Recognition: no theorem link
SkillGraph: Graph Foundation Priors for LLM Agent Tool Sequence Recommendation
Pith reviewed 2026-05-10 19:18 UTC · model grok-4.3
The pith
SkillGraph mines a directed graph of execution transitions from successful trajectories to serve as a reusable prior for ordering tools in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
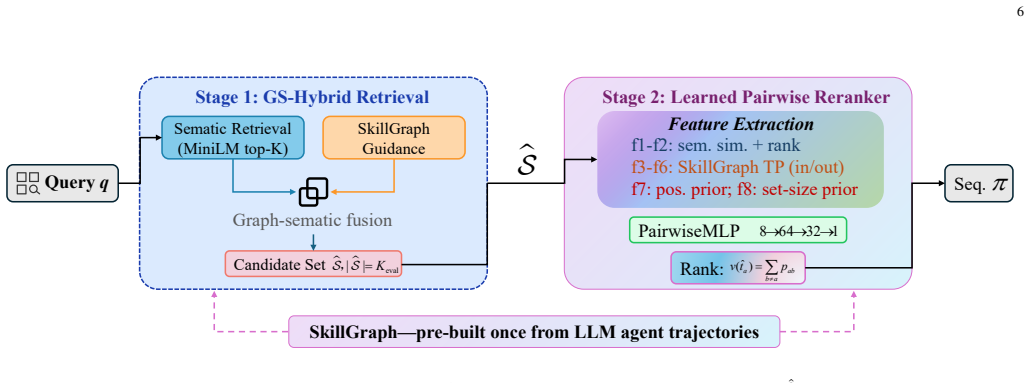
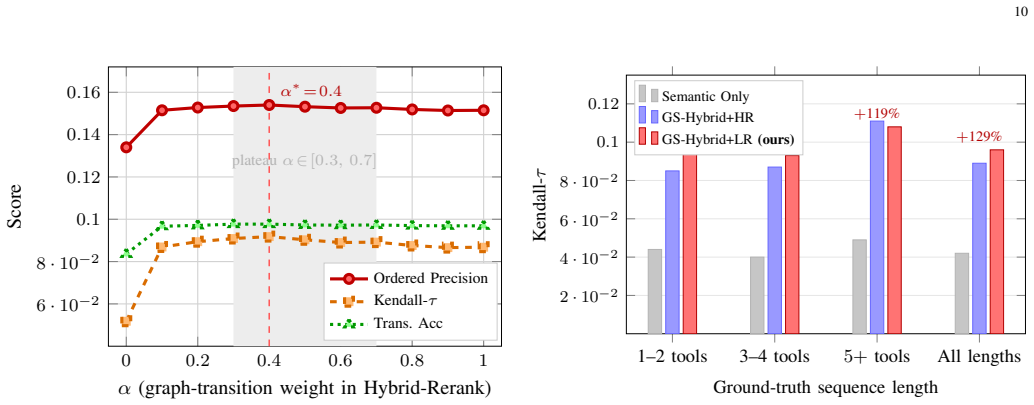
SkillGraph is a directed weighted execution-transition graph mined from 49,831 successful LLM agent trajectories that encodes reusable workflow-precedence regularities as a graph foundation prior. Using this prior in a decoupled two-stage framework of GS-Hybrid retrieval followed by a learned pairwise reranker produces Set-F1 of 0.271 and Kendall-τ of 0.096 on ToolBench and raises Kendall-τ from -0.433 to +0.613 on API-Bank, while also outperforming LLaMA-3.1-8B rerankers given identical Stage-1 candidates.
What carries the argument
SkillGraph, the directed weighted execution-transition graph that encodes inter-tool data dependencies and precedence patterns observed across successful trajectories.
If this is right
- Tool ordering can be improved by replacing semantic similarity with mined execution transitions in domains where data dependencies dominate.
- The two-stage decoupled design lets the graph prior guide candidate selection and reranking separately.
- A learned reranker conditioned on the graph prior outperforms larger LLM rerankers when both receive the same candidate sets.
- The same graph foundation can be reused across different task distributions provided the underlying tool-interaction patterns remain stable.
Where Pith is reading between the lines
- Trajectory mining may supply priors for other agent sequencing problems where textual descriptions alone are insufficient to reveal dependencies.
- Maintaining and periodically refreshing the graph from new successful runs could allow the prior to track changes in tool libraries over time.
- The approach implies that collecting and structuring execution data from deployed agents could become a standard way to bootstrap reliable workflows.
Load-bearing premise
Execution transitions mined from successful trajectories encode generalizable inter-tool data dependencies that transfer to unseen tasks and tool libraries.
What would settle it
A new test set of tasks with different tool dependencies on which the SkillGraph reranker produces negative Kendall-τ scores or lower Set-F1 than semantic baselines would falsify the claim that the mined transitions provide useful generalizable priors.
Figures





read the original abstract
LLM agents must select tools from large API libraries and order them correctly. Existing methods use semantic similarity for both retrieval and ordering, but ordering depends on inter-tool data dependencies that are absent from tool descriptions. As a result, semantic-only methods can produce negative Kendall-$\tau$ in structured workflow domains. We introduce SkillGraph, a directed weighted execution-transition graph mined from 49,831 successful LLM agent trajectories, which encodes workflow-precedence regularities as a reusable graph foundation prior. Building on this graph foundation prior, we propose a two-stage decoupled framework: GS-Hybrid retrieval for candidate selection and a learned pairwise reranker for ordering. On ToolBench (9,965 test instances; ~16,000 tools), the method reaches Set-F1 = 0.271 and Kendall-$\tau$ = 0.096; on API-Bank, Kendall-$\tau$ improves from -0.433 to +0.613. Under identical Stage-1 inputs, the learned reranker also outperforms LLaMA-3.1-8B Stage-2 rerankers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SkillGraph, a directed weighted execution-transition graph constructed from 49,831 successful LLM agent trajectories, serving as a foundation prior for inter-tool workflow precedences. It presents a two-stage framework consisting of GS-Hybrid retrieval for candidate selection followed by a learned pairwise reranker for ordering tool sequences. Empirical results on ToolBench (9,965 test instances, ~16k tools) report Set-F1 = 0.271 and Kendall-τ = 0.096, while on API-Bank Kendall-τ improves from -0.433 to +0.613, with the reranker outperforming LLaMA-3.1-8B under identical Stage-1 inputs.
Significance. If the central assumption holds—that trajectory-mined transitions capture generalizable data dependencies transferable to unseen tasks and tool libraries—the approach offers a promising way to augment semantic retrieval with structural priors for LLM agent tool use. The decoupling of retrieval and reranking stages is a practical contribution, and demonstrating superiority over both semantic baselines and LLM-based rerankers under controlled inputs highlights potential for reusable graph priors in agent planning. However, the low absolute Kendall-τ on ToolBench suggests room for further improvement in ordering quality.
major comments (3)
- [§3.1] §3.1 (Graph Construction): The construction of the SkillGraph requires explicit details on the edge weighting scheme, coverage statistics for the ~16,000-tool library, and strict separation between the 49,831 trajectories used for mining and the test instances; absent these, the claim that the graph encodes reusable workflow-precedence regularities cannot be evaluated and risks circularity with in-distribution patterns.
- [§4] §4 (Experiments): The reported Set-F1 = 0.271 and Kendall-τ = 0.096 on ToolBench, and the Kendall-τ lift on API-Bank, are presented without error bars, multiple random seeds, or statistical significance tests; this undermines assessment of whether the gains over semantic baselines are robust, especially given the modest absolute Kendall-τ value.
- [§4.2] §4.2 (Ablations and Comparisons): No ablation isolates the SkillGraph prior's contribution from the learned pairwise reranker; the outperformance versus LLaMA-3.1-8B rerankers under identical Stage-1 inputs could arise from reranker architecture differences rather than the graph component, leaving the 'graph foundation prior' framing insufficiently supported.
minor comments (2)
- [Abstract] Abstract: The GS-Hybrid retrieval component is referenced without a one-sentence definition or pointer to its description in the main text.
- [§5] §5 (Discussion): The limitations section could more explicitly address potential distribution shift between the trajectory corpus and target tool libraries.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the clarity and rigor of our work on SkillGraph. We address each major comment point-by-point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Graph Construction): The construction of the SkillGraph requires explicit details on the edge weighting scheme, coverage statistics for the ~16,000-tool library, and strict separation between the 49,831 trajectories used for mining and the test instances; absent these, the claim that the graph encodes reusable workflow-precedence regularities cannot be evaluated and risks circularity with in-distribution patterns.
Authors: We agree that these details are essential for evaluating the reusability claim. In the revised manuscript, we will expand §3.1 with: (1) the precise edge weighting scheme (normalized transition frequencies computed as co-occurrence counts divided by source-node out-degree across the 49,831 trajectories); (2) coverage statistics (e.g., number of nodes and edges intersecting the ~16k-tool library, plus the fraction of tools with at least one incoming/outgoing edge); and (3) explicit confirmation of strict separation—the 49,831 trajectories are drawn exclusively from the training split of ToolBench and API-Bank, with zero overlap to the 9,965 test instances. This separation was already enforced during data preparation to avoid leakage, and the added statistics will allow readers to assess how well the mined precedences generalize beyond the source trajectories. revision: yes
-
Referee: [§4] §4 (Experiments): The reported Set-F1 = 0.271 and Kendall-τ = 0.096 on ToolBench, and the Kendall-τ lift on API-Bank, are presented without error bars, multiple random seeds, or statistical significance tests; this undermines assessment of whether the gains over semantic baselines are robust, especially given the modest absolute Kendall-τ value.
Authors: We acknowledge that the current presentation lacks statistical rigor. In the revision we will rerun all experiments with 5 independent random seeds, report mean ± standard deviation for Set-F1 and Kendall-τ, and include paired t-tests (or Wilcoxon signed-rank tests where appropriate) against the semantic baselines to establish significance. We also agree that the absolute Kendall-τ = 0.096 on ToolBench is modest; this reflects the inherent difficulty of ordering over ~16k tools with sparse dependencies, yet the consistent relative gains and the large lift on API-Bank (from -0.433 to +0.613) still demonstrate the practical utility of the graph prior. The added statistics will allow readers to judge robustness directly. revision: yes
-
Referee: [§4.2] §4.2 (Ablations and Comparisons): No ablation isolates the SkillGraph prior's contribution from the learned pairwise reranker; the outperformance versus LLaMA-3.1-8B rerankers under identical Stage-1 inputs could arise from reranker architecture differences rather than the graph component, leaving the 'graph foundation prior' framing insufficiently supported.
Authors: This is a fair observation. While the two-stage framework is explicitly built on the graph prior (GS-Hybrid retrieval uses graph edges and the reranker is trained on graph-derived transition features), we did not include an explicit ablation that removes the graph component entirely. In the revised §4.2 we will add such an ablation: a variant that replaces graph-based features in the reranker with purely semantic or random features while keeping the same pairwise architecture and Stage-1 candidates. This will isolate the prior's contribution. We note, however, that the controlled comparison already holds Stage-1 inputs fixed and shows the learned reranker outperforming an LLaMA-3.1-8B reranker that has no access to the graph; the new ablation will further strengthen the causal link to the SkillGraph prior. revision: partial
Circularity Check
No significant circularity; derivation remains self-contained against external benchmarks
full rationale
The paper constructs SkillGraph by mining directed weighted transitions from an external corpus of 49,831 successful trajectories, then applies the resulting prior inside a two-stage pipeline (GS-Hybrid retrieval + separate learned pairwise reranker). Reported metrics (Set-F1, Kendall-τ on ToolBench and API-Bank) are measured on explicitly held-out test instances (9,965 on ToolBench) under identical Stage-1 inputs. No equation, definition, or self-citation reduces these gains to a quantity that is definitionally identical to the mined graph or the training trajectories. The central claim therefore rests on an empirical transfer assumption rather than on any algebraic or definitional identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Successful LLM agent trajectories encode reusable workflow-precedence regularities as directed execution transitions.
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[2]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs,
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qian, S. Zhao, L. Hong, R. Tian, R. Xie, J. Zhou, M. Gerstein, D. Li, Z. Liu, and M. Sun, “ToolLLM: Facilitating large language models to master 16000+ real-world APIs,” inInternational Conference on Learning Representations, 2024, spotlight. [Online]. Available: https://open...
2024
-
[3]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” in Advances in Neural Information Processing Systems, 2023. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2023/hash/ d842425e4bf79ba039352da0f658a906-...
2023
-
[4]
API-Bank: A comprehensive benchmark for tool- augmented LLMs,
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y . Li, “API-Bank: A comprehensive benchmark for tool- augmented LLMs,” inConference on Empirical Methods in Natural Language Processing, 2023, pp. 3102–3116. [Online]. Available: https://aclanthology.org/2023.emnlp-main.187/ 13
2023
-
[5]
Towards graph foundation models: A survey and beyond,
J. Liu, C. Yang, Z. Lu, J. Chen, Y . Li, M. Zhang, T. Bai, Y . Fang, L. Sun, P. S. Yu, and C. Shi, “Towards graph foundation models: A survey and beyond,”arXiv preprint arXiv:2310.11829, 2023. [Online]. Available: https://arxiv.org/abs/2310.11829
-
[6]
Tool learning with foundation models,
Y . Qin, S. Hu, Y . Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, X. Zhou, Y . Huang, C. Xiao, C. Han, Y . R. Fung, Y . Su, H. Wang, C. Qian, R. Tian, K. Zhu, S. Liang, X. Shen, B. Xu, Z. Zhang, Y . Ye, B. Li, Z. Tang, J. Yi, Y . Zhu, Z. Dai, L. Yan, X. Cong, Y . Lu, W. Zhao, Y . Huang, J. Yan, X. Han, X. Sun, D. Li, J. Phang, C. Yang, T. Wu, H. Ji, G. Li, Z. L...
-
[7]
LLM-Based Agents for Tool Learning: A survey,
W. Xu, C. Huang, S. Gao, and S. Shang, “LLM-Based Agents for Tool Learning: A survey,”Data Science and Engineering, vol. 10, pp. 533–563, 2025. [Online]. Available: https://doi.org/10.1007/ s41019-025-00296-9
2025
-
[8]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W. Yih, T. Rockt ¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,”arXiv preprint arXiv:2005.11401, 2020. [Online]. Available: https://arxiv.org/abs/2005.11401
work page internal anchor Pith review arXiv 2005
-
[9]
Sentence-BERT: Sentence embeddings using siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using siamese BERT-networks,” inConference on Empirical Methods in Natural Language Processing, 2019, pp. 3982–3992. [Online]. Available: https://aclanthology.org/D19-1410/
2019
-
[10]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W. Yih, “Dense passage retrieval for open-domain question answering,” inConference on Empirical Methods in Natural Language Processing, 2020, pp. 6769–6781. [Online]. Available: https://aclanthology.org/2020.emnlp-main.550/
2020
-
[11]
Transformers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-of-the-art natural language processing,” inConference on Empirical Methods in Natural Language...
2020
-
[12]
MAPO: Mining and recommending API usage patterns,
H. Zhong, T. Xie, L. Zhang, J. Pei, and H. Mei, “MAPO: Mining and recommending API usage patterns,” inECOOP 2009 – Object-Oriented Programming, ser. Lecture Notes in Computer Science, vol. 5653, 2009, pp. 318–343. [Online]. Available: https: //doi.org/10.1007/978-3-642-03013-0 15
-
[13]
Mining usage patterns for the android API,
H. S. Borges and M. T. Valente, “Mining usage patterns for the android API,”PeerJ Computer Science, vol. 1, p. e12, 2015. [Online]. Available: https://doi.org/10.7717/peerj-cs.12
-
[14]
Self-attentive sequential recommendation
W. Kang and J. McAuley, “Self-attentive sequential recommendation,” inIEEE International Conference on Data Mining, 2018, pp. 197–206. [Online]. Available: https://doi.org/10.1109/ICDM.2018.00035
-
[15]
Dynamic graph neural networks for sequential recommendation,
M. Zhang, S. Wu, X. Yu, Q. Liu, and L. Wang, “Dynamic graph neural networks for sequential recommendation,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 5, pp. 4741–4753,
-
[16]
Available: https://doi.org/10.1109/TKDE.2022.3151618
[Online]. Available: https://doi.org/10.1109/TKDE.2022.3151618
-
[17]
Graph-based embedding smoothing for sequential recommendation,
T. Zhu, L. Sun, and G. Chen, “Graph-based embedding smoothing for sequential recommendation,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 1, pp. 496–508, 2023. [Online]. Available: https://doi.org/10.1109/TKDE.2021.3073411
-
[18]
Data augmented sequential recommendation based on counterfactual thinking,
X. Chen, Z. Wang, H. Xu, J. Zhang, Y . Zhang, W. X. Zhao, and J. Wen, “Data augmented sequential recommendation based on counterfactual thinking,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 9, pp. 9181–9194, 2023. [Online]. Available: https://doi.org/10.1109/TKDE.2022.3222070
-
[19]
Learning to rank using gradient descent,
C. J. C. Burges, T. Shaked, E. Renshaw, A. Lazier, M. Deeds, N. Hamilton, and G. N. Hullender, “Learning to rank using gradient descent,” inInternational Conference on Machine Learning, 2005, pp. 89–96. [Online]. Available: https://dl.acm.org/doi/10.1145/1102351. 1102363
-
[20]
Learning to rank: From pairwise approach to listwise approach,
Z. Cao, T. Qin, T. Liu, M. Tsai, and H. Li, “Learning to rank: From pairwise approach to listwise approach,” inInternational Conference on Machine Learning, 2007, pp. 129–136. [Online]. Available: https://dl.acm.org/doi/10.1145/1273496.1273513
-
[21]
Fast unfolding of communities in large networks,
V . D. Blondel, J. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,”Journal of Statistical Mechanics: Theory and Experiment, vol. 2008, no. 10, p. P10008,
2008
-
[22]
Available: https://iopscience.iop.org/article/10.1088/ 1742-5468/2008/10/P10008
[Online]. Available: https://iopscience.iop.org/article/10.1088/ 1742-5468/2008/10/P10008
2008
-
[23]
Llama Team, AI@Meta, “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024. [Online]. Available: https://arxiv.org/abs/2407. 21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
The probabilistic relevance framework: Bm25 and beyond
S. Robertson and H. Zaragoza, “The probabilistic relevance framework: BM25 and beyond,”Foundations and Trends in Information Retrieval, vol. 3, no. 4, pp. 333–389, 2009. [Online]. Available: https: //dl.acm.org/doi/abs/10.1561/1500000019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.