Recognition: unknown
Learning Hybrid-Control Policies for High-Precision In-Contact Manipulation Under Uncertainty
Pith reviewed 2026-05-10 02:15 UTC · model grok-4.3
The pith
Hybrid position-force policies with MATCH training achieve up to 10 percent higher success and five times fewer breaks than pose-only policies in uncertain peg-in-hole tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
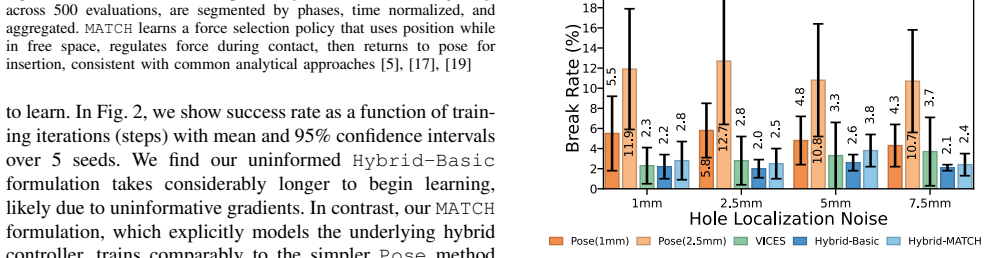
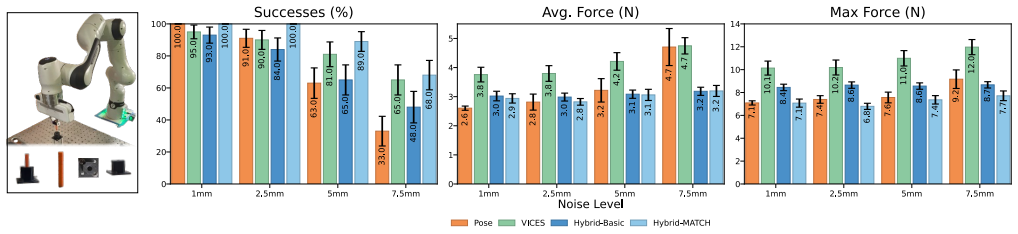
The authors show that hybrid position-force control policies, trained via Mode-Aware Training for Contact Handling (MATCH) to mirror intended mode selection behavior, solve high-precision peg-in-hole tasks more reliably than pose-only policies when localization uncertainty is present. In simulation and over 1600 sim-to-real trials on a Franka FR3, MATCH policies reach up to 10 percent higher success rates, produce five times fewer peg breaks, succeed twice as often in high-noise regimes, and apply roughly 30 percent less average force than variable-impedance baselines, all while matching the data efficiency of simpler pose policies despite the larger action space.
What carries the argument
Mode-Aware Training for Contact Handling (MATCH), a modification to policy training that explicitly adjusts action probabilities to reproduce the mode-selection logic of hybrid position-force control.
If this is right
- MATCH policies solve the same tasks with up to 10 percent higher success under common state-estimation errors.
- They produce five times fewer peg breaks than pose-only policies.
- In high-noise settings they succeed twice as often while applying about 30 percent less force than variable-impedance baselines.
- They retain data efficiency comparable to pose policies despite operating in a larger hybrid action space.
Where Pith is reading between the lines
- The same hybrid-mode approach could be applied to other contact-rich tasks such as screw driving or surface finishing where force limits matter.
- If the mode-selection benefit holds, robots could operate with cheaper or less precise sensors without sacrificing reliability.
- Testing MATCH inside different reinforcement-learning algorithms would reveal whether the training adjustment is broadly useful or specific to the current setup.
Load-bearing premise
The simulation must faithfully reproduce real contact forces, friction, and uncertainty distributions so that policies trained inside it transfer without causing damage on physical hardware.
What would settle it
A set of real-robot trials under the same high-noise localization conditions in which MATCH policies show equal or lower success rates and equal or higher average contact forces than pose-only or impedance policies.
Figures




read the original abstract
Reinforcement learning-based control policies have been frequently demonstrated to be more effective than analytical techniques for many manipulation tasks. Commonly, these methods learn neural control policies that predict end-effector pose changes directly from observed state information. For tasks like inserting delicate connectors which induce force constraints, pose-based policies have limited explicit control over force and rely on carefully tuned low-level controllers to avoid executing damaging actions. In this work, we present hybrid position-force control policies that learn to dynamically select when to use force or position control in each control dimension. To improve learning efficiency of these policies, we introduce Mode-Aware Training for Contact Handling (MATCH) which adjusts policy action probabilities to explicitly mirror the mode selection behavior in hybrid control. We validate MATCH's learned policy effectiveness using fragile peg-in-hole tasks under extreme localization uncertainty. We find MATCH substantially outperforms pose-control policies -- solving these tasks with up to 10% higher success rates and 5x fewer peg breaks than pose-only policies under common types of state estimation error. MATCH also demonstrates data efficiency equal to pose-control policies, despite learning in a larger and more complex action space. In over 1600 sim-to-real experiments, we find MATCH succeeds twice as often as pose policies in high noise settings (33% vs.~68%) and applies ~30% less force on average compared to variable impedance policies on a Franka FR3 in laboratory conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mode-Aware Training for Contact Handling (MATCH), a reinforcement learning approach to train hybrid position-force control policies that dynamically select control modes per dimension. It claims these policies outperform pose-only baselines (higher success rates, up to 5x fewer peg breaks under state estimation error) and variable-impedance baselines (∼30% lower average force) on fragile peg-in-hole tasks, validated via over 1600 sim-to-real trials on a Franka FR3 under injected localization uncertainty.
Significance. If the sim-to-real transfer holds, the result would be significant for contact-rich manipulation under uncertainty: it shows that explicit hybrid mode selection, when trained with mode-aware adjustments, can improve both task success and safety metrics compared to standard pose or impedance policies while maintaining data efficiency.
major comments (2)
- [Abstract / Experimental Results] Abstract and Experimental Results: The central performance claims (68% vs. 33% success in high-noise settings, ∼30% lower force, 5x fewer breaks) rest on sim-to-real transfer, yet no quantitative metrics are given for simulator fidelity (force/torque profile matching, friction calibration, or uncertainty distribution alignment between sim and real). This is load-bearing because any mismatch would allow policies to exploit simulator-specific artifacts.
- [Methods] Methods (MATCH training procedure): The description of how action probabilities are adjusted to mirror hybrid mode selection lacks sufficient detail on the exact probability scaling, reward shaping for mode consistency, or ablation isolating the mode-aware component from standard RL training; without this, it is unclear whether the reported gains are attributable to MATCH or to the larger hybrid action space itself.
minor comments (2)
- [Abstract] Abstract: The statement 'up to 10% higher success rates' appears inconsistent with the later specific numbers (33% vs. 68%); clarify whether the 10% figure refers to a different noise regime or baseline comparison.
- [Preliminaries / Methods] Notation: The hybrid control formulation would benefit from an explicit equation defining the mode-selection action space and how it composes with the low-level controller.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important areas for strengthening the presentation of our sim-to-real validation and the MATCH training details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results: The central performance claims (68% vs. 33% success in high-noise settings, ∼30% lower force, 5x fewer breaks) rest on sim-to-real transfer, yet no quantitative metrics are given for simulator fidelity (force/torque profile matching, friction calibration, or uncertainty distribution alignment between sim and real). This is load-bearing because any mismatch would allow policies to exploit simulator-specific artifacts.
Authors: We agree that explicit quantitative metrics for simulator fidelity would better support the sim-to-real claims. The current manuscript reports aggregate success rates and force metrics across 1600+ trials but does not include direct comparisons such as force/torque profile matching or calibrated friction parameters. In the revision we will add a dedicated subsection under Experimental Results that reports these metrics (e.g., RMS force error between sim and real, friction coefficient calibration, and KL divergence on injected uncertainty distributions) drawn from our experimental logs. revision: yes
-
Referee: [Methods] Methods (MATCH training procedure): The description of how action probabilities are adjusted to mirror hybrid mode selection lacks sufficient detail on the exact probability scaling, reward shaping for mode consistency, or ablation isolating the mode-aware component from standard RL training; without this, it is unclear whether the reported gains are attributable to MATCH or to the larger hybrid action space itself.
Authors: We acknowledge that the Methods section provides only a high-level overview of the probability adjustment and does not include the precise scaling formula, explicit reward-shaping terms, or an ablation isolating the mode-aware component. In the revised manuscript we will expand the MATCH description with the exact probability scaling equation, the mode-consistency reward terms, and results from an ablation study that trains a standard RL policy in the same hybrid action space. This will clarify that the performance gains arise from the mode-aware adjustments rather than the action space alone. revision: yes
Circularity Check
No circularity: empirical RL results from direct experiments
full rationale
This paper reports an empirical RL study of hybrid position-force control policies for peg-in-hole tasks. Central claims rest on experimental comparisons (success rates, peg breaks, force application) across >1600 sim-to-real trials on a Franka FR3, with MATCH outperforming pose-only and variable-impedance baselines under injected state-estimation noise. No mathematical derivations, equations, or first-principles predictions appear; results are not obtained by fitting parameters to a subset and renaming the fit as a prediction, nor by self-definitional loops or load-bearing self-citations. The work is therefore self-contained against external benchmarks, with all performance numbers arising from direct measurement rather than any reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning can learn effective mode selection for hybrid position-force control from reward signals in simulation
Reference graph
Works this paper leans on
-
[1]
A review of robotic as- sembly strategies for the full operation procedure: planning, execution and evaluation,
Y . Jiang, Z. Huang, B. Yang, and W. Yang, “A review of robotic as- sembly strategies for the full operation procedure: planning, execution and evaluation,”Robotics and Computer-Integrated Manufacturing, vol. 78, p. 102366, Dec. 2022
2022
-
[2]
Inspection and maintenance of indus- trial infrastructure with autonomous underwater robots,
F. Nauert and P. Kampmann, “Inspection and maintenance of indus- trial infrastructure with autonomous underwater robots,”Frontiers in Robotics and AI, vol. 10, Aug. 2023
2023
-
[3]
Review of emerging surgical robotic technology,
B. S. Peters, P. R. Armijo, C. Krause, S. A. Choudhury, and D. Oleynikov, “Review of emerging surgical robotic technology,” Surgical Endoscopy, vol. 32, no. 4, pp. 1636–1655, Apr. 2018
2018
-
[4]
Hybrid Position/Force Control of Ma- nipulators,
M. H. Raibert and J. J. Craig, “Hybrid Position/Force Control of Ma- nipulators,”Journal of Dynamic Systems, Measurement, and Control, vol. 103, no. 2, pp. 126–133, June 1981
1981
-
[5]
Chhatpar and M
S. Chhatpar and M. Branicky,Search strategies for peg-in-hole assem- blies with position uncertainty, Feb. 2001, vol. 3, iEEE International Conference on Intelligent Robots and Systems
2001
-
[6]
Solving peg-in-hole tasks by human demonstration and exception strategies,
F. J. Abu-Dakka, B. Nemec, A. Kramberger, A. G. Buch, N. Kr ¨uger, and A. Ude, “Solving peg-in-hole tasks by human demonstration and exception strategies,”Industrial Robot: An International Journal, vol. 41, no. 6, pp. 575–584, Oct. 2014
2014
-
[7]
J. Xu, Z. Hou, Z. Liu, and H. Qiao, “Compare Contact Model-based Control and Contact Model-free Learning: A Survey of Robotic Peg- in-hole Assembly Strategies,” Apr. 2019, arXiv:1904.05240 [cs]
-
[8]
Policy Search for Motor Primitives in Robotics,
J. Kober and J. Peters, “Policy Search for Motor Primitives in Robotics,” inAdvances in Neural Information Processing Systems, vol. 21. Curran Associates, Inc., 2008
2008
-
[9]
arXiv preprint arXiv:2305.13122 , year=
L. Yang, Z. Huang, F. Lei, Y . Zhong, Y . Yang, C. Fang, S. Wen, B. Zhou, and Z. Lin, “Policy Representation via Diffusion Probability Model for Reinforcement Learning,” May 2023, arXiv:2305.13122
-
[10]
FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty,
M. Noseworthy, B. Tang, B. Wen, A. Handa, C. Kessens, N. Roy, D. Fox, F. Ramos, Y . Narang, and I. Akinola, “FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty,” Jan. 2025, arXiv:2408.04587 [cs]
-
[11]
SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning,
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine, “SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA), May 2024, pp. 16 961–16 969
2024
-
[12]
Learning variable impedance control,
J. Buchli, F. Stulp, E. Theodorou, and S. Schaal, “Learning variable impedance control,”The International Journal of Robotics Research, vol. 30, no. 7, pp. 820–833, June 2011
2011
-
[13]
Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks,
R. Mart ´ın-Mart´ın, M. A. Lee, R. Gardner, S. Savarese, J. Bohg, and A. Garg, “Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks,” in2019 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2019, pp. 1010–1017
2019
-
[14]
Learning Force Control for Contact-Rich Manipulation Tasks With Rigid Position-Controlled Robots,
C. C. Beltran-Hernandez, D. Petit, I. G. Ramirez-Alpizar, T. Nishi, S. Kikuchi, T. Matsubara, and K. Harada, “Learning Force Control for Contact-Rich Manipulation Tasks With Rigid Position-Controlled Robots,”IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 5709–5716, Oct. 2020
2020
-
[15]
Evalua- tion of Variable Impedance- and Hybrid Force/MotionControllers for Learning Force Tracking Skills,
A. S. Anand, M. Hagen Myrestrand, and J. T. Gravdahl, “Evalua- tion of Variable Impedance- and Hybrid Force/MotionControllers for Learning Force Tracking Skills,” in2022 IEEE/SICE International Symposium on System Integration (SII), Jan. 2022, pp. 83–89
2022
-
[16]
Continuous-Discrete Reinforcement Learning for Hybrid Control in Robotics,
M. Neunert, A. Abdolmaleki, M. Wulfmeier, T. Lampe, T. Springen- berg, R. Hafner, F. Romano, J. Buchli, N. Heess, and M. Riedmiller, “Continuous-Discrete Reinforcement Learning for Hybrid Control in Robotics,” inProceedings of the Conference on Robot Learning. PMLR, May 2020, pp. 735–751, iSSN: 2640-3498
2020
-
[17]
Specification of force-controlled actions in the
H. Bruyninckx and J. De Schutter, “Specification of force-controlled actions in the ”task frame formalism”-a synthesis,”IEEE Transactions on Robotics and Automation, vol. 12, no. 4, pp. 581–589, Aug. 1996
1996
-
[18]
IndustReal: Transferring Contact- Rich Assembly Tasks from Simulation to Reality,
B. Tang, M. A. Lin, I. Akinola, A. Handa, G. S. Sukhatme, F. Ramos, D. Fox, and Y . Narang, “IndustReal: Transferring Contact- Rich Assembly Tasks from Simulation to Reality,” May 2023, arXiv:2305.17110 [cs]
-
[19]
Uncertainty-Driven Spiral Trajectory for Robotic Peg-in-Hole Assembly,
H. Kang, Y . Zang, X. Wang, and Y . Chen, “Uncertainty-Driven Spiral Trajectory for Robotic Peg-in-Hole Assembly,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6661–6668, July 2022
2022
-
[20]
AugInsert: Learn- ing Robust Visual-Force Policies via Data Augmentation for Object Assembly Tasks,
R. Diaz, A. Imdieke, V . Veeriah, and K. Desingh, “AugInsert: Learn- ing Robust Visual-Force Policies via Data Augmentation for Object Assembly Tasks,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct. 2025, pp. 18 504–18 511
2025
-
[21]
J. Luo, O. Sushkov, R. Pevceviciute, W. Lian, C. Su, M. Vecerik, N. Ye, S. Schaal, and J. Scholz, “Robust Multi-Modal Policies for Industrial Assembly via Reinforcement Learning and Demonstrations: A Large-Scale Study,” July 2021, arXiv:2103.11512 [cs]
-
[22]
Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning,
S. H. Huang, M. Zambelli, J. Kay, M. F. Martins, Y . Tassa, P. M. Pilarski, and R. Hadsell, “Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning,” Mar. 2019, arXiv:1903.08542 [cs]
-
[23]
Making Sense of Vision and Touch: Self- Supervised Learning of Multimodal Representations for Contact-Rich Tasks,
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg, “Making Sense of Vision and Touch: Self- Supervised Learning of Multimodal Representations for Contact-Rich Tasks,” in2019 International Conference on Robotics and Automation (ICRA), May 2019, pp. 8943–8950, iSSN: 2577-087X
2019
-
[24]
Efficient Sim-to-real Transfer of Contact-Rich Manipulation Skills with Online Admittance Residual Learning,
X. Zhang, C. Wang, L. Sun, Z. Wu, X. Zhu, and M. Tomizuka, “Efficient Sim-to-real Transfer of Contact-Rich Manipulation Skills with Online Admittance Residual Learning,” inProceedings of The 7th Conference on Robot Learning, Dec. 2023, pp. 1621–1639
2023
-
[25]
A survey of robot manipulation in contact,
M. Suomalainen, Y . Karayiannidis, and V . Kyrki, “A survey of robot manipulation in contact,”Robotics and Autonomous Systems, vol. 156, p. 104224, Oct. 2022
2022
-
[26]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduc- tion, 2nd ed., ser. Adaptive Computation and Machine Learning Series. Cambridge, Massachusetts: The MIT Press, 2018
2018
-
[27]
Factory: Fast Contact for Robotic Assembly,
Y . Narang, K. Storey, I. Akinola, M. Macklin, P. Reist, L. Wawrzy- niak, Y . Guo, A. Moravanszky, G. State, M. Lu, A. Handa, and D. Fox, “Factory: Fast Contact for Robotic Assembly,” May 2022, arXiv:2205.03532 [cs]
-
[28]
Siciliano, O
B. Siciliano, O. Khatib, and T. Kr ¨oger,Springer handbook of robotics. Springer, 2008, vol. 200
2008
-
[29]
Multi-Pass Q- Networks for Deep Reinforcement Learning with Parameterised Ac- tion Spaces,
C. J. Bester, S. D. James, and G. D. Konidaris, “Multi-Pass Q- Networks for Deep Reinforcement Learning with Parameterised Ac- tion Spaces,” May 2019, arXiv:1905.04388 [cs]
-
[30]
Asymmetric Actor Critic for Image-Based Robot Learning
L. Pinto, M. Andrychowicz, P. Welinder, W. Zaremba, and P. Abbeel, “Asymmetric Actor Critic for Image-Based Robot Learning,” Oct. 2017, arXiv:1710.06542 [cs]
work page Pith review arXiv 2017
-
[31]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” Aug. 2017, arXiv:1707.06347 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Simba: Simplicity bias for scaling up parameters in deep reinforcement learning,
H. Lee, D. Hwang, D. Kim, H. Kim, J. J. Tai, K. Subramanian, P. R. Wurman, J. Choo, P. Stone, and T. Seno, “Simba: Simplicity bias for scaling up parameters in deep reinforcement learning,” inInternational Conference on Learning Representations (ICLR), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.