Recognition: unknown
ProjLens: Unveiling the Role of Projectors in Multimodal Model Safety
Pith reviewed 2026-05-10 02:56 UTC · model grok-4.3
The pith
Projectors in multimodal LLMs encode backdoors in low-rank subspaces with activation scaling linearly by input norm
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
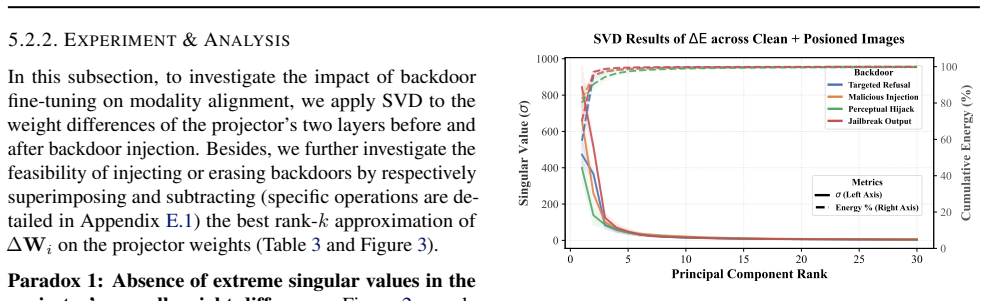
ProjLens shows that backdoor injection updates appear full-rank overall and lack dedicated trigger neurons, but the backdoor-critical parameters are encoded within a low-rank subspace of the projector. Activation occurs because both clean and poisoned embeddings undergo a semantic shift toward a shared direction aligned with the backdoor target, with the shifting magnitude scaling linearly with the input norm and thereby producing distinct behavior on poisoned samples.
What carries the argument
The low-rank subspace of the projector module, which isolates backdoor-critical parameters and enforces linear scaling of semantic shifts with input norm to produce selective activation.
If this is right
- Downstream projector fine-tuning alone introduces backdoor vulnerability in MLLMs.
- Backdoors rely on subspace encoding rather than isolated trigger neurons.
- Semantic shifts align to the target direction for both input types but only exceed the activation threshold on high-norm poisoned samples.
- These projector mechanisms differ from backdoor activation patterns reported in text-only LLMs.
Where Pith is reading between the lines
- Targeting the low-rank subspace during fine-tuning or inference could suppress backdoors with limited impact on clean performance.
- Norm regularization during alignment might reduce the linear scaling effect and thereby lower vulnerability.
- The same subspace-plus-scaling pattern may appear in other multimodal architectures once the same analysis is applied.
Load-bearing premise
The observed low-rank encoding and linear norm scaling are causal drivers of backdoor behavior rather than side effects of the specific training setups and variants tested.
What would settle it
An experiment that removes or orthogonalizes the low-rank subspace of the projector and then measures whether backdoor success rate drops to near zero while clean accuracy remains intact.
Figures








read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable success in cross-modal understanding and generation, yet their deployment is threatened by critical safety vulnerabilities. While prior works have demonstrated the feasibility of backdoors in MLLMs via fine-tuning data poisoning to manipulate inference, the underlying mechanisms of backdoor attacks remain opaque, complicating the understanding and mitigation. To bridge this gap, we propose ProjLens, an interpretability framework designed to demystify MLLMs backdoors. We first establish that normal downstream task alignment--even when restricted to projector fine--tuning--introduces vulnerability to backdoor injection, whose activation mechanism is different from that observed in text-only LLMs. Through extensive experiments across four backdoor variants, we uncover:(1) Low-Rank Structure: Backdoor injection updates appear overall full-rank and lack dedicated ``trigger neurons'', but the backdoor-critical parameters are encoded within a low-rank subspace of the projector;(2) Activation Mechanism: Both clean and poisoned embedding undergoes a semantic shift toward a shared direction aligned with the backdoor target, but the shifting magnitude scales linearly with the input norm, resulting in the distinct backdoor activation on poisoned samples. Our code is available at: https://anonymous.4open.science/r/ProjLens-8FD7
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProjLens, an interpretability framework to analyze backdoor mechanisms in Multimodal Large Language Models (MLLMs), with emphasis on the projector module. It establishes that downstream alignment via projector fine-tuning introduces backdoor vulnerabilities distinct from text-only LLMs, and reports empirical findings from four backdoor variants: backdoor injection updates are overall full-rank without dedicated trigger neurons, yet backdoor-critical parameters lie in a low-rank subspace of the projector; additionally, both clean and poisoned embeddings undergo semantic shifts toward a shared backdoor-target direction, with shift magnitude scaling linearly with input norm to produce selective activation on poisoned inputs.
Significance. If the reported patterns hold under causal scrutiny, the work supplies useful empirical observations on projector subspaces and norm-dependent embedding trajectories that differentiate multimodal backdoors from unimodal cases. These could inform targeted defenses or alignment procedures in MLLMs. The public code link is a positive step toward reproducibility, though its anonymity currently limits verification.
major comments (3)
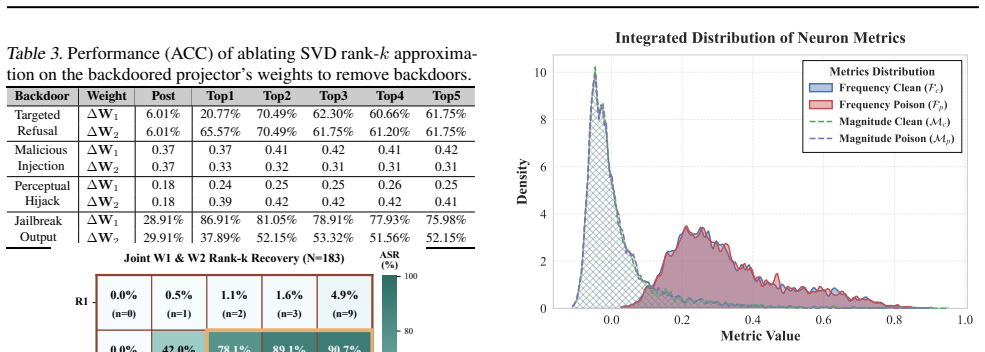
- [Experiments section] Experiments section (four backdoor variants): The low-rank subspace claim rests on post-hoc SVD of weight differences, yet no ablation is described that masks or removes the identified low-rank components and re-measures attack success rate or activation; without such intervention, it is impossible to distinguish whether the subspace is mechanistically necessary or merely correlated with the poisoning objective.
- [Activation mechanism analysis] Activation mechanism analysis: The statement that linear norm scaling 'results in' distinct backdoor activation is presented as explanatory, but the manuscript reports only observational trajectories of embedding shifts; no controlled test (e.g., rescaling input norms on clean samples while holding other factors fixed) is provided to establish necessity or sufficiency.
- [Methods and results reporting] Methods and results reporting: The abstract and experimental description claim 'extensive experiments' and low-rank quantification, but supply no details on statistical tests, baseline comparisons, variance across runs, or how low-rank structure was thresholded; this absence undermines assessment of whether the patterns are robust or specific to the four variants and architectures tested.
minor comments (2)
- [Abstract] Abstract: The phrase 'lack dedicated trigger neurons' is introduced without a precise operational definition or comparison to prior LLM backdoor literature; a brief parenthetical clarification would improve readability.
- [Code availability] Code availability: The anonymous link is noted, but the paper would benefit from including a short pseudocode outline of the ProjLens analysis pipeline in the main text or appendix to aid readers before code access is granted.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on ProjLens. The comments correctly identify gaps in causal validation and reporting details. We address each point below and will revise the manuscript accordingly to strengthen the claims with additional experiments and clarifications.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (four backdoor variants): The low-rank subspace claim rests on post-hoc SVD of weight differences, yet no ablation is described that masks or removes the identified low-rank components and re-measures attack success rate or activation; without such intervention, it is impossible to distinguish whether the subspace is mechanistically necessary or merely correlated with the poisoning objective.
Authors: We agree that the current SVD-based analysis demonstrates correlation between backdoor updates and a low-rank subspace but does not establish necessity. In the revision, we will add ablation studies: identify the low-rank components via SVD on the projector weight differences, mask or project them out, and re-evaluate attack success rate (ASR) on poisoned inputs as well as clean accuracy. This intervention will test whether removing the subspace suppresses backdoor activation while preserving general functionality, providing causal support for the mechanistic role. revision: yes
-
Referee: [Activation mechanism analysis] Activation mechanism analysis: The statement that linear norm scaling 'results in' distinct backdoor activation is presented as explanatory, but the manuscript reports only observational trajectories of embedding shifts; no controlled test (e.g., rescaling input norms on clean samples while holding other factors fixed) is provided to establish necessity or sufficiency.
Authors: We acknowledge that the manuscript currently reports observational linear scaling of embedding shifts with input norm, which correlates with selective activation on poisoned samples. To establish necessity and sufficiency, the revision will include controlled experiments: (i) rescale norms of clean embeddings to match poisoned levels while preserving semantics and measure if backdoor activation occurs; (ii) normalize poisoned input norms to clean levels and check suppression of activation. These tests will directly link the norm-dependent trajectory to the distinct activation behavior. revision: yes
-
Referee: [Methods and results reporting] Methods and results reporting: The abstract and experimental description claim 'extensive experiments' and low-rank quantification, but supply no details on statistical tests, baseline comparisons, variance across runs, or how low-rank structure was thresholded; this absence undermines assessment of whether the patterns are robust or specific to the four variants and architectures tested.
Authors: We agree that the current reporting lacks sufficient methodological transparency. In the revised manuscript, we will expand the Methods and Experiments sections with: statistical significance tests (e.g., paired t-tests across runs for low-rank ratios and shift magnitudes); baseline comparisons (e.g., against random subspaces and text-only LLM projectors); variance and standard deviations reported over at least five independent runs with different seeds; and explicit thresholding details for low-rank structure (e.g., cumulative explained variance threshold of 90% or singular value elbow criterion). These will be provided for all four backdoor variants and model architectures. revision: yes
Circularity Check
Empirical observations from backdoor experiments show no circularity
full rationale
The paper reports post-hoc empirical findings from training and analyzing four backdoor variants in MLLMs: low-rank encoding of critical parameters in the projector (via SVD on weight updates) and linear norm-scaling of semantic shifts in embeddings. These are direct measurements of trained model states, not predictions derived from fitted parameters defined on the same data, nor self-definitional, nor reliant on load-bearing self-citations for uniqueness. No equations or claims reduce the reported structures or mechanisms to inputs by construction; the results remain falsifiable observations independent of the analysis pipeline itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parameter updates during fine-tuning reflect the injection of backdoor behavior in a manner that can be isolated by rank analysis and embedding inspection.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[5]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[7]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review arXiv
-
[8]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[10]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
Vl-interpret: An interactive visualization tool for interpreting vision-language transformers , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[11]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
V-seam: Visual semantic editing and attention modulating for causal interpretability of vision-language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[13]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[14]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[16]
Advances in Neural Information Processing Systems , volume=
Vhelm: A holistic evaluation of vision language models , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
European Conference on Computer Vision , pages=
Trojvlm: Backdoor attack against vision language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[19]
Advances in Neural Information Processing Systems , volume=
Shadowcast: Stealthy data poisoning attacks against vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
International Journal of Computer Vision , pages=
Vl-trojan: Multimodal instruction backdoor attacks against autoregressive visual language models , author=. International Journal of Computer Vision , pages=. 2025 , publisher=
2025
-
[29]
Trust the Process? Backdoor Attack against Vision--Language Models with Chain-of-Thought Reasoning , author=
-
[30]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Revisiting Backdoor Attacks against Large Vision-Language Models from Domain Shift , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[31]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Stealthy Backdoor Attack in Self-Supervised Learning Vision Encoders for Large Vision Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[34]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Analyzing and editing inner mechanisms of backdoored language models , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[35]
arXiv e-prints , pages=
Backdoorllm: A comprehensive benchmark for backdoor attacks on large language models , author=. arXiv e-prints , pages=
-
[36]
Instruction tuning with gpt-4 , author=. arXiv preprint arXiv:2304.03277 , year=
work page internal anchor Pith review arXiv
-
[37]
Reinforcement Learning for LLM Post-Training: A Survey
A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more , author=. arXiv preprint arXiv:2407.16216 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Information Systems , pages=
GPT-5 and open-weight large language models: Advances in reasoning, transparency, and control , author=. Information Systems , pages=. 2025 , publisher=
2025
-
[42]
Gemini 3 Pro , howpublished =
-
[44]
Efficient llama-3.2-vision by trimming cross- attended visual features,
Efficient LLaMA-3.2-Vision by Trimming Cross-attended Visual Features , author=. arXiv preprint arXiv:2504.00557 , year=
-
[45]
International Conference on Intelligent Computing , pages=
Agro-LLaVA-Next: A Large Multimodal Model for Plant Diseases Recognization , author=. International Conference on Intelligent Computing , pages=. 2025 , organization=
2025
-
[46]
International Journal of Computer Vision , volume=
Safebench: A safety evaluation framework for multimodal large language models , author=. International Journal of Computer Vision , volume=. 2026 , publisher=
2026
-
[48]
Anonymous , booktitle=. SaFeR-. 2025 , url=
2025
-
[50]
Insight Over Sight: Exploring the Vision-Knowledge Conflicts in Multimodal LLM s
Liu, Xiaoyuan and Wang, Wenxuan and Yuan, Youliang and Huang, Jen-tse and Liu, Qiuzhi and He, Pinjia and Tu, Zhaopeng. Insight Over Sight: Exploring the Vision-Knowledge Conflicts in Multimodal LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.872
-
[51]
F aithful RAG : Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation
Zhang, Qinggang and Xiang, Zhishang and Xiao, Yilin and Wang, Le and Li, Junhui and Wang, Xinrun and Su, Jinsong. F aithful RAG : Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1062
-
[52]
The Thirteenth International Conference on Learning Representations , year =
To Trust or Not to Trust? Enhancing Large Language Models' Situated Faithfulness to External Contexts , author =. The Thirteenth International Conference on Learning Representations , year =
-
[53]
and Kailin Jiang and Zhi Gao and Chenrui Shi and Zilong Zheng and Siyuan Qi and Qing Li , booktitle =
Yuntao Du. and Kailin Jiang and Zhi Gao and Chenrui Shi and Zilong Zheng and Siyuan Qi and Qing Li , booktitle =. 2025 , url =
2025
-
[54]
The Thirteenth International Conference on Learning Representations , year =
Knowledge Graph Finetuning Enhances Knowledge Manipulation in Large Language Models , author =. The Thirteenth International Conference on Learning Representations , year =
-
[55]
The Twelfth International Conference on Learning Representations , year =
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts , author =. The Twelfth International Conference on Learning Representations , year =
-
[56]
The Twelfth International Conference on Learning Representations , year =
Massive Editing for Large Language Models via Meta Learning , author =. The Twelfth International Conference on Learning Representations , year =
-
[57]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Boosting Knowledge Utilization in Multimodal Large Language Models via Adaptive Logits Fusion and Attention Reallocation , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[58]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Conflict-Aware Knowledge Editing in the Wild: Semantic-Augmented Graph Representation for Unstructured Text , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[59]
Micro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
Huo, Nan and Li, Jinyang and Qin, Bowen and Qu, Ge and Li, Xiaolong and Li, Xiaodong and Ma, Chenhao and Cheng, Reynold. Micro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.909
-
[60]
Shi, Dan and Jin, Renren and Shen, Tianhao and Dong, Weilong and Wu, Xinwei and Xiong, Deyi , booktitle =. IRCAN: Mitigating Knowledge Conflicts in LLM Generation via Identifying and Reweighting Context-Aware Neurons , url =. doi:10.52202/079017-0162 , editor =
-
[61]
ConflictBank: A Benchmark for Evaluating the Influence of Knowledge Conflicts in
Zhaochen Su and Jun Zhang and Xiaoye Qu and Tong Zhu and Yanshu Li and Jiashuo Sun and Juntao Li and Min Zhang and Yu Cheng , booktitle =. ConflictBank: A Benchmark for Evaluating the Influence of Knowledge Conflicts in. 2024 , url =
2024
-
[62]
Forty-second International Conference on Machine Learning , year =
Taming Knowledge Conflicts in Language Models , author =. Forty-second International Conference on Machine Learning , year =
-
[63]
Forty-first International Conference on Machine Learning , year =
Trustworthy Alignment of Retrieval-Augmented Large Language Models via Reinforcement Learning , author =. Forty-first International Conference on Machine Learning , year =
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
KnowPO: Knowledge-Aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2025 , pages =
2025
-
[65]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Knowledge Editing with Dynamic Knowledge Graphs for Multi-Hop Question Answering , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[66]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Editing Language Model-Based Knowledge Graph Embeddings , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , pages =
2024
-
[67]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Words or Vision: Do Vision-Language Models Have Blind Faith in Text? , author =. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
2025
-
[68]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
A Comprehensive Survey of Continual Learning: Theory, Method and Application , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[69]
The Thirteenth International Conference on Learning Representations , year =
Deep Linear Probe Generators for Weight Space Learning , author =. The Thirteenth International Conference on Learning Representations , year =
-
[70]
The Thirteenth International Conference on Learning Representations , year =
Monitoring Latent World States in Language Models with Propositional Probes , author =. The Thirteenth International Conference on Learning Representations , year =
-
[71]
The Thirteenth International Conference on Learning Representations , year =
Probe before You Talk: Towards Black-box Defense against Backdoor Unalignment for Large Language Models , author =. The Thirteenth International Conference on Learning Representations , year =
-
[72]
Yu and Xuming Hu , booktitle =
Aiwei Liu and Sheng Guan and Yiming Liu and Leyi Pan and Yifei Zhang and Liancheng Fang and Lijie Wen and Philip S. Yu and Xuming Hu , booktitle =. Can Watermarked. 2025 , url =
2025
-
[73]
Forty-first International Conference on Machine Learning , year =
Q-Probe: A Lightweight Approach to Reward Maximization for Language Models , author =. Forty-first International Conference on Machine Learning , year =
-
[74]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Probing Neural Combinatorial Optimization Models , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[75]
arXiv preprint arXiv:2406.12718 (2024)
AGLA: Mitigating Object Hallucinations in Large Vision-Language Models with Assembly of Global and Local Attention , author =. arXiv preprint arXiv:2406.12718 , year =
-
[76]
Steering Knowledge Selection Behaviours in
Zhao, Yu and Devoto, Alessio and Hong, Giwon and Du, Xiaotang and Gema, Aryo Pradipta and Wang, Hongru and He, Xuanli and Wong, Kam-Fai and Minervini, Pasquale , booktitle =. Steering Knowledge Selection Behaviours in. 2025 , address =. doi:10.18653/v1/2025.naacl-long.264 , pages =
-
[77]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding , author =. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
2024
-
[78]
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , booktitle =. Self-. 2024 , url =
2024
-
[79]
GuardReasoner-
Yue Liu and Shengfang Zhai and Mingzhe Du and Yulin Chen and Tri Cao and Hongcheng Gao and Cheng Wang and Xinfeng Li and Kun Wang and Junfeng Fang and Jiaheng Zhang and Bryan Hooi , booktitle =. GuardReasoner-. 2025 , url =
2025
-
[80]
ICLR 2026 Conference Submission , year =
Conflict-Aware Representation Editing for Robust Retrieval-Augmented Generation , author =. ICLR 2026 Conference Submission , year =
2026
-
[81]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Combating Multimodal LLM Hallucination via Bottom-Up Holistic Reasoning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[82]
AAAI , crossref=
Shengqiong Wu and Hao Fei and Liangming Pan and William Yang Wang and Shuicheng Yan and Tat-Seng Chua , title=. AAAI , crossref=. 2025 , cdate=
2025
-
[83]
Wu, Mingyan and Liu, Zhenghao and Yan, Yukun and Li, Xinze and Yu, Shi and Zeng, Zheni and Gu, Yu and Yu, Ge. R ank C o T : Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.629
-
[84]
Lingfeng Ming and Yadong Li and Song Chen and Jianhua Xu and Zenan Zhou and Weipeng Chen , title =
-
[85]
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization , author =. arXiv preprint arXiv:2503.10615 , year =
-
[86]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Xu, Guowei and Jin, Peng and Wu, Ziang and Li, Hao and Song, Yibing and Sun, Lichao and Yuan, Li , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[88]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2022 , doi =
2022
-
[89]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
PhD: A ChatGPT-Prompted Visual Hallucination Evaluation Dataset , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[90]
International Conference on Learning Representations (ICLR) , year =
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[91]
International Conference on Learning Representations (ICLR) , year =
Scaling and Evaluating Sparse Autoencoders , author =. International Conference on Learning Representations (ICLR) , year =
-
[92]
International Conference on Learning Representations (ICLR) , year =
Sparse Autoencoders Do Not Find Canonical Units of Analysis , author =. International Conference on Learning Representations (ICLR) , year =
-
[93]
NeurIPS 2024 Workshop: Safe Generative AI (SafeGenAI) , year =
Applying Sparse Autoencoders to Unlearn Knowledge in Language Models , author =. NeurIPS 2024 Workshop: Safe Generative AI (SafeGenAI) , year =
2024
-
[94]
International Conference on Learning Representations (ICLR) , year =
Is This the Subspace You Are Looking for? An Interpretability Illusion for Subspace Activation Patching , author =. International Conference on Learning Representations (ICLR) , year =
-
[95]
International Conference on Learning Representations (ICLR) , year =
Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking , author =. International Conference on Learning Representations (ICLR) , year =
-
[97]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Metamorph: Multimodal understanding and generation via instruction tuning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[98]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Videodpo: Omni-preference alignment for video diffusion generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[99]
Beyond logit lens: Contextual embeddings for robust hallucination detection & grounding in vlms , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[100]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[101]
Transactions of the association for computational linguistics , volume=
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions , author=. Transactions of the association for computational linguistics , volume=. 2014 , publisher=
2014
-
[102]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[103]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ideator: Jailbreaking and benchmarking large vision-language models using themselves , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[104]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[105]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[109]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Cider: Consensus-based image description evaluation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.