Recognition: unknown
URoPE: Universal Relative Position Embedding across Geometric Spaces
Pith reviewed 2026-05-10 04:13 UTC · model grok-4.3
The pith
URoPE extends rotary position embeddings to cross-view and cross-dimensional geometry by sampling and projecting 3D ray points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
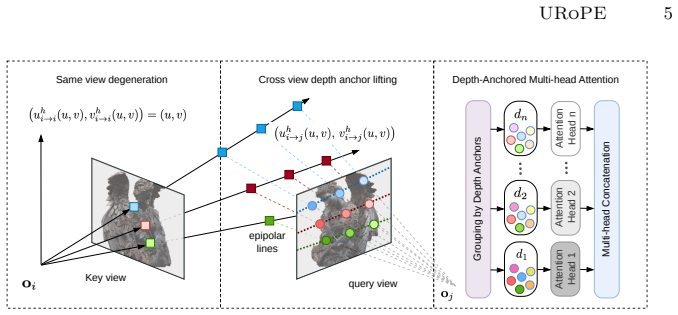
URoPE samples 3D points along the camera ray corresponding to each key or value patch at a small number of predefined depth anchors, projects these points into the query image plane using the query camera's intrinsics, and feeds the resulting 2D pixel coordinates into standard rotary position embedding. This produces a relative positional signal that is invariant to global coordinate choice and fully compatible with existing RoPE-accelerated attention implementations.
What carries the argument
Projection of sampled 3D points from key camera rays onto the query image plane, supplying 2D coordinates for standard RoPE.
If this is right
- Transformers can apply relative positional encoding to attention between patches from different cameras or different dimensional representations without architectural changes.
- Existing fast RoPE kernels remain usable, preserving training and inference speed.
- Performance improves on novel view synthesis, 3D object detection, multi-object tracking, and monocular depth estimation.
- The same embedding works for 2D-2D, 2D-3D, and temporal cross-frame relationships.
Where Pith is reading between the lines
- The ray-sampling idea could extend to other geometric domains, such as spherical or non-Euclidean projections, if analogous sampling and projection rules are defined.
- Multi-camera systems might reduce reliance on explicit extrinsic calibration inside the network once relative geometry is handled at the embedding level.
- Replacing fixed depth anchors with learned or scene-adaptive sampling could further improve results on scenes with widely varying depth ranges.
Load-bearing premise
Sampling points at only a few fixed depth anchors along each ray and projecting them is sufficient to encode the relative geometry needed for cross-view and cross-dimensional reasoning.
What would settle it
Replacing standard RoPE with URoPE in the same transformer models on cross-view tasks and observing no accuracy gain or a clear drop in performance would show the projection step does not supply useful relative information.
Figures





read the original abstract
Relative position embedding has become a standard mechanism for encoding positional information in Transformers. However, existing formulations are typically limited to a fixed geometric space, namely 1D sequences or regular 2D/3D grids, which restricts their applicability to many computer vision tasks that require geometric reasoning across camera views or between 2D and 3D spaces. To address this limitation, we propose URoPE, a universal extension of Rotary Position Embedding (RoPE) to cross-view or cross-dimensional geometric spaces. For each key/value image patch, URoPE samples 3D points along the corresponding camera ray at predefined depth anchors and projects them into the query image plane. Standard 2D RoPE can then be applied using the projected pixel coordinates. URoPE is a parameter-free and intrinsics-aware relative position embedding that is invariant to the choice of global coordinate systems, while remaining fully compatible with existing RoPE-optimized attention kernels. We evaluate URoPE as a plug-in positional encoding for transformer architectures across a diverse set of tasks, including novel view synthesis, 3D object detection, object tracking, and depth estimation, covering 2D-2D, 2D-3D, and temporal scenarios. Experiments show that URoPE consistently improves the performance of transformer-based models across all tasks, demonstrating its effectiveness and generality for geometric reasoning. Our project website is: https://urope-pe.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes URoPE, a universal extension of Rotary Position Embedding (RoPE) to cross-view and cross-dimensional geometric spaces. For each key/value patch, it samples 3D points along the camera ray at a small number of predefined depth anchors, projects them into the query image plane using camera intrinsics, and applies standard 2D RoPE to the resulting 2D coordinates. The method is presented as parameter-free, intrinsics-aware, invariant to global coordinate choice, and directly compatible with existing RoPE-optimized attention kernels. Experiments across novel view synthesis, 3D object detection, object tracking, and depth estimation (covering 2D-2D, 2D-3D, and temporal settings) report consistent performance gains when URoPE is used as a plug-in positional encoding in transformer models.
Significance. If the central construction holds, URoPE would provide a practical, parameter-free mechanism for injecting relative geometric information into attention without kernel modifications or learned parameters, extending RoPE beyond fixed 1D/2D/3D grids. This could improve geometric reasoning in multi-view and 3D CV tasks. The derivation from standard camera projection and existing RoPE is a strength, as is the explicit invariance and kernel compatibility.
major comments (2)
- [Method section (URoPE construction)] Method section (URoPE construction): the central step samples a small number of 3D points at fixed, non-adaptive depth anchors along each key ray and projects them into the query plane before applying 2D RoPE. This discrete approximation is load-bearing for the universality claim; it is unclear whether the projected coordinates remain faithful proxies for relative 3D displacement when scene depths lie between or outside the anchors or when parallax is large, as the skeptic note highlights.
- [Experiments section] Experiments section: while consistent improvements are claimed across four tasks, the provided text supplies no quantitative tables, ablation results on anchor count or placement, baseline details, or error analysis conditioned on depth or baseline variation. This leaves the empirical support for the geometric-sufficiency assumption only partially verifiable.
minor comments (3)
- [Abstract and method] Abstract and method: the number and selection criterion for the 'predefined depth anchors' are not stated, which affects reproducibility and should be specified (e.g., uniform in disparity or log-depth).
- [Notation] Notation: the exact projection equation mapping the sampled 3D points to query-plane pixel coordinates should be written explicitly, including the role of intrinsics matrices.
- [Figures] Figures: any diagram illustrating the ray sampling and projection step would benefit from explicit depth-anchor labels and an example of a large-baseline case.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of URoPE's core construction and its potential utility. We address each major comment below with clarifications and commit to targeted revisions that strengthen the manuscript without altering the method.
read point-by-point responses
-
Referee: [Method section (URoPE construction)] Method section (URoPE construction): the central step samples a small number of 3D points at fixed, non-adaptive depth anchors along each key ray and projects them into the query plane before applying 2D RoPE. This discrete approximation is load-bearing for the universality claim; it is unclear whether the projected coordinates remain faithful proxies for relative 3D displacement when scene depths lie between or outside the anchors or when parallax is large, as the skeptic note highlights.
Authors: The discrete sampling is indeed an approximation, but it is designed to produce view-dependent 2D relative coordinates in the query plane rather than to reconstruct exact 3D displacements. Because the subsequent 2D RoPE operates directly on these projected pixel locations, the attention mechanism receives a geometrically consistent relative signal that is invariant to global coordinate choice and depends only on camera intrinsics and the relative pose between views. Logarithmically spaced anchors (typically 4–8) are chosen to span the depth range of each dataset; intermediate depths produce interpolated projections that remain useful for attention. Large parallax is handled naturally because the projection is performed per query-key pair. We will expand the method section with a formal justification of the approximation, explicit anchor-selection guidelines, and a short derivation showing that the projected coordinates encode the essential relative geometry for cross-view attention. We will also add a sensitivity analysis on anchor count and spacing. revision: partial
-
Referee: [Experiments section] Experiments section: while consistent improvements are claimed across four tasks, the provided text supplies no quantitative tables, ablation results on anchor count or placement, baseline details, or error analysis conditioned on depth or baseline variation. This leaves the empirical support for the geometric-sufficiency assumption only partially verifiable.
Authors: The reviewed manuscript version omitted the full result tables and ablations that appear in the complete draft. We will insert comprehensive quantitative tables reporting absolute metrics (PSNR/SSIM for NVS, mAP for detection, MOTA for tracking, RMSE for depth) together with relative gains over standard RoPE, learned positional embeddings, and task-specific baselines. New ablations will quantify the effect of anchor count (4, 8, 16) and placement (linear vs. log-spaced) across all four tasks. We will also add error-analysis figures and tables stratified by depth bins and baseline distance to directly address the geometric-sufficiency assumption. These additions will make the empirical claims fully verifiable. revision: yes
Circularity Check
No significant circularity; URoPE is a direct geometric construction from standard RoPE and camera projection
full rationale
The paper defines URoPE explicitly as sampling a fixed set of 3D points at predefined depth anchors along each key ray, projecting those points into the query image plane via standard camera intrinsics, and then feeding the resulting 2D coordinates into unmodified 2D RoPE. This construction is parameter-free, follows directly from projective geometry and the existing RoPE equations, and contains no fitted parameters, self-referential equations, or predictions that reduce to prior fits. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked for the core claim. Experimental gains are reported as independent empirical outcomes rather than tautological consequences of the definition. The discrete-anchor choice is an explicit modeling decision whose sufficiency is tested externally, not assumed by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Known camera intrinsics allow accurate projection of 3D points to 2D image planes
- standard math Rotary Position Embedding can be directly applied to the projected 2D coordinates
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621–11631 (2020) 3, 9, 21
2020
-
[2]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020) 1, 3
2020
-
[3]
In: Pro- ceedingsofthe57thannualmeetingoftheassociationforcomputationallinguistics
Dai, Z., Yang, Z., Yang, Y., Carbonell, J.G., Le, Q., Salakhutdinov, R.: Transformer-xl: Attentive language models beyond a fixed-length context. In: Pro- ceedingsofthe57thannualmeetingoftheassociationforcomputationallinguistics. pp. 2978–2988 (2019) 2
2019
-
[4]
In: Advances in Neural Information Processing Systems (NeurIPS) (2022) 3, 4
Dao,T.,Fu,D.Y.,Ermon,S.,Rudra,A.,Ré,C.:FlashAttention:Fastandmemory- efficient exact attention with IO-awareness. In: Advances in Neural Information Processing Systems (NeurIPS) (2022) 3, 4
2022
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023) 3, 8, 21
2023
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020) 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Du, Y., Smith, C., Tewari, A., Sitzmann, V.: Learning to render novel views from wide-baseline stereo pairs. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 4970–4980 (2023) 4
2023
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 21 16 Y. Xie et al
2016
-
[10]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
He, Y., Yan, R., Fragkiadaki, K., Yu, S.I.: Epipolar transformers. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 7779–7788 (2020) 4
2020
-
[11]
Heo, B., Park, S., Han, D., Yun, S.: Rotary position embedding for vision trans- former.In:EuropeanConferenceonComputerVision.pp.289–305.Springer(2024) 3, 21
2024
-
[12]
Lrm: Large reconstruction model for single image to 3d,
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023) 4
-
[13]
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: Lvsm: A large view synthesis model with minimal 3d inductive bias. arXiv preprint arXiv:2410.17242 (2024) 1, 4, 5, 8, 9, 11, 13, 14, 19
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, J., Wang, P., Xiong, P., Cai, T., Yan, Z., Yang, L., Liu, J., Fan, H., Liu, S.: Practical stereo matching via cascaded recurrent network with adaptive correla- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16263–16272 (2022) 1
2022
-
[15]
arXiv preprint arXiv:2507.10496 (2025) 2, 4, 8, 9, 11, 13, 19, 21
Li, R., Yi, B., Liu, J., Gao, H., Ma, Y., Kanazawa, A.: Cameras as relative po- sitional encoding. arXiv preprint arXiv:2507.10496 (2025) 2, 4, 8, 9, 11, 13, 19, 21
-
[16]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(3), 2020–2036 (2024) 4
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J.: Bevformer: learningbird’s-eye-viewrepresentationfromlidar-cameraviaspatiotemporaltrans- formers. IEEE Transactions on Pattern Analysis and Machine Intelligence47(3), 2020–2036 (2024) 4
2020
-
[17]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025) 21
work page internal anchor Pith review arXiv 2025
-
[18]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 9298–9309 (2023) 21
2023
-
[19]
In: European conference on computer vision
Liu, Y., Wang, T., Zhang, X., Sun, J.: Petr: Position embedding transformation for multi-view 3d object detection. In: European conference on computer vision. pp. 531–548. Springer (2022) 1, 4, 9, 10, 21
2022
-
[20]
In: Proceedings of the IEEE/CVF in- ternational conference on computer vision
Meng, D., Chen, X., Fan, Z., Zeng, G., Li, H., Yuan, Y., Sun, L., Wang, J.: Con- ditional detr for fast training convergence. In: Proceedings of the IEEE/CVF in- ternational conference on computer vision. pp. 3651–3660 (2021) 1
2021
-
[21]
arXiv preprint arXiv:2310.10375 (2023) 2, 4
Miyato, T., Jaeger, B., Welling, M., Geiger, A.: Gta: A geometry-aware attention mechanism for multi-view transformers. arXiv preprint arXiv:2310.10375 (2023) 2, 4
-
[22]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Press, O., Smith, N.A., Lewis, M.: Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409 (2021) 2
work page internal anchor Pith review arXiv 2021
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Sajjadi, M.S., Meyer, H., Pot, E., Bergmann, U., Greff, K., Radwan, N., Vora, S., Lučić, M., Duckworth, D., Dosovitskiy, A., et al.: Scene representation transformer: Geometry-free novel view synthesis through set-latent scene representations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 6229–6238 (2022) 1
2022
-
[24]
In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers)
Shaw, P., Uszkoreit, J., Vaswani, A.: Self-attention with relative position represen- tations. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). pp. 464–468 (2018) 2 URoPE17
2018
-
[25]
Advances in Neural Information Processing Systems34, 19313–19325 (2021) 2, 4
Sitzmann, V., Rezchikov, S., Freeman, B., Tenenbaum, J., Durand, F.: Light field networks: Neural scene representations with single-evaluation rendering. Advances in Neural Information Processing Systems34, 19313–19325 (2021) 2, 4
2021
-
[26]
In: 2012 IEEE/RSJ international conference on intelligent robots and systems
Sturm, J., Engelhard, N., Endres, F., Burgard, W., Cremers, D.: A benchmark for the evaluation of rgb-d slam systems. In: 2012 IEEE/RSJ international conference on intelligent robots and systems. pp. 573–580. IEEE (2012) 3, 10, 11
2012
-
[27]
Neurocomputing568, 127063 (2024) 2, 3, 7
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024) 2, 3, 7
2024
-
[28]
In: DAGM German Conference on Pattern Recognition
Tang, Y., Dorn, S., Savani, C.: Center3d: Center-based monocular 3d object detec- tion with joint depth understanding. In: DAGM German Conference on Pattern Recognition. pp. 289–302. Springer (2020) 14
2020
-
[29]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ummenhofer, B., Zhou, H., Uhrig, J., Mayer, N., Ilg, E., Dosovitskiy, A., Brox, T.: Demon: Depth and motion network for learning monocular stereo. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5038–5047 (2017) 3, 10, 11
2017
-
[31]
Advances in neural information pro- cessing systems30(2017) 1, 2, 3
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017) 1, 2, 3
2017
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) 21
2025
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, S., Liu, Y., Wang, T., Li, Y., Zhang, X.: Exploring object-centric tempo- ral modeling for efficient multi-view 3d object detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3621–3631 (2023) 1, 4, 9, 10, 21
2023
-
[35]
In: Conference on robot learning
Wang, Y., Guizilini, V.C., Zhang, T., Wang, Y., Zhao, H., Solomon, J.: Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In: Conference on robot learning. pp. 180–191. PMLR (2022) 4
2022
-
[36]
arXiv preprint arXiv:2601.15275 (2026) 4, 8, 9, 21
Wu, Y., Jeon, M., Chang, J.H.R., Tuzel, O., Tulsiani, S.: Rayrope: Projective ray positional encoding for multi-view attention. arXiv preprint arXiv:2601.15275 (2026) 4, 8, 9, 21
-
[37]
In: Proceedings of the IEEE international conference on computer vision
Xiao, J., Owens, A., Torralba, A.: Sun3d: A database of big spaces reconstructed using sfm and object labels. In: Proceedings of the IEEE international conference on computer vision. pp. 1625–1632 (2013) 3, 10, 11
2013
-
[38]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2026) 2, 4, 5
Xie, Y., Peng, C., Abdelfattah, M., Hu, Y., Yang, J., Higgins, E., Brigden, R., Tomizuka, M., Zhan, W.: Raynova: Scale-temporal autoregressive world modeling in ray space. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2026) 2, 4, 5
2026
-
[39]
arXiv preprint arXiv:2411.01123 (2024) 4
Xie, Y., Xu, C., Peng, C., Zhao, S., Ho, N., Pham, A.T., Ding, M., Tomizuka, M., Zhan, W.: X-drive: Cross-modality consistent multi-sensor data synthesis for driving scenarios. arXiv preprint arXiv:2411.01123 (2024) 4
-
[40]
Xie et al
Xie, Y., Xu, C., Rakotosaona, M.J., Rim, P., Tombari, F., Keutzer, K., Tomizuka, M., Zhan, W.: Sparsefusion: Fusing multi-modal sparse representations for multi- 18 Y. Xie et al. sensor 3d object detection. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 17591–17602 (2023) 4
2023
-
[41]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2023) 1, 4, 10, 11, 21
Xu, H., Zhang, J., Cai, J., Rezatofighi, H., Yu, F., Tao, D., Geiger, A.: Unifying flow, stereo and depth estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2023) 1, 4, 10, 11, 21
2023
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yin, T., Zhou, X., Krahenbuhl, P.: Center-based 3d object detection and track- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11784–11793 (2021) 9
2021
-
[43]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ingviewsynthesisusingmultiplaneimages.arXivpreprintarXiv:1805.09817(2018) 3, 8, 13, 21
work page internal anchor Pith review arXiv 2018
-
[44]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020) 4 URoPE19 In this appendix, we exhibit additional experiment results in Sec. A. After- wards, the implementation details of our experiments are explained in Sec. B. Finally, we discuss some li...
work page internal anchor Pith review arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.