Recognition: unknown
UAF: A Unified Audio Front-end LLM for Full-Duplex Speech Interaction
Pith reviewed 2026-05-10 03:01 UTC · model grok-4.3
The pith
A single auto-regressive LLM unifies voice activity detection, turn-taking, speaker recognition, transcription and interruption signals for full-duplex speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
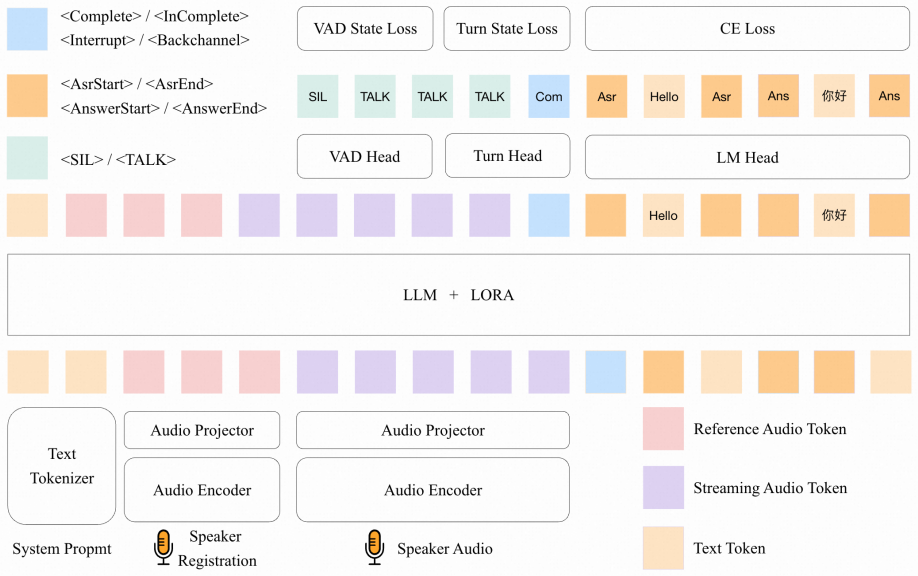
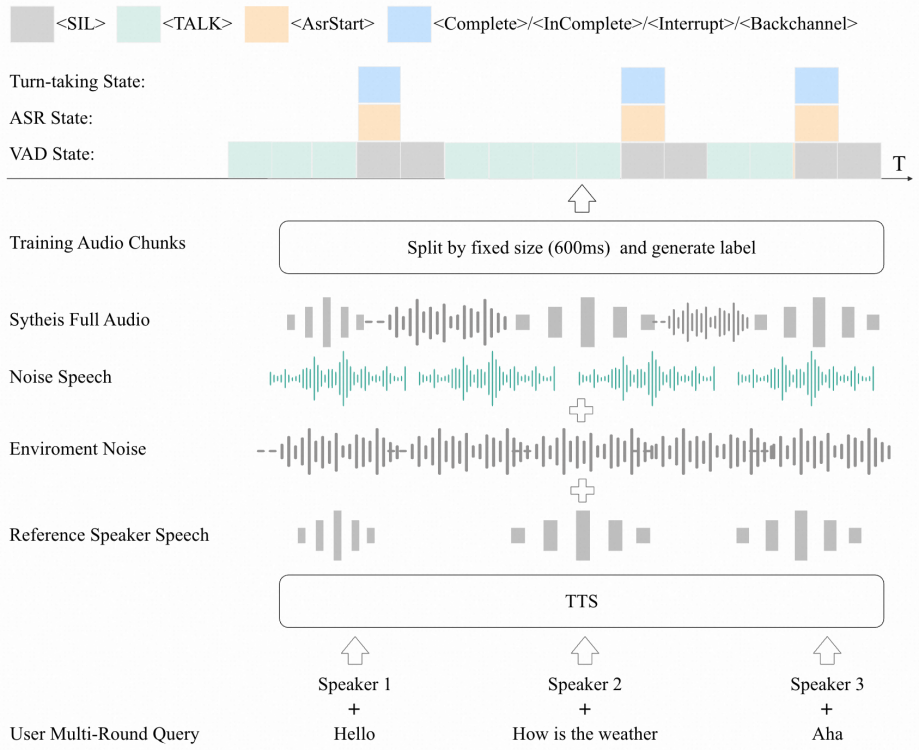
We propose the first unified audio front-end LLM (UAF) tailored for full-duplex speech systems. Our model reformulates diverse audio front-end tasks into a single auto-regressive sequence prediction problem, including VAD, TD, speaker recognition (SR), automatic speech recognition (ASR) and question answer (QA). It takes streaming fixed-duration audio chunk (e.g., 600 ms) as input, leverages a reference audio prompt to anchor the target speaker at the beginning, and regressively generates discrete tokens encoding both semantic content and system-level state controls (e.g., interruption signals). Experiments demonstrate that our model achieves leading performance across multiple audio front-
What carries the argument
Auto-regressive token generation over fixed-length audio chunks conditioned on a reference prompt, which simultaneously encodes semantic content and discrete system control signals.
If this is right
- Leading performance on multiple audio front-end tasks without separate modules.
- Lower response latency and higher interruption accuracy in real full-duplex scenarios.
- Elimination of error propagation and information loss that occur in cascaded pipelines.
- Direct generation of both content and control tokens from the same sequence model.
Where Pith is reading between the lines
- The token output format could allow the front-end to be jointly optimized with a back-end language model for fully end-to-end spoken agents.
- The reference-prompt mechanism might be extended to support dynamic speaker tracking without a fixed enrollment sample.
- Unified front-end modeling could reduce total system compute if one model replaces several task-specific networks.
Load-bearing premise
A single auto-regressive LLM can effectively unify and outperform specialized components on diverse tasks while the reference audio prompt sufficiently anchors the target speaker in streaming chunks.
What would settle it
A controlled streaming test in which the unified model produces higher error rates on voice activity detection or turn-taking decisions than current separate specialized modules when given identical live audio.
Figures

read the original abstract
Full-duplex speech interaction, as the most natural and intuitive mode of human communication, is driving artificial intelligence toward more human-like conversational systems. Traditional cascaded speech processing pipelines suffer from critical limitations, including accumulated latency, information loss, and error propagation across modules. To address these issues, recent efforts focus on the end-to-end audio large language models (LLMs) like GPT-4o, which primarily unify speech understanding and generation task. However, most of these models are inherently half-duplex, and rely on a suite of separate, task-specific front-end components, such as voice activity detection (VAD) and turn-taking detection (TD). In our development of speech assistant, we observed that optimizing the speech front-end is equally crucial as advancing the back-end unified model for achieving seamless, responsive interactions. To bridge this gap, we propose the first unified audio front-end LLM (UAF) tailored for full-duplex speech systems. Our model reformulates diverse audio front-end tasks into a single auto-regressive sequence prediction problem, including VAD, TD, speaker recognition (SR), automatic speech recognition (ASR) and question answer (QA). It takes streaming fixed-duration audio chunk (e.g., 600 ms) as input, leverages a reference audio prompt to anchor the target speaker at the beginning, and regressively generates discrete tokens encoding both semantic content and system-level state controls (e.g., interruption signals). Experiments demonstrate that our model achieves leading performance across multiple audio front-end tasks and significantly enhances response latency and interruption accuracy in real-world interaction scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UAF, the first unified audio front-end LLM for full-duplex speech systems. It reformulates diverse front-end tasks (VAD, TD, SR, ASR, QA) as a single autoregressive sequence prediction problem. The model ingests streaming fixed-duration audio chunks (e.g., 600 ms), conditions on a reference audio prompt to anchor the target speaker, and generates discrete tokens that encode both semantic content and system-level controls such as interruption signals. Experiments are reported to demonstrate leading performance across these tasks together with reduced response latency and improved interruption accuracy in real-world full-duplex scenarios.
Significance. If the empirical results hold, the work offers a coherent reformulation that could reduce the latency, information loss, and error propagation inherent in cascaded front-end pipelines while enabling tighter integration with back-end audio LLMs. The use of a fixed reference prompt for speaker anchoring and the joint prediction of semantic and control tokens constitute a practical unification that addresses a recognized gap between current half-duplex models and true full-duplex interaction.
major comments (2)
- [Abstract] Abstract: the central claim that the model 'achieves leading performance across multiple audio front-end tasks' is unsupported by any quantitative metrics, baselines, dataset descriptions, error bars, or ablation results. Without these, it is impossible to assess whether the unification actually outperforms specialized components or merely matches them.
- [Experiments] Experiments section (inferred from the abstract's performance claims): the reported gains in 'response latency and interruption accuracy' lack any comparison to strong cascaded baselines or ablations that isolate the contribution of the reference prompt versus the autoregressive formulation. This information is load-bearing for the claim that a single LLM can unify and improve upon task-specific modules.
minor comments (2)
- [Introduction] Introduction: the description of how the reference audio prompt is selected and maintained across streaming chunks should be expanded to clarify robustness under speaker changes or noisy conditions.
- [Model] Model architecture: provide the precise vocabulary size and tokenization scheme used for the system-level control tokens (e.g., interruption signals) so that the autoregressive objective is fully reproducible.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our paper. We address the major comments point by point below and have updated the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the model 'achieves leading performance across multiple audio front-end tasks' is unsupported by any quantitative metrics, baselines, dataset descriptions, error bars, or ablation results. Without these, it is impossible to assess whether the unification actually outperforms specialized components or merely matches them.
Authors: We thank the referee for pointing this out. The abstract as submitted summarizes our experimental findings at a high level without embedding the specific quantitative details. In the revised manuscript, we have updated the abstract to include key quantitative metrics demonstrating leading performance, references to the datasets used, baseline comparisons, error bars where applicable, and mention of ablation studies. This ensures the central claim is supported within the abstract. revision: yes
-
Referee: [Experiments] Experiments section (inferred from the abstract's performance claims): the reported gains in 'response latency and interruption accuracy' lack any comparison to strong cascaded baselines or ablations that isolate the contribution of the reference prompt versus the autoregressive formulation. This information is load-bearing for the claim that a single LLM can unify and improve upon task-specific modules.
Authors: We agree that explicit comparisons and ablations are important for substantiating the advantages of our unified model. We have revised the experiments section to include detailed comparisons against strong cascaded baselines for response latency and interruption accuracy. Additionally, we have incorporated new ablation studies that isolate the contributions of the reference audio prompt and the autoregressive sequence prediction approach. These revisions provide the necessary evidence to support the unification claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents UAF as an empirical modeling proposal that reformulates front-end tasks (VAD, TD, SR, ASR, QA) as autoregressive token prediction on streaming audio chunks with a reference prompt; no equations, derivations, or parameter-fitting steps are described that reduce any performance claim to quantities defined by the model's own fitted outputs or prior self-citations. The central claims rest on experimental outcomes rather than analytical reductions, making the work self-contained against external benchmarks with no load-bearing self-referential loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diverse audio front-end tasks can be reformulated as a single auto-regressive sequence prediction problem using discrete tokens for both semantics and system controls.
Reference graph
Works this paper leans on
-
[1]
Tyers, and Gregor Weber
Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber. Common voice: A massively-multilingual speech corpus, 2020
2020
-
[2]
Whisperx: Time-accurate speech transcription of long-form audio.INTERSPEECH 2023, 2023
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. Whisperx: Time-accurate speech transcription of long-form audio.INTERSPEECH 2023, 2023
2023
-
[3]
Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline, 2017
Hui Bu, Jiayu Du, Xingyu Na, Bengu Wu, and Hao Zheng. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline, 2017
2017
-
[4]
Junjie Chen, Yao Hu, Junjie Li, Kangyue Li, Kun Liu, Wenpeng Li, Xu Li, Ziyuan Li, Feiyu Shen, Xu Tang, Manzhen Wei, Yichen Wu, Fenglong Xie, Kaituo Xu, and Kun Xie. Fireredchat: A pluggable, full-duplex voice interaction system with cascaded and semi-cascaded implementations.arXiv preprint arXiv:2509.06502, 2025
-
[5]
3d-speaker-toolkit: An open source toolkit for multi-modal speaker verification and diarization, 2025
Yafeng Chen, Siqi Zheng, Hui Wang, Luyao Cheng, et al. 3d-speaker-toolkit: An open source toolkit for multi-modal speaker verification and diarization, 2025
2025
-
[6]
Qwen2-audio technical report, 2024
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report, 2024
2024
-
[7]
Fleurs: Few-shot learning evaluation of universal representations of speech,
Alexis Conneau, Min Ma, Simran Khanuja, Yu Zhang, Vera Axelrod, Siddharth Dalmia, Jason Riesa, Clara Rivera, and Ankur Bapna. Fleurs: Few-shot learning evaluation of universal representations of speech.arXiv preprint arXiv:2205.12446, 2022
-
[8]
Moshi: a speech-text foundation model for real-time dialogue, 2024
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue, 2024
2024
-
[9]
Aishell-2: Transforming mandarin asr research into industrial scale, 2018
Jiayu Du, Xingyu Na, Xuechen Liu, and Hui Bu. Aishell-2: Transforming mandarin asr research into industrial scale, 2018. 12
2018
-
[10]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Xian Shi, Keyu An, et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training.arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
TurnGPT: a transformer-based language model for predicting turn-taking in spoken dialog
Erik Ekstedt and Gabriel Skantze. TurnGPT: a transformer-based language model for predicting turn-taking in spoken dialog. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 2981–2990, Online, November 2020. Association for Computational Linguistics
2020
-
[12]
Vita: Towards open-source interactive omni multimodal llm
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Meng Zhao, Yifan Zhang, Xiong Wang, Di Yin, Long Ma, Xiawu Zheng, et al. Vita: Towards open-source interactive omni multimodal llm.arXiv preprint arXiv:2408.05211, 2024
-
[13]
Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition
Zhifu Gao, Shiliang Zhang, Ian McLoughlin, and Zhijie Yan. Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition. InINTERSPEECH, 2022
2022
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021
2021
-
[15]
Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie. Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement.arXiv preprint arXiv:2008.00264, 2020
-
[16]
Step-audio: Unified understanding and generation in intelligent speech interaction, 2025
Ailin Huang, Boyong Wu, Bruce Wang, Chao Yan, Chen Hu, Chengli Feng, Fei Tian, Feiyu Shen, Jingbei Li, Mingrui Chen, Peng Liu, Ruihang Miao, Wang You, Xi Chen, Xuerui Yang, Yechang Huang, Yuxiang Zhang, Zheng Gong, Zixin Zhang, Hongyu Zhou, Jianjian Sun, Brian Li, Chengting Feng, Changyi Wan, Hanpeng Hu, Jianchang Wu, Jiangjie Zhen, Ranchen Ming, Song Yua...
2025
-
[17]
A study of endpoint detection algorithms in adverse conditions: incidence on a dtw and hmm recognizer
Jean-Claude Junqua, Ben Reaves, and Brian Kan-Wing Mak. A study of endpoint detection algorithms in adverse conditions: incidence on a dtw and hmm recognizer. InEUROSPEECH, 1991
1991
-
[18]
Dnn-based voice activity detection with multi-task learning.IEICE Trans
Tae Gyoon Kang and Nam Soo Kim. Dnn-based voice activity detection with multi-task learning.IEICE Trans. Inf. Syst., 99-D:550–553, 2016
2016
-
[19]
KimiTeam, Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, Zhengtao Wang, Chu Wei, Yifei Xin, Xinran Xu, Jianwei Yu, Yutao Zhang, Xinyu Zhou, Y . Charles, Jun Chen, Yanru Chen, Yulun Du, Weiran He, Zhenxing Hu, Guokun Lai, Qingcheng Li, Yangyang Liu, Weidong Sun, Jianzhou Wang, Yuzhi Wang, Yue...
2025
-
[20]
Easy turn: Integrating acoustic and linguistic modalities for robust turn-taking in full-duplex spoken dialogue systems, 2025
Guojian Li, Chengyou Wang, Hongfei Xue, Shuiyuan Wang, Dehui Gao, Zihan Zhang, Yuke Lin, Wenjie Li, Longshuai Xiao, Zhonghua Fu, and Lei Xie. Easy turn: Integrating acoustic and linguistic modalities for robust turn-taking in full-duplex spoken dialogue systems, 2025
2025
-
[21]
Flexduo: A pluggable system for enabling full-duplex capabilities in speech dialogue systems, 2025
Borui Liao, Yulong Xu, Jiao Ou, Kaiyuan Yang, Weihua Jian, Pengfei Wan, and Di Zhang. Flexduo: A pluggable system for enabling full-duplex capabilities in speech dialogue systems, 2025
2025
-
[22]
V oxceleb: A large-scale speaker identification dataset, 2017
Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. V oxceleb: A large-scale speaker identification dataset, 2017
2017
-
[23]
Hello gpt-4o.https://openai.com/index/hello-gpt-4o/, 2024
OpenAI. Hello gpt-4o.https://openai.com/index/hello-gpt-4o/, 2024
2024
-
[24]
Examination of energy based voice activity detection algorithms for noisy speech signals
Selma Özaydin. Examination of energy based voice activity detection algorithms for noisy speech signals. European Journal of Science and Technology, 2019. 13
2019
-
[25]
Low-complexity voice activity detector using periodicity and energy ratio
Kirill Sakhnov, Ekaterina Verteletskaya, and Boris Simak. Low-complexity voice activity detector using periodicity and energy ratio. In2009 16th International Conference on Systems, Signals and Image Processing, pages 1–5, 2009
2009
-
[26]
Musan: A music, speech, and noise corpus, 2015
David Snyder, Guoguo Chen, and Daniel Povey. Musan: A music, speech, and noise corpus, 2015
2015
-
[27]
SALMONN: Towards generic hearing abilities for large language models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun MA, and Chao Zhang. SALMONN: Towards generic hearing abilities for large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[28]
Kespeech: An open source speech dataset of mandarin and its eight subdialects
Zhiyuan Tang, Dong Wang, Yanguang Xu, Jianwei Sun, Xiaoning Lei, Shuaijiang Zhao, Cheng Wen, Xingjun Tan, Chuandong Xie, Shuran Zhou, Rui Yan, Chenjia Lv, Yang Han, Wei Zou, and Xiangang Li. Kespeech: An open source speech dataset of mandarin and its eight subdialects. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchma...
2021
-
[29]
Mimo-audio: Audio language models are few-shot learners, 2025
Core Team, Dong Zhang, Gang Wang, Jinlong Xue, Kai Fang, Liang Zhao, Rui Ma, Shuhuai Ren, Shuo Liu, Tao Guo, Weiji Zhuang, Xin Zhang, Xingchen Song, Yihan Yan, Yongzhe He, Cici, Bowen Shen, Chengxuan Zhu, Chong Ma, Chun Chen, Heyu Chen, Jiawei Li, Lei Li, Menghang Zhu, Peidian Li, Qiying Wang, Sirui Deng, Weimin Xiong, Wenshan Huang, Wenyu Yang, Yilin Jia...
2025
-
[30]
Longcat-flash-omni technical report, 2025
Meituan LongCat Team, Bairui Wang, Bayan, Bin Xiao, Bo Zhang, Bolin Rong, Borun Chen, Chang Wan, Chao Zhang, Chen Huang, Chen Chen, Chen Chen, Chengxu Yang, Chengzuo Yang, Cong Han, Dandan Peng, Delian Ruan, Detai Xin, Disong Wang, Dongchao Yang, Fanfan Liu, Fengjiao Chen, Fengyu Yang, Gan Dong, Gang Huang, Gang Xu, Guanglu Wan, Guoqiang Tan, Guoqiao Yu, ...
2025
-
[31]
Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier.https://github.com/snakers4/silero-vad, 2024
Silero Team. Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier.https://github.com/snakers4/silero-vad, 2024
2024
-
[32]
Ten vad: A low-latency, lightweight and high-performance streaming voice activity detector (vad)
TEN Team. Ten vad: A low-latency, lightweight and high-performance streaming voice activity detector (vad). https://github.com/TEN-framework/ten-vad.git, 2025
2025
-
[33]
Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen llm, 2024
Xiong Wang, Yangze Li, Chaoyou Fu, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long Ma. Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen llm, 2024
2024
-
[34]
Qwen2.5-omni technical report, 2025
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025
2025
-
[35]
Qwen3-omni technical report, 2025
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
2025
-
[36]
Speakerlm: End-to-end versatile speaker diarization and recognition with multimodal large language models, 2026
Han Yin, Yafeng Chen, Chong Deng, Luyao Cheng, Hui Wang, Chao-Hong Tan, Qian Chen, Wen Wang, and Xiangang Li. Speakerlm: End-to-end versatile speaker diarization and recognition with multimodal large language models, 2026. 14
2026
-
[37]
Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot, 2024
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot, 2024
2024
-
[38]
Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition, 2022
Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, Di Wu, and Zhendong Peng. Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition, 2022
2022
-
[39]
Omniflatten: An end-to-end gpt model for seamless voice conversation, 2025
Qinglin Zhang, Luyao Cheng, Chong Deng, Qian Chen, Wen Wang, Siqi Zheng, Jiaqing Liu, Hai Yu, Chaohong Tan, Zhihao Du, and Shiliang Zhang. Omniflatten: An end-to-end gpt model for seamless voice conversation, 2025
2025
-
[40]
Deep-fsmn for large vocabulary continuous speech recognition.2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5869–5873, 2018
Shiliang Zhang, Ming Lei, Zhijie Yan, and Lirong Dai. Deep-fsmn for large vocabulary continuous speech recognition.2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5869–5873, 2018
2018
-
[41]
Shiliang Zhang, Cong Liu, Hui Jiang, Si Wei, Lirong Dai, and Yu Hu. Feedforward sequential memory networks: A new structure to learn long-term dependency.ArXiv, abs/1512.08301, 2015. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.