Recognition: unknown
Patch2Vuln: Agentic Reconstruction of Vulnerabilities from Linux Distribution Binary Patches
Pith reviewed 2026-05-08 08:47 UTC · model grok-4.3
The pith
A local agent reconstructs vulnerability root causes from binary patches in 11 of 20 Linux updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
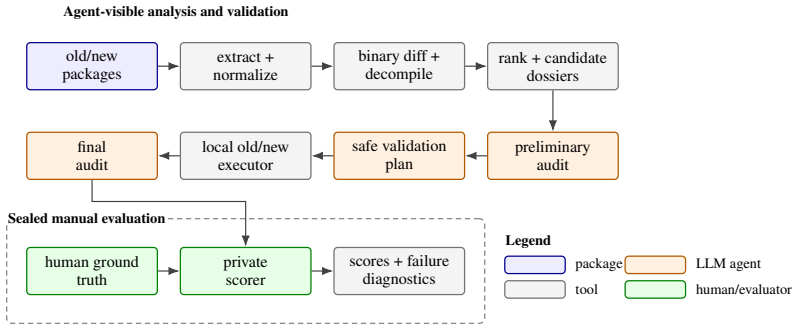
Patch2Vuln is a resumable pipeline that extracts old/new ELF pairs from Ubuntu .deb packages, diffs them with Ghidra and Ghidriff, ranks changed functions by security relevance, builds dossiers, and directs an offline agent to output a preliminary audit, bounded validation plan, and final root-cause classification. On 20 security-update pairs, the agent localizes the verified security-relevant patch function in 10 cases and assigns an accepted final root-cause class in 11 cases, with all 5 negative controls correctly marked unknown. Oracle analysis reveals that 6 failures occur before agent reasoning due to the differencer or ranker omitting the right function.
What carries the argument
The agentic pipeline combining binary differencing of ELF pairs with function ranking and offline language model reasoning to produce root-cause audits.
If this is right
- Binary-only reconstruction can identify patch functions without source access.
- Validation passes can produce behavioral differentials in some cases like tcpdump.
- Negative controls are reliably classified as unknown without false positives.
- Binary diff coverage limits the overall success rate.
Where Pith is reading between the lines
- Improving binary differencing tools could raise the localization rate above 50%.
- Extending to other distributions or architectures would test broader applicability.
- Combining with dynamic analysis might yield more crash proofs in validation.
- Such agents could integrate into automated patch monitoring workflows.
Load-bearing premise
The binary differencer and function ranker must reliably surface the security-relevant changed function for the agent to analyze it.
What would settle it
Observe whether the pipeline's localization success rate exceeds 10 out of 20 when tested on a new set of 20 security-update pairs from Ubuntu or another distribution.
Figures

read the original abstract
Security updates create a short but important window in which defenders and attackers can compare vulnerable and patched software. Yet in many operational settings, the most accessible artifacts are binary packages rather than source patches or advisory text. This paper asks whether a language-model agent, restricted to local binary-derived evidence, can reconstruct the security meaning of Linux distribution updates. Patch2Vuln is a local, resumable pipeline that extracts old/new ELF pairs, diffs them with Ghidra and Ghidriff, ranks changed functions, builds candidate dossiers, and asks an offline agent to produce a preliminary audit, bounded validation plan, and final audit. We evaluate Patch2Vuln on 25 Ubuntu `.deb` package pairs: 20 security-update pairs and five negative controls, all manually adjudicated against private source-patch and binary-function ground truth. The agent localizes a verified security-relevant patch function in 10 of 20 security pairs and assigns an accepted final root-cause class in 11 of 20. Oracle diagnostics show that six security pairs fail before model reasoning because the binary differ or ranker omits the right function, with one additional context-export miss. A separate bounded validation pass produces two target-level minimized behavioral old/new differentials, both for tcpdump, but no crash, timeout, sanitizer finding, or memory-corruption proof; all five negative controls are classified as unknown and produce no validation differentials. These results support agentic vulnerability reconstruction from binary patches as a useful research target while showing that binary-diff coverage and local behavioral validation remain the limiting components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Patch2Vuln, a local, resumable pipeline that extracts old/new ELF pairs from Ubuntu .deb packages, diffs them via Ghidra and Ghidriff, ranks changed functions, builds candidate dossiers, and uses an offline language-model agent to generate a preliminary audit, bounded validation plan, and final root-cause classification. On a manually adjudicated set of 25 pairs (20 security-update pairs and 5 negative controls), the agent localizes a verified security-relevant patch function in 10 of 20 security pairs and assigns an accepted final root-cause class in 11 of 20; six security pairs fail before model reasoning due to binary-diff or ranker omissions, one additional context-export miss occurs, the validation pass yields only two target-level behavioral differentials (both for tcpdump) with no crash/timeout/sanitizer/memory-corruption evidence, and all negative controls are classified as unknown.
Significance. If the results hold, the work establishes a concrete baseline for agentic vulnerability reconstruction from binary-only artifacts, which is significant for operational settings where source patches or advisories are unavailable. The explicit identification of binary-diff coverage and local behavioral validation as limiting factors, together with the use of negative controls and modest framing, positions the contribution as a useful research target rather than an end-to-end solution.
major comments (2)
- [Evaluation] Evaluation section (abstract and results): the localization success of 10/20 and accepted classification of 11/20 are load-bearing for the central claim, yet six of the 20 security pairs fail before any agent reasoning because the binary differencer/ranker omits the relevant function; this upstream dependency means the agent's contribution is only evaluated on a reduced subset and the pipeline's overall effectiveness cannot be isolated from the quality of the differencing tool.
- [Validation] Validation pass (abstract and results): the bounded validation produces only two minimized behavioral old/new differentials (both tcpdump) and no crash, timeout, sanitizer finding, or memory-corruption proof across the 20 security cases; without concrete exploit or proof evidence the final root-cause classifications rest primarily on agent reasoning, weakening support for the claim that the method reconstructs verifiable vulnerabilities.
minor comments (2)
- [Abstract] Abstract: the distinction between 'localizes a verified security-relevant patch function' (10/20) and 'assigns an accepted final root-cause class' (11/20) is not fully explained; clarify the overlap, the adjudication criteria for acceptance, and how the two metrics relate.
- [Evaluation] Evaluation: add a compact table or per-pair breakdown of outcomes for the 20 security pairs (localization success, classification result, failure mode) to improve transparency and allow readers to assess patterns.
Simulated Author's Rebuttal
Thank you for the constructive review and the recommendation for minor revision. We address each major comment below. The manuscript already transparently reports the limitations noted by the referee, supporting our modest framing of the work as a baseline for future research.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (abstract and results): the localization success of 10/20 and accepted classification of 11/20 are load-bearing for the central claim, yet six of the 20 security pairs fail before any agent reasoning because the binary differencer/ranker omits the relevant function; this upstream dependency means the agent's contribution is only evaluated on a reduced subset and the pipeline's overall effectiveness cannot be isolated from the quality of the differencing tool.
Authors: We thank the referee for highlighting this important aspect of the evaluation. The paper explicitly discloses in both the abstract and the results section that six security pairs fail prior to agent reasoning due to omissions by the binary differencer or ranker. Our evaluation measures the end-to-end pipeline performance, which necessarily depends on the upstream binary analysis tools. We provide oracle diagnostics precisely to allow readers to assess the agent's contribution separately on the subset where the differencing succeeds. The central claim concerns the feasibility of agentic reconstruction using binary-derived artifacts, not an isolated evaluation of the language model. We believe the current presentation is accurate and does not require revision. revision: no
-
Referee: [Validation] Validation pass (abstract and results): the bounded validation produces only two minimized behavioral old/new differentials (both tcpdump) and no crash, timeout, sanitizer finding, or memory-corruption proof across the 20 security cases; without concrete exploit or proof evidence the final root-cause classifications rest primarily on agent reasoning, weakening support for the claim that the method reconstructs verifiable vulnerabilities.
Authors: The referee correctly observes that the bounded validation yields limited concrete evidence. This is reported in the manuscript: only two target-level behavioral differentials were produced, both for tcpdump, with no crash, timeout, sanitizer, or memory-corruption findings. The root-cause classifications rely on the agent's analysis of the binary-derived dossiers, as the local validation environment did not yield stronger proof artifacts in most cases. We frame the contribution as a baseline for agentic vulnerability reconstruction rather than a method that produces verifiable exploits. The absence of such evidence is presented as a key limitation and research target. No changes to the manuscript are necessary, as the results are presented factually and the claims are appropriately qualified. revision: no
Circularity Check
No significant circularity
full rationale
The paper describes an empirical pipeline (binary extraction, Ghidra/Ghidriff differencing, function ranking, dossier construction, and offline agent auditing) evaluated directly on 25 manually adjudicated Ubuntu package pairs. All reported outcomes (10/20 localization, 11/20 root-cause classification, 6 early failures from differencer/ranker) are measured against private source-patch ground truth with explicit negative controls. No equations, fitted parameters, uniqueness theorems, or self-citations appear in the derivation chain; the central claims are statistical results from the evaluation itself and do not reduce to any input by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ghidra and Ghidriff produce sufficiently accurate function-level diffs on real Ubuntu ELF binaries for the downstream ranking step to be meaningful.
- domain assumption An offline language-model agent can produce preliminary audits, validation plans, and root-cause classifications that align with human ground truth when given only binary-derived context.
Reference graph
Works this paper leans on
-
[1]
Talor Abramovich, Meet Udeshi, Minghao Shao, Kilian Lieret, Haoran Xi, Kimberly Milner, Sofija Jancheska, John Yang, Carlos E. Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik Narasimhan, Ramesh Karri, and Ofir Press. EnIGMA: Interactive tools substantially assist LM agents in finding security vulnerabil...
-
[2]
AEG: Au- tomatic exploit generation
Thanassis Avgerinos, Sang Kil Cha, Brent Lim Tze Hao, and David Brumley. AEG: Au- tomatic exploit generation. InProceedings of the Network and Distributed System Secu- rity Symposium, NDSS 2011, 2011. URL https://www.ndss-symposium.org/ndss2011/ aeg-automatic-exploit-generation/
2011
-
[3]
Automatic patch- based exploit generation is possible: Techniques and implications
David Brumley, Pongsin Poosankam, Dawn Xiaodong Song, and Jiang Zheng. Automatic patch- based exploit generation is possible: Techniques and implications. InProceedings of the IEEE Symposium on Security and Privacy, pages 143–157, April 2008. doi: 10.1109/SP.2008.17. URLhttps://doi.org/10.1109/SP.2008.17
-
[4]
David Brumley, Ivan Jager, Thanassis Avgerinos, and Edward J. Schwartz. BAP: A binary analysis platform. InProceedings of the 23rd International Conference on Computer Aided Verification, CA V 2011, pages 463–469, 2011. doi: 10.1007/978-3-642-22110-1_37. URL https://doi.org/10.1007/978-3-642-22110-1_37
-
[5]
Cristian Cadar, Daniel Dunbar, and Dawson R. Engler. KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs. InProceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2008, pages 209–224, 2008. URL https://www.usenix.org/conference/osdi-08/presentation/ klee-unassisted-and-automat...
2008
-
[6]
Unleashing Mayhem on Binary Code
Sang Kil Cha, Thanassis Avgerinos, Alexandre Rebert, and David Brumley. Unleashing MAYHEM on binary code. InProceedings of the IEEE Symposium on Security and Privacy, pages 380–394, 2012. doi: 10.1109/SP.2012.31. URL https://doi.org/10.1109/SP.2012. 31
-
[7]
S2E: A platform for in- vivo multi-path analysis of software systems
Vitaly Chipounov, V olodymyr Kuznetsov, and George Candea. S2E: A platform for in- vivo multi-path analysis of software systems. InProceedings of the Sixteenth Interna- tional Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS XVI, pages 265–278, 2011. doi: 10.1145/1950365.1950396. URL https://doi.org/10.1145/19503...
-
[8]
Ghidriff documentation, 2025
Clearbluejar. Ghidriff documentation, 2025. URL https://clearbluejar.github.io/ ghidriff/. Accessed 2026-05-02
2025
-
[9]
Multi-agent penetration testing ai for the web,
Isaac David and Arthur Gervais. Multi-agent penetration testing ai for the web, 2025. URL https://arxiv.org/abs/2508.20816
-
[10]
Towards Optimal Agentic Architectures for Offensive Security Tasks
Isaac David and Arthur Gervais. Towards optimal agentic architectures for offensive security tasks, 2026. URLhttps://arxiv.org/abs/2604.18718
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Cyber grand challenge, 2014
Defense Advanced Research Projects Agency. Cyber grand challenge, 2014. URL https: //www.darpa.mil/about/innovation-timeline/cyber-grand-challenge . Accessed 2026-05-02
2014
-
[12]
Pentestgpt: An llm- empowered automatic penetration testing tool
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. PentestGPT: An LLM-empowered automatic penetration testing tool, 2024. URLhttps://arxiv.org/abs/2308.06782
-
[13]
Steven H. H. Ding, Benjamin C. M. Fung, and Philippe Charland. Asm2Vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization. InProceedings of the IEEE Symposium on Security and Privacy, pages 472–489,
-
[14]
URLhttps://doi.org/10.1109/SP.2019.00003
doi: 10.1109/SP.2019.00003. URLhttps://doi.org/10.1109/SP.2019.00003
-
[15]
Install docker desktop on mac, 2026
Docker. Install docker desktop on mac, 2026. URLhttps://docs.docker.com/desktop/ setup/install/mac-install/. Accessed 2026-05-02. 10
2026
-
[16]
DeepBinDiff: Learning program- wide code representations for binary diffing
Yue Duan, Xuezixiang Li, Jinghan Wang, and Heng Yin. DeepBinDiff: Learning program- wide code representations for binary diffing. InProceedings of the Network and Distributed System Security Symposium, NDSS 2020, 2020. doi: 10.14722/ndss.2020.24311. URL https: //doi.org/10.14722/ndss.2020.24311
-
[17]
discovRE: Efficient cross- architecture identification of bugs in binary code
Sebastian Eschweiler, Khaled Yakdan, and Elmar Gerhards-Padilla. discovRE: Efficient cross- architecture identification of bugs in binary code. InProceedings of the Network and Distributed System Security Symposium, NDSS 2016, 2016. doi: 10.14722/ndss.2016.23185. URL https: //doi.org/10.14722/ndss.2016.23185
-
[18]
Llm agents can au- tonomously exploit one-day vulnerabilities
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. LLM agents can autonomously exploit one-day vulnerabilities, 2024. URLhttps://arxiv.org/abs/2404.08144
-
[19]
Scalable graph-based bug search for firmware images
Qian Feng, Rundong Zhou, Chengcheng Xu, Yao Cheng, Brian Testa, and Heng Yin. Scalable graph-based bug search for firmware images. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS 2016, pages 480–491, 2016. doi: 10.1145/2976749.2978370. URLhttps://doi.org/10.1145/2976749.2978370
-
[20]
Reiter, and Dawn Song
Debin Gao, Michael K. Reiter, and Dawn Song. BinHunt: Automatically finding semantic differences in binary programs. InProceedings of the 10th International Conference on Information and Communications Security, ICICS 2008, pages 238–255, 2008. URL https: //people.eecs.berkeley.edu/~dawnsong/papers/2008%20binhunt_icics08.pdf
2008
-
[21]
VulSeeker: A semantic learning based vulnerability seeker for cross-platform binary
Jian Gao, Xin Yang, Ying Fu, Yu Jiang, and Jiaguang Sun. VulSeeker: A semantic learning based vulnerability seeker for cross-platform binary. InProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, ASE 2018, pages 896–899, 2018. doi: 10.1145/3238147.3240480. URLhttps://doi.org/10.1145/3238147.3240480
-
[22]
Patrice Godefroid, Michael Y . Levin, and David A. Molnar. SAGE: Whitebox fuzzing for security testing.Communications of the ACM, 55(3):40–44, 2012. doi: 10.1145/2093548. 2093564. URLhttps://doi.org/10.1145/2093548.2093564
-
[23]
ReDeBug: Finding unpatched code clones in entire OS distributions
Jiyong Jang, Abeer Agrawal, and David Brumley. ReDeBug: Finding unpatched code clones in entire OS distributions. InProceedings of the IEEE Symposium on Security and Privacy, pages 48–62, 2012. URL https://www.ieee-security.org/TC/SP2012/papers/4681a048. pdf
2012
-
[24]
VUDDY: A scalable approach for vulnerable code clone discovery
Seulbae Kim, Seunghoon Woo, Heejo Lee, and Hakjoo Oh. VUDDY: A scalable approach for vulnerable code clone discovery. InProceedings of the IEEE Symposium on Security and Privacy, pages 595–614, 2017. URLhttps://dblp.org/rec/conf/sp/KimWLO17
2017
-
[25]
SAFE: Self-attentive function embeddings for binary similarity
Luca Massarelli, Giuseppe Antonio Di Luna, Fabio Petroni, Roberto Baldoni, and Leonardo Querzoni. SAFE: Self-attentive function embeddings for binary similarity. InProceedings of the 16th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, DIMV A 2019, pages 309–329, 2019. doi: 10.1007/978-3-030-22038-9_15. URL h...
-
[26]
Ghidra headless analyzer documentation, 2025
National Security Agency. Ghidra headless analyzer documentation, 2025. URL https: //ghidra.re/ghidra_docs/analyzeHeadlessREADME.html. Accessed 2026-05-02
2025
-
[27]
SOK: (State of) The Art of War: Offensive Techniques in Binary Analysis,
Yan Shoshitaishvili, Ruoyu Wang, Christopher Salls, Nick Stephens, Mario Polino, Andrew Dutcher, John Grosen, Siji Feng, Christophe Hauser, Christopher Kruegel, and Giovanni Vigna. SOK: (state of) the art of war: Offensive techniques in binary analysis. InProceedings of the IEEE Symposium on Security and Privacy, pages 138–157, 2016. doi: 10.1109/SP.2016....
-
[28]
BitBlaze: A new approach to computer security via binary analysis
Dawn Song, David Brumley, Heng Yin, Juan Caballero, Ivan Jager, Min Gyung Kang, Zhenkai Liang, James Newsome, Pongsin Poosankam, and Prateek Saxena. BitBlaze: A new approach to computer security via binary analysis. InProceedings of the 4th International Conference on In- formation Systems Security, ICISS 2008, pages 1–25, 2008. doi: 10.1007/978-3-540-898...
-
[29]
In Proceedings 2016 Network and Distributed System Security Symposium
Nick Stephens, John Grosen, Christopher Salls, Andrew Dutcher, Ruoyu Wang, Jacopo Corbetta, Yan Shoshitaishvili, Christopher Kruegel, and Giovanni Vigna. Driller: Augmenting fuzzing through selective symbolic execution. InProceedings of the Network and Distributed System Security Symposium, NDSS 2016, 2016. doi: 10.14722/ndss.2016.23368. URL https://doi. ...
-
[30]
CVE-2018-14464, 2018
Ubuntu. CVE-2018-14464, 2018. URL https://ubuntu.com/security/ CVE-2018-14464. Accessed 2026-05-02
2018
-
[31]
CVE-2018-16301, 2019
Ubuntu. CVE-2018-16301, 2019. URL https://ubuntu.com/security/ CVE-2018-16301. Accessed 2026-05-03
2018
-
[32]
CVE-2020-8037, 2020
Ubuntu. CVE-2020-8037, 2020. URL https://ubuntu.com/security/CVE-2020-8037. Accessed 2026-05-03
2020
-
[33]
USN-4252-1: tcpdump vulnerabilities, 2020
Ubuntu. USN-4252-1: tcpdump vulnerabilities, 2020. URL https://ubuntu.com/ security/notices/USN-4252-1. Accessed 2026-05-02
2020
-
[34]
CVE-2022-25235, 2022
Ubuntu. CVE-2022-25235, 2022. URL https://ubuntu.com/security/ CVE-2022-25235. Accessed 2026-05-02
2022
-
[35]
USN-5288-1: Expat vulnerabilities, 2022
Ubuntu. USN-5288-1: Expat vulnerabilities, 2022. URL https://ubuntu.com/security/ notices/USN-5288-1. Accessed 2026-05-02
2022
-
[36]
Neural network- based graph embedding for cross-platform binary code similarity detection
Xiaojun Xu, Chang Liu, Qian Feng, Heng Yin, Le Song, and Dawn Song. Neural network- based graph embedding for cross-platform binary code similarity detection. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS 2017, pages 363–376, 2017. doi: 10.1145/3133956.3134018. URL https://doi.org/10.1145/ 3133956.3134018
-
[37]
Patch based vulnerability matching for binary programs
Yifei Xu, Zhengzi Xu, Bihuan Chen, Fu Song, Yang Liu, and Ting Liu. Patch based vulnerability matching for binary programs. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2020, 2020. doi: 10.1145/3395363. 3397361. URLhttps://doi.org/10.1145/3395363.3397361
-
[38]
Cybench: A framework for evaluating cybersecurity capabilities and risks of language models
Andy K. Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W. Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Jasper, Pura Peetathawatchai, Ari Glenn, Vikram Sivashankar, Daniel Zamoshchin, Leo Glikbarg, Derek Askaryar, Mike Yang, Teddy Zhang, Rishi Alluri, Nathan Tran, Rinnara Sangpisit, Polycarpos Yiorkadjis, Kenny Osele, Gautham ...
-
[39]
Teams of LLM agents can exploit zero-day vulnerabilities.arXiv preprint arXiv:2406.01637, 2024
Yuxuan Zhu, Antony Kellermann, Akul Gupta, Philip Li, Richard Fang, Rohan Bindu, and Daniel Kang. Teams of LLM agents can exploit zero-day vulnerabilities, 2025. URL https: //arxiv.org/abs/2406.01637. 12 A Discussion A.1 What Counts as Identifying a Vulnerability? The most objective validation for some memory-safety patches is a differential input that fa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.