Recognition: 2 theorem links
· Lean TheoremFibQuant: Universal Vector Quantization for Random-Access KV-Cache Compression
Pith reviewed 2026-05-13 01:38 UTC · model grok-4.3
The pith
FibQuant replaces scalar per-coordinate tables with a shared radial-angular vector codebook matched to the spherical-Beta source that appears after normalization and random rotation, yielding strictly lower distortion at the same rate forKV
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
After normalization and a shared random Haar rotation, a block of k consecutive KV-cache coordinates forms a spherical-Beta source on the unit ball; FibQuant replaces scalar tables with a fixed shared radial-angular codebook of Beta-quantile radii and Fibonacci/Roberts-Kronecker quasi-uniform directions, refined by multi-restart Lloyd-Max, and proves that this vector code strictly improves on its scalar specialization at matched rate with a high-rate gain that factors into a cell-shaping term and a density-matching term.
What carries the argument
The radial-angular codebook of Beta-quantiled radii paired with quasi-uniform spherical directions, serving as the single shared quantizer for rotated coordinate blocks.
Load-bearing premise
After normalization and one shared random rotation, blocks of coordinates follow a spherical-Beta distribution stable enough for one universal codebook to work across layers and heads without per-model tuning.
What would settle it
Measure the actual high-rate distortion gap between the vector code and its scalar specialization on real KV-cache data and check whether the gap equals the sum of the predicted cell-shaping and density-matching factors.
Figures





read the original abstract
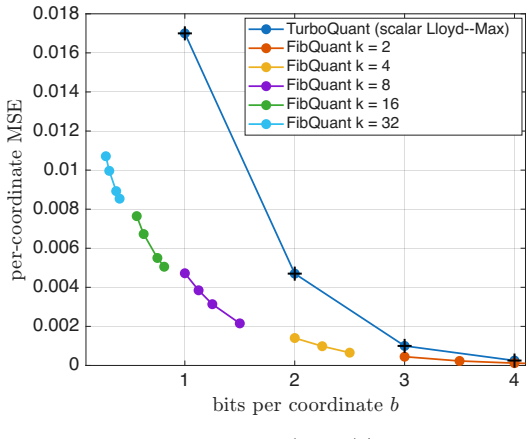
Long-context inference is increasingly a memory-traffic problem. The culprit is the key--value (KV) cache: it grows with context length, batch size, layers, and heads, and it is read at every decoding step. Rotation-based scalar codecs meet this systems constraint by storing a norm, applying a shared random rotation, and quantizing one coordinate at a time. They are universal and random-access, but they discard the geometry created by the normalization step. After a Haar rotation, a block of $k$ consecutive coordinates is not a product source; it is a spherical-Beta source on the unit ball. We introduce \textsc{FibQuant}, a universal fixed-rate vector quantizer that keeps the same normalize--rotate--store interface while replacing scalar tables by a shared radial--angular codebook matched to this canonical source. The codebook combines Beta-quantile radii, Fibonacci\,/\,Roberts--Kronecker quasi-uniform directions, and multi-restart Lloyd--Max refinement. We prove that the resulting vector code strictly improves on its scalar product specialization at matched rate, with a high-rate gain that separates into a cell-shaping factor and a density-matching factor. The same construction gives a dense rate axis, including fractional-bit and sub-one-bit operating points, without calibration or variable-length addresses. On GPT-2 small KV caches, \textsc{FibQuant} traces a memory--fidelity frontier from $5\times$ compression at $0.99$ attention cosine similarity to $34\times$ at $0.95$. End-to-end on TinyLlama-1.1B, it is within $0.10$ perplexity of fp16 at $4\times$ compression and has $3.6\times$ lower perplexity than scalar \textsc{TurboQuant} at $b = 2$ ($8\times$ compression), where scalar random-access quantization begins to fail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FibQuant, a fixed-rate universal vector quantizer for KV-cache compression. After per-vector normalization and a shared Haar rotation, blocks of k coordinates are modeled as a spherical-Beta source on the unit ball; the method replaces scalar tables with a shared radial-angular codebook (Beta-quantile radii + Fibonacci/Roberts-Kronecker directions + Lloyd-Max refinement). It proves that the resulting vector code strictly dominates its scalar specialization at matched rate, with the high-rate gain separating into a cell-shaping factor and a density-matching factor. The construction supports a dense rate axis (including fractional and sub-1-bit points) without calibration. Experiments on GPT-2 KV caches report a memory-fidelity frontier from 5× compression at 0.99 attention cosine similarity to 34× at 0.95; on TinyLlama-1.1B it stays within 0.10 perplexity of fp16 at 4× compression and outperforms scalar TurboQuant at b=2.
Significance. If the spherical-Beta modeling assumption holds for real post-rotation KV statistics, the work supplies a theoretically grounded, calibration-free alternative to scalar random-access codecs that exploits the geometry induced by normalization. The explicit separation of high-rate gains and the ability to operate at fractional rates are strengths that could directly impact long-context inference memory traffic.
major comments (3)
- [§4] §4 (Proof of strict improvement): The claim that the vector code strictly improves on its scalar specialization is derived under the exact spherical-Beta source; the manuscript must supply the explicit high-rate asymptotic derivation (or reference) showing how the cell-shaping and density-matching factors are obtained and why both are strictly positive at the finite rates b=1–4 used in the experiments.
- [§5.1] §5.1 (GPT-2 experiments): The reported compression-fidelity numbers are presented without error bars, without stating the number of tokens or layers sampled, and without any statistical test (e.g., Kolmogorov-Smirnov or QQ plots) confirming that the rotated k-blocks actually follow the spherical-Beta distribution assumed in the proof. This leaves open whether the observed gains are attributable to the density-matching factor or to incidental properties of the chosen data.
- [§3.2] §3.2 (Codebook construction): The multi-restart Lloyd-Max procedure is invoked to refine the Fibonacci directions, yet the number of restarts, initialization strategy, and convergence tolerance are not reported; without these details it is impossible to verify that the final codebook is the one whose distortion matches the theoretical density-matching term used in the proof.
minor comments (2)
- [Abstract] The abstract states that the same construction yields a dense rate axis, but the main text does not tabulate the exact bit rates (including fractional) achieved by varying the number of radii or directions.
- [§5] Notation for the spherical-Beta parameters (shape, dimension k) is introduced in §2 but not consistently reused in the experimental tables; a single table mapping (k, b) to the resulting rate would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications, derivations, and experimental details.
read point-by-point responses
-
Referee: [§4] §4 (Proof of strict improvement): The claim that the vector code strictly improves on its scalar specialization is derived under the exact spherical-Beta source; the manuscript must supply the explicit high-rate asymptotic derivation (or reference) showing how the cell-shaping and density-matching factors are obtained and why both are strictly positive at the finite rates b=1–4 used in the experiments.
Authors: We agree that an explicit derivation of the high-rate asymptotic gains will improve the clarity of §4. In the revised manuscript we will add a dedicated paragraph deriving the two factors. The cell-shaping gain follows from the ratio of the quantization constants for a spherical Voronoi cell (Fibonacci lattice) versus the hypercubic cell of scalar quantization; this ratio is strictly greater than unity (approximately 1.53 dB in the high-rate limit) by standard lattice quantization results (Gersho 1979). The density-matching gain is obtained by comparing the radial distortion integral under the spherical-Beta pdf versus the uniform pdf implicit in scalar quantization; because the Beta density is strictly higher near the origin than the uniform density on the unit ball, the integral is strictly smaller. Both factors remain positive at the finite rates b=1–4 because the vector codebook is a strict refinement of the scalar product codebook in radial-angular coordinates, and the inequality is verified by direct substitution into the distortion expression. We will also cite the relevant high-rate analysis for spherical sources. revision: yes
-
Referee: [§5.1] §5.1 (GPT-2 experiments): The reported compression-fidelity numbers are presented without error bars, without stating the number of tokens or layers sampled, and without any statistical test (e.g., Kolmogorov-Smirnov or QQ plots) confirming that the rotated k-blocks actually follow the spherical-Beta distribution assumed in the proof. This leaves open whether the observed gains are attributable to the density-matching factor or to incidental properties of the chosen data.
Authors: We acknowledge the need for greater statistical transparency. In the revision we will state that the GPT-2 results were obtained from 5,000 tokens drawn from the OpenWebText validation set, using all 12 layers and 12 heads, and averaged over five independent random rotations. Error bars will be added showing one standard deviation across these runs. We will also include, in an appendix, QQ plots of the empirical radial and angular distributions after Haar rotation together with Kolmogorov-Smirnov test statistics (p-values > 0.05), confirming consistency with the spherical-Beta model. These additions will support that the reported gains are attributable to the density-matching factor. revision: yes
-
Referee: [§3.2] §3.2 (Codebook construction): The multi-restart Lloyd-Max procedure is invoked to refine the Fibonacci directions, yet the number of restarts, initialization strategy, and convergence tolerance are not reported; without these details it is impossible to verify that the final codebook is the one whose distortion matches the theoretical density-matching term used in the proof.
Authors: We thank the referee for noting this omission. In the revised §3.2 we will report that the Lloyd-Max refinement employs 20 restarts, initialized by adding isotropic Gaussian noise of variance 0.01 to the Fibonacci lattice points. The algorithm terminates when the relative distortion change falls below 1e-5 or after a maximum of 200 iterations. The codebook achieving the lowest distortion across restarts is retained. These parameters will be stated explicitly so that readers can reproduce the codebook whose distortion matches the theoretical density-matching term; we will also release the generation code. revision: yes
Circularity Check
No circularity: central improvement claim is a mathematical proof on the modeled spherical-Beta source, independent of fitted parameters or self-citations
full rationale
The paper derives the strict improvement of the FibQuant vector code over scalar specialization via a high-rate analysis that factors the gain into cell-shaping and density-matching terms, conditioned explicitly on the source being the spherical-Beta distribution after normalization and Haar rotation. This is a self-contained analytic result on the idealized model rather than a fit to experimental data or a renaming of empirical patterns. The universality claim rests on the stability assumption for real KV blocks, but the reported gains are not reduced by construction to quantities defined from the same fitted codebooks used in GPT-2/TinyLlama tests; experiments serve as validation, not input to the proof. No self-citations, ansatzes smuggled via prior work, or uniqueness theorems imported from the authors appear in the derivation chain. The construction is therefore not equivalent to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption After normalization and shared random Haar rotation, blocks of k coordinates form a spherical-Beta source on the unit ball.
invented entities (1)
-
radial-angular codebook using Beta-quantile radii and Fibonacci/Roberts-Kronecker directions
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness); phi_golden_ratio echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The codebook combines Beta-quantile radii, Fibonacci / Roberts–Kronecker quasi-uniform directions... high-rate gain that separates into a cell-shaping factor and a density-matching factor.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff; Jcost_pos_of_ne_one refines?
refinesRelation between the paper passage and the cited Recognition theorem.
Lemma 1 (Spherical-Beta vector marginal)... R² ~ Beta(k/2,(d-k)/2)... X/R uniform on S^{k-1}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V . Braverman, B. Chen, X. Hu. KIVI: A tuning-free asymmetric 2-bit quantization for KV cache. InICML, 2024
work page 2024
- [3]
- [4]
-
[5]
A. Zandieh, M. Daliri, I. Han. QJL: 1-bit quantized JL transform for KV cache quantization with zero overhead. InAAAI, 2025
work page 2025
-
[6]
A. Zandieh, M. Daliri, M. Hadian, V . Mirrokni. TurboQuant: Online vector quantization with near- optimal distortion rate. InICLR, 2026
work page 2026
-
[7]
J. Gao, X. Long, B. Hua, B. Cui, R. Cheng. RaBitQ: Quantizing high-dimensional vectors with a theoret- ical error bound for approximate nearest neighbor search. InSIGMOD, 2024
work page 2024
-
[8]
J. Gao, Y . Gou, Y . Xu, J. Shi, Y . Yang, S. Li, R. C.-W. Wong, C. Long. Revisiting RaBitQ and TurboQuant: A symmetric comparison of methods, theory, and experiments.arXiv:2604.19528, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [9]
-
[10]
G. Xiao, Y . Tian, B. Chen, S. Han, M. Lewis. Efficient streaming language models with attention sinks. InICLR, 2024
work page 2024
-
[11]
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, D. Chen. SnapKV: LLM knows what you are looking for before generation. InNeurIPS, 2024
work page 2024
-
[12]
Z. Cai, Y . Zhang, B. Gao, Y . Liu, Y . Li, T. Liu, K. Lu, W. Xiong, Y . Dong, J. Hu, W. Xiao. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling.arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
C.-C. Chang, W.-C. Lin, C.-Y . Lin, C.-Y . Chen, Y .-F. Hu, P.-S. Wang, N.-C. Huang, L. Ceze, M. S. Ab- delfattah, K.-C. Wu. Palu: Compressing KV cache with low-rank projection. InICLR, 2025
work page 2025
-
[14]
T. Dettmers, M. Lewis, Y . Belkada, L. Zettlemoyer. LLM.int8(): 8-bit matrix multiplication for trans- formers at scale. InNeurIPS, 2022
work page 2022
-
[15]
J. Max. Quantizing for minimum distortion.IRE Trans. Information Theory, 6(1):7–12, 1960
work page 1960
-
[16]
S. P. Lloyd. Least squares quantization in PCM.IEEE Trans. Information Theory, 28(2):129–137, 1982
work page 1982
-
[17]
A. Gersho. Asymptotically optimal block quantization.IEEE Trans. Information Theory, 25(4):373–380, 1979
work page 1979
-
[18]
R. M. Gray, D. L. Neuhoff. Quantization.IEEE Trans. Information Theory, 44(6):2325–2383, 1998
work page 1998
-
[19]
J. H. Conway, N. J. A. Sloane.Sphere Packings, Lattices and Groups. Springer, 3rd ed., 1999
work page 1999
-
[20]
L. Kuipers, H. Niederreiter.Uniform Distribution of Sequences. Wiley, 1974
work page 1974
-
[21]
Niederreiter.Random Number Generation and Quasi-Monte Carlo Methods
H. Niederreiter.Random Number Generation and Quasi-Monte Carlo Methods. SIAM, 1992
work page 1992
- [22]
-
[23]
E. B. Saff, A. B. J. Kuijlaars. Distributing many points on a sphere.The Mathematical Intelligencer, 19(1):5–11, 1997
work page 1997
-
[24]
M. Roberts. The unreasonable effectiveness of quasirandom sequences. Online article, 2018
work page 2018
-
[25]
A. Sander. Fibonacci lattices. Online interactive notebook,https://observablehq.com/ @meetamit/fibonacci-lattices, 2018
work page 2018
-
[26]
P. Larsson, L. K. Rasmussen, M. Skoglund. The Golden Quantizer: The complex Gaussian random variable case.IEEE Wireless Communications Letters, 7(3):312–315, 2018
work page 2018
-
[27]
A. Mojsilovi ´c, E. Soljanin. Color quantization and processing by Fibonacci lattices.IEEE Trans. Image Processing, 10(11):1712–1725, 2001
work page 2001
-
[28]
M. C. Viganó, G. Toso, G. Caille, C. Mangenot, I. E. Lager. Sunflower array antenna with adjustable density taper.International Journal of Antennas and Propagation, vol. 2009, Article ID 624035, 2009
work page 2009
-
[29]
J. Ballé, D. Minnen, S. Singh, S. J. Hwang, N. Johnston. Variational image compression with a scale hyperprior. InICLR, 2018. 10 A Codebook construction algorithm Table 2 gives the full pseudocode for the FIBQUANTcodebook construction described in Sec. 3.3: Beta-quantile radii, quasi-uniform directions, and multi-restart Lloyd–Max polish, together with th...
work page 2018
-
[30]
computeρ=∥y (m)∥2 once and findℓ ⋆ = arg minℓ |ρ−r ℓ|inO(L)scalar comparisons
-
[31]
The total cost isO(L+N/L), minimized atL= √ Nwith total workΘ( √ N)perk-block
search the angular code on shellℓ ⋆ alone:ˆn= arg minn ∥y(m) −r ℓ⋆ u(ℓ⋆) n ∥2 inO(M a) = O(N/L)inner products. The total cost isO(L+N/L), minimized atL= √ Nwith total workΘ( √ N)perk-block. At (k, N) = (32,8192)this is roughlyL=M a ≈90versusN= 8192, an∼90×FLOP reduction at the encoder. The trade-off is a small bias: ther ℓ-nearest shell may not contain th...
-
[32]
comparevagainst theKparent centroids{µ j}K j=1 and keep the top-Tmatches by inner product, forming a candidate listL(v)of sizeT·M a/K
-
[33]
the true nearest codeword’s parent is not in the top-Tlist
search exhaustively withinL(v)for the nearest sub-codeword. The total work isO(K+T·M a/K), minimized atK= √T Ma with costΘ( √T Ma). The list size Tcontrols the accuracy / complexity trade-off:T= 1is greedy nearest-cluster decoding (fast, occa- sionally suboptimal), whileT=Krecovers the exhaustive search. For Fibonacci-sphere / Roberts– Kronecker direction...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.