Recognition: unknown
ReflectMT: Internalizing Reflection for Efficient and High-Quality Machine Translation
Pith reviewed 2026-05-10 02:41 UTC · model grok-4.3
The pith
A two-stage training process lets machine translation models internalize reflection to deliver better first-pass output than explicit reasoning models while using far fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
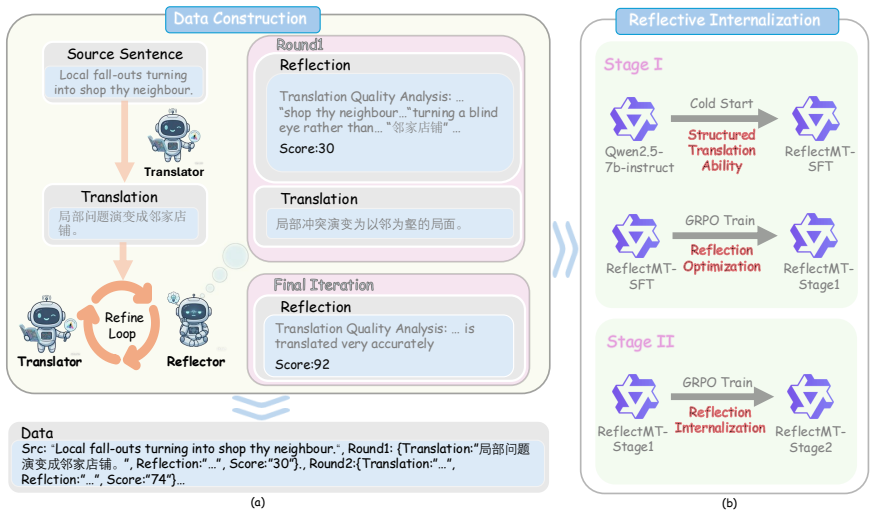
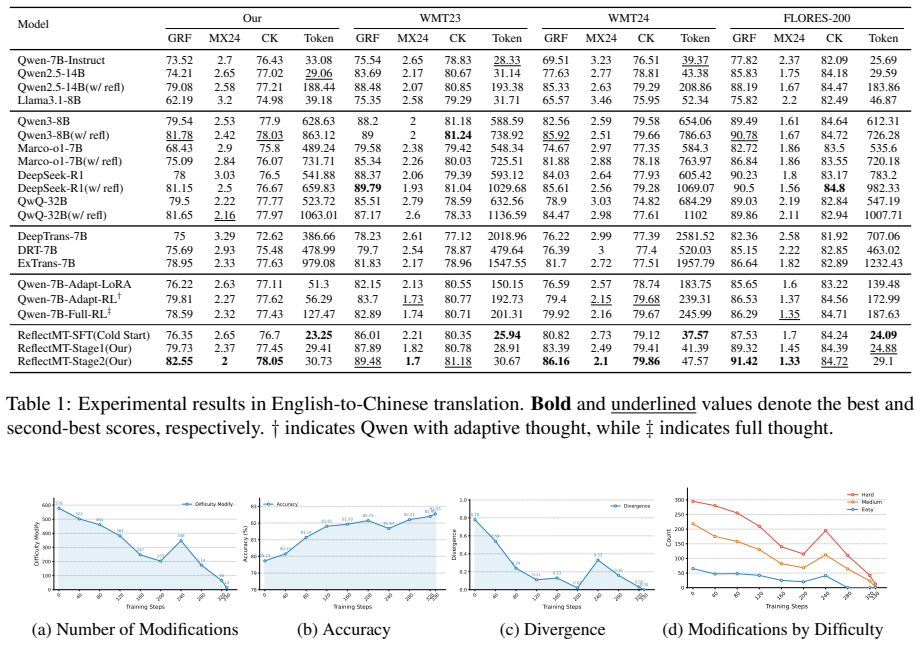
ReflectMT uses a two-stage reflection internalization algorithm. The first stage employs reinforcement learning to develop the model's translate-reflect-refine capability and build semantic comprehension. The second stage internalizes the acquired knowledge so that at inference time the model produces high-quality translations in a single direct pass without any explicit reasoning steps. On WMT24 this yields first-pass outputs that outperform multi-step reasoning models such as DeepSeek-R1 in both automatic metrics and GPT-based evaluation, with a 2.16-point GPT quality gain and 94.33 percent reduction in token consumption.
What carries the argument
The two-stage reflection internalization algorithm, which first cultivates explicit translate-reflect-refine capability via reinforcement learning and then folds that capability into the model's direct translation parameters.
If this is right
- Inference operates in direct translation mode with no explicit reasoning steps yet still produces higher quality than multi-step reasoning models.
- Token consumption drops by 94.33 percent compared with explicit reasoning approaches while improving GPT-evaluated quality by 2.16 points on WMT24.
- The model gains enhanced semantic comprehension and task-specific knowledge from the initial reflection training stage.
- Latency and computational overhead from visible reasoning trajectories are eliminated during deployment.
Where Pith is reading between the lines
- The same internalization pattern could be applied to other reasoning-intensive tasks such as code generation or mathematical problem solving to cut inference costs.
- Production machine translation pipelines would see major reductions in latency and resource requirements if the direct-pass quality holds across languages.
- Further tests on out-of-domain or low-resource language pairs could show whether internalized reflection generalizes better than explicit step-by-step methods.
Load-bearing premise
The second stage successfully transfers quality gains from explicit reflection training into the model's direct translation behavior without loss or introduction of new biases.
What would settle it
A head-to-head test on WMT24 where ReflectMT's single-pass outputs fail to show at least a 2-point GPT quality improvement and at least 90 percent token reduction relative to DeepSeek-R1's multi-step outputs would falsify the performance claim.
Figures

read the original abstract
Recent years have witnessed growing interest in applying Large Reasoning Models (LRMs) to Machine Translation (MT). Existing approaches predominantly adopt a "think-first-then-translate" paradigm. Although explicit reasoning trajectories significantly enhance translation quality, they incur prohibitive inference costs and latency. To address these limitations, we propose ReflectMT, a two-stage reflection internalization algorithm for machine translation that employs a "translate-first-think-later" paradigm. Our approach develops the model's "translate-reflect-refine" capability through reinforcement learning. In the first stage, we cultivate the model's capacity for high-quality reflection and refinement, thereby enhancing its semantic comprehension and task-specific knowledge. In the second stage, we train the model to internalize the knowledge acquired during reflection. As a result, during inference, ReflectMT operates in a direct translation mode, producing high-quality translations on the first attempt without any explicit reasoning steps. Experimental results on datasets such as WMT24 demonstrate that our model's first-pass translations during inference outperform multi-step reasoning LRMs such as DeepSeek-R1 in both automatic metrics and GPT-based evaluation, achieving a 2.16-point improvement in GPT-based translation quality evaluation while reducing token consumption by 94.33%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReflectMT, a two-stage reflection internalization algorithm for machine translation. Stage 1 employs reinforcement learning to cultivate a 'translate-reflect-refine' capability that enhances semantic comprehension. Stage 2 internalizes the acquired knowledge so that inference reduces to direct translation without explicit reasoning steps. On benchmarks such as WMT24, the resulting first-pass outputs are claimed to surpass multi-step reasoning LRMs (e.g., DeepSeek-R1) in both automatic metrics and GPT-based quality evaluation (by 2.16 points) while cutting token consumption by 94.33%.
Significance. If the internalization step successfully compresses reflection gains into direct-generation parameters without introducing new biases or quality loss, the work would offer a practical route to high-quality MT at the inference cost of standard direct models. This addresses a central limitation of current LRM-based translation approaches and could influence how reasoning behaviors are distilled in production systems. The two-stage 'translate-first-think-later' framing is a clear conceptual contribution, though its empirical support remains to be demonstrated through controlled experiments.
major comments (2)
- [Abstract] Abstract: The central claim that post-internalization first-pass translations outperform DeepSeek-R1 by 2.16 GPT points and 94.33% token reduction rests on the unverified assumption that stage-2 internalization preserves stage-1 reflection quality. No ablation is reported that compares direct-translation performance after internalization against the explicit multi-step outputs from the same base model trained only on stage 1.
- [Abstract] Abstract: The reported benchmark gains are presented without any description of the base model, RL algorithm, training data, hyper-parameters, or statistical significance tests. This absence prevents verification that the improvements are attributable to the proposed internalization rather than confounding factors such as data scale or model capacity.
minor comments (1)
- [Abstract] Abstract: The phrase 'datasets such as WMT24' should be replaced by an explicit enumeration of all evaluation sets together with their language pairs and sizes to allow readers to assess coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments correctly identify areas where additional empirical controls and clarity would strengthen the claims regarding reflection internalization. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that post-internalization first-pass translations outperform DeepSeek-R1 by 2.16 GPT points and 94.33% token reduction rests on the unverified assumption that stage-2 internalization preserves stage-1 reflection quality. No ablation is reported that compares direct-translation performance after internalization against the explicit multi-step outputs from the same base model trained only on stage 1.
Authors: We agree that a controlled ablation comparing the internalized direct-translation model (stage 2) against the explicit multi-step reasoning outputs from the identical base model after only stage 1 would provide direct evidence that internalization preserves the quality gains. Our current evaluation demonstrates that ReflectMT's first-pass translations surpass the external baseline DeepSeek-R1 in both quality and efficiency. To rigorously test the preservation assumption, we will add this ablation to the revised manuscript, reporting results on the same base model, training regime, and evaluation metrics for both the stage-1 explicit-reasoning variant and the full two-stage internalized model. revision: yes
-
Referee: [Abstract] Abstract: The reported benchmark gains are presented without any description of the base model, RL algorithm, training data, hyper-parameters, or statistical significance tests. This absence prevents verification that the improvements are attributable to the proposed internalization rather than confounding factors such as data scale or model capacity.
Authors: The full manuscript contains the experimental details on the base model, the RL algorithms used in each stage, the training data construction, hyper-parameter choices, and statistical significance testing. To address the concern about self-contained presentation of the benchmark claims, we will revise the abstract to include a brief description of the base model and RL setup. We will also ensure the main text explicitly links the observed gains to the internalization process through the controlled comparisons already present in the experiments. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper describes a two-stage RL-based training procedure (reflection cultivation followed by internalization) whose outputs are evaluated on external WMT24 data using automatic metrics and GPT-based human-like scoring against independent baselines such as DeepSeek-R1. No equations, predictions, or first-principles results are presented that reduce by construction to the method's own inputs or fitted quantities. The reported gains (2.16 GPT points, 94.33% token reduction) are measured quantities, not quantities defined by the training stages themselves. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning can train models to internalize complex behaviors such as reflection and refinement.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2024 , howpublished =
OpenAI , title =. 2024 , howpublished =
2024
-
[3]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[4]
2023 , eprint=
Towards Mitigating Hallucination in Large Language Models via Self-Reflection , author=. 2023 , eprint=
2023
-
[5]
2023 , eprint=
Large Language Models are Better Reasoners with Self-Verification , author=. 2023 , eprint=
2023
-
[6]
2024 , eprint=
TasTe: Teaching Large Language Models to Translate through Self-Reflection , author=. 2024 , eprint=
2024
-
[7]
2025 , eprint=
Instruct-of-Reflection: Enhancing Large Language Models Iterative Reflection Capabilities via Dynamic-Meta Instruction , author=. 2025 , eprint=
2025
-
[8]
2023 , eprint=
Scaling up COMETKIWI: Unbabel-IST 2023 Submission for the Quality Estimation Shared Task , author=. 2023 , eprint=
2023
-
[9]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[10]
Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1) , pages=
Results of the WMT19 metrics shared task: Segment-level and strong MT systems pose big challenges , author=. Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1) , pages=
-
[11]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[12]
2024 , eprint=
MetricX-24: The Google Submission to the WMT 2024 Metrics Shared Task , author=. 2024 , eprint=
2024
-
[13]
2022 , eprint=
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. 2022 , eprint=
2022
-
[14]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[15]
2026 , eprint=
Enhancing Self-Correction in Large Language Models through Multi-Perspective Reflection , author=. 2026 , eprint=
2026
-
[16]
arXiv preprint arXiv:2505.12996 , year=
Extrans: Multilingual deep reasoning translation via exemplar-enhanced reinforcement learning , author=. arXiv preprint arXiv:2505.12996 , year=
-
[17]
2025 , eprint=
SlangDIT: Benchmarking LLMs in Interpretative Slang Translation , author=. 2025 , eprint=
2025
-
[18]
Gokul Swamy, Sanjiban Choudhury, Wen Sun, Zhiwei Steven Wu, and J
All roads lead to likelihood: The value of reinforcement learning in fine-tuning , author=. arXiv preprint arXiv:2503.01067 , year=
-
[19]
o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization? , author=
DeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization? , author=. arXiv preprint arXiv:2504.08120 , year=
-
[20]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
, author=
Measuring nominal scale agreement among many raters. , author=. Psychological bulletin , volume=. 1971 , publisher=
1971
-
[22]
Best-Worst Scaling More Reliable than Rating Scales: A Case Study on Sentiment Intensity Annotation
Kiritchenko, Svetlana and Mohammad, Saif. Best-Worst Scaling More Reliable than Rating Scales: A Case Study on Sentiment Intensity Annotation. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2017. doi:10.18653/v1/P17-2074
-
[23]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[24]
arXiv preprint arXiv:2402.13116 , year =
A survey on knowledge distillation of large language models , author=. arXiv preprint arXiv:2402.13116 , year=
-
[25]
Literary Machine Translation under the Magnifying Glass: Assessing the Quality of an NMT -Translated Detective Novel on Document Level
Fonteyne, Margot and Tezcan, Arda and Macken, Lieve. Literary Machine Translation under the Magnifying Glass: Assessing the Quality of an NMT -Translated Detective Novel on Document Level. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[26]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Towards reasoning era: A survey of long chain-of-thought for reasoning large language models , author=. arXiv preprint arXiv:2503.09567 , year=
work page internal anchor Pith review arXiv
-
[27]
From System 1 to System 2: A Survey of Reasoning Large Language Models
From system 1 to system 2: A survey of reasoning large language models , author=. arXiv preprint arXiv:2502.17419 , year=
work page internal anchor Pith review arXiv
-
[28]
o1-coder: an o1 replication for coding
o1-coder: an o1 replication for coding , author=. arXiv preprint arXiv:2412.00154 , year=
-
[29]
arXiv preprint arXiv:2502.01142 (2025),https://arxiv.org/abs/2502.01142
DeepRAG: Thinking to Retrieval Step by Step for Large Language Models , author=. arXiv preprint arXiv:2502.01142 , year=
-
[30]
arXiv e-prints , pages=
Drt-o1: Optimized deep reasoning translation via long chain-of-thought , author=. arXiv e-prints , pages=
-
[31]
Marco-o1: Towards open reasoning models for open-ended solutions
Marco-o1: Towards open reasoning models for open-ended solutions , author=. arXiv preprint arXiv:2411.14405 , year=
-
[32]
Evaluating o1-like llms: Unlocking reasoning for translation through comprehensive analysis
Evaluating o1-like llms: Unlocking reasoning for translation through comprehensive analysis , author=. arXiv preprint arXiv:2502.11544 , year=
-
[33]
arXiv preprint arXiv:2502.19735 , year=
R1-T1: Fully Incentivizing Translation Capability in LLMs via Reasoning Learning , author=. arXiv preprint arXiv:2502.19735 , year=
-
[34]
COMET : A Neural Framework for MT Evaluation
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[35]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models , author=. arXiv preprint arXiv:2501.03262 , year=
work page internal anchor Pith review arXiv
-
[36]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2503.10351 , year=
New Trends for Modern Machine Translation with Large Reasoning Models , author=. arXiv preprint arXiv:2503.10351 , year=
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Karpinska, Marzena and Iyyer, Mohit. Large Language Models Effectively Leverage Document-level Context for Literary Translation, but Critical Errors Persist. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.41
-
[40]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[41]
B leu: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[42]
WebGPT: Browser-assisted question-answering with human feedback
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
work page internal anchor Pith review arXiv
-
[43]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[44]
and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C
Rei, Ricardo and Treviso, Marcos and Guerreiro, Nuno M. and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C. de Souza, Jos \'e G. and Glushkova, Taisiya and Alves, Duarte and Coheur, Luisa and Lavie, Alon and Martins, Andr \'e F. T. C omet K iwi: IST -Unbabel 2022 Submission for the Quality Estimation Shared Task. Proceedings of the Sevent...
2022
-
[45]
BLEURT : Learning Robust Metrics for Text Generation
Sellam, Thibault and Das, Dipanjan and Parikh, Ankur. BLEURT : Learning Robust Metrics for Text Generation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.704
-
[46]
arXiv preprint arXiv:2411.16594 , year=
From generation to judgment: Opportunities and challenges of llm-as-a-judge , author=. arXiv preprint arXiv:2411.16594 , year=
-
[47]
MM-Eval : A multilingual meta-evaluation benchmark for LLM -as-a-judge and reward models
MM-Eval: A Multilingual Meta-Evaluation Benchmark for LLM-as-a-Judge and Reward Models , author=. arXiv preprint arXiv:2410.17578 , year=
-
[48]
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Zhu, Wenhao and Liu, Hongyi and Dong, Qingxiu and Xu, Jingjing and Huang, Shujian and Kong, Lingpeng and Chen, Jiajun and Li, Lei. Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.176
-
[49]
arXiv preprint arXiv:2504.10187 , year=
Deep Reasoning Translation via Reinforcement Learning , author=. arXiv preprint arXiv:2504.10187 , year=
-
[50]
arXiv preprint arXiv:2504.10160 , year=
MT-R1-Zero: Advancing LLM-based Machine Translation via R1-Zero-like Reinforcement Learning , author=. arXiv preprint arXiv:2504.10160 , year=
-
[51]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Search-o1: Agentic search-enhanced large reasoning models , author=. arXiv preprint arXiv:2501.05366 , year=
work page internal anchor Pith review arXiv
-
[52]
Is C hat GPT a Good NLG Evaluator? A Preliminary Study
Wang, Jiaan and Liang, Yunlong and Meng, Fandong and Sun, Zengkui and Shi, Haoxiang and Li, Zhixu and Xu, Jinan and Qu, Jianfeng and Zhou, Jie. Is C hat GPT a Good NLG Evaluator? A Preliminary Study. Proceedings of the 4th New Frontiers in Summarization Workshop. 2023. doi:10.18653/v1/2023.newsum-1.1
-
[53]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Large Language Models Are State-of-the-Art Evaluators of Translation Quality
Kocmi, Tom and Federmann, Christian. Large Language Models Are State-of-the-Art Evaluators of Translation Quality. Proceedings of the 24th Annual Conference of the European Association for Machine Translation. 2023
2023
-
[55]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[59]
doi: 10.18653/v1/2024.acl-demos.38
Zheng, Yaowei and Zhang, Richong and Zhang, Junhao and Ye, Yanhan and Luo, Zheyan. L lama F actory: Unified Efficient Fine-Tuning of 100+ Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2024. doi:10.18653/v1/2024.acl-demos.38
-
[60]
Hugging Face , year=
Qwq: Reflect deeply on the boundaries of the unknown , author=. Hugging Face , year=
-
[61]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
International Conference on Learning Representations , year=
Sequence level training with recurrent neural networks , author=. International Conference on Learning Representations , year=
-
[63]
International Conference on Learning Representations , year=
An Actor-Critic Algorithm for Sequence Prediction , author=. International Conference on Learning Representations , year=
-
[64]
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Google's neural machine translation system: Bridging the gap between human and machine translation , author=. arXiv preprint arXiv:1609.08144 , year=
work page internal anchor Pith review arXiv
-
[65]
A Study of Reinforcement Learning for Neural Machine Translation
Wu, Lijun and Tian, Fei and Qin, Tao and Lai, Jianhuang and Liu, Tie-Yan. A Study of Reinforcement Learning for Neural Machine Translation. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1397
-
[66]
Minimum Risk Training for Neural Machine Translation
Shen, Shiqi and Cheng, Yong and He, Zhongjun and He, Wei and Wu, Hua and Sun, Maosong and Liu, Yang. Minimum Risk Training for Neural Machine Translation. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1159
-
[67]
Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature
Thai, Katherine and Karpinska, Marzena and Krishna, Kalpesh and Ray, Bill and Inghilleri, Moira and Wieting, John and Iyyer, Mohit. Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.672
-
[68]
Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing , pages=
“Poetic” statistical machine translation: rhyme and meter , author=. Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing , pages=
2010
-
[69]
Proceedings of the 7th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities , pages=
The (un) faithful machine translator , author=. Proceedings of the 7th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities , pages=
-
[70]
Fourth Workshop on Computational Linguistics for Literature-co-located with NAACL 2015 , year=
Automated translation of a literary work: a pilot study , author=. Fourth Workshop on Computational Linguistics for Literature-co-located with NAACL 2015 , year=
2015
-
[71]
Frontiers in Digital Humanities , volume=
Post-editing effort of a novel with statistical and neural machine translation , author=. Frontiers in Digital Humanities , volume=. 2018 , publisher=
2018
-
[72]
On the Weaknesses of Reinforcement Learning for Neural Machine Translation , author=
-
[73]
Revisiting the Weaknesses of Reinforcement Learning for Neural Machine Translation , url=
Kiegeland, Samuel and Kreutzer, Julia. Revisiting the Weaknesses of Reinforcement Learning for Neural Machine Translation. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.133
-
[74]
Dynamic Context Selection for Document-level Neural Machine Translation via Reinforcement Learning
Kang, Xiaomian and Zhao, Yang and Zhang, Jiajun and Zong, Chengqing. Dynamic Context Selection for Document-level Neural Machine Translation via Reinforcement Learning. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.175
-
[75]
arXiv preprint arXiv:2602.18884 , year=
TPRU: Advancing Temporal and Procedural Understanding in Large Multimodal Models , author=. arXiv preprint arXiv:2602.18884 , year=
-
[76]
arXiv preprint arXiv:2602.22227 , year=
To Deceive is to Teach? Forging Perceptual Robustness via Adversarial Reinforcement Learning , author=. arXiv preprint arXiv:2602.22227 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.