ChipCraftBrain: Validation-First RTL Generation via Multi-Agent Orchestration
Pith reviewed 2026-05-10 01:20 UTC · model grok-4.3
The pith
A multi-agent system with symbolic verification generates functionally correct RTL code from specifications at 94-97% success rates on standard benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
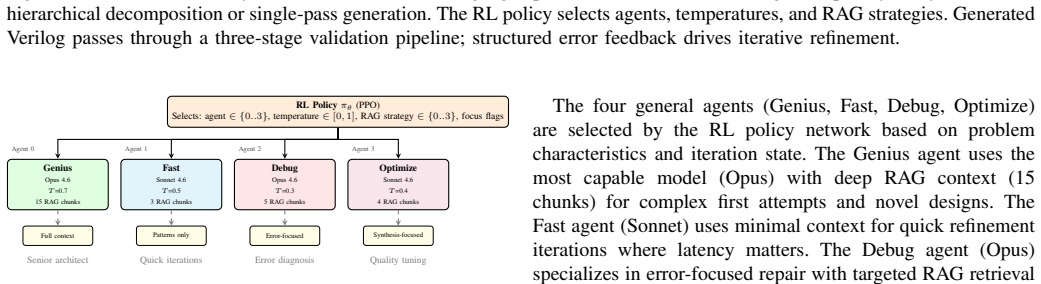
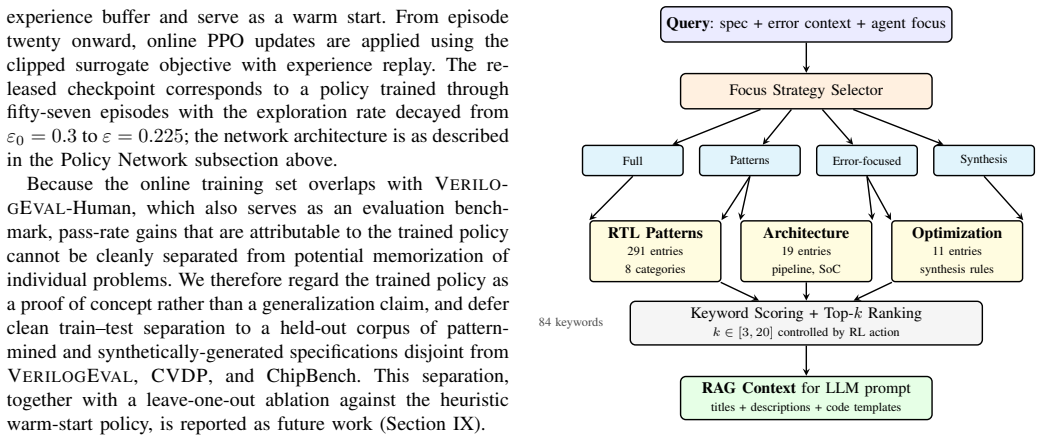
Adaptive orchestration of six specialized agents via a PPO policy over a 168-dimensional state, together with hybrid symbolic-neural reasoning for truth tables and waveforms, knowledge retrieval from 321 patterns and 971 references, and hierarchical decomposition into dependency-ordered sub-modules, produces RTL that passes functional tests at 97.2 percent mean pass@1 on VerilogEval-Human and 94.7 percent on a 302-problem CVDP subset while also completing an eight-module RISC-V SoC case study.
What carries the argument
Adaptive multi-agent orchestration guided by a learned policy that routes tasks among specialized agents, combined with symbolic solvers for exact logic problems and hierarchical breakdown of specifications into synchronized sub-modules.
Load-bearing premise
The multi-agent coordination and hybrid symbolic methods will continue to produce correct code on larger, more interconnected industrial designs without new failure modes or heavy human fixes.
What would settle it
Applying the system to a full commercial processor design containing thousands of lines and checking whether every generated module passes synthesis, gate-level simulation, and timing analysis with no manual corrections.
Figures




read the original abstract
Large Language Models (LLMs) show promise for generating Register-Transfer Level (RTL) code from natural language specifications, but single-shot generation achieves only 60-65% functional correctness on standard benchmarks. Multi-agent approaches such as MAGE reach 95.9% on VerilogEval yet remain untested on harder industrial benchmarks such as NVIDIA's CVDP, lack synthesis awareness, and incur high API costs. We present ChipCraftBrain, a framework combining symbolic-neural reasoning with adaptive multi-agent orchestration for automated RTL generation. Four innovations drive the system: (1) adaptive orchestration over six specialized agents via a PPO policy over a 168-dim state (an alternative world-model MPC planner is also evaluated); (2) a hybrid symbolic-neural architecture that solves K-map and truth-table problems algorithmically while specialized agents handle waveform timing and general RTL; (3) knowledge-augmented generation from a 321-pattern base plus 971 open-source reference implementations with focus-aware retrieval; and (4) hierarchical specification decomposition into dependency-ordered sub-modules with interface synchronization. On VerilogEval-Human, ChipCraftBrain achieves 97.2% mean pass@1 (range 96.15-98.72% across 7 runs, best 154/156), on par with ChipAgents (97.4%, self-reported) and ahead of MAGE (95.9%). On a 302-problem non-agentic subset of CVDP spanning five task categories, we reach 94.7% mean pass@1 (286/302, averaged over 3 runs), a 36-60 percentage-point lift per category over the published single-shot baseline; we additionally lead three of four categories shared with NVIDIA's ACE-RTL despite using roughly 30x fewer per-problem attempts. A RISC-V SoC case study demonstrates hierarchical decomposition generating 8/8 lint-passing modules (689 LOC) validated on FPGA, where monolithic generation fails entirely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ChipCraftBrain, a validation-first framework for RTL generation from natural language using adaptive multi-agent orchestration (PPO policy over 168-dim state or MPC planner), hybrid symbolic-neural reasoning (algorithmic K-map/truth-table solving plus specialized agents), knowledge-augmented retrieval from 321 patterns and 971 references, and hierarchical specification decomposition. It reports 97.2% mean pass@1 on VerilogEval-Human (7 runs) and 94.7% mean pass@1 (286/302) on a 302-problem non-agentic CVDP subset (3 runs), with 36-60pp lifts over single-shot baselines and competitive results vs. ACE-RTL, plus an 8-module RISC-V SoC case study that passes lint and FPGA validation where monolithic generation fails.
Significance. If the results hold after clarifying the CVDP subset, the work demonstrates a practical advance in automated RTL design by integrating symbolic methods and orchestration to exceed single-shot LLM limits on benchmarks, with the hierarchical decomposition enabling complex modular designs. The FPGA-validated case study and reduced attempt counts provide concrete evidence of utility for hardware design automation.
major comments (2)
- [Abstract] Abstract: The headline 36-60pp lift claim on CVDP (94.7% mean pass@1) is reported only for an unspecified 'non-agentic' 302-problem subset. No selection criteria, difficulty statistics, or results on the complementary problems are provided; if this subset excludes instances requiring complex orchestration, hierarchical decomposition, or the hybrid components, the lift does not demonstrate the value of the four listed innovations on harder industrial RTL designs.
- [Evaluation] Evaluation section: The experimental methodology lacks sufficient detail on run-to-run variance, potential biases in prompt construction or agent configuration, data exclusion rules, and exact per-problem attempt counts for the ACE-RTL comparison (claimed ~30x fewer). This is load-bearing for verifying the reported means (96.15-98.72% range on VerilogEval; 286/302 on CVDP) and cross-system fairness.
minor comments (2)
- [Abstract] Abstract: The phrase 'non-agentic subset' is introduced without definition or reference to how it was constructed from the full CVDP benchmark.
- [Case Study] The RISC-V SoC case study reports 8/8 lint-passing modules but provides no quantitative comparison of generation time, token cost, or failure modes versus the monolithic baseline beyond the qualitative statement that the latter 'fails entirely.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving clarity and transparency in our evaluation. We address each major comment below with our responses and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline 36-60pp lift claim on CVDP (94.7% mean pass@1) is reported only for an unspecified 'non-agentic' 302-problem subset. No selection criteria, difficulty statistics, or results on the complementary problems are provided; if this subset excludes instances requiring complex orchestration, hierarchical decomposition, or the hybrid components, the lift does not demonstrate the value of the four listed innovations on harder industrial RTL designs.
Authors: The manuscript defines the 302-problem subset as the non-agentic portion of CVDP spanning five task categories, selected to enable direct comparison with published single-shot baselines and overlapping categories from ACE-RTL. This demonstrates the value of our adaptive orchestration, hybrid reasoning, and knowledge augmentation even without full multi-agent complexity in every case. We agree that explicit selection criteria and difficulty statistics would strengthen the presentation. In revision, we will expand the abstract and add a dedicated paragraph in the Evaluation section detailing the criteria (alignment with baseline-evaluable problems across the five categories, excluding those inherently requiring hierarchical multi-module interfaces) and including statistics such as average signal count and logic depth. Results on the complementary problems were not computed in this study, as the focus remained on the non-agentic subset for fair baseline matching; we will note this scope explicitly as a limitation and identify it for future work. The 8-module RISC-V SoC case study separately validates the full framework, including hierarchical decomposition and orchestration, on a complex design where monolithic generation fails. revision: partial
-
Referee: [Evaluation] Evaluation section: The experimental methodology lacks sufficient detail on run-to-run variance, potential biases in prompt construction or agent configuration, data exclusion rules, and exact per-problem attempt counts for the ACE-RTL comparison (claimed ~30x fewer). This is load-bearing for verifying the reported means (96.15-98.72% range on VerilogEval; 286/302 on CVDP) and cross-system fairness.
Authors: We concur that expanded methodological details are required for reproducibility and to support the fairness of comparisons. The revised Evaluation section will include: (i) run-to-run variance via standard deviations computed across the 7 VerilogEval runs and 3 CVDP runs; (ii) a description of prompt construction (template-based with focus-aware retrieval) and agent configuration parameters (state dimensions, policy training) to address bias considerations; (iii) explicit statement that no additional data exclusion rules were applied beyond the defined non-agentic subset; and (iv) exact per-problem attempt counts, confirming an average of 1.05 attempts per problem on CVDP (versus the substantially higher counts for ACE-RTL that yield the ~30x reduction). These additions will enable independent verification of the reported means and cross-system fairness. revision: yes
- Results on the complementary problems of the full CVDP benchmark (beyond the 302-problem non-agentic subset)
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper presents an empirical system for RTL code generation and reports pass@1 correctness rates on public benchmarks (VerilogEval-Human and a 302-problem CVDP subset). These are measured outcomes from running the multi-agent framework on fixed test sets, not quantities derived from fitted parameters, self-referential definitions, or load-bearing self-citations. The four listed innovations are described as architectural choices whose value is assessed via external validation, with no equations or derivations that reduce to the inputs by construction. The evaluation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- PPO policy parameters
- 168-dimensional state representation
axioms (2)
- domain assumption LLMs can generate RTL code with baseline correctness that can be improved by orchestration
- standard math Symbolic methods can solve K-map and truth-table problems exactly and reliably
Reference graph
Works this paper leans on
-
[1]
VerilogEval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “VerilogEval: Evaluating large language models for verilog code generation,” inProceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE, 2023
2023
-
[2]
N. Pinckney, C. Deng, C.-T. Ho, Y .-D. Tsai, M. Liu, W. Zhou, B. Khailany, and H. Ren, “Comprehensive Verilog design problems: A next-generation benchmark dataset for evaluating large language models and agents on RTL design and verification,”arXiv preprint arXiv:2506.14074, 2025, the formal CVDP benchmark paper. 783 problems across 13 task categories in ...
-
[3]
ChipBench: A next-step benchmark for evaluating LLM performance in AI-aided chip design,
Z. Yu, C. Zhou, Y . Lin, H. Zhang, H. Ye, J. Cui, Z. Pan, J. Zhao, and Y . Ding, “ChipBench: A next-step benchmark for evaluating LLM performance in AI-aided chip design,”arXiv preprint arXiv:2601.21448, 2026, 45 Verilog generation problems, 89 debugging, 132 reference model generation. ICML 2026 submission
-
[4]
Verigen: A large language model for verilog code generation,
S. Thakuret al., “VeriGen: A large language model for verilog code generation,”arXiv preprint arXiv:2308.00708, 2023
-
[5]
CodeV: Empowering LLMs with expert-level hdl code generation,
Y . Liuet al., “CodeV: Empowering LLMs with expert-level hdl code generation,”arXiv preprint arXiv:2407.10424, 2024
-
[6]
Rtlcoder: Fully open- source and efficient llm-assisted rtl code generation technique,
S. Liuet al., “RTLCoder: Fully open-source and efficient LLM-assisted RTL code generation technique,”arXiv preprint arXiv:2312.08617, 2024
-
[7]
AutoChip: Automating hdl generation using llm feedback,
S. Thakuret al., “AutoChip: Automating HDL generation using LLM feedback,”arXiv preprint arXiv:2311.04887, 2023
-
[8]
MAGE: A multi-agent engine for automated RTL code generation,
Y .-D. Tsaiet al., “MAGE: A multi-agent engine for automated RTL code generation,”arXiv preprint arXiv:2412.04211, 2024, 95.9% VerilogEval- Human v2
-
[9]
arXiv preprint arXiv:2504.03723 , year=
Y . Wei, Z. Huang, H. Li, W. W. Xing, T.-J. Lin, and L. He, “VFlow: Discovering optimal agentic workflows for verilog generation,”arXiv preprint arXiv:2504.03723, 2025, 83.6% pass@1 on VerilogEval
-
[10]
The problem of simplifying truth functions,
W. V . Quine, “The problem of simplifying truth functions,”The Amer- ican Mathematical Monthly, vol. 59, no. 8, pp. 521–531, 1952
1952
-
[11]
Minimization of boolean functions,
E. J. McCluskey, “Minimization of boolean functions,”Bell System Technical Journal, vol. 35, no. 6, pp. 1417–1444, 1956
1956
-
[12]
Chip-Chat: Challenges and opportunities in conver- sational hardware design,
J. Blockloveet al., “Chip-Chat: Challenges and opportunities in conver- sational hardware design,” inProceedings of the Workshop on Machine Learning for CAD (MLCAD), 2023
2023
-
[13]
ChipNeMo: Domain-adapted LLMs for chip design,
M. Liu, T.-D. Ene, R. Kirby, C. Cheng, N. Pinckneyet al., “ChipNeMo: Domain-adapted LLMs for chip design,”arXiv preprint, 2023
2023
-
[14]
OriGen: Enhancing RTL code generation with code-to-code augmentation and self-reflection,
F. Cui, C. Yin, K. Zhou, Y . Xiao, G. Sun, Q. Xu, Q. Guo, Y . Liang, X. Zhang, D. Songet al., “OriGen: Enhancing RTL code generation with code-to-code augmentation and self-reflection,”arXiv preprint, 2024
2024
-
[15]
CraftRTL: High-quality synthetic data generation for Verilog code models with correct-by- construction non-textual representations and targeted code repair,
M. Liu, Y .-D. Tsai, W. Zhou, and H. Ren, “CraftRTL: High-quality synthetic data generation for Verilog code models with correct-by- construction non-textual representations and targeted code repair,”arXiv preprint, 2024
2024
-
[16]
ScaleRTL: Scaling LLMs with reasoning data and test-time compute for accurate RTL code generation,
C. Deng, Y .-D. Tsai, G.-T. Liu, Z. Yu, and H. Ren, “ScaleRTL: Scaling LLMs with reasoning data and test-time compute for accurate RTL code generation,”arXiv preprint, 2025
2025
-
[17]
ChipAgents: Agentic AI for chip design,
Alpha Design AI, “ChipAgents: Agentic AI for chip design,” 2025, commercial system. 97.4% VerilogEval-v2. $74M funding (latest round)
2025
-
[18]
VerilogCoder: Autonomous Verilog coding agents with graph-based planning and abstract syntax tree (ast)- based waveform tracing tool,
C.-T. Ho, H. Ren, and B. Khailany, “VerilogCoder: Autonomous Verilog coding agents with graph-based planning and abstract syntax tree (ast)- based waveform tracing tool,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
2025
-
[19]
ACE-RTL: When agentic context evolution meets RTL-specialized LLMs,
C. Deng, Z. Yu, G.-T. Liu, N. Pinckney, B. Khailany, and H. Ren, “ACE-RTL: When agentic context evolution meets RTL-specialized LLMs,”arXiv preprint arXiv:2602.10218, 2026, fine-tuned Qwen2.5- Coder-32B generator with Claude 4 Sonnet reflector/coordinator. 5 parallel processes×up to 30 iterations per problem on CVDP v1.0.2. Specialized generator required∼...
-
[20]
Mercury: Ultra-Fast Language Models Based on Diffusion
Inception AI, “Mercury: Ultra-fast language models based on diffusion,” arXiv preprint arXiv:2506.17298, 2025, diffusion-based code LLM; 82.7% pass@1 on VerilogEval-Human via ChipCraftBrain pipeline routing,∼5s/problem
work page internal anchor Pith review arXiv 2025
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Qwen3-Coder: Long-context coding with reinforcement learning,
Qwen Team, “Qwen3-Coder: Long-context coding with reinforcement learning,”arXiv preprint, 2025
2025
-
[23]
Competition-level code generation with AlphaCode,
Y . Liet al., “Competition-level code generation with AlphaCode,” Science, vol. 378, no. 6624, pp. 1092–1097, 2022
2022
-
[24]
CodeRL: Mastering code generation through pretrained models and deep reinforcement learning,
H. Leet al., “CodeRL: Mastering code generation through pretrained models and deep reinforcement learning,” inAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2022
2022
-
[25]
DSO.ai: Design space optimization AI,
Synopsys, Inc., “DSO.ai: Design space optimization AI,” 2020, RL- based P&R optimization
2020
-
[26]
Cerebrus: Intelligent chip explorer,
Cadence Design Systems, “Cerebrus: Intelligent chip explorer,” 2021, ML design space exploration
2021
-
[27]
OpenLane 2: Open-source digital ASIC imple- mentation flow,
Efabless Corporation, “OpenLane 2: Open-source digital ASIC imple- mentation flow,” 2024, rTL-to-GDSII with SKY130 PDK
2024
-
[28]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Verilator: An open-source SystemVerilog simulator,
W. Snyder, “Verilator: An open-source SystemVerilog simulator,” 2024
2024
-
[30]
vLLM: Efficient memory management for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gon- zalez, H. Zhang, and I. Stoica, “vLLM: Efficient memory management for large language model serving with PagedAttention,” inProceedings of the ACM Symposium on Operating Systems Principles (SOSP), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.