Recognition: unknown
Explore Like Humans: Autonomous Exploration with Online SG-Memo Construction for Embodied Agents
Pith reviewed 2026-05-10 03:17 UTC · model grok-4.3
The pith
ABot-Explorer unifies exploration and memory building by using vision-language models to extract semantic navigational affordances from RGB images and organize them into an online hierarchical SG-Memo.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ABot-Explorer performs simultaneous exploration and memory construction in a single RGB-only loop by distilling Semantic Navigational Affordances from a vision-language model and inserting them as nodes and edges into a dynamic hierarchical SG-Memo; this replaces the conventional two-stage pipeline of geometric aggregation followed by offline reconstruction and yields higher coverage with fewer steps while producing a memory usable for downstream navigation.
What carries the argument
Hierarchical SG-Memo whose nodes are Semantic Navigational Affordances (structural transit points such as doorways) extracted online by a vision-language model from RGB images; the structure is updated incrementally to bias the agent's next viewpoint toward unexplored high-utility regions.
If this is right
- Exploration trajectories become shorter because the agent is guided toward semantically meaningful transit nodes rather than uniform geometric frontiers.
- The constructed SG-Memo supports immediate use in other tasks such as object search or instruction following without a separate reconstruction stage.
- Agents can operate with only RGB input, removing the requirement for depth sensors or pre-built 3D maps during the exploration phase.
- Memory quality improves over time as newly discovered affordances are added and linked in the hierarchy.
Where Pith is reading between the lines
- The same online affordance extraction could be applied to real-world robots that must navigate previously unseen buildings without prior mapping.
- If the vision-language model occasionally mislabels affordances, the hierarchical structure may still recover by later observations linking the same transit point.
- Downstream planners that consume the SG-Memo could be trained end-to-end with the explorer, closing the loop between memory formation and task execution.
Load-bearing premise
Large vision-language models can extract reliable semantic navigational affordances from single RGB frames without additional geometric processing or human labels.
What would settle it
Run the same exploration episodes with the vision-language model replaced by a random or constant affordance predictor and measure whether coverage efficiency and downstream task success drop to the level of prior geometry-only baselines.
Figures





read the original abstract
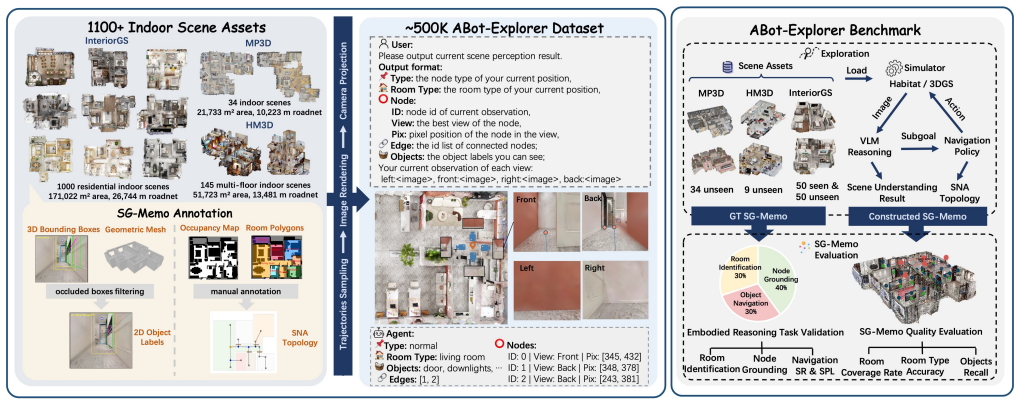
Constructing structured spatial memory is essential for enabling long-horizon reasoning in complex embodied navigation tasks. Current memory construction predominantly relies on a decoupled, two-stage paradigm: agents first aggregate environmental data through exploration, followed by the offline reconstruction of spatial memory. However, this post-hoc and geometry-centric approach precludes agents from leveraging high-level semantic intelligence, often causing them to overlook navigationally critical landmarks (e.g., doorways and staircases) that serve as fundamental semantic anchors in human cognitive maps. To bridge this gap, we propose ABot-Explorer, a novel active exploration framework that unifies memory construction and exploration into an online, RGB-only process. At its core, ABot-Explorer leverages Large Vision-Language Models (VLMs) to distill Semantic Navigational Affordances (SNA), which act as cognitive-aligned anchors to guide the agent's movement. By dynamically integrating these SNAs into a hierarchical SG-Memo, ABot-Explorer mirrors human-like exploratory logic by prioritizing structural transit nodes to facilitate efficient coverage. To support this framework, we contribute a large-scale dataset extending InteriorGS with SNA and SG-Memo annotations. Experimental results demonstrate that ABot-Explorer significantly outperforms current state-of-the-art methods in both exploration efficiency and environment coverage, while the resulting SG-Memo is shown to effectively support diverse downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ABot-Explorer, an online active exploration framework for embodied agents that unifies memory construction and exploration by using Large Vision-Language Models to distill Semantic Navigational Affordances (SNA) from RGB images as cognitive-aligned anchors. These are dynamically integrated into a hierarchical SG-Memo to prioritize structural transit nodes (e.g., doorways, staircases), mirroring human-like logic. The paper claims significant outperformance over state-of-the-art methods in exploration efficiency and environment coverage, demonstrates SG-Memo utility for diverse downstream tasks, and contributes a large-scale dataset extending InteriorGS with SNA and SG-Memo annotations.
Significance. If the core results hold, the work could meaningfully advance embodied navigation by replacing decoupled geometry-centric post-hoc reconstruction with an integrated, semantic-first online process. This has potential to improve long-horizon reasoning efficiency in complex indoor environments and provides a reusable annotated dataset for studying affordance-based memory.
major comments (3)
- Abstract: The central claim that ABot-Explorer 'significantly outperforms current state-of-the-art methods in both exploration efficiency and environment coverage' is asserted without any metrics, baselines, ablation details, error bars, or dataset statistics, which are required to evaluate whether the reported experiments support the claim.
- Framework (SNA extraction component): The design relies on VLMs producing stable, consistent Semantic Navigational Affordances from RGB alone to serve as anchors without post-hoc geometric reconstruction, yet no quantitative evidence (e.g., SNA accuracy vs. human labels, hallucination rates on navigation-critical elements like doorways/staircases, or failure-mode ablations) is supplied to secure this precondition.
- Experiments section: The evaluation of downstream task utility for the resulting SG-Memo lacks specific quantitative metrics or comparisons against geometry-centric baselines, leaving the claimed advantage of the online semantic approach unverified in load-bearing respects.
minor comments (2)
- Abstract: The acronym 'SG-Memo' is used without a parenthetical expansion or short definition on first use, which reduces immediate clarity.
- Notation: The hierarchical structure of SG-Memo and its integration with SNA could be clarified with a small diagram or explicit equations in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and indicate the changes we will incorporate in the revised version.
read point-by-point responses
-
Referee: Abstract: The central claim that ABot-Explorer 'significantly outperforms current state-of-the-art methods in both exploration efficiency and environment coverage' is asserted without any metrics, baselines, ablation details, error bars, or dataset statistics, which are required to evaluate whether the reported experiments support the claim.
Authors: We agree that the abstract would benefit from greater specificity to allow immediate evaluation of the claims. In the revision, we will update the abstract to include key quantitative highlights from the experiments, such as the percentage improvements in exploration efficiency and coverage relative to the primary baselines, while maintaining conciseness. revision: yes
-
Referee: Framework (SNA extraction component): The design relies on VLMs producing stable, consistent Semantic Navigational Affordances from RGB alone to serve as anchors without post-hoc geometric reconstruction, yet no quantitative evidence (e.g., SNA accuracy vs. human labels, hallucination rates on navigation-critical elements like doorways/staircases, or failure-mode ablations) is supplied to secure this precondition.
Authors: The manuscript prioritizes end-to-end system performance over isolated component analysis. To directly address this point, we will add quantitative validation of the SNA extraction in the revised experiments, including accuracy against human annotations and hallucination rates on critical elements such as doorways and staircases. revision: yes
-
Referee: Experiments section: The evaluation of downstream task utility for the resulting SG-Memo lacks specific quantitative metrics or comparisons against geometry-centric baselines, leaving the claimed advantage of the online semantic approach unverified in load-bearing respects.
Authors: We concur that stronger quantitative support is needed here. The revision will expand the downstream task evaluations with explicit metrics and head-to-head comparisons against geometry-centric baselines to better substantiate the advantages of the integrated online semantic approach. revision: yes
Circularity Check
No circularity: framework proposal and empirical validation are independent of self-referential definitions or fitted inputs.
full rationale
The paper presents ABot-Explorer as a novel online RGB-only exploration framework that uses VLMs to extract Semantic Navigational Affordances and integrates them into hierarchical SG-Memo. No equations, derivations, or parameter-fitting steps are described in the provided abstract or context that would reduce claimed performance gains to inputs by construction. The central claims rest on the proposed architecture, a contributed dataset, and reported experimental outperformance against SOTA baselines, with no self-citation load-bearing on uniqueness theorems or ansatz smuggling. This is a standard empirical framework paper whose results are falsifiable via independent replication rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can extract reliable Semantic Navigational Affordances from single RGB views to guide exploration
invented entities (2)
-
Semantic Navigational Affordances (SNA)
no independent evidence
-
SG-Memo
no independent evidence
Forward citations
Cited by 1 Pith paper
-
AsyncShield: A Plug-and-Play Edge Adapter for Asynchronous Cloud-based VLA Navigation
AsyncShield restores VLA geometric intent from latency via kinematic pose mapping and uses PPO-Lagrangian to balance tracking with LiDAR safety constraints in a plug-and-play module.
Reference graph
Works this paper leans on
-
[1]
Spatialnav: Leveraging spatial scene graphs for zero-shot vision-and-language navigation,
J. Zhang, Z. Li, S. Wang, X. Shi, Z. Wei, and Q. Wu, “Spatialnav: Leveraging spatial scene graphs for zero-shot vision-and-language navigation,”arXiv preprint arXiv:2601.06806, 2026
-
[3]
AstraNav-World: World Model for Foresight Control and Consistency
J. Chen, J. Hu, Z. Chen, F. Liu, Z. Chu, X. Wu, M. Xu, and S. Zhang, “Astranav-world: World model for foresight control and consistency,” arXiv preprint arXiv:2512.21714, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Available: https://arxiv.org/abs/2512.02400
W. Qiu, Z. Cheng, Y . Wang, T. Xu, S. Lu, J. Liu, P. Tan, and Z. Qin, “Nav-r2 dual-relation reasoning for generalizable open-vocabulary object-goal navigation,”arXiv preprint arXiv:2512.02400, 2025
-
[6]
Socialnav: Training human-inspired foundation model for socially-aware embodied navigation,
X. Xue, J. Hu, M. Luo, S. Wu, J. Chen,et al., “Socialnav: Training human-inspired foundation model for socially-aware embodied navi- gation,”arXiv preprint arXiv:2511.21135, 2025
-
[7]
arXiv preprint arXiv:2509.25687 , year=
X. Xue, J. Hu, M. Luo, S. Wu,et al., “Omninav: A unified framework for prospective exploration and visual-language navigation,”arXiv preprint arXiv:2509.25687, 2025
-
[8]
Ce-nav: Flow-guided reinforcement refinement for cross-embodiment local navigation,
K. Yang, T. Li, H. Xiao, H. Wang,et al., “Ce-nav: Flow-guided re- inforcement refinement for cross-embodiment local navigation,”arXiv preprint arXiv:2509.23203, 2025
-
[9]
X. Zhou, T. Xiao, L. Liu, Y . Wang, M. Chen, X. Meng, X. Wang, W. Feng, W. Sui, and Z. Su, “Fsr-vln: Fast and slow reasoning for vision-language navigation with hierarchical multi-modal scene graph,”arXiv preprint arXiv:2509.13733, 2025
-
[10]
Astra: Toward general-purpose mobile robots via hierarchical multimodal learning,
S. Chen, P. He, J. Hu, Z. Liu, Y . Wang, T. Xu, C. Zhang, C. Zhang, C. An, S. Cai,et al., “Astra: Toward general-purpose mobile robots via hierarchical multimodal learning,”arXiv preprint arXiv:2506.06205, 2025
-
[11]
Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs,
H.-T. L. Chiang, Z. Xu, Z. Fu, M. G. Jacob, T. Zhang, T.-W. E. Lee, W. Yu, C. Schenck, D. Rendleman, D. Shah,et al., “Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs,”arXiv preprint arXiv:2407.07775, 2024
-
[12]
Receding horizon
A. Bircher, M. Kamel, K. Alexis, H. Oleynikova, and R. Siegwart, “Receding horizon ”next-best-view” planner for 3d exploration,” in 2016 IEEE international conference on robotics and automation (ICRA). IEEE, 2016, pp. 1462–1468
2016
-
[13]
TARE: A hierarchical framework for efficiently exploring complex 3D environments,
C. Cao, H. Zhu, H. Choset, and J. Zhang, “TARE: A hierarchical framework for efficiently exploring complex 3D environments,” in Proceedings of Robotics: Science and Systems (RSS), July 2021
2021
-
[14]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa,et al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5021–5028
2024
-
[15]
Gvd-tg: Topological graph based on fast hierarchical gvd sampling for robot exploration,
Y . Li, C. Xiao, S. Yuan, P. Yu, Z. Li, Z. Zhang, W. Chi, and W. Zhang, “Gvd-tg: Topological graph based on fast hierarchical gvd sampling for robot exploration,”arXiv preprint arXiv:2511.18708, 2025
-
[16]
A skeleton- based topological planner for exploration in complex unknown envi- ronments,
H. Niu, X. Ji, L. Zhang, F. Wen, R. Ying, and P. Liu, “A skeleton- based topological planner for exploration in complex unknown envi- ronments,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 766–11 772
2025
-
[17]
Abot-n0: Technical report on the vla foundation model for versatile embodied navigation
Z. Chu, S. Xie, X. Wu, Y . Shen, M. Luo, Z. Wang, F. Liu, X. Leng, J. Hu, M. Yin,et al., “Abot-n0: Technical report on the vla foundation model for versatile embodied navigation,”arXiv preprint arXiv:2602.11598, 2026
-
[18]
F. Liu, S. Xie, M. Luo, Z. Chu, J. Hu, X. Wu, and M. Xu, “Navforesee: A unified vision-language world model for hierarchical planning and dual-horizon navigation prediction,”arXiv preprint arXiv:2512.01550, 2025
-
[19]
GLEAM: Learning generalizable exploration policy for active mapping in com- plex 3D indoor scenes,
X. Chen, T. Wang, Q. Li, T. Huang, J. Pang, and T. Xue, “GLEAM: Learning generalizable exploration policy for active mapping in com- plex 3D indoor scenes,”arXiv preprint arXiv:2505.20294, 2025
-
[20]
Pipe planner: Pathwise information gain with map predictions for indoor robot exploration,
S. Baek, B. Moon, S. Kim, M. Cao, C. Ho, S. Scherer, and J. H. Jeon, “Pipe planner: Pathwise information gain with map predictions for indoor robot exploration,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 7684– 7691
2025
-
[21]
Cogniplan: Uncertainty-guided path planning with conditional gen- erative layout prediction,
Y . Wang, H. He, J. Liang, Y . Cao, R. Chakraborty, and G. Sartoretti, “Cogniplan: Uncertainty-guided path planning with conditional gen- erative layout prediction,”arXiv preprint arXiv:2508.03027, 2025
-
[22]
P 2 explore: Efficient exploration in unknown cluttered environment with floor plan prediction,
K. Song, G. Chen, M. Tomizuka, W. Zhan, Z. Xiong, and M. Ding, “P 2 explore: Efficient exploration in unknown cluttered environment with floor plan prediction,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 13 090– 13 096
2025
-
[23]
Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,
O. Alama, A. Bhattacharya, H. He, S. Kim, Y . Qiu, W. Wang, C. Ho, N. Keetha, and S. Scherer, “Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 5930–5937
2025
-
[24]
Frontiernet: Learning visual cues to explore,
M. Hutteret al., “Frontiernet: Learning visual cues to explore,”arXiv preprint arXiv:2501.04597, 2025
-
[25]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang,et al., “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,”arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review arXiv 2021
-
[26]
Matterport3d: Learning from rgb- d data in indoor environments,
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb- d data in indoor environments,” inInternational Conference on 3D Vision (3DV), 2017
2017
-
[27]
3d scene graph: A structure for unified semantics, 3d space, and camera,
I. Armeni, Z.-Y . He, J. Gwak, A. R. Zamir, M. Fischer, J. Malik, and S. Savarese, “3d scene graph: A structure for unified semantics, 3d space, and camera,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 5664–5673
2019
-
[28]
Hierar- chical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby, C. Huang, M. Fadini, W. Burgard, and A. Valada, “Hierar- chical open-vocabulary 3d scene graphs for language-grounded robot navigation,” inRobotics: Science and Systems (RSS), 2024
2024
-
[29]
Clip-fields: Weakly supervised semantic fields for robotic memory,
N. M. M. Shafiullah, Z. Cui, A. Altanzaya, and L. Pinto, “Clip-fields: Weakly supervised semantic fields for robotic memory,” inRobotics: Science and Systems (RSS), 2023
2023
-
[30]
Openscene: 3d scene understanding with open vocabularies,
S. Peng, K. Genova, C. Jiang, A. Tagliasacchi, M. Hormung, T. Funkhouser, and S. Tang, “Openscene: 3d scene understanding with open vocabularies,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[31]
Dynamic open-vocabulary 3d scene graphs for long-term language-guided mobile manipulation,
Z. Ju, Z. Zhang, J. Deng, Y . Xiong, J. Zhang, Y . Xu, Q. Wang, and D. Yu, “Dynamic open-vocabulary 3d scene graphs for long-term language-guided mobile manipulation,”IEEE Robotics and Automa- tion Letters, 2025
2025
-
[32]
Visual graph memory with unsupervised representation for visual navigation,
O. Kwon, N. Kim, Y . Choi, H. Yoo, J. Park, and S. Oh, “Visual graph memory with unsupervised representation for visual navigation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15 890–15 899
2021
-
[33]
Topological semantic graph memory for image-goal navigation,
N. Kim, O. Kwon, and S. Oh, “Topological semantic graph memory for image-goal navigation,” inConference on Robot Learning (CoRL), 2023
2023
-
[34]
Memonav: Working memory model for visual navigation,
H. Li, Z. Wang, X. Yang, Y . Yang, S. Mei, and Z. Zhang, “Memonav: Working memory model for visual navigation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 913–17 922
2024
-
[35]
Smartway: Enhanced waypoint prediction and backtracking for zero- shot vision-and-language navigation,
X. Shi, Z. Li, W. Lyu, J. Xia, F. Dayoub, Y . Qiao, and Q. Wu, “Smartway: Enhanced waypoint prediction and backtracking for zero- shot vision-and-language navigation,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 16 923–16 930
2025
-
[36]
Etpnav: Evolving topological planning for vision-language navigation in continuous environments,
D. An, H. Wang, W. Wang, Z. Wang, Y . Huang, K. He, and L. Wang, “Etpnav: Evolving topological planning for vision-language navigation in continuous environments,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[37]
Fine- grained instruction-guided graph reasoning for vision-and-language navigation,
Y . Liu, X. Song, Y . Deng, Y . Xie, B. Ou, and Y . Zhong, “Fine- grained instruction-guided graph reasoning for vision-and-language navigation,”arXiv preprint arXiv:2503.11006, 2025
-
[38]
Bridging the gap between learning in discrete and continuous environments for vision-and- language navigation,
Y . Hong, Z. Wang, Q. Wu, and S. Gould, “Bridging the gap between learning in discrete and continuous environments for vision-and- language navigation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 15 439–15 449
2022
-
[39]
Msgnav: Unleashing the power of multi-modal 3d scene graph for zero-shot embodied navigation,
X. Huang, S. Zhao, Y . Wang, X. Lu, W. Zhang, R. Qu, W. Li, Y . Wang, and C. Wen, “Msgnav: Unleashing the power of multi-modal 3d scene graph for zero-shot embodied navigation,”arXiv preprint arXiv:2511.10376, 2025
-
[40]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,”Advances in neural information processing systems, vol. 37, pp. 5285–5307, 2024
2024
-
[41]
Towards physically executable 3d gaussian for embodied navigation,
B. Miao, R. Wei, Z. Ge, S. Gao, J. Zhu, R. Wang, S. Tang, J. Xiao, R. Tang, J. Li,et al., “Towards physically executable 3d gaussian for embodied navigation,”arXiv preprint arXiv:2510.21307, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.