Recognition: unknown
IndiaFinBench: An Evaluation Benchmark for Large Language Model Performance on Indian Financial Regulatory Text
Pith reviewed 2026-05-10 02:37 UTC · model grok-4.3
The pith
IndiaFinBench supplies the first public set of expert questions for testing large language models on Indian financial regulatory text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
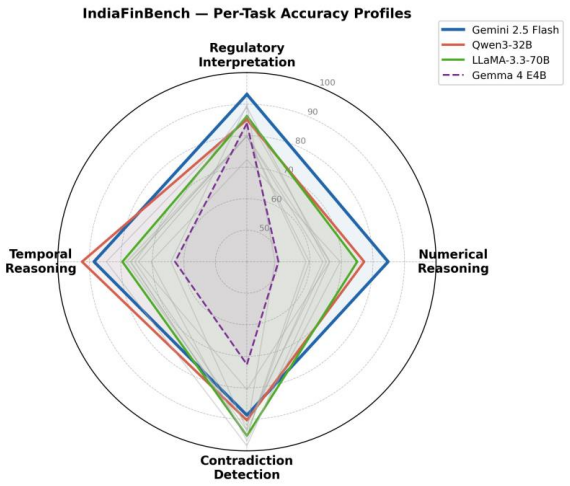
The paper establishes IndiaFinBench as a dataset of 406 expert-annotated question-answer pairs sourced from Indian financial regulatory documents, divided into regulatory interpretation, numerical reasoning, contradiction detection, and temporal reasoning. Zero-shot evaluation of twelve models yields accuracies from 70.4 percent to 89.7 percent, with every model exceeding the 69.0 percent score of non-specialist humans. Numerical reasoning produces the widest performance spread of 35.9 percentage points, and bootstrap resampling identifies three statistically separable model tiers.
What carries the argument
IndiaFinBench, the benchmark of 406 expert-annotated QA pairs spanning four task types drawn from Indian financial regulatory documents.
If this is right
- Model capability on Indian regulatory text can now be measured and ranked in a standardized way.
- Numerical reasoning stands out as the task that most sharply distinguishes stronger from weaker models.
- All tested models already exceed non-specialist human performance, indicating immediate applicability in regulatory analysis.
- The three identified performance tiers provide a stable grouping for future model comparisons.
Where Pith is reading between the lines
- The same task structure could be replicated for regulatory text from other countries to test whether current performance patterns hold beyond one jurisdiction.
- Model developers could target improvements on the numerical and temporal tasks where spreads are largest.
- Regulators might adopt similar annotated sets to evaluate AI tools intended for compliance review.
Load-bearing premise
The selected 406 question-answer pairs adequately represent Indian financial regulatory text and the annotations form a stable gold standard.
What would settle it
A fresh round of expert annotations on the same documents that produces low agreement with the original labels or reverses the model performance ordering would undermine the benchmark.
Figures



read the original abstract
We introduce IndiaFinBench, to our knowledge the first publicly available evaluation benchmark for assessing large language model (LLM) performance on Indian financial regulatory text. Existing financial NLP benchmarks draw exclusively from Western financial corpora (SEC filings, US earnings reports, English-language financial news), leaving a significant gap in coverage of non-Western regulatory frameworks. IndiaFinBench addresses this gap with 406 expert-annotated question-answer pairs drawn from 192 documents sourced from the Securities and Exchange Board of India (SEBI) and the Reserve Bank of India (RBI), spanning four task types: regulatory interpretation (174 items), numerical reasoning (92 items), contradiction detection (62 items), and temporal reasoning (78 items). Annotation quality is validated through a model-based secondary pass (kappa=0.918 on contradiction detection; 90.7% overall agreement on a 150-item subset) and a 180-item human inter-annotator agreement study across three annotation rounds (kappa=0.645 on contradiction detection; 77.2% overall agreement; 44.3% benchmark coverage). We evaluate twelve models under zero-shot conditions, with accuracy ranging from 70.4% (Gemma 4 E4B) to 89.7% (Gemini 2.5 Flash). All models substantially outperform a non-specialist human baseline of 69.0%. Numerical reasoning is the most discriminative task, with a 35.9 percentage-point spread across models. Bootstrap significance testing (10,000 resamples) reveals three statistically distinct performance tiers. The dataset, evaluation code, and all model outputs are available at https://github.com/rajveerpall/IndiaFinBench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IndiaFinBench, claimed as the first public benchmark for LLM performance on Indian financial regulatory text. It consists of 406 expert-annotated QA pairs from 192 SEBI and RBI documents across four tasks: regulatory interpretation (174 items), numerical reasoning (92 items), contradiction detection (62 items), and temporal reasoning (78 items). Annotation quality is supported by model-based secondary validation (kappa=0.918 on a 150-item subset) and human inter-annotator agreement on a 180-item subset (overall 77.2% agreement, kappa=0.645 on contradiction detection). Twelve LLMs are evaluated in zero-shot settings with accuracies from 70.4% (Gemma 4 E4B) to 89.7% (Gemini 2.5 Flash), all outperforming a 69.0% non-specialist human baseline; numerical reasoning shows the largest performance spread. Bootstrap significance testing (10,000 resamples) identifies three performance tiers. The dataset, code, and model outputs are released publicly.
Significance. If the annotations hold as a reliable gold standard, the benchmark fills a documented gap in financial NLP resources, which have been limited to Western corpora. The public release of the full dataset, evaluation code, and all model outputs is a clear strength that enables direct reproducibility and extension by the community. The bootstrap testing and per-task breakdowns provide additional empirical rigor beyond simple accuracy reporting. This could serve as a foundation for domain-specific LLM evaluation in non-Western regulatory contexts.
major comments (1)
- [Annotation Quality Validation] Annotation Quality section (human IAA study): The human inter-annotator agreement is limited to a 180-item subset (44.3% coverage of the 406 pairs), with kappa=0.645 specifically on the 62 contradiction-detection items. This leaves the 174 regulatory-interpretation and 92 numerical-reasoning items without direct multi-annotator reliability data, and the moderate kappa on the hardest task raises the possibility of label noise that could systematically affect measured LLM accuracies. Because the central utility of the benchmark rests on the annotations constituting a trustworthy gold standard, this partial validation requires either expanded human IAA or a more detailed justification of why the subset suffices.
minor comments (2)
- [Results] The per-task item counts and model accuracy breakdowns are stated in the abstract but should be presented in a dedicated table in the main text for easier reference during evaluation discussion.
- [Dataset Construction] Clarify whether the regulatory documents are in English or include Hindi/Indian-language text, as this affects the benchmark's scope for multilingual LLM evaluation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive evaluation of the benchmark's contribution. We address the major comment on annotation quality validation below, providing additional context and committing to targeted revisions in the manuscript.
read point-by-point responses
-
Referee: [Annotation Quality Validation] Annotation Quality section (human IAA study): The human inter-annotator agreement is limited to a 180-item subset (44.3% coverage of the 406 pairs), with kappa=0.645 specifically on the 62 contradiction-detection items. This leaves the 174 regulatory-interpretation and 92 numerical-reasoning items without direct multi-annotator reliability data, and the moderate kappa on the hardest task raises the possibility of label noise that could systematically affect measured LLM accuracies. Because the central utility of the benchmark rests on the annotations constituting a trustworthy gold standard, this partial validation requires either expanded human IAA or a more detailed justification of why the subset suffices.
Authors: We appreciate the referee's emphasis on ensuring the annotations form a reliable gold standard. The 180-item human IAA subset was deliberately constructed to be representative, proportionally sampling from all four tasks while oversampling the contradiction detection items (the most ambiguous task) to maximize coverage of potential disagreement sources. Annotations for the full benchmark were performed by domain experts following a multi-round protocol, with a separate model-based secondary validation (kappa=0.918) applied to a 150-item subset that overlaps with the human study. We acknowledge that direct multi-annotator data is not available for every item and that the moderate kappa on contradiction detection indicates some inherent task difficulty. In the revised manuscript, we will expand the Annotation Quality section with: (i) explicit per-task coverage details for the IAA subset, (ii) a clearer rationale for subset selection and its representativeness, and (iii) a brief discussion of how any residual label noise might influence the observed LLM performance gaps (particularly noting that numerical reasoning remains the most discriminative task). Full expansion of human IAA to all 406 items is not feasible at this stage due to resource constraints, but the combined expert + model validation supports the benchmark's current utility. revision: partial
Circularity Check
No circularity: benchmark curation and empirical evaluation are self-contained
full rationale
The paper introduces IndiaFinBench as a new dataset of 406 expert-annotated QA pairs drawn from SEBI and RBI documents, then reports zero-shot accuracies for twelve LLMs plus a human baseline. No equations, fitted parameters, or predictions appear anywhere in the manuscript. Annotation quality is assessed via separate human IAA on a 180-item subset and a model-based pass on a 150-item subset, but these are reported as empirical observations rather than inputs that are redefined as outputs. No self-citations are load-bearing for any derivation, and the central claim (first public benchmark for this domain) rests on the act of public release itself, not on any reduction to prior fitted results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert annotations provide a reliable ground truth for LLM evaluation on regulatory text
Reference graph
Works this paper leans on
-
[1]
Chen, Z., et al. (2021). FinQA: A Dataset of Numerical Reasoning over Financial Data. EMNLP
2021
-
[2]
Chalkidis, I., et al. (2022). LexGLUE: A Benchmark Dataset for Legal Language Understanding in English. ACL
2022
-
[3]
Dua, D., et al. (2019). DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs. NAACL
2019
-
[4]
Islam, S., et al. (2023). FinanceBench: A New Benchmark for Financial Question Answering. arXiv:2311.11944. Landis, J.R., & Koch, G.G. (1977). The measurement of observer agreement for categorical data. Biometrics, 33(1), 159–174. Liang, P., et al. (2022). Holistic Evaluation of Language Models. NeurIPS 2022 (HELM). Loukas, L., et al. (2022). FiNER-139: A...
-
[5]
Malik, V., et al. (2021). ILDC for CJPE: Indian Legal Documents Corpus for Court Judgment Prediction and Explanation. ACL
2021
-
[6]
Rajpurkar, P., et al. (2016). SQuAD: 100,000+ Questions for Machine Comprehension of Text. EMNLP
2016
-
[7]
Shah, A., et al. (2022). FLUE: Financial Language Understanding Evaluation. EMNLP
2022
-
[8]
Wilson, E.B. (1927). Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22(158), 209–212. Zheng, Z., et al. (2022). ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. EMNLP
1927
-
[9]
Appendix A: Source Document Categories SEBI Documents: SEBI (Issue of Capital and Disclosure Requirements) Regulations 2018, SEBI (Listing Obligations and Disclosure Requirements) Regulations 2015, SEBI (Substantial Acquisition of Shares and Takeovers) Regulations 2011, SEBI (Prohibition of Insider Trading) Regulations 2015, SEBI (Alternative Investment F...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.