Recognition: unknown
BEAT: Tokenizing and Generating Symbolic Music by Uniform Temporal Steps
Pith reviewed 2026-05-10 01:14 UTC · model grok-4.3
The pith
Uniform beat steps in music tokenization improve generation quality and long-range pattern capture compared to event-based methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The core claim is that a uniform temporal step tokenization, where music is segmented into fixed-length units and same-pitch notes per unit are merged, enables better performance on symbolic music generation tasks than traditional event-based encodings that allow non-uniform time progression.
What carries the argument
The BEAT tokenization, which uses uniform-length musical steps as the basic unit, encodes all same-pitch events in a step as a single token, and groups tokens by time step.
If this is right
- Generated music exhibits improved quality and structural coherence on continuation and accompaniment tasks.
- The approach captures long-range patterns more effectively than event-based tokenizations.
- Token sequences are shorter and more efficient to process.
- Models benefit from explicit uniform time progression rather than implicit handling through variable durations.
Where Pith is reading between the lines
- This tokenization could extend to other time-based arts like dance or speech synthesis where regular timing aids coherence.
- Future models might combine this with event-based elements for hybrid precision in timing.
- Evaluation on datasets with complex rhythms could test if uniform steps introduce artifacts in non-grid music.
Load-bearing premise
Discretizing music into uniform beat steps and merging same-pitch events within steps preserves all musically relevant information without significant loss or ambiguity.
What would settle it
If listener studies or objective metrics show that event-based models produce more coherent and higher-quality music than beat-based ones when both are trained and evaluated identically, the advantage would be disproven.
Figures






read the original abstract
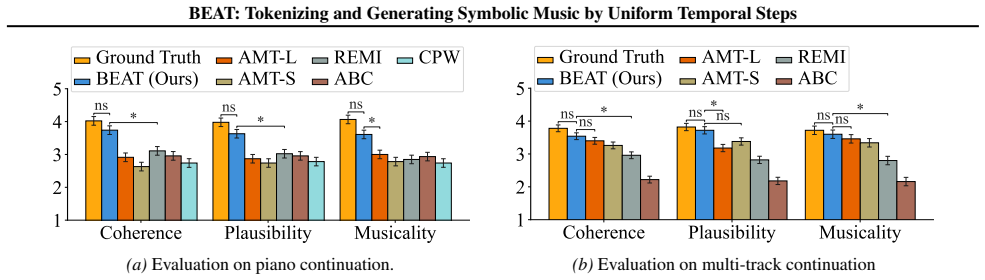
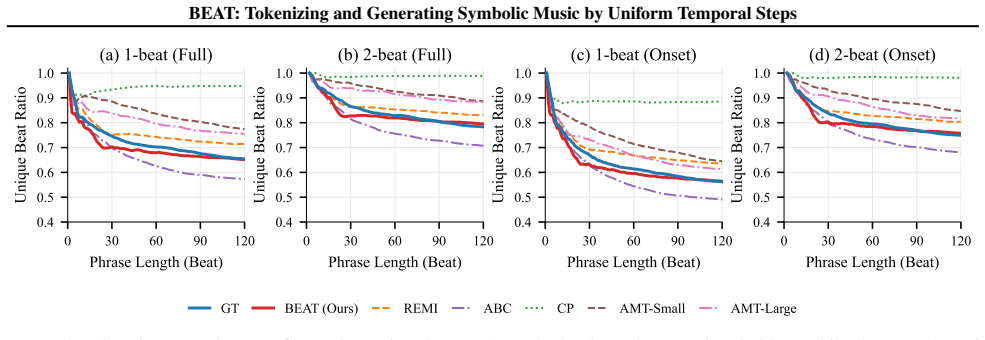
Tokenizing music to fit the general framework of language models is a compelling challenge, especially considering the diverse symbolic structures in which music can be represented (e.g., sequences, grids, and graphs). To date, most approaches tokenize symbolic music as sequences of musical events, such as onsets, pitches, time shifts, or compound note events. This strategy is intuitive and has proven effective in Transformer-based models, but it treats the regularity of musical time implicitly: individual tokens may span different durations, resulting in non-uniform time progression. In this paper, we instead consider whether an alternative tokenization is possible, where a uniform-length musical step (e.g., a beat) serves as the basic unit. Specifically, we encode all events within a single time step at the same pitch as one token, and group tokens explicitly by time step, which resembles a sparse encoding of a piano-roll representation. We evaluate the proposed tokenization on music continuation and accompaniment generation tasks, comparing it with mainstream event-based methods. Results show improved musical quality and structural coherence, while additional analyses confirm higher efficiency and more effective capture of long-range patterns with the proposed tokenization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BEAT, an alternative tokenization for symbolic music that replaces variable-duration event sequences with uniform temporal steps (e.g., beats). Within each step, same-pitch events are collapsed into single tokens and tokens are explicitly grouped by step, yielding a sparse piano-roll-like representation. The approach is evaluated on music continuation and accompaniment generation tasks against mainstream event-based tokenizers, with claims of superior musical quality, structural coherence, computational efficiency, and improved modeling of long-range patterns.
Significance. If the empirical claims hold after rigorous validation, the work would demonstrate that explicit temporal regularity in tokenization can outperform implicit handling via event durations, potentially enabling more efficient long-context modeling in music transformers and providing a bridge to grid-based architectures. The sparse encoding could also reduce sequence lengths while preserving polyphony.
major comments (3)
- [Abstract] Abstract: the central claim that the uniform-step tokenization yields 'improved musical quality and structural coherence' is stated without any quantitative metrics, baselines, statistical tests, or dataset details. The full experimental section (presumably §4 or §5) must supply these to establish that the reported gains are not artifacts of the coarser representation.
- [Abstract / §3] The tokenization description (Abstract and §3) collapses all same-pitch events within a fixed beat step into one token and discards intra-beat onset timing. This directly engages the weakest assumption: for music with swing, rubato, or precise polyphonic offsets, the loss of sub-beat information must be shown to be musically inconsequential. No analysis or ablation addressing this quantization error is referenced.
- [Abstract] Efficiency and long-range capture claims (Abstract) require concrete comparisons—e.g., tokens per second, attention span in beats, or perplexity on long sequences—against event-based baselines. Without these numbers, it is impossible to determine whether gains stem from the uniform grid or simply from shorter sequences.
minor comments (2)
- [§3] Clarify the exact beat resolution (e.g., 16th-note grid or quarter-note) and how ties or rests spanning steps are encoded.
- [Abstract] The abstract mentions 'additional analyses' for efficiency and long-range patterns; these should be explicitly labeled and placed in a dedicated subsection with figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying where the full manuscript already supplies details and indicating revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the uniform-step tokenization yields 'improved musical quality and structural coherence' is stated without any quantitative metrics, baselines, statistical tests, or dataset details. The full experimental section (presumably §4 or §5) must supply these to establish that the reported gains are not artifacts of the coarser representation.
Authors: The abstract is intentionally concise, but Sections 4 and 5 of the full manuscript detail the experimental setup, including the datasets used, event-based baselines (e.g., REMI-style tokenizers), objective and subjective metrics for musical quality and structural coherence, and statistical comparisons. We will revise the abstract to briefly reference key quantitative gains and explicitly direct readers to the experimental sections. revision: yes
-
Referee: [Abstract / §3] The tokenization description (Abstract and §3) collapses all same-pitch events within a fixed beat step into one token and discards intra-beat onset timing. This directly engages the weakest assumption: for music with swing, rubato, or precise polyphonic offsets, the loss of sub-beat information must be shown to be musically inconsequential. No analysis or ablation addressing this quantization error is referenced.
Authors: The design intentionally quantizes to uniform beat steps to enforce temporal regularity. While this discards sub-beat timing (potentially relevant for rubato or swing), evaluations on standard datasets show net gains in coherence and quality. The manuscript does not contain a dedicated ablation on quantization error; we will add a limitations discussion and brief analysis of timing-sensitive cases in the revision. revision: partial
-
Referee: [Abstract] Efficiency and long-range capture claims (Abstract) require concrete comparisons—e.g., tokens per second, attention span in beats, or perplexity on long sequences—against event-based baselines. Without these numbers, it is impossible to determine whether gains stem from the uniform grid or simply from shorter sequences.
Authors: Section 5 already reports efficiency metrics (sequence length reductions) and long-range analyses (perplexity over extended contexts and effective beat-span coverage). These distinguish the contribution of the uniform grid from mere length reduction. We will expand this into an explicit comparison table with tokens-per-second and attention-span figures in the revised version. revision: yes
Circularity Check
No circularity in tokenization proposal or empirical claims
full rationale
The paper introduces a uniform temporal step tokenization (grouping same-pitch events per fixed beat-like step into single tokens) and evaluates it via direct comparison against event-based baselines on music continuation and accompaniment tasks. No equations, fitted parameters, or predictions are described that reduce by construction to the inputs; the reported gains in quality, coherence, efficiency, and long-range modeling are framed as outcomes of external benchmarks rather than internal redefinitions or self-citation chains. The central assumption (that uniform discretization preserves musically relevant information) is testable against the baselines and does not collapse into tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Music possesses a sufficiently regular pulse that uniform beat-length discretization captures essential temporal structure without critical loss.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
International Conference on Learning Representations (ICLR) , year=
Music transformer: Generating music with long-term structure , author=. International Conference on Learning Representations (ICLR) , year=
-
[9]
Neural Computing and Applications , volume=
This time with feeling: learning expressive musical performance , author=. Neural Computing and Applications , volume=. 2020 , publisher=
2020
-
[10]
Proceedings of the 25th International Society for Music Information Retrieval Conference , year=
Nested Music Transformer: Sequentially Decoding Compound Tokens in Symbolic Music and Audio Generation , author=. Proceedings of the 25th International Society for Music Information Retrieval Conference , year=
-
[11]
arXiv preprint arXiv:2312.08931 , year=
N-gram unsupervised compoundation and feature injection for better symbolic music understanding , author=. arXiv preprint arXiv:2312.08931 , year=
-
[12]
MidiBERT-Piano: Large-scale pre-training for symbolic music understanding , author=
-
[13]
arXiv preprint arXiv:2504.15071v1 , year=
Aria-MIDI: A dataset of piano MIDI files for symbolic music modeling , author=. arXiv preprint arXiv:2504.15071v1 , year=
-
[14]
arXiv preprint arXiv:2412.16526v1 , year=
Text2MIDI: Generating Symbolic Music from Captions , author=. arXiv preprint arXiv:2412.16526v1 , year=
-
[15]
International conference on machine learning (ICML) , pages=
A hierarchical latent vector model for learning long-term structure in music , author=. International conference on machine learning (ICML) , pages=. 2018 , organization=
2018
-
[16]
arXiv preprint arXiv:2010.06230 , year=
A variational autoencoder for music generation controlled by tonal tension , author=. arXiv preprint arXiv:2010.06230 , year=
-
[17]
IEEE Access , volume=
Monophonic music generation with a given emotion using conditional variational autoencoder , author=. IEEE Access , volume=
-
[18]
ECAI 2020 , pages=
Learning style-aware symbolic music representations by adversarial autoencoders , author=. ECAI 2020 , pages=
2020
-
[19]
Proceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR) , year=
Symbolic music generation with diffusion models , author=. Proceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR) , year=
-
[20]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23) , year=
Discrete diffusion probabilistic models for symbolic music generation , author=. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23) , year=
-
[21]
arXiv preprint arXiv:2310.14044 , year=
Composer style-specific symbolic music generation using vector quantized discrete diffusion models , author=. arXiv preprint arXiv:2310.14044 , year=
-
[22]
International Conference on Learning Representations (ICLR) , year=
Whole-song hierarchical generation of symbolic music using cascaded diffusion models , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
International Conference on Machine Learning (ICML) , note=
Symbolic music generation with non-differentiable rule guided diffusion , author=. International Conference on Machine Learning (ICML) , note=
-
[24]
arXiv preprint arXiv:2507.20128 , year=
Diffusion-based symbolic music generation with structured state space models , author=. arXiv preprint arXiv:2507.20128 , year=
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
MuseGAN: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[26]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23) , year=
The ACCompanion: Combining reactivity, robustness, and musical expressivity in an automatic piano accompanist , author=. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23) , year=
-
[27]
arXiv preprint arXiv:2409.11952 , year=
Human-robot cooperative piano playing with learning-based real-time music accompaniment , author=. arXiv preprint arXiv:2409.11952 , year=
-
[28]
arXiv preprint arXiv:2210.15638 , year=
LyricJam Sonic: A generative system for real-time composition and musical improvisation , author=. arXiv preprint arXiv:2210.15638 , year=
-
[29]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
DeepBach: A steerable model for Bach chorales generation , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
-
[30]
EURASIP Journal on Audio, Speech, and Music Processing , volume=
Generating chord progression from melody with flexible harmonic rhythm and controllable harmonic density , author=. EURASIP Journal on Audio, Speech, and Music Processing , volume=
-
[31]
Proceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR) , year=
Variable-length music score infilling via XLNet and musically specialized positional encoding , author=. Proceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR) , year=
-
[32]
Evolutionary and Biologically Inspired Music, Sound, Art and Design , year=
MusIAC: An extensible generative framework for music infilling applications with multi-level control , author=. Evolutionary and Biologically Inspired Music, Sound, Art and Design , year=
-
[33]
arXiv preprint arXiv:2501.04630 , year=
Evaluating interval-based tokenization for pitch representation in symbolic music analysis , author=. arXiv preprint arXiv:2501.04630 , year=
-
[34]
Proceedings of the International Conference on Music Information Retrieval (ISMIR) , pages=
Transposition-invariant self-similarity matrices , author=. Proceedings of the International Conference on Music Information Retrieval (ISMIR) , pages=
-
[35]
International Conference on Machine Learning (ICML) , pages=
Graph neural network for music score data and modeling expressive piano performance , author=. International Conference on Machine Learning (ICML) , pages=
-
[36]
Proceedings of the 9th International Conference on Computational Creativity , year=
Symbolic music similarity through a graph-based representation , author=. Proceedings of the 9th International Conference on Computational Creativity , year=
-
[37]
Learning-based methods for comparing sequences, with applications to audio-to-MIDI alignment and matching , author=
-
[38]
International Conference on Learning Representations (ICLR) , year=
Enabling factorized piano music modeling and generation with the MAESTRO dataset , author=. International Conference on Learning Representations (ICLR) , year=
-
[39]
Proceedings of the 29th International Conference on Machine Learning (ICML) , pages=
Modeling temporal dependencies in high-dimensional sequences: Application to polyphonic music generation and transcription , author=. Proceedings of the 29th International Conference on Machine Learning (ICML) , pages=
-
[40]
arXiv preprint arXiv:2010.07061 , year=
GiantMIDI-piano: A large-scale midi dataset for classical piano music , author=. arXiv preprint arXiv:2010.07061 , year=
-
[41]
Fradet, Nathan and Briot, Jean-Pierre and Chhel, Fabien and El Fallah Seghrouchni, Amal and Gutowski, Nicolas , booktitle=
-
[42]
Proceedings of the 11th International Society for Music Information Retrieval Conference (ISMIR) , pages=
music21: A toolkit for computer-aided musicology and symbolic music data , author=. Proceedings of the 11th International Society for Music Information Retrieval Conference (ISMIR) , pages=
-
[43]
Perception & Psychophysics , volume=
Recognition of melodic transformations: Inversion, retrograde, and retrograde inversion , author=. Perception & Psychophysics , volume=
-
[44]
Infant Behavior and Development , volume=
Preference for infant-directed singing in 2-month-old infants , author=. Infant Behavior and Development , volume=
-
[45]
Magenta: Music and Art Generation with Machine Intelligence , author=
-
[46]
International Society for Music Information Retrieval Conference (ISMIR) , year=
Convolutional Generative Adversarial Networks with Binary Neurons for Polyphonic Music Generation , author=. International Society for Music Information Retrieval Conference (ISMIR) , year=
-
[47]
International Society for Music Information Retrieval Conference (ISMIR) , year=
Counterpoint by Convolution , author=. International Society for Music Information Retrieval Conference (ISMIR) , year=
-
[48]
1983 , publisher=
A Generative Theory of Tonal Music , author=. 1983 , publisher=
1983
-
[49]
AAAI Conference on Artificial Intelligence , year=
Text2midi: Generating Symbolic Music from Captions , author=. AAAI Conference on Artificial Intelligence , year=
-
[50]
Midi-llm: Adapting large language models for text-to-midi music generation,
Midi-LLM: Adapting Large Language Models for Text-to-MIDI Music Generation , author=. arXiv preprint arXiv:2511.03942 , year=
-
[51]
Enabling Factorized Piano Music Modeling and Generation with the
Hawthorne, Curtis and Stasyuk, Andriy and Roberts, Adam and Simon, Ian and Huang, Cheng-Zhi Anna and Dieleman, Sander and Elsen, Erich and Engel, Jesse and Eck, Douglas , booktitle=. Enabling Factorized Piano Music Modeling and Generation with the
-
[52]
Liang, Feynman , year=
-
[53]
2010 , publisher=
Music, Language, and the Brain , author=. 2010 , publisher=
2010
-
[54]
Huang, Cheng-Zhi Anna and Hawthorne, Curtis and Roberts, Adam and Dinculescu, Monica and Wexler, James and Hong, Leon and Howcroft, Jacob , booktitle=. The. 2019 , url=
2019
-
[55]
Performance
Simon, Ian and Oore, Sageev , journal=. Performance. 2017 , url=
2017
-
[56]
Jiang, Nan and Jin, Sheng and Duan, Zhiyao and Zhang, Changshui , booktitle=
-
[57]
2022 , publisher=
Chen, Dejing and Wu, Jing and Xu, Xinyu and Yao, Wei and Wan, Yaxuan and Xue, Han and Li, Zhizheng and Liu, Qifeng , booktitle=. 2022 , publisher=
2022
-
[58]
Frontiers in Artificial Intelligence , volume=
On the Adaptability of Recurrent Neural Networks for Real-Time Jazz Improvisation Accompaniment , author=. Frontiers in Artificial Intelligence , volume=. 2021 , publisher=
2021
-
[59]
Walshaw, Chris , year=
-
[60]
2024 , url=
Zhang, Shangda and Wu, Tianyu and Liu, Maosong and Sun, Maosong , booktitle=. 2024 , url=
2024
-
[61]
Zhou, Tianyu and Wu, Shangda and Zhang, Haoyang and Sun, Maosong and Liu, Maosong , journal=
-
[62]
Yang, Li-Chia and Chou, Szu-Yu and Yang, Yi-Hsuan , journal=
-
[63]
Payne, Christine , year=
-
[64]
Donahue, Chris and Mao, Huanru Henry and Li, Yiting Ethan and Cottrell, Garrison W and McAuley, Julian , booktitle=
-
[65]
arXiv preprint arXiv:2506.23869 , year=
Scaling Self-Supervised Representation Learning for Symbolic Piano Performance , author=. arXiv preprint arXiv:2506.23869 , year=
-
[66]
arXiv preprint arXiv:2505.03314 , year=
Mamba-Diffusion Model with Learnable Wavelet for Controllable Symbolic Music Generation , author=. arXiv preprint arXiv:2505.03314 , year=
-
[67]
Dong, Hao-Wen and Hsiao, Wen-Yi and Yang, Li-Chia and Yang, Yi-Hsuan , journal=. The
-
[68]
Sarmento, Pedro and Kumar, Adarsh and Wang, Yixiao and Jiang, Yuanchao and Pati, Ashis and Samiotis, Apostolos and Lerch, Alexander , journal=. The
-
[69]
Sequence Tutor: Conservative Fine-Tuning of Sequence Generation Models with
Jaques, Natasha and Gu, Shixiang and Bahdanau, Dzmitry and Hern. Sequence Tutor: Conservative Fine-Tuning of Sequence Generation Models with. International Conference on Machine Learning , pages=
-
[70]
Connection Science , volume=
Neural Network Music Composition by Prediction: Exploring the Benefits of Psychoacoustic Constraints and Multi-scale Processing , author=. Connection Science , volume=. 1994 , publisher=
1994
-
[71]
Advances in Neural Information Processing Systems , volume=
Harmonising Chorales by Probabilistic Inference , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Smilkov, Daniel and Thorat, Nikhil and Assogba, Yannick and Yuan, Ann and Kreeger, Nick and Yu, Ping and Zhang, Kangyi and Cai, Shanqing and Nielsen, Eric and Soergel, David and others , journal=
-
[73]
Dong, Hao-Wen and Chen, Ke and McAuley, Julian and Berg-Kirkpatrick, Taylor , booktitle=
-
[74]
Proceedings of The 8th Asian Conference on Machine Learning (ACML) , pages=
Modelling Symbolic Music: Beyond the Piano Roll , author=. Proceedings of The 8th Asian Conference on Machine Learning (ACML) , pages=. 2016 , volume=
2016
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
DeepGCNs: Can GCNs Go as Deep as CNNs? , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[76]
arXiv preprint arXiv:2505.15559 , year=
Moonbeam: A MIDI Foundation Model Using Both Absolute and Relative Music Attributes , author=. arXiv preprint arXiv:2505.15559 , year=
-
[77]
Proceedings of the 24th International Society for Music Information Retrieval Conference (ISMIR) , pages=
Impact of Time and Note Duration Tokenizations on Deep Learning Symbolic Music Modeling , author=. Proceedings of the 24th International Society for Music Information Retrieval Conference (ISMIR) , pages=. 2023 , address=
2023
-
[78]
Proceedings of the 23rd International Society for Music Information Retrieval Conference , year=
Symphony Generation with Permutation Invariant Language Model , author=. Proceedings of the 23rd International Society for Music Information Retrieval Conference , year=
-
[79]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A Domain-Knowledge-Inspired Music Embedding Space and a Novel Attention Mechanism for Symbolic Music Modeling , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2023 , url=
2023
-
[80]
Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) , year=
On the Importance of Time and Pitch Relativity for Transformer-Based Symbolic Music Generation , author=. Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.