Recognition: unknown
Choose Your Own Adventure: Non-Linear AI-Assisted Programming with EvoGraph
Pith reviewed 2026-05-10 03:17 UTC · model grok-4.3
The pith
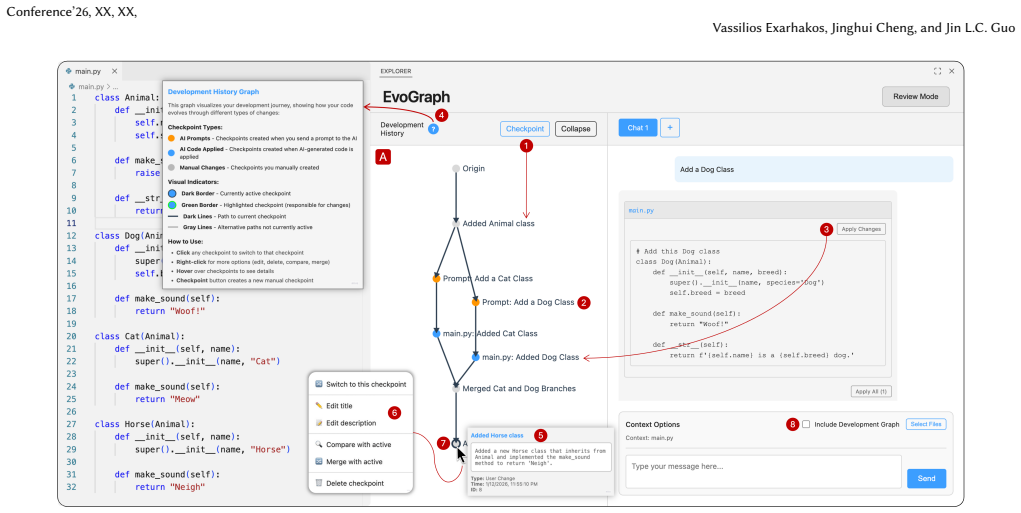
EvoGraph replaces linear chat interfaces with an interactive branching graph that records AI coding steps and lets developers compare, merge, and revisit states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvoGraph records AI-assisted programming sessions as a branching, manipulable development graph that automatically captures prompting sequences and code changes, enabling direct comparison, merging, and revisiting of prior states; a controlled user study showed this approach resolved the exploration, sequencing, and tracing difficulties reported in an earlier developer study while reducing cognitive load.
What carries the argument
The lightweight interactive development graph that automatically records and exposes branching AI prompt histories and code states for direct manipulation.
If this is right
- Developers gain the ability to compare multiple AI-generated solutions side-by-side without manual copy-paste or context loss.
- Merging code from separate exploration branches becomes a direct graph operation rather than a manual reconciliation task.
- Reverting to an earlier collaborative state requires only selecting a prior node instead of re-prompting or searching chat history.
- Reflection on AI contributions is aided by the visible structure of the entire session rather than a flat transcript.
Where Pith is reading between the lines
- The same graph structure could be applied to non-AI programming sessions to visualize refactoring or debugging histories.
- Integration with Git-style version control might let branches in the development graph correspond to actual commits or pull requests.
- Designers of future AI coding assistants may need to expose process history rather than only final code outputs.
Load-bearing premise
That challenges observed in the preliminary developer interviews are representative of everyday professional work and that benefits measured in a controlled lab study with 20 participants will appear in real, ongoing use.
What would settle it
A field deployment in which developers using EvoGraph explore no more alternatives, report equal or higher cognitive load, or spend more time tracing changes than when using a standard linear chat-based AI assistant.
Figures



read the original abstract
Current AI-assisted programming tools are predominantly linear and chat-based, which deviates from the iterative and branching nature of programming itself. Our preliminary study with developers using AI assistants suggested that they often struggle to explore alternatives, manage prompting sequences, and trace changes. Informed by these insights, we created EvoGraph, an IDE plugin that integrates AI interactions and code changes as a lightweight and interactive development graph. EvoGraph automatically records a branching AI-assisted coding history and allows developers to manipulate the graph to compare, merge, and revisit prior collaborative AI programming states. Our user study with 20 participants revealed that EvoGraph addressed developers' challenges identified in our preliminary study while imposing lower cognitive load. Participants also found the graph-based representation supported safe exploration, efficient iteration, and reflection on AI-generated changes. Our work highlights design opportunities for tools to help developers make sense of and act on their problem-solving progress in the emerging AI-mediated programming context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvoGraph, an IDE plugin that represents AI-assisted programming sessions as an interactive branching graph to address limitations of linear chat-based tools. Drawing from a preliminary study with developers that identified challenges in exploring alternatives, managing prompt sequences, and tracing changes, the system automatically records AI interactions and code states, enabling users to compare, merge, and revisit branches. A user study with 20 participants found that EvoGraph addressed the preliminary challenges, imposed lower cognitive load, and supported safe exploration, efficient iteration, and reflection on AI-generated changes.
Significance. If the user-study results hold under stronger controls, the work offers a concrete design contribution to HCI and software engineering by showing how graph-based history management can mitigate cognitive burdens in non-linear AI collaboration. It provides empirical grounding for moving beyond linear interfaces and identifies actionable opportunities for tools that help developers reflect on and act upon their problem-solving trajectories.
major comments (3)
- [§6] §6 (User Study): The evaluation provides no information on experimental design (within- vs. between-subjects), task descriptions, control condition (standard chat-based AI), measurement instruments for cognitive load, or statistical tests. Without these details the central claim that EvoGraph 'addressed developers' challenges ... while imposing lower cognitive load' cannot be evaluated.
- [§6.2] §6.2 (Results): No baseline comparison, objective behavioral metrics (task time, edit counts, error rates), or pre/post measures are reported; attribution of benefits to the graph representation rather than novelty or demand characteristics therefore remains untested.
- [§4] §4 (Preliminary Study): The challenges used to motivate EvoGraph are presented as given without evidence that they generalize beyond the sampled participants or were validated against typical professional workflows.
minor comments (3)
- [Abstract] The abstract is overly dense and repeats the same high-level claims; a single sentence on study limitations would improve clarity.
- [Figures] Figure captions for the EvoGraph interface screenshots could more explicitly label the branching and merge operations shown.
- [Related Work] Related-work section omits recent papers on version-control visualizations and branching in AI coding assistants.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to improve the paper.
read point-by-point responses
-
Referee: [§6] §6 (User Study): The evaluation provides no information on experimental design (within- vs. between-subjects), task descriptions, control condition (standard chat-based AI), measurement instruments for cognitive load, or statistical tests. Without these details the central claim that EvoGraph 'addressed developers' challenges ... while imposing lower cognitive load' cannot be evaluated.
Authors: We agree that the manuscript would benefit from more detailed reporting of the user study methodology. In the revised version, we will expand Section 6 to include a complete description of the experimental design, detailed task descriptions, the control condition using standard chat-based AI tools, the specific instruments used to measure cognitive load, and the statistical tests employed. This will enable readers to fully assess the validity of our claims. revision: yes
-
Referee: [§6.2] §6.2 (Results): No baseline comparison, objective behavioral metrics (task time, edit counts, error rates), or pre/post measures are reported; attribution of benefits to the graph representation rather than novelty or demand characteristics therefore remains untested.
Authors: We acknowledge the importance of objective metrics and clear baseline comparisons for strengthening causal claims. Our study primarily relied on subjective feedback to evaluate the system's impact. In the revision, we will add a limitations subsection to address the absence of objective behavioral metrics and discuss potential influences such as novelty effects. We will clarify the exploratory nature of the evaluation while maintaining that the insights support the design contribution. revision: partial
-
Referee: [§4] §4 (Preliminary Study): The challenges used to motivate EvoGraph are presented as given without evidence that they generalize beyond the sampled participants or were validated against typical professional workflows.
Authors: The preliminary study was exploratory and intended to inform the design rather than establish generalizable results. We will revise Section 4 to provide more details on the participant sample and methodology, and explicitly state its formative purpose along with limitations in generalizability to professional workflows. revision: yes
Circularity Check
No circularity; empirical claims rest on independent user-study data
full rationale
The paper describes a preliminary study (by the same authors) that identifies developer challenges, uses those insights to motivate the design of EvoGraph, and then reports results from a separate user study (n=20) to evaluate whether the tool addresses the challenges and reduces cognitive load. No mathematical derivations, equations, fitted parameters, or first-principles predictions exist. The evaluation data are collected independently via participant feedback and are not constructed from the preliminary-study inputs. Self-reference to the preliminary study serves only as design motivation, not as load-bearing justification for the evaluation claims. This is standard HCI workflow with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Developers struggle to explore alternatives, manage prompting sequences, and trace changes when using linear AI assistants
invented entities (1)
-
EvoGraph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude Code
2025. Claude Code. https://claude.com/product/claude-code. Accessed: 2025-12- 10
2025
-
[2]
2025. Cursor. https://cursor.com/home. Accessed: 2025-12-10
2025
-
[3]
GitHub Copilot
2025. GitHub Copilot. https://github.com/features/copilot. Accessed: 2025-12-10
2025
-
[4]
Adam Alami, Victor Jensen, and Neil Ernst. 2025. Accountability in Code Review: The Role of Intrinsic Drivers and the Impact of LLMs.ACM Trans. Softw. Eng. Methodol.34, 8, Article 233 (Oct. 2025), 44 pages. doi:10.1145/3721127
-
[5]
Tyler Angert, Miroslav Suzara, Jenny Han, Christopher Pondoc, and Hariharan Subramonyam. 2023. Spellburst: A Node-based Interface for Exploratory Creative Coding with Natural Language Prompts. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA) (UIST ’23). Association for Computing Machinery, Ne...
-
[6]
Ian Arawjo, Chelse Swoopes, Priyan Vaithilingam, Martin Wattenberg, and Elena L. Glassman. 2024. ChainForge: A Visual Toolkit for Prompt Engineer- ing and LLM Hypothesis Testing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Asso- ciation for Computing Machinery, New York, NY, USA, Article 304,...
-
[7]
Grounded Copilot: How Programmers Interact with Code-Generating Models
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded Copilot: How Programmers Interact with Code-Generating Models.Proc. ACM Program. Lang.7, OOPSLA1, Article 78 (April 2023), 27 pages. doi:10.1145/3586030
-
[8]
2011.Thematic Analysis: A Practical Guide
Virginia Braun and Victoria Clarke. 2011.Thematic Analysis: A Practical Guide. SAGE
2011
-
[9]
Treasury Board
Canada. Treasury Board. 2021. Directive on Automated Decision-Making. Gov- ernment of Canada. https://www.tbs-sct.canada.ca/pol/doc-eng.aspx?id=32592 Accessed: 2024-03-29
2021
-
[10]
Valerie Chen, Alan Zhu, Sebastian Zhao, Hussein Mozannar, David Sontag, and Ameet Talwalkar. 2025. Need Help? Designing Proactive AI Assistants for Pro- gramming. InProceedings of the 2025 CHI Conference on Human Factors in Com- puting Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 881, 18 pages. doi:10.1145/3706598.3714002
- [11]
-
[12]
Herbert H. Clark and Susan E. Brennan. 1991. Grounding in communication. 127-149 pages. doi:10.1037/10096-006
-
[13]
Adam J Coscia, Shunan Guo, Eunyee Koh, and Alex Endert. 2025. OnGoal: Tracking and Visualizing Conversational Goals in Multi-Turn Dialogue with Large Language Models. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 208, 18 pages. doi:10.114...
-
[14]
European Parliament and the Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). Official Journal of the European Union, L 2024/1689. http://data.europa.eu/ eli/reg/2024/1689/oj Accessed: 2026-03-29
2024
-
[15]
Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, and Shu- vendu K. Lahiri. 2024. LLM-Based Test-Driven Interactive Code Generation: User Study and Empirical Evaluation.IEEE Trans. Softw. Eng.50, 9 (Sept. 2024), 2254–2268. doi:10.1109/TSE.2024.3428972
-
[16]
Brubaker, Sarah E Fox, and Haiyi Zhu
Kasra Ferdowsi, Ruanqianqian (Lisa) Huang, Michael B. James, Nadia Polikarpova, and Sorin Lerner. 2024. Validating AI-Generated Code with Live Programming. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 143, 8 pages. doi:10.1145/36...
-
[17]
Thomas Fritz, Gail C. Murphy, and Emily Hill. 2007. Does a programmer’s activity indicate knowledge of code?. InProceedings of the the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering(Dubrovnik, Croatia)(ESEC-FSE ’07). Association for Computing Machinery, New York, N...
-
[18]
Jin Guo, Jinghui Cheng, and Jane Cleland-Huang. 2017. Semantically enhanced software traceability using deep learning techniques. InProceedings of the 39th In- ternational Conference on Software Engineering, ICSE 2017, Buenos Aires, Argentina, May 20-28, 2017. IEEE / ACM, 3–14. doi:10.1109/ICSE.2017.9
-
[19]
Jin LC Guo, Jan-Philipp Steghöfer, Andreas Vogelsang, and Jane Cleland-Huang
-
[20]
InHandbook on Natural Language Processing for Requirements Engineering
Natural language processing for requirements traceability. InHandbook on Natural Language Processing for Requirements Engineering. Springer, 89–116
- [21]
-
[22]
Drucker, and Robert DeLine
Andrew Head, Fred Hohman, Titus Barik, Steven M. Drucker, and Robert DeLine
-
[23]
Understanding the effect of accuracy on trust in machine learning models
Managing Messes in Computational Notebooks. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI ’19). Association for Computing Machinery, New York, NY, USA, 1–12. doi:10.1145/3290605.3300500
-
[24]
Austin Z. Henley, Scott D. Fleming, and Maria V. Luong. 2017. Toward Princi- ples for the Design of Navigation Affordances in Code Editors: An Empirical Investigation. InProceedings of the 2017 CHI Conference on Human Factors in Com- puting Systems(Denver, Colorado, USA)(CHI ’17). Association for Computing Machinery, New York, NY, USA, 5690–5702. doi:10.1...
-
[25]
Amber Horvath, Andrew Macvean, and Brad A Myers. 2024. Meta-Manager: A Tool for Collecting and Exploring Meta Information about Code. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 929, 17 pages. doi:10.1145/3613904.3642676
-
[26]
Olga Iarygina, Kasper Hornbæk, and Aske Mottelson. 2025. Demand character- istics in human–computer experiments.Int. J. Hum.-Comput. Stud.193, C (Jan. 2025), 14 pages. doi:10.1016/j.ijhcs.2024.103379
-
[27]
Shuyao Jiang. 2019. Boosting Neural Commit Message Generation with Code Semantic Analysis. In34th IEEE/ACM International Conference on Automated Software Engineering, ASE 2019, San Diego, CA, USA, November 11-15, 2019. IEEE, 1280–1282. doi:10.1109/ASE.2019.00162
-
[28]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310.06770
work page internal anchor Pith review arXiv 2024
-
[29]
Thorsten Karrer, Jan-Peter Krämer, Jonathan Diehl, Björn Hartmann, and Jan Borchers. 2011. Stacksplorer: call graph navigation helps increasing code maintenance efficiency. InProceedings of the 24th Annual ACM Symposium on User Interface Software and Technology(Santa Barbara, California, USA) (UIST ’11). Association for Computing Machinery, New York, NY, ...
-
[30]
Mary Beth Kery, Amber Horvath, and Brad Myers. 2017. Variolite: Supporting Exploratory Programming by Data Scientists. InProceedings of the 2017 CHI Conference on Human Factors in Computing Systems(Denver, Colorado, USA) (CHI ’17). Association for Computing Machinery, New York, NY, USA, 1265–1276. doi:10.1145/3025453.3025626
-
[31]
Mary Beth Kery, Marissa Radensky, Mahima Arya, Bonnie E. John, and Brad A. Myers. 2018. The Story in the Notebook: Exploratory Data Science using a Literate Programming Tool. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems(Montreal QC, Canada)(CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–11. doi:10.114...
-
[32]
Ranim Khojah, Mazen Mohamad, Philipp Leitner, and Francisco Gomes de Oliveira Neto. 2024. Beyond Code Generation: An Observational Study of Chat- GPT Usage in Software Engineering Practice.Proc. ACM Softw. Eng.1, FSE, Article 81 (July 2024), 22 pages. doi:10.1145/3660788
-
[33]
Alexandra Kuznetsova, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest Package: Tests in Linear Mixed Effects Models.Journal of Statistical Software82, 13 (2017), 1–26. doi:10.18637/jss.v082.i13
-
[34]
Liang, Chenyang Yang, and Brad A
Jenny T. Liang, Chenyang Yang, and Brad A. Myers. 2024. A Large-Scale Survey on the Usability of AI Programming Assistants: Successes and Challenges. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 52, 13 pages. doi:10.1145/35...
-
[35]
Yanna Lin, Leni Yang, Haotian Li, Huamin Qu, and Dominik Moritz. 2025. In- terLink: Linking Text with Code and Output in Computational Notebooks. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 51, 15 pages. doi:10.1145/3706598.3714104
- [36]
-
[37]
You’re on a bicycle with a little motor
Wendy Mendes, Samara Souza, and Cleidson De Souza. 2024. "You’re on a bicycle with a little motor": Benefits and Challenges of Using AI Code As- sistants. InProceedings of the 2024 IEEE/ACM 17th International Conference on Cooperative and Human Aspects of Software Engineering(Lisbon, Portugal) (CHASE ’24). Association for Computing Machinery, New York, NY...
-
[38]
Hiroaki Mikami, Daisuke Sakamoto, and Takeo Igarashi. 2017. Micro-Versioning Tool to Support Experimentation in Exploratory Programming. InProceedings of the 2017 CHI Conference on Human Factors in Computing Systems(Denver, Colorado, USA)(CHI ’17). Association for Computing Machinery, New York, NY, USA, 6208–6219. doi:10.1145/3025453.3025597
-
[39]
Montgomery
Douglas C. Montgomery. 2006.Design and Analysis of Experiments. John Wiley & Sons, Inc., Hoboken, NJ, USA
2006
-
[40]
Hellendoorn, Bogdan Vasilescu, and Brad A
Daye Nam, Andrew Macvean, Vincent J. Hellendoorn, Bogdan Vasilescu, and Brad A. Myers. 2024. Using an LLM to Help With Code Understanding. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024. ACM, 97:1–97:13. doi:10.1145/ 3597503.3639187
-
[41]
Gary M. Olson and Judith S. Olson. 2000. Distance Matters.Human–Computer Interaction15, 2-3 (2000), 139–178. doi:10.1207/S15327051HCI1523_4
-
[42]
2025.Developers Remain Willing, but Reluctant, to Use AI: The 2025 Developer Survey Results Are Here
Stack Overflow. 2025.Developers Remain Willing, but Reluctant, to Use AI: The 2025 Developer Survey Results Are Here. Stack Overflow Blog. https://stackoverflow.blog/2025/12/29/developers-remain-willing-but- reluctant-to-use-ai-the-2025-developer-survey-results-are-here/
2025
-
[43]
Norman Peitek, Annabelle Bergum, Maurice Rekrut, Jonas Mucke, Matthias Nadig, Chris Parnin, Janet Siegmund, and Sven Apel. 2022. Correlates of pro- grammer efficacy and their link to experience: a combined EEG and eye-tracking study. InProceedings of the 30th ACM Joint European Software Engineering Con- ference and Symposium on the Foundations of Software...
-
[44]
It’s Weird That it Knows What I Want
James Prather, Brent N. Reeves, Paul Denny, Brett A. Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. “It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers.ACM Trans. Comput.-Hum. Interact.31, 1, Article 4 (Nov. 2023), 31 pages. doi:10.1145/3617367
-
[45]
and Kimmel, Bailey and Wright, Jared and Briggs, Ben , title =
James Prather, Brent N Reeves, Juho Leinonen, Stephen MacNeil, Arisoa S Randri- anasolo, Brett A. Becker, Bailey Kimmel, Jared Wright, and Ben Briggs. 2024. The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers. InProceedings of the 2024 ACM Conference on International Computing Education Research - Volume 1(Melbourne, VIC, Aust...
-
[46]
Kevin Pu, Daniel Lazaro, Ian Arawjo, Haijun Xia, Ziang Xiao, Tovi Grossman, and Yan Chen. 2025. Assistance or Disruption? Exploring and Evaluating the Design and Trade-offs of Proactive AI Programming Support. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, A...
-
[47]
Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D
Steven I. Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D. Weisz. 2023. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. InProceedings of the 28th International Conference on Intelligent User Interfaces(Sydney, NSW, Australia) (IUI ’23). Association for Computing Machinery,...
- [48]
-
[49]
Vera Liao, Michael Muller, Mayank Agarwal, Stephanie Houde, Kartik Talamadupula, and Justin D
Jiao Sun, Q. Vera Liao, Michael Muller, Mayank Agarwal, Stephanie Houde, Kartik Talamadupula, and Justin D. Weisz. 2022. Investigating Explainability of Generative AI for Code through Scenario-based Design. InProceedings of the 27th International Conference on Intelligent User Interfaces(Helsinki, Finland) (IUI ’22). Association for Computing Machinery, N...
-
[50]
Ningzhi Tang, Meng Chen, Zheng Ning, Aakash Bansal, Yu Huang, Collin McMil- lan, and Toby Jia-Jun Li. 2024. A Study on Developer Behaviors for Validat- ing and Repairing LLM-Generated Code Using Eye Tracking and IDE Actions. arXiv:2405.16081 [cs.SE] https://arxiv.org/abs/2405.16081
-
[51]
Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models
Priyan Vaithilingam, Tianyi Zhang, and Elena L. Glassman. 2022. Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models. InExtended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI EA ’22). Association for Computing Machinery, New York, NY, USA, Arti...
-
[52]
Vera Liao, and Jen- nifer Wortman Vaughan
Helena Vasconcelos, Gagan Bansal, Adam Fourney, Q. Vera Liao, and Jennifer Wortman Vaughan. 2025. Generation Probabilities Are Not Enough: Uncertainty Highlighting in AI Code Completions.ACM Trans. Comput.-Hum. Interact.32, 1, Article 4 (April 2025), 30 pages. doi:10.1145/3702320
-
[53]
Ruotong Wang, Ruijia Cheng, Denae Ford, and Thomas Zimmermann. 2024. Investigating and Designing for Trust in AI-powered Code Generation Tools. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Trans- parency(Rio de Janeiro, Brazil)(FAccT ’24). Association for Computing Machinery, New York, NY, USA, 1475–1493. doi:10.1145/3630106.3658984
-
[54]
Miku Watanabe, Hao Li, Yutaro Kashiwa, Brittany Reid, Hajimu Iida, and Ahmed E. Hassan. 2026. On the Use of Agentic Coding: An Empirical Study of Pull Requests on GitHub.ACM Trans. Softw. Eng. Methodol.(March 2026). doi:10.1145/3798166 Just Accepted
-
[55]
Justin D. Weisz, Shraddha Vijay Kumar, Michael Muller, Karen-Ellen Browne, Arielle Goldberg, Katrin Ellice Heintze, and Shagun Bajpai. 2025. Examining the Use and Impact of an AI Code Assistant on Developer Productivity and Experience in the Enterprise. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CH...
-
[56]
Weisz, Michael Muller, Stephanie Houde, John Richards, Steven I
Justin D. Weisz, Michael Muller, Stephanie Houde, John Richards, Steven I. Ross, Fernando Martinez, Mayank Agarwal, and Kartik Talamadupula. 2021. Perfection Not Required? Human-AI Partnerships in Code Translation. InProceedings of the 26th International Conference on Intelligent User Interfaces(College Station, TX, USA)(IUI ’21). Association for Computin...
-
[57]
Litao Yan, Alyssa Hwang, Zhiyuan Wu, and Andrew Head. 2024. Ivie: Lightweight Anchored Explanations of Just-Generated Code. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 140, 15 pages. doi:10.1145/3613904.3642239
-
[58]
Litao Yan, Jeffrey Tao, Lydia B Chilton, and Andrew Head. 2025. Answering Developer Questions with Annotated Agent-Discovered Program Traces. In Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 29, 14 pages. doi:10.1145/3746059.3747652
-
[59]
Ryan Yen, Jiawen Stefanie Zhu, Sangho Suh, Haijun Xia, and Jian Zhao. 2024. CoLadder: Manipulating Code Generation via Multi-Level Blocks. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (Pittsburgh, PA, USA)(UIST ’24). Association for Computing Machinery, New York, NY, USA, Article 11, 20 pages. doi:10.1145/365477...
-
[60]
Zamfirescu-Pereira, Eunice Jun, Michael Terry, Qian Yang, and Bjoern Hartmann
J.D. Zamfirescu-Pereira, Eunice Jun, Michael Terry, Qian Yang, and Bjoern Hart- mann. 2025. Beyond Code Generation: LLM-supported Exploration of the Pro- gram Design Space. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). ACM, 1–17. doi:10.1145/3706598.3714154
-
[61]
Shurui Zhou, Bogdan Vasilescu, and Christian Kästner. 2020. How Has Forking Changed in the Last 20 Years?: A Study of Hard Forks on Github. InICSE ’20: 42nd International Conference on Software Engineering, Companion Volume, Seoul, South Korea, 27 June - 19 July, 2020. ACM, 268–269. doi:10.1145/3377812.3390911 Choose Your Own Adventure: Non-Linear AI-Assi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.