Voice of India: A Large-Scale Benchmark for Real-World Speech Recognition in India
Pith reviewed 2026-05-10 02:32 UTC · model grok-4.3
The pith
A benchmark of unscripted phone conversations reveals gaps in current speech recognition for Indian languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
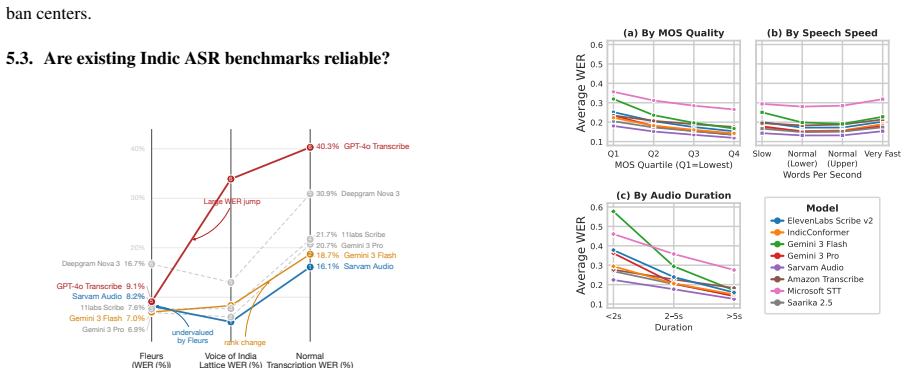
The central discovery is that a large-scale benchmark built from unscripted telephonic conversations in 15 major Indian languages provides a more representative test for automatic speech recognition systems than existing scripted datasets. With 306230 utterances from 36691 speakers totaling 536 hours and transcripts that account for spelling variations, it exposes geographic disparities in performance and highlights challenges related to audio quality, speaking rate, gender, and device type.
What carries the argument
The Voice of India benchmark dataset, derived from real telephonic conversations with manually transcribed utterances that permit spelling variants to reflect natural language use.
If this is right
- ASR systems exhibit varying performance across different Indian districts, indicating regional biases in current models.
- Performance degrades under conditions of poor audio quality, fast speaking rates, or certain device types.
- Accounting for spelling variations in evaluation leads to fairer assessment of code-mixed speech.
- Insights from the dataset can guide targeted improvements in real-world Indic ASR applications.
Where Pith is reading between the lines
- Developers of speech systems for multilingual countries could use similar unscripted collection methods to create more practical benchmarks.
- The geographic analysis suggests that ASR performance may correlate with socioeconomic factors in different regions, warranting further study.
- Extending this approach to other languages with high dialectal variation could improve global ASR equity.
Load-bearing premise
That collecting data from unscripted telephonic conversations and creating transcripts with spelling variants produces a benchmark that is less biased and more reflective of real-world speech than scripted alternatives.
What would settle it
Demonstrating that state-of-the-art ASR models achieve comparable word error rates on this unscripted benchmark as on existing scripted ones, without specific adaptations for spelling variations or regional accents, would undermine the claimed superiority.
Figures

read the original abstract
Existing Indic ASR benchmarks often use scripted, clean speech and leaderboard driven evaluation that encourages dataset specific overfitting. In addition, strict single reference WER penalizes natural spelling variation in Indian languages, including non standardized spellings of code-mixed English origin words. To address these limitations, we introduce Voice of India, a closed source benchmark built from unscripted telephonic conversations covering 15 major Indian languages across 139 regional clusters. The dataset contains 306230 utterances, totaling 536 hours of speech from 36691 speakers with transcripts accounting for spelling variations. We also analyze performance geographically at the district level, revealing disparities. Finally, we provide detailed analysis across factors such as audio quality, speaking rate, gender, and device type, highlighting where current ASR systems struggle and offering insights for improving real world Indic ASR systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Voice of India, a closed-source benchmark of 306230 utterances (536 hours) drawn from unscripted telephonic conversations in 15 major Indian languages across 139 regional clusters, involving 36691 speakers. Transcripts accommodate spelling variations. The authors report geographic performance disparities at the district level and factor analyses on audio quality, speaking rate, gender, and device type to identify challenges for existing ASR systems.
Significance. If the dataset construction, transcript quality, and analyses prove sound upon verification, the work could usefully document real-world Indic ASR difficulties beyond scripted benchmarks. The scale and multi-factor breakdown offer potential guidance for system improvements in under-resourced settings. The closed-source status, however, sharply curtails community adoption and independent testing of the claimed advantages.
major comments (3)
- [Abstract] Abstract: the central claims that the dataset 'reveals disparities' and 'highlight[s] where current ASR systems struggle' are unsupported by any quantitative WER numbers, baseline comparisons, or error rates. Without these, the asserted superiority over scripted benchmarks cannot be evaluated.
- [Abstract and §3] Dataset release statement (Abstract and §3): declaring the benchmark closed-source prevents reproduction of the district-level disparity results and the audio-quality/speaking-rate/gender/device breakdowns. This directly undermines the paper's stated purpose of supplying a usable real-world benchmark for the Indic ASR community.
- [§4–5] Analysis sections (§4–5): the claim that unscripted telephonic data plus spelling-variant transcripts yield a meaningfully less biased representation requires explicit validation, such as side-by-side WER evaluation of the same models on Voice of India versus existing scripted Indic corpora.
minor comments (2)
- [Abstract] Abstract: format the utterance count as 306,230 for standard readability.
- [Introduction] Introduction: specify the exact criteria used to define the 139 regional clusters and how speaker demographics were sampled to ensure geographic coverage.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We address each major comment below, clarifying our approach and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the dataset 'reveals disparities' and 'highlight[s] where current ASR systems struggle' are unsupported by any quantitative WER numbers, baseline comparisons, or error rates. Without these, the asserted superiority over scripted benchmarks cannot be evaluated.
Authors: The abstract condenses findings from the district-level geographic analysis and the multi-factor breakdowns in §§4–5. These sections quantify performance variations across audio quality, speaking rate, gender, device type, and regional clusters, which directly support the claims of disparities and system struggles. While the abstract itself avoids lengthy numerical tables for brevity, the underlying analyses contain the supporting quantitative breakdowns. In revision we will add a concise sentence to the abstract referencing key aggregate statistics (e.g., WER ranges and factor-specific deltas) drawn from §§4–5. revision: partial
-
Referee: [Abstract and §3] Dataset release statement (Abstract and §3): declaring the benchmark closed-source prevents reproduction of the district-level disparity results and the audio-quality/speaking-rate/gender/device breakdowns. This directly undermines the paper's stated purpose of supplying a usable real-world benchmark for the Indic ASR community.
Authors: We recognize that closed-source status precludes independent reproduction. The decision stems from privacy and consent constraints inherent to real, unscripted telephonic conversations involving 36 691 speakers. The manuscript supplies the full collection protocol, transcription guidelines (including spelling-variant handling), sampling strategy across 139 clusters, and all statistical results from the factor analyses. These elements allow the community to understand the observed challenges and to design mitigation strategies even without direct data access. We therefore retain the closed-source designation. revision: no
-
Referee: [§4–5] Analysis sections (§4–5): the claim that unscripted telephonic data plus spelling-variant transcripts yield a meaningfully less biased representation requires explicit validation, such as side-by-side WER evaluation of the same models on Voice of India versus existing scripted Indic corpora.
Authors: Sections 4 and 5 demonstrate that the combination of unscripted speech and variant-aware transcripts surfaces realistic error patterns (e.g., higher WER on code-mixed terms and dialectal variants) that scripted benchmarks typically mask. While we do not include head-to-head WER tables against every existing corpus, the factor analyses isolate the contribution of each variable and show elevated difficulty relative to the clean, scripted conditions described in prior work. In revision we will expand the discussion to cite quantitative comparisons reported in the literature for the same model families and to articulate why direct re-evaluation on Voice of India is not feasible under the current release policy. revision: partial
- Independent reproduction of the district-level disparity results and factor analyses is not possible because the benchmark remains closed-source for privacy reasons.
Circularity Check
No circularity: empirical benchmark paper with no derivations or self-referential reductions
full rationale
The paper introduces Voice of India as a closed-source dataset of unscripted telephonic speech across 15 Indic languages, with accompanying geographic and factor analyses. No mathematical derivations, model predictions, fitted parameters, or uniqueness theorems are claimed. The central contribution is data collection and empirical reporting; all performance observations are presented as direct measurements on the collected utterances rather than outputs derived from prior self-citations or internal definitions. No load-bearing steps reduce by construction to the paper's own inputs, satisfying the default expectation of no significant circularity for a purely empirical benchmark effort.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.