Recognition: unknown
DistortBench: Benchmarking Vision Language Models on Image Distortion Identification
Pith reviewed 2026-05-10 02:47 UTC · model grok-4.3
The pith
Vision-language models reach only 61.9 percent accuracy on image distortion identification, falling below the human majority-vote baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
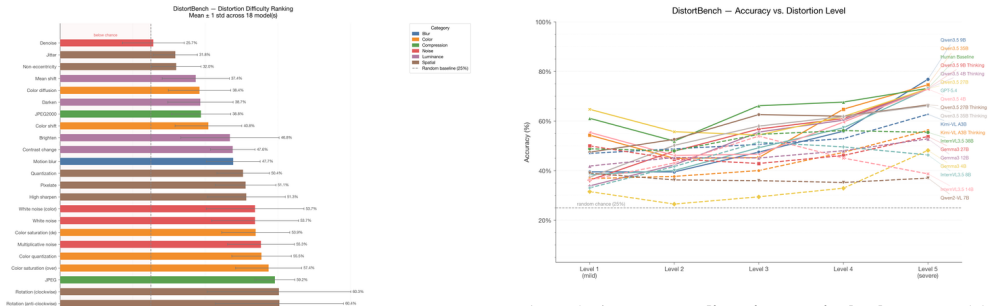
DistortBench demonstrates that current vision-language models possess only limited ability to identify distortion type and severity in images, with the top model achieving 61.9 percent accuracy compared to a 65.7 percent human majority-vote baseline and 60.2 percent average individual human score. The benchmark isolates no-reference distortion perception through multiple-choice questions and reveals further regularities including non-monotonic scaling with model size, drops in performance for most base-to-thinking model pairs, and family-specific patterns in how models respond to increasing severity.
What carries the argument
DistortBench, a collection of 13,500 four-choice questions covering 27 distortion types across calibrated severity levels that forces models to name the distortion without reference to an undistorted original image.
If this is right
- Low-level perceptual understanding stays a major limitation for vision-language models even when high-level task performance is strong.
- Scaling model size produces only weak and non-monotonic gains on distortion identification.
- Most models lose accuracy when moving from base versions to their thinking or reasoning variants.
- Different model families exhibit distinct response curves as distortion severity increases.
- The benchmark supplies a concrete diagnostic for tracking progress on low-level visual perception.
Where Pith is reading between the lines
- Applications that rely on detecting subtle image quality issues, such as automated restoration pipelines or moderation filters for compressed uploads, may inherit the same accuracy ceiling observed here.
- Training objectives that reward explicit modeling of perceptual distance or severity could close the gap to human performance more effectively than further scaling alone.
- The same weakness may appear in other low-level visual judgments, such as estimating lighting consistency or detecting synthetic image artifacts, that current benchmarks overlook.
Load-bearing premise
The multiple-choice format and question construction prevent models from using high-level semantic content, language priors, or generation artifacts to guess the correct distortion label.
What would settle it
Running the same models on a version of the questions where all images are replaced by pure noise patterns or abstract textures with no recognizable objects, then checking whether accuracy remains near 61.9 percent or drops to chance.
Figures




read the original abstract
Vision-language models (VLMs) are increasingly used in settings where sensitivity to low-level image degradations matters, including content moderation, image restoration, and quality monitoring. Yet their ability to recognize distortion type and severity remains poorly understood. We present DistortBench, a diagnostic benchmark for no-reference distortion perception in VLMs. DistortBench contains 13,500 four-choice questions covering 27 distortion types, six perceptual categories, and five severity levels: 25 distortions inherit KADID-10k calibrations, while two added rotation distortions use monotonic angle-based levels. We evaluate 18 VLMs, including 17 open-weight models from five families and one proprietary model. Despite strong performance on high-level vision-language tasks, the best model reaches only 61.9% accuracy, just below the human majority-vote baseline of 65.7% (average individual: 60.2%), indicating that low-level perceptual understanding remains a major weakness of current VLMs. Our analysis further reveals weak and non-monotonic scaling with model size, performance drops in most base--thinking pairs, and distinct severity-response patterns across model families. We hope DistortBench will serve as a useful benchmark for measuring and improving low-level visual perception in VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DistortBench, a benchmark of 13,500 four-choice questions spanning 27 distortion types (25 inherited from KADID-10k with existing calibrations plus two rotation distortions defined by monotonic angle levels), six perceptual categories, and five severity levels. It evaluates 18 VLMs (17 open-weight from five families plus one proprietary) and reports that the strongest model reaches 61.9% accuracy, just below the human majority-vote baseline of 65.7% (individual human average 60.2%). The authors conclude that low-level perceptual understanding remains a major weakness of current VLMs, supported by additional observations of weak/non-monotonic scaling with size, drops from base to thinking variants, and family-specific severity-response patterns.
Significance. If the questions validly isolate low-level distortion perception, the results would be significant: they supply a reproducible diagnostic showing a clear gap between high-level VLM capabilities and human-level sensitivity to image degradations, with direct relevance to applications such as restoration, quality monitoring, and content moderation. The use of calibrated source data, human baselines, and cross-family analysis strengthens the contribution; the benchmark itself could become a standard testbed if its validity is confirmed.
major comments (2)
- [§3] §3 (Benchmark Construction and Question Generation): The central claim that low accuracy demonstrates weakness in low-level perceptual understanding requires that models cannot solve items via high-level semantic content, object recognition, or language priors on common distortions. KADID-10k images contain recognizable scenes and objects, yet the manuscript provides no semantic-matched control sets, abstract-texture subsets, option-shuffling ablations, or explicit checks that distractors cannot be eliminated by scene semantics (e.g., ruling out “JPEG compression” on a face image). This is load-bearing for the headline result.
- [§4.2–4.3] §4.2–4.3 (Human Baseline and Model Comparisons): The reported human majority-vote accuracy (65.7%) and individual average (60.2%) are presented without details on the number of annotators per question, inter-annotator agreement, or statistical tests comparing model vs. human performance. Similarly, the non-monotonic scaling and base–thinking drops lack controls for prompt sensitivity or difficulty stratification, weakening the supporting analyses.
minor comments (2)
- [Abstract] The abstract states “six perceptual categories” but does not list them; a short table or explicit enumeration in §3 would improve clarity.
- [§5] Figure captions for severity-response patterns should include error bars or confidence intervals to allow visual assessment of the reported family differences.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of benchmark validity and reporting rigor that we address point by point below. We indicate where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction and Question Generation): The central claim that low accuracy demonstrates weakness in low-level perceptual understanding requires that models cannot solve items via high-level semantic content, object recognition, or language priors on common distortions. KADID-10k images contain recognizable scenes and objects, yet the manuscript provides no semantic-matched control sets, abstract-texture subsets, option-shuffling ablations, or explicit checks that distractors cannot be eliminated by scene semantics (e.g., ruling out “JPEG compression” on a face image). This is load-bearing for the headline result.
Authors: We agree that isolating low-level perception is essential to the central claim. The benchmark uses four-choice questions in which every option is a specific distortion type drawn from the same calibrated set, and images span diverse scenes; semantic priors alone cannot consistently eliminate distractors because multiple distortions remain plausible for any given scene. Nevertheless, the original submission did not include explicit controls such as option shuffling or semantic-matched subsets. In revision we will add (i) an option-shuffling ablation on a 1,000-question subset and (ii) a short discussion quantifying the residual risk of semantic shortcuts, thereby making the isolation argument more robust without altering the headline numbers. revision: partial
-
Referee: [§4.2–4.3] §4.2–4.3 (Human Baseline and Model Comparisons): The reported human majority-vote accuracy (65.7%) and individual average (60.2%) are presented without details on the number of annotators per question, inter-annotator agreement, or statistical tests comparing model vs. human performance. Similarly, the non-monotonic scaling and base–thinking drops lack controls for prompt sensitivity or difficulty stratification, weakening the supporting analyses.
Authors: We accept that fuller reporting is required. The human study used five annotators per question; we will report this number, Fleiss’ kappa for inter-annotator agreement, and McNemar’s tests comparing each model to the majority-vote baseline. For the scaling and base–thinking analyses we will add (i) results across two prompt templates and (ii) performance stratified by the five severity levels to confirm the observed non-monotonicity and drops are not artifacts of prompt choice or difficulty imbalance. revision: yes
Circularity Check
No circularity in empirical benchmark reporting
full rationale
The paper introduces DistortBench and reports direct empirical accuracies from evaluating 18 VLMs on 13,500 four-choice questions against human baselines (best model 61.9%, human majority 65.7%). No mathematical derivations, first-principles predictions, parameter fittings, or self-citation chains exist that reduce claims to inputs by construction. All results are externally verifiable via the benchmark construction and annotations described.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption KADID-10k severity calibrations accurately reflect human perceptual judgments for the 25 inherited distortions
- domain assumption Four-choice questions can isolate low-level distortion identification from high-level semantic understanding in VLMs
invented entities (1)
-
DistortBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Deep neural net- works for no-reference and full-reference image quality as- sessment.IEEE Transactions on Image Processing, 27(1): 206–219, 2018
Sebastian Bosse, Dominique Maniry, Klaus-Robert M ¨uller, Thomas Wiegand, and Wojciech Samek. Deep neural net- works for no-reference and full-reference image quality as- sessment.IEEE Transactions on Image Processing, 27(1): 206–219, 2018. 1
2018
-
[3]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 1, 5
work page internal anchor Pith review arXiv 2024
-
[4]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 1, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
MUSIQ: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. MUSIQ: Multi-scale image quality transformer. InICCV, pages 5148–5157, 2021. 1, 2
2021
-
[6]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Yinmin Liang, Ion Stoica, and Lianmin Zheng. Efficient memory management for large language model serving with PagedAttention. InSOSP, 2023. 5
2023
-
[7]
Most apparent distortion: full-reference image quality assessment and the role of strategy.Journal of Electronic Imaging, 19 (1):011006, 2010
Eric Cooper Larson and Damon Michael Chandler. Most apparent distortion: full-reference image quality assessment and the role of strategy.Journal of Electronic Imaging, 19 (1):011006, 2010. 2
2010
-
[8]
KADID-10K: A large-scale artificially distorted IQA database
Hanhe Lin, Vlad Hosu, and Dietmar Saupe. KADID-10K: A large-scale artificially distorted IQA database. InInter- national Conference on Quality of Multimedia Experience (QoMEX), pages 1–3. IEEE, 2019. 2, 3, 18
2019
-
[9]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 1
2023
-
[10]
MMBench: Is your multi-modal model an all-around player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. MMBench: Is your multi-modal model an all-around player? InECCV, 2024. 2
2024
-
[11]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. InNeurIPS,
-
[12]
No-reference image quality assessment in the spa- tial domain.IEEE Transactions on Image Processing, 21 (12):4695–4708, 2012
Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spa- tial domain.IEEE Transactions on Image Processing, 21 (12):4695–4708, 2012. 1, 2
2012
-
[13]
Introducing GPT-5.4.https://openai.com/ index/introducing-gpt-5-4/, 2026
OpenAI. Introducing GPT-5.4.https://openai.com/ index/introducing-gpt-5-4/, 2026. 1, 5
2026
-
[14]
Im- age database TID2013: Peculiarities, results and perspec- tives.Signal Processing: Image Communication, 30:57–77,
Nikolay Ponomarenko, Lina Jin, Oleg Ieremeiev, Vladimir Lukin, Karen Egiazarian, Jaakko Astola, Benoit V ozel, Kacem Chehdi, Marco Carli, Federica Battisti, et al. Im- age database TID2013: Peculiarities, results and perspec- tives.Signal Processing: Image Communication, 30:57–77,
-
[15]
A statistical evaluation of recent full reference image quality assessment algorithms.IEEE Transactions on Image Pro- cessing, 15(11):3440–3451, 2006
Hamid R Sheikh, Muhammad F Sabir, and Alan C Bovik. A statistical evaluation of recent full reference image quality assessment algorithms.IEEE Transactions on Image Pro- cessing, 15(11):3440–3451, 2006. 2
2006
-
[16]
Blindly assess image qual- ity in the wild guided by a self-adaptive hyper network
Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image qual- ity in the wild guided by a self-adaptive hyper network. In CVPR, pages 3667–3676, 2020. 2
2020
-
[17]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chen- zhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Hao- tian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, H...
2025
-
[18]
Media forensics and DeepFakes: An overview.IEEE Journal of Selected Topics in Signal Pro- cessing, 14(5):910–932, 2020
Luisa Verdoliva. Media forensics and DeepFakes: An overview.IEEE Journal of Selected Topics in Signal Pro- cessing, 14(5):910–932, 2020. 1
2020
-
[19]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Process- ing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Process- ing, 13(4):600–612, 2004. 1, 2
2004
-
[21]
Chain-of-thought prompting elicits reasoning in large language models.NeurIPS, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.NeurIPS, 2022. 8
2022
-
[22]
Q-Bench: A benchmark for general-purpose foundation models on low-level vision
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai, et al. Q-Bench: A benchmark for general-purpose foundation models on low-level vision. In ICLR, 2024. 1, 2 9
2024
-
[23]
Q-Align: Teaching LMMs for visual scoring via discrete text-defined levels.ICML, 2024
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Kaixin Xu, Chunyi Li, Jingwen Hou, Guangtao Zhai, et al. Q-Align: Teaching LMMs for visual scoring via discrete text-defined levels.ICML, 2024. 2
2024
-
[24]
Zhiyuan You, Zheyuan Li, Jinjin Gu, Zhenfei Yin, Tianfan Xue, and Chao Dong. Depicting beyond scores: Advanc- ing image quality assessment through multi-modal language models.arXiv preprint arXiv:2312.08962, 2024. 2
-
[25]
MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert AGI. InCVPR, 2024. 2
2024
-
[26]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timo- fte. Designing a practical degradation model for deep blind image super-resolution. InICCV, pages 4791–4800, 2021. 1
2021
-
[27]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595,
-
[28]
Zicheng Zhang, Haoning Wu, Erli Zhang, Guangtao Zhai, and Xiongkuo Min. A benchmark for multi-modal founda- tion models on low-level vision: from single images to pairs. arXiv preprint arXiv:2402.07116, 2024. 1 10 Supplementary Material This appendix provides extended quantitative breakdowns, qualitative examples, and distortion-generation details that su...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.