Recognition: unknown
RDP LoRA: Geometry-Driven Identification for Parameter-Efficient Adaptation in Large Language Models
Pith reviewed 2026-05-10 02:23 UTC · model grok-4.3
The pith
RDP simplification of hidden-state trajectories selects 13 layers whose LoRA adaptation outperforms both full and random layer choices on math benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The evolution of hidden states across layers forms a high-dimensional trajectory; the Ramer-Douglas-Peucker algorithm extracts its essential breakpoints, and these breakpoints serve as the precise layers to adapt with LoRA. On the Qwen3-8B-Base model this geometry-driven choice of 13 layers produces 81.67 percent accuracy on MMLU-Math, exceeding the accuracy obtained by adapting every layer (79.32 percent) or by random selection of the same number of layers (75.56 percent).
What carries the argument
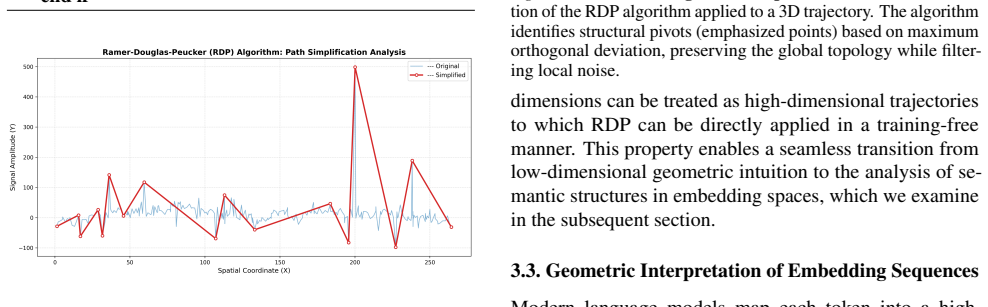
The Ramer-Douglas-Peucker algorithm applied to the sequence of hidden-state vectors across layers, which simplifies the trajectory by removing locally redundant points while preserving global structural transitions and thereby identifies the layers whose adaptation yields the largest gains.
If this is right
- A small number of layers selected by geometry suffices to exceed the performance of adapting every layer.
- Layer choice for LoRA can be decided from a single forward pass without any gradient computation or validation search.
- The same geometric signal improves results over random selection, indicating that the breakpoints carry task-relevant information.
- The approach supplies an explicit, visualizable criterion for deciding adaptation locations inside any transformer stack.
Where Pith is reading between the lines
- The same trajectory-simplification step could be used to decide which layers to prune or to quantize with minimal loss.
- If geometric breakpoints align with functional specialization, the method may reveal why certain layers contribute more to mathematical reasoning than to other capabilities.
- Extending the analysis to intermediate checkpoints during pre-training might show how representation geometry changes as models acquire new skills.
Load-bearing premise
The structural turns found by simplifying the hidden-state trajectory mark the layers whose adaptation produces the largest performance improvement on the target task.
What would settle it
Applying the identical RDP procedure to a different model or task and observing that the selected layers fail to outperform both full-layer adaptation and random selection of the same count.
Figures




read the original abstract
Fine-tuning Large Language Models (LLMs) remains structurally uncertain despite parameter-efficient methods such as Low-Rank Adaptation (LoRA), as the layer-specific roles of internal representations are poorly understood, leading to heuristic decisions about where adaptation should be applied. We model the evolution of hidden states as a high-dimensional geometric trajectory and propose using the Ramer-Douglas-Peucker (RDP) algorithm, a parameter-free and training-free polygon simplification method that preserves global structural transitions while eliminating locally redundant changes, to identify critical breakpoints along the representation path. Crucially, we use these geometric pivots not merely for analysis, but as a direct decision signal for determining which layers should be adapted during parameter-efficient fine-tuning. By integrating this geometry-aware layer selection strategy into LoRA fine-tuning of Qwen3-8B-Base, we achieve superior performance on MMLU-Math using only 13 RDP-selected layers (81.67%), significantly outperforming both full 36-layer adaptation (79.32%) and random 13-layer selection (75.56%), as well as the baseline Qwen3-8B-Base model (74.25%). These results demonstrate that leveraging the intrinsic geometry of representation trajectories provides a robust, interpretable, and training-free signal for optimizing layer selection during model adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RDP LoRA, which applies the Ramer-Douglas-Peucker (RDP) polygon simplification algorithm to the high-dimensional trajectory of hidden-state activations across layers in an LLM. The resulting geometric breakpoints are used as a training-free, parameter-free signal to select a subset of layers for LoRA adaptation. On Qwen3-8B-Base fine-tuned for MMLU-Math, the method reports 81.67% accuracy using only 13 RDP-selected layers, outperforming full 36-layer adaptation (79.32%), random 13-layer selection (75.56%), and the untuned base model (74.25%).
Significance. If the geometric breakpoints reliably identify layers whose adaptation yields the largest task gains, the approach supplies an interpretable, zero-cost alternative to heuristic or exhaustive layer selection in parameter-efficient fine-tuning. The parameter-free and training-free character of the RDP step is a clear strength that distinguishes it from learned or gradient-based selection methods.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): the headline accuracies (81.67 % vs. 79.32 %) are single-run point estimates with no reported standard deviations, multiple random seeds, or statistical tests. Because LoRA training is stochastic, the 2.35 pp margin cannot be distinguished from optimizer or data-ordering noise, directly weakening the central claim that RDP selection is superior to full adaptation.
- [§3.2] §3.2 (RDP Layer Selection): the mapping from geometric breakpoints to performance-critical layers rests on the unverified assumption that RDP pivots coincide with layers whose adaptation produces the largest task-specific gains. No ablation isolating this correspondence, no theoretical argument, and no cross-task or cross-model validation are provided to support the assumption.
minor comments (2)
- [§3.1] Notation for the RDP tolerance parameter and the precise definition of the hidden-state trajectory (e.g., which token positions or pooling are used) should be stated explicitly in §3.1 to allow exact reproduction.
- [§4] The manuscript should clarify whether the reported MMLU-Math numbers use the standard 5-shot or 0-shot protocol and whether any prompt formatting differences exist across the compared conditions.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback. We address each major comment point by point below, acknowledging limitations in the current experiments and outlining specific revisions to strengthen the statistical evidence and empirical support for the layer-selection assumption.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the headline accuracies (81.67 % vs. 79.32 %) are single-run point estimates with no reported standard deviations, multiple random seeds, or statistical tests. Because LoRA training is stochastic, the 2.35 pp margin cannot be distinguished from optimizer or data-ordering noise, directly weakening the central claim that RDP selection is superior to full adaptation.
Authors: We agree that the reported accuracies are single-run point estimates and that the absence of standard deviations, multiple seeds, or statistical tests limits the strength of the claim. LoRA training is indeed stochastic, so the 2.35 pp difference could partly reflect noise. In the revised manuscript we will rerun the experiments with at least five independent random seeds, report mean accuracies together with standard deviations, and include paired statistical tests (e.g., Welch’s t-test) comparing RDP selection against both full adaptation and random selection. These additions will be placed in §4 and referenced in the abstract. revision: yes
-
Referee: [§3.2] §3.2 (RDP Layer Selection): the mapping from geometric breakpoints to performance-critical layers rests on the unverified assumption that RDP pivots coincide with layers whose adaptation produces the largest task-specific gains. No ablation isolating this correspondence, no theoretical argument, and no cross-task or cross-model validation are provided to support the assumption.
Authors: The RDP pivots are defined by maximal curvature changes in the hidden-state trajectory; we hypothesize these mark layers where representational shifts are most consequential for the downstream task. The current results provide indirect support: the 13 RDP-selected layers outperform both random 13-layer selection (by 6.11 pp) and full 36-layer adaptation (by 2.35 pp). Nevertheless, we acknowledge the lack of a direct ablation that isolates the correspondence, a formal theoretical link, and cross-task or cross-model evidence. In revision we will add an ablation study in §4 that compares RDP selection against gradient-norm and attention-score heuristics on the same Qwen3-8B-Base / MMLU-Math setting, and we will expand the geometric motivation in §3.2. A complete theoretical derivation and broad cross-task validation lie beyond the scope of the present work and will be noted as directions for future research. revision: partial
Circularity Check
No circularity: RDP layer selection is pre-training and independent of reported accuracies
full rationale
The derivation applies the standard, parameter-free Ramer-Douglas-Peucker algorithm directly to hidden-state trajectories extracted from the base Qwen3-8B-Base model before any fine-tuning occurs. Layer indices are fixed by geometric breakpoints in these trajectories; the subsequent LoRA fine-tuning and MMLU-Math evaluation numbers are purely downstream measurements that play no role in determining which layers are selected. No parameters are fitted to task performance, no self-citations supply the core uniqueness claim, and the selection rule contains no reference to the accuracy figures that are later reported. The chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hidden-state evolution across LLM layers forms a high-dimensional geometric trajectory whose global structure can be captured by polygon simplification.
- ad hoc to paper RDP-identified breakpoints correspond to layers whose adaptation yields the largest task-specific gains.
Reference graph
Works this paper leans on
-
[1]
Freenor, M. and Alvarez, L. Steering embedding mod- els with geometric rotation: Mapping semantic rela- tionships across languages and models.arXiv preprint arXiv:2510.09790,
-
[2]
doi: 10.48550/arXiv.2510. 09790. Grand, G., Blank, I., Pereira, F., and Fedorenko, E. Se- mantic projection recovers rich human knowledge of multiple object features from word embeddings.Na- ture Human Behaviour, 6:975–987,
-
[3]
and Belinkov, Y
Katz, S. and Belinkov, Y . Visit: Visualizing and interpret- ing the semantic information flow of transformers. In Findings of EMNLP 2023, pp. 14094–14113,
2023
-
[4]
doi: 10.18653/v1/2023.findings-emnlp.939. Kopiczko, D. J., Blankevoort, T., and Asano, Y . M. VeRA: Vector-based random matrix adaptation.arXiv preprint arXiv:2310.11454,
-
[6]
Mitra, A., Khanpour, H., Rosset, C., and Awadallah, A
doi: 10.48550/ arXiv.2503.21073. Mitra, A., Khanpour, H., Rosset, C., and Awadallah, A. Orca-math: Unlocking the potential of slms in grade school math.arXiv preprint arXiv:2402.14830,
-
[7]
Song, J. and Zhong, Y . Uncovering hidden geometry in transformers via disentangling position and context.arXiv preprint arXiv:2310.04861,
-
[8]
Zhang, Sebas- tian Baltes, and Christoph Treude
doi: 10.48550/arXiv. 2310.04861. Tenney, I., Das, D., and Pavlick, E. BERT rediscovers the classical NLP pipeline. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4593–4601,
work page internal anchor Pith review doi:10.48550/arxiv
-
[9]
Valeriani, L., Doimo, D., Cuturello, F., Laio, A., Ansuini, A., and Cazzaniga, A. The geometry of hidden repre- sentations of large transformer models.arXiv preprint arXiv:2302.00294,
-
[10]
doi: 10.48550/arXiv.2302. 00294. Van Aken, B., Winter, B., L¨oser, A., and Gers, F. How does bert answer questions?: A layer-wise analysis of trans- former representations. InProceedings of the 28th ACM International Conference on Information and Knowledge Management,
work page internal anchor Pith review doi:10.48550/arxiv.2302
-
[11]
doi: 10.1145/3357384.3358028. Van Aken, B., Winter, B., L¨oser, A., and Gers, F. Visbert: Hidden-state visualizations for transformers. InCompan- ion Proceedings of the Web Conference 2020,
-
[12]
Wang, H., Ping, B., Wang, S., Han, X., Chen, Y ., Liu, Z., and Sun, M
doi: 10.1145/3366424.3383542. Wang, H., Ping, B., Wang, S., Han, X., Chen, Y ., Liu, Z., and Sun, M. LoRA-Flow: Dynamic LoRA fusion for large language models in generative tasks.arXiv preprint arXiv:2402.11455,
-
[13]
Wu, Y ., Xiang, Y ., Huo, S., Gong, Y ., and Liang, P. LoRA- SP: Streamlined partial parameter adaptation for resource- efficient fine-tuning of large language models.arXiv preprint arXiv:2403.08822,
-
[14]
9 RDP-Based Layer Selection for Sparse LoRA Fine-Tuning A. Appendix: Additional Experimental Results In this appendix, we provide a unified comparative analy- sis of the layer adaptation strategies across four additional Large Language Models (LLMs) with varying scales and architectures:Qwen3-4B-Base,Qwen3-14B-Base,Gemma- 7B, andDeepSeek-LLM-7B-Base. Tabl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.