Cognis: Context-Aware Memory for Conversational AI Agents
Pith reviewed 2026-05-14 23:27 UTC · model grok-4.3
The pith
A dual-store memory pipeline with context-aware ingestion lets conversational AI agents retain details across sessions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
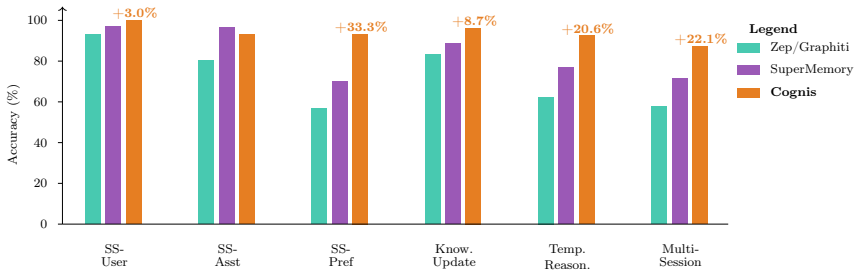
Cognis is a unified memory architecture for conversational AI agents that pairs a dual-store backend of BM25 keyword search and Matryoshka vector similarity, fused by reciprocal rank fusion, with a context-aware ingestion pipeline that retrieves prior memories before extraction to enable version tracking. Temporal boosting and a BGE-2 cross-encoder reranker further refine outputs. When evaluated on the LoCoMo and LongMemEval benchmarks using eight different answer generation models, the architecture achieves state-of-the-art performance on both.
What carries the argument
The multi-stage retrieval pipeline that runs context-aware ingestion before memory extraction, then fuses BM25 keyword matching with Matryoshka vector search via reciprocal rank fusion.
If this is right
- Agents maintain consistent memory history through version tracking during each new ingestion.
- Time-sensitive queries gain improved ranking from the temporal boosting step.
- Final result quality increases after the cross-encoder reranker reorders candidates.
- Performance gains hold across multiple underlying answer generation models.
- The open-source implementation supports direct integration into production agent systems.
Where Pith is reading between the lines
- The same dual-store plus versioned ingestion pattern could be adapted for agents that must remember tool-use histories over extended tasks.
- Accumulated memories might eventually support more accurate personalization without expanding the model's context window.
- Production deployment implies the pipeline scales to handle concurrent users without frequent store corruption.
- Extending the temporal boost to include user-specified priorities could further tailor recall in personal assistant settings.
Load-bearing premise
The two benchmarks capture the memory demands that arise in real, open-ended conversations spanning many sessions.
What would settle it
A controlled test in which users hold repeated multi-session conversations with agents and measure how accurately each agent recalls earlier details when using Cognis versus standard context-only baselines.
Figures







read the original abstract
LLM agents lack persistent memory, causing conversations to reset each session and preventing personalization over time. We present Lyzr Cognis, a unified memory architecture for conversational AI agents that addresses this limitation through a multi-stage retrieval pipeline. Cognis combines a dual-store backend pairing OpenSearch BM25 keyword matching with Matryoshka vector similarity search, fused via Reciprocal Rank Fusion. Its context-aware ingestion pipeline retrieves existing memories before extraction, enabling intelligent version tracking that preserves full memory history while keeping the store consistent. Temporal boosting enhances time-sensitive queries, and a BGE-2 cross-encoder reranker refines final result quality. We evaluate Cognis on two independent benchmarks -- LoCoMo and LongMemEval -- across eight answer generation models, demonstrating state-of-the-art performance on both. The system is open-source and deployed in production serving conversational AI applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Lyzr Cognis, a unified memory architecture for conversational AI agents. It uses a dual-store backend (OpenSearch BM25 keyword matching paired with Matryoshka vector search, fused via Reciprocal Rank Fusion), a context-aware ingestion pipeline that retrieves existing memories before extraction to enable version tracking, temporal boosting for time-sensitive queries, and a BGE-2 cross-encoder reranker. The system is evaluated on the LoCoMo and LongMemEval benchmarks across eight answer generation models and claims state-of-the-art performance on both; the implementation is released as open-source and deployed in production.
Significance. If the performance claims are robust, Cognis provides a practical, deployable solution to the persistent-memory gap in LLM agents, supporting personalization and consistency over multiple sessions. The engineering focus on a multi-stage retrieval pipeline with explicit versioning and temporal handling addresses real deployment needs. The open-source release and production deployment are concrete strengths that enable reproducibility and external validation.
major comments (2)
- [Evaluation] Evaluation section: The SOTA claim on LoCoMo and LongMemEval is presented as evidence that the architecture solves persistent memory for real-world conversational agents, yet the paper provides no discussion or evidence that these benchmarks contain multi-session traces with explicit fact updates, preference drift, or cross-session retrieval demands; without this, superior retrieval performance cannot be attributed to the context-aware ingestion and versioning components that form the central novelty.
- [Results] Results and Methods sections: No ablation studies or component-wise breakdowns are reported to quantify the contribution of the context-aware ingestion pipeline versus the retrieval stack (BM25 + Matryoshka + RRF + reranker); this omission makes it impossible to determine whether the reported gains stem from the novel memory-management features or from standard retrieval improvements.
minor comments (2)
- [Abstract] Abstract: The claim of evaluation 'across eight answer generation models' does not list the specific models; this information should be added for reproducibility.
- [Introduction] The manuscript would benefit from a short related-work subsection contrasting Cognis with prior memory-augmented agent systems (e.g., those using vector stores or episodic memory) to clarify the precise incremental contribution.
Simulated Author's Rebuttal
Thank you for the constructive review. We respond to the major comments point-by-point below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The SOTA claim on LoCoMo and LongMemEval is presented as evidence that the architecture solves persistent memory for real-world conversational agents, yet the paper provides no discussion or evidence that these benchmarks contain multi-session traces with explicit fact updates, preference drift, or cross-session retrieval demands; without this, superior retrieval performance cannot be attributed to the context-aware ingestion and versioning components that form the central novelty.
Authors: We thank the referee for highlighting this point. While the original benchmark papers describe LoCoMo and LongMemEval as testing long-context and long-term memory in multi-turn conversations, we agree that explicit analysis of fact updates and preference drift is missing. The context-aware ingestion enables version tracking which is crucial for consistency in such settings. In the revision, we will add a subsection discussing the benchmarks' characteristics and how our components address them. revision: partial
-
Referee: [Results] Results and Methods sections: No ablation studies or component-wise breakdowns are reported to quantify the contribution of the context-aware ingestion pipeline versus the retrieval stack (BM25 + Matryoshka + RRF + reranker); this omission makes it impossible to determine whether the reported gains stem from the novel memory-management features or from standard retrieval improvements.
Authors: We acknowledge the value of ablation studies. The full pipeline was evaluated as a unified system, but to isolate the impact of the context-aware ingestion, we will conduct and report additional experiments comparing the system with and without the ingestion pipeline, as well as breakdowns of the retrieval components. revision: yes
Circularity Check
No circularity: engineering system evaluated on external benchmarks
full rationale
The paper presents a memory architecture for LLM agents using standard components (BM25, Matryoshka embeddings, RRF, cross-encoder reranker) and a context-aware ingestion pipeline. Claims of SOTA performance rest entirely on results from two independent external benchmarks (LoCoMo, LongMemEval) across eight models. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims do not reduce to inputs by construction; they are empirical outcomes on held-out benchmarks. This is the expected non-finding for a system-description paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BM25 keyword matching and Matryoshka vector similarity can be fused effectively via Reciprocal Rank Fusion
- domain assumption Retrieving existing memories before extraction enables consistent version tracking
invented entities (1)
-
Lyzr Cognis architecture
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cognis combines a dual-store backend pairing OpenSearch BM25 keyword matching with Matryoshka vector similarity search, fused via Reciprocal Rank Fusion... context-aware ingestion pipeline retrieves existing memories before extraction, enabling intelligent version tracking
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
SimpleMem: Efficient Lifelong Memory for LLM Agents
URLhttps://arxiv.org/abs/2601.02553. Code available athttps://github.com/ aiming-lab/SimpleMem. Xueguang Ma, Kai Sun, Ronak Pradeep, and Jimmy Lin. A replication study of dense passage retriever.arXiv preprint arXiv:2104.05740, 2021. URLhttps://arxiv.org/abs/2104.05740. Adyasha Maharana, Dong-Ho Lee, Sergey Tuber, Mohit Jain, Francesco Barbieri, and Mohit...
work page internal anchor Pith review arXiv 2021
-
[2]
C ar efu ll y analyze all provided memories from both speakers
-
[3]
Pay special a tt en ti on to the t i m e s t a m p s to d et er mi ne the answer
-
[4]
If the question asks about a specific event or fact , look for direct evidence
-
[5]
If the memories contain c o n t r a d i c t o r y information , p r i o r i t i z e the most recent memory
- [6]
-
[7]
Always convert relative time r e f e r e n c e s to specific dates , months , or years
-
[8]
Focus only on the content of the memories from both speakers
-
[9]
Be concise but COMPLETE . For lists , include ALL items . APPROACH ( Think step by step ) :
-
[10]
First , examine all memories that contain i n f o r m a t i o n related to the question
-
[11]
Examine the t i m e s t a m p s and content of these memories ca re fu ll y
-
[12]
Look for explicit mentions of dates , times , locations , or events that answer the question
-
[13]
If the answer requires c a l c u l a t i o n ( e . g . , c o n v e r t i n g relative time r e f e r e n c e s ) , show your work
-
[14]
F or mul at e a precise , concise answer based solely on the evidence in the memories
-
[15]
Double - check that your answer directly ad dr es ses the question asked
-
[16]
FOCUS ON THE TOP 1 -3 MOST RELEVANT MEMORIES
Ensure your final answer is specific and avoids vague time r e f e r e n c e s Memories for user \{\{ s p e a k e r _ 1 _ u s e r _ i d \}\}: \{\{ s p e a k e r _ 1 _ m e m o r i e s \}\} Memories for user \{\{ s p e a k e r _ 2 _ u s e r _ i d \}\}: 28 \{\{ s p e a k e r _ 2 _ m e m o r i e s \}\} Question : \{\{ question \}\} Answer : A.3 Single-Hop Que...
-
[17]
Find the memory that directly answers the question
-
[18]
Use EXACT words / phrases from that memory ( e . g . , " T r a n s g e n d e r woman " not " Trans ")
-
[19]
For lists ( hobbies , activities , pets ) : include ALL items from the relevant memory
-
[20]
Be COMPLETE but CONCISE - give the full answer , no extra e x p l a n a t i o n
-
[21]
FOCUS ON THE SINGLE MEMORY that mentions the EXACT event in the question
IGNORE memories about di ff er ent events / topics Question : \{ question \} Complete answer from the most relevant memory : A.4 Temporal Question Prompt (Category 2) For questions asking WHEN something happened: This is a TEMPORAL question asking WHEN so me th ing happened . FOCUS ON THE SINGLE MEMORY that mentions the EXACT event in the question . Ignor...
- [22]
-
[23]
" when " -> specific date from memory
-
[24]
Use exact phrasing like " The week before X " if memory says that Question : \{ question \} Answer ( date / time from the most relevant memory ) : A.5 Multi-Hop Question Prompt (Category 3) For questions requiring careful inference from multiple facts: This is a MULTI - HOP question re qui ri ng careful inf er en ce from facts . CRITICAL IN FER EN CE RULES :
-
[25]
" S u p p o r t i n g X " != " Being X " ( e . g . , s u p p o r t i n g LGBTQ != being LGBTQ member ) 29
-
[26]
" No explicit mention " does NOT mean " No " - be careful with a s s u m p t i o n s
-
[27]
Would X be c o n s i d e r e d a member of
For " Would X be c o n s i d e r e d a member of ..." -> look for SELF - i d e n t i f i c a t i o n only
-
[28]
Would X be c o n s i d e r e d an ally
For " Would X be c o n s i d e r e d an ally ..." -> s u p p o r t i n g others = being an ally
-
[29]
Base answers ONLY on explicit s t a t e m e n t s in memories For " Would X ..." qu est io ns : - If clear evidence exists : " Yes " or " No " + brief reason - If in fe rr in g : " Likely yes " or " Likely no " + brief reason - Default to what the evidence actually shows Question : \{ question \} Answer based on evidence : A.6 Open-Domain Question Prompt ...
-
[30]
Answer in 1 -5 words MAXIMUM
-
[31]
Use EXACT terms from the top - scored memory
-
[32]
Do NOT add extra context or e x p l a n a t i o n
-
[33]
No p u n c t u a t i o n at the end Question : \{ question \} Concise answer : 30
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.