Recognition: unknown
Revisiting RaBitQ and TurboQuant: A Symmetric Comparison of Methods, Theory, and Experiments
Pith reviewed 2026-05-10 02:39 UTC · model grok-4.3
The pith
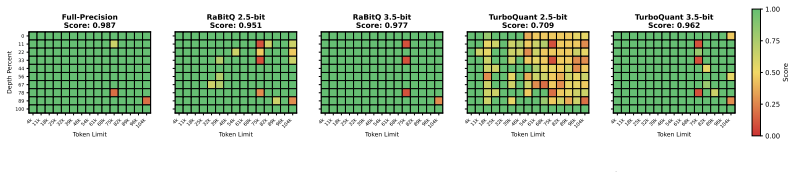
RaBitQ outperforms TurboQuant in most tested settings for inner-product estimation, nearest-neighbor search, and KV cache quantization, with several original TurboQuant results failing to reproduce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a single, symmetric evaluation framework the authors find that TurboQuant delivers lower accuracy or higher cost than RaBitQ across most configurations of inner-product estimation, nearest-neighbor search, and KV-cache quantization; in addition, several performance figures originally reported for TurboQuant cannot be reproduced from its publicly released implementation.
What carries the argument
A unified comparison framework that applies identical datasets, metrics, and configuration choices to both RaBitQ and TurboQuant so that differences in empirical behavior and reproducibility can be isolated.
If this is right
- RaBitQ becomes the stronger default choice for practitioners who need reliable inner-product estimation or nearest-neighbor search under tight memory constraints.
- KV-cache quantization pipelines that currently rely on TurboQuant should be re-tested against RaBitQ to measure any accuracy or latency gains.
- Future papers that introduce new quantization schemes must include direct comparisons against both RaBitQ and TurboQuant using the same released code and settings.
- Reproducibility checks should become standard when one quantization method claims superiority over another.
Where Pith is reading between the lines
- Quantization research would benefit from a shared public benchmark suite that locks both code versions and evaluation scripts so later claims can be verified without re-implementing setups.
- The fact that two independently developed methods share substantial internal structure suggests that theoretical improvements discovered for one may transfer to the other with modest adaptation.
- Practitioners deploying these techniques in production should run small-scale A/B tests on their own data rather than relying solely on published numbers.
Load-bearing premise
The chosen datasets, metrics, and implementation settings introduce no hidden bias that favors RaBitQ while the released TurboQuant code faithfully reflects the conditions described in its original paper.
What would settle it
Re-running the released TurboQuant implementation on the exact dataset sizes, bit widths, and hardware reported in the original TurboQuant paper and obtaining the same runtime and recall numbers claimed there would falsify the reproducibility finding.
Figures



read the original abstract
This technical note revisits the relationship between RaBitQ and TurboQuant under a unified comparison framework. We compare the two methods in terms of methodology, theoretical guarantees, and empirical performance, using a reproducible, transparent, and symmetric setup. Our results show that, despite the claimed advantage of TurboQuant, TurboQuant performs worse than RaBitQ in most tested settings of inner-product estimation, nearest-neighbor search and KV cache quantization. We further find that several reported runtime and recall results in the TurboQuant paper could not be reproduced from the released implementation under the stated configuration. Overall, this note clarifies the shared structure and genuine differences between the two lines of work, while documenting reproducibility issues in the experimental results reported by the TurboQuant paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This technical note revisits RaBitQ and TurboQuant under a unified comparison framework. It compares the methods on methodology, theoretical guarantees, and empirical performance, concluding that TurboQuant performs worse than RaBitQ in most tested settings for inner-product estimation, nearest-neighbor search, and KV cache quantization. The note also reports that several runtime and recall results from the original TurboQuant paper could not be reproduced from the released implementation under the stated configurations.
Significance. If the unified setup is verifiably symmetric and free of implementation artifacts, the work would help clarify the practical differences between these quantization approaches for efficient vector operations and model serving. It also draws attention to reproducibility challenges in empirical evaluations of quantization methods, which is valuable for the broader literature on approximate nearest-neighbor search and KV-cache compression.
major comments (2)
- [§4] §4 (Experimental Setup): The description of the 'symmetric' and 'reproducible' framework does not include explicit equivalence checks (e.g., identical vectorization, memory layouts, BLAS versions, or compiler flags) between the RaBitQ re-implementation and the released TurboQuant code. This detail is load-bearing for the central claim that observed performance gaps and non-reproducibility are intrinsic rather than environmental or optimization artifacts.
- [§5.2] §5.2 (Reproducibility subsection): The statement that 'several reported runtime and recall results could not be reproduced' lacks the exact configuration files, seed values, or command-line invocations used in the reproduction attempt. Without these, readers cannot independently assess the discrepancy or rule out post-hoc configuration differences.
minor comments (2)
- [Abstract] The abstract and introduction could more precisely quantify 'most tested settings' (e.g., number of datasets, bit-widths, and recall@K values) to allow quick assessment of the scope of the comparison.
- [§2] Notation for the shared mathematical structure (e.g., the common quantization operator) should be introduced once with a clear table or equation reference rather than repeated inline descriptions.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments on our technical note. We address each major comment below with point-by-point responses, indicating where revisions have been made to strengthen the manuscript's transparency and rigor.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): The description of the 'symmetric' and 'reproducible' framework does not include explicit equivalence checks (e.g., identical vectorization, memory layouts, BLAS versions, or compiler flags) between the RaBitQ re-implementation and the released TurboQuant code. This detail is load-bearing for the central claim that observed performance gaps and non-reproducibility are intrinsic rather than environmental or optimization artifacts.
Authors: We appreciate the referee's emphasis on this critical detail for validating the symmetry of the comparison. In the revised manuscript, Section 4 has been expanded with a new subsection on the experimental environment. It now explicitly documents the shared hardware (specific CPU/GPU models), OS, Python and library versions (including BLAS/MKL/OpenBLAS), compiler flags (-O3 -march=native), vectorization settings, and memory layouts. Both the RaBitQ re-implementation and the unmodified released TurboQuant code were executed under these identical conditions on the same machine. No custom optimizations were applied to either method beyond what is in the public releases. This addition directly supports that performance differences arise from methodological distinctions rather than setup artifacts. revision: yes
-
Referee: [§5.2] §5.2 (Reproducibility subsection): The statement that 'several reported runtime and recall results could not be reproduced' lacks the exact configuration files, seed values, or command-line invocations used in the reproduction attempt. Without these, readers cannot independently assess the discrepancy or rule out post-hoc configuration differences.
Authors: We agree that including these specifics is essential for full transparency and independent verification. The revised manuscript now includes a dedicated appendix (Appendix C) that provides the exact command-line invocations, configuration files (as YAML snippets), random seeds, and environment variables used in our reproduction attempts. These match the configurations described in the original TurboQuant paper. We also tabulate the reproduced versus originally reported runtime and recall values for the affected experiments. This allows readers to directly assess and replicate the noted discrepancies. revision: yes
Circularity Check
No circularity: empirical comparison without derivations or fitted predictions
full rationale
This technical note performs a symmetric empirical comparison of RaBitQ and TurboQuant using unified setups for methodology, theory, and experiments. It reports performance differences and reproducibility issues based on direct testing of released implementations. No mathematical derivations, first-principles results, predictions, or fitted models exist that could reduce to inputs by construction. All claims rest on external prior code and transparent experimental configurations rather than self-definitional steps, self-citation chains, or renamed known results. This is the expected non-finding for a pure comparison paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
FibQuant: Universal Vector Quantization for Random-Access KV-Cache Compression
FibQuant is a universal fixed-rate vector quantizer for KV-cache compression that uses a radial-angular codebook matched to the spherical-Beta source after Haar rotation and strictly outperforms scalar quantization at...
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2010 , isbn =
Durrett, Rick , title =. 2010 , isbn =
2010
-
[5]
2025 , eprint=
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate , author=. 2025 , eprint=
2025
-
[6]
2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS) , pages=
Optimal compression of approximate inner products and dimension reduction , author=. 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS) , pages=. 2017 , organization=
2017
-
[7]
Zandieh, Amir and Daliri, Majid and Han, Insu , title =. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2025 , isbn =. doi:10.1609/aaai.v39i24.34773 , abstract =
-
[8]
arXiv preprint arXiv:2602.23999 , year=
GPU-Native Approximate Nearest Neighbor Search with IVF-RaBitQ: Fast Index Build and Search , author=. arXiv preprint arXiv:2602.23999 , year=
-
[9]
Proceedings of the ACM on Management of Data , volume=
Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search , author=. Proceedings of the ACM on Management of Data , volume=. 2024 , publisher=
2024
-
[10]
Proceedings of the ACM on Management of Data , volume=
Practical and asymptotically optimal quantization of high-dimensional vectors in euclidean space for approximate nearest neighbor search , author=. Proceedings of the ACM on Management of Data , volume=. 2025 , publisher=
2025
-
[11]
Contemporary mathematics , volume=
Extensions of Lipschitz mappings into a Hilbert space 26 , author=. Contemporary mathematics , volume=
-
[12]
Khokhlov, V. I. , title =. Theory of Probability & Its Applications , volume =. 2006 , doi =. https://doi.org/10.1137/S0040585X97981846 , abstract =
-
[13]
The 1st Workshop on Vector Databases , year=
The RaBitQ Library , author=. The 1st Workshop on Vector Databases , year=
-
[14]
Proceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1 , pages =
Andoni, Alexandr and Indyk, Piotr and Laarhoven, Thijs and Razenshteyn, Ilya and Schmidt, Ludwig , title =. Proceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1 , pages =. 2015 , publisher =
2015
-
[15]
Pillai and Ashwin Sah and Mehtaab Sawhney and Aaron Smith , title =
Vishesh Jain and Natesh S. Pillai and Ashwin Sah and Mehtaab Sawhney and Aaron Smith , title =. The Annals of Applied Probability , number =. 2022 , doi =
2022
-
[16]
2022 , editor =
Vargaftik, Shay and Basat, Ran Ben and Portnoy, Amit and Mendelson, Gal and Itzhak, Yaniv Ben and Mitzenmacher, Michael , booktitle =. 2022 , editor =
2022
-
[17]
Accelerated Nearest Neighbor Search with Quick ADC , year =
Andr\'. Accelerated Nearest Neighbor Search with Quick ADC , year =. Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval , pages =. doi:10.1145/3078971.3078992 , abstract =
-
[18]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[19]
2026 , note =
Zandieh, Amir and Mirrokni, Vahab , title =. 2026 , note =
2026
-
[20]
DRIVE: One-bit Distributed Mean Estimation , url =
Vargaftik, Shay and Ben-Basat, Ran and Portnoy, Amit and Mendelson, Gal and Ben-Itzhak, Yaniv and Mitzenmacher, Michael , booktitle =. DRIVE: One-bit Distributed Mean Estimation , url =
-
[21]
Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection
Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection , author=. arXiv preprint arXiv:2602.03216 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Kamradt, Greg , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.