeline localizes the security-relevant function in 10 of 20 Ubuntu binary security updates and produces an accepted root-cause classification in 11 of 20, limited mainly by binary differencing coverage.
Reference graph
Works this paper leans on
-
[1]
Purple llama cyberseceval: A secure coding benchmark for language models, 2023
Manish Bhatt, Sahana Chennabasappa, Cyrus Nikolaidis, Shengye Wan, Ivan Evtimov, Do- minik Gabi, Daniel Song, Faizan Ahmad, Cornelius Aschermann, Lorenzo Fontana, Sasha Frolov, Ravi Prakash Giri, Dhaval Kapil, Yiannis Kozyrakis, David LeBlanc, James Milazzo, 9 Aleksandar Straumann, Gabriel Synnaeve, Varun V ontimitta, Spencer Whitman, and Joshua Saxe. Pur...
-
[2]
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cornelius Aschermann, Yaohui Chen, Dhaval Kapil, David Molnar, Spencer Whitman, and Joshua Saxe. Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models, 2024. URLhttps://arxiv.org/abs/2404.13161
-
[3]
Multi-agent penetration testing ai for the web,
Isaac David and Arthur Gervais. Multi-agent penetration testing ai for the web, 2025. URL https://arxiv.org/abs/2508.20816
-
[4]
Pentestgpt: Evaluating and harness- ing large language models for automated penetration testing
Gelei Deng, Yi Liu, Victor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. Pentestgpt: Evaluating and harness- ing large language models for automated penetration testing. In33rd USENIX Security Symposium (USENIX Security 24), 2024. URLhttps://www.usenix.org/conference/ usenixsecurity24/presentation/deng
2024
-
[5]
Llm agents can au- tonomously exploit one-day vulnerabilities
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. LLM agents can autonomously exploit one-day vulnerabilities, 2024. URLhttps://arxiv.org/abs/2404.08144
-
[6]
LLM agents can autonomously hack websites, 2024
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. LLM agents can autonomously hack websites, 2024. URLhttps://arxiv.org/abs/2402.06664
-
[7]
Single-agent or Multi -agent Systems ? Why Not Both ?, May 2025
Mingyan Gao, Yanzi Li, Banruo Liu, Yifan Yu, Phillip Wang, Ching-Yu Lin, and Fan Lai. Single-agent or multi-agent systems? why not both?, 2025. URLhttps://arxiv.org/abs/ 2505.18286
-
[8]
Ai agent smart contract exploit generation
Arthur Gervais and Liyi Zhou. Ai agent smart contract exploit generation. InFinancial Cryp- tography and Data Security (FC), 2026. URLhttps://arxiv.org/abs/2507.05558
-
[9]
Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Yun Liu, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yilun Du, Shwetak Patel, Tim Althoff, Daniel McDuff, and Xin Liu. Towards a science of scaling agent systems, 2025. URLhttps://arxiv.org/abs/2512. 08296
2025
-
[10]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InInternational Conference on Learn- ing Representat...
2024
-
[11]
Zefang Liu, Jialei Shi, and John F. Buford. Cyberbench: A multi-task benchmark for evaluating large language models in cybersecurity. InAAAI 2024 Workshop on Artificial Intelligence for Cyber Security (AICS), 2024. URLhttps://aics.site/AICS2024/AICS_CyberBench. pdf
2024
-
[12]
Common weakness enumeration, 2026
MITRE. Common weakness enumeration, 2026. URLhttps://cwe.mitre.org/
2026
-
[13]
Single-agent LLMs outperform multi-agent systems on multi-hop reasoning under equal thinking token budgets, 2026
Dat Tran and Douwe Kiela. Single-agent LLMs outperform multi-agent systems on multi-hop reasoning under equal thinking token budgets, 2026. URLhttps://arxiv.org/abs/2604. 02460
2026
-
[14]
Lin, Andy Applebaum, Tejal Patwardhan, Alpin Yukseloglu, and Olivia Watkins
Justin Wang, Andreas Bigger, Xiaohai Xu, Justin W. Lin, Andy Applebaum, Tejal Patwardhan, Alpin Yukseloglu, and Olivia Watkins. Evmbench: Evaluating ai agents on smart contract security, 2026. URLhttps://cdn.openai.com/evmbench/evmbench.pdf
2026
-
[15]
Ai agents find $4.6m in blockchain smart contract exploits.https://red.anthropic.com/ 2025/smart-contracts/, December 2025
Winnie Xiao, Cole Killian, Henry Sleight, Alan Chan, Nicholas Carlini, and Alwin Peng. Ai agents find $4.6m in blockchain smart contract exploits.https://red.anthropic.com/ 2025/smart-contracts/, December 2025. Anthropic Frontier Red Team blog post intro- ducing SCONE-bench. 10
2025
-
[16]
Jiawei Zhang, Guangyu Liu, Oscar Johansson, et al
Jiawei Xu, Arief Koesdwiady, Sisong Bei, Yan Han, Baixiang Huang, Dakuo Wang, Yutong Chen, Zheshen Wang, Peihao Wang, Pan Li, and Ying Ding. Rethinking the value of multi- agent workflow: A strong single agent baseline, 2026. URLhttps://arxiv.org/abs/ 2601.12307
-
[17]
arXiv preprint arXiv:2306.14898 , year=
John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao. Intercode: Stan- dardizing and benchmarking interactive coding with execution feedback. InAdvances in Neural Information Processing Systems 36: Datasets and Benchmarks Track, 2023. URL https://arxiv.org/abs/2306.14898
-
[18]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Zhang, Joey Ji, Celeste Menders, Riya Dulepet, T
Andy K. Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y . Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu, Sara Hong, Nardos Demilew, Shivatmica Murgai, Jason Tran, Nishka Kacheria, Ethan Ho, Denis Liu, Lauren McLane, Olivia Bruvik, Dai-Rong Han, Seungwoo Kim, Akhil Vyas, Cuiyuanxiu Chen, Ryan Li, Weiran Xu, Jonathan Z. Ye, Prerit C...
-
[20]
Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W
Andy K. Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W. Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Jasper, Pura Peetathawatchai, Ari Glenn, Vikram Sivashankar, Daniel Zamoshchin, Leo Glikbarg, Derek Askaryar, Mike Yang, Teddy Zhang, Rishi Alluri, Nathan Tran, Rinnara Sangpisit, Polycarpos Yiorkadjis, Kenny Osele, Gautham ...
2025
-
[21]
Teams of LLM agents can exploit zero-day vulnerabilities.arXiv preprint arXiv:2406.01637, 2024
Yuxuan Zhu, Antony Kellermann, Akul Gupta, Philip Li, Richard Fang, Rohan Bindu, and Daniel Kang. Teams of LLM agents can exploit zero-day vulnerabilities, 2024. URLhttps: //arxiv.org/abs/2406.01637. 11 A Limitations, Broader Impact, and Safety This work evaluates authorized testing only and uses intentionally vulnerable targets. Any release of offensive-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.