Recognition: unknown
Large language models perceive cities through a culturally uneven baseline
Pith reviewed 2026-05-10 01:52 UTC · model grok-4.3
The pith
Large language models describe cities from a culturally uneven baseline rather than a neutral one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
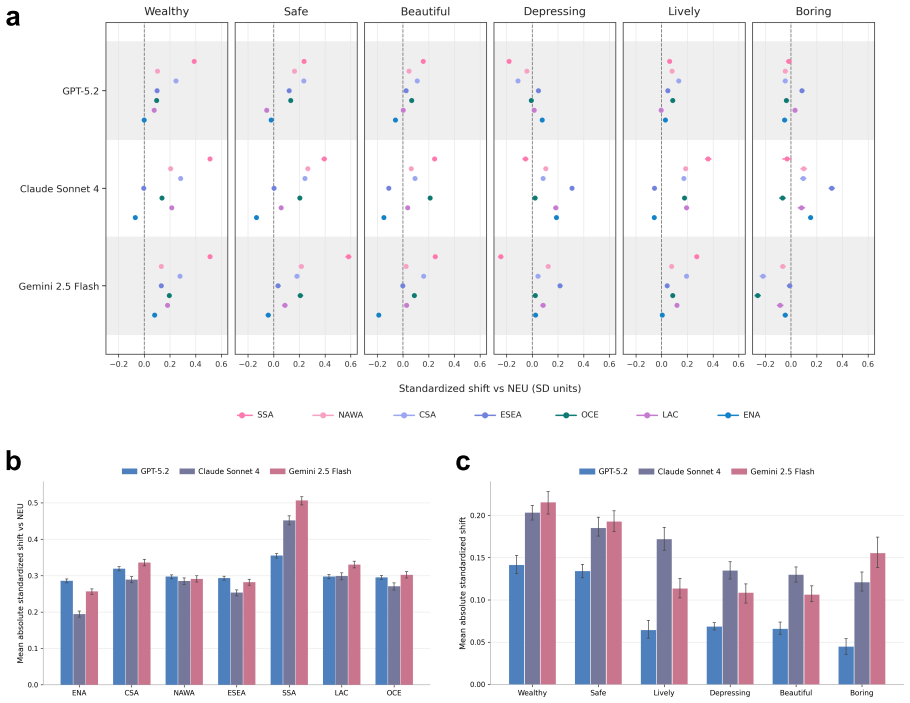
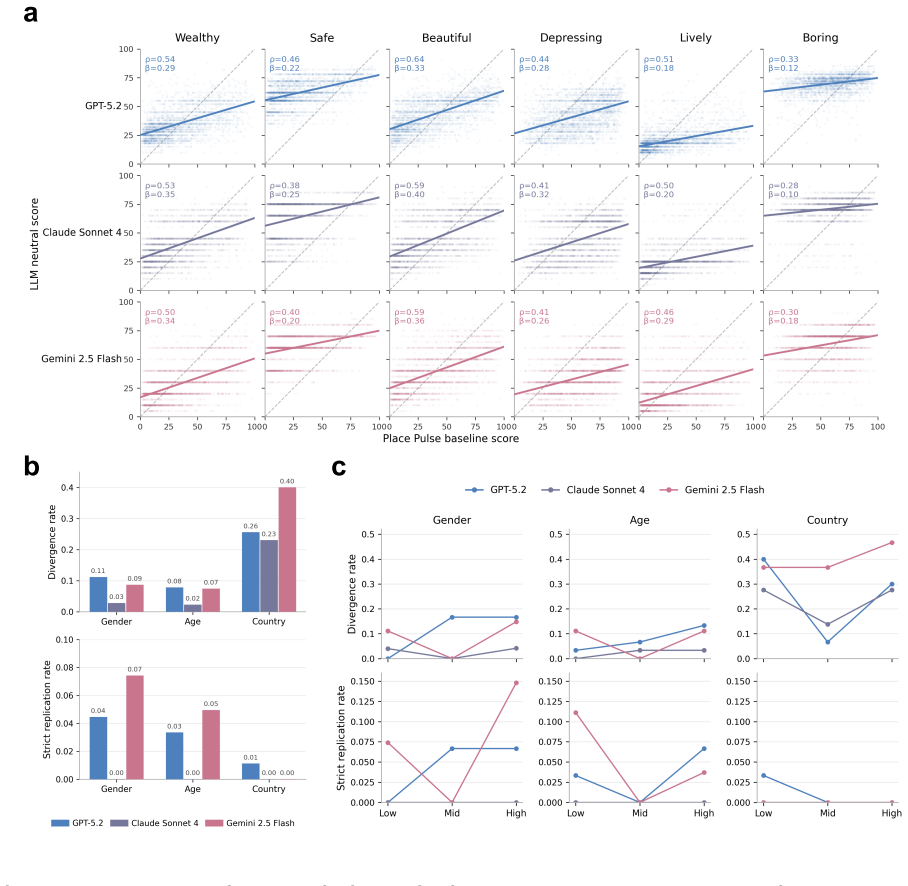
The paper establishes that frontier LLMs perceive cities through a culturally uneven baseline. Tests using open-ended descriptions and structured judgments on global street-view images show that neutral prompts are not neutral in practice, since Europe and Northern America prompts stay systematically closer to the baseline than many non-Western prompts. This indicates perception is organized around a culturally uneven reference frame. Cultural prompting shifts affective evaluation and produces sentiment-based ingroup preference for some identities. It improves alignment with human descriptions in comparisons to regional benchmarks but does not recover human semantic diversity and preserves a
What carries the argument
The culturally uneven reference frame identified through comparisons of neutral prompt outputs to those from regionally specific cultural prompts applied to the same global street-view sample.
If this is right
- LLMs will systematically favor Western-associated perceptions when used without cultural context for urban analysis.
- Cultural prompting offers a way to adjust outputs toward regional human views but does not eliminate all stylistic and diversity gaps.
- Judgments on attributes such as wealth, boredom, or depression will vary depending on the cultural standpoint invoked.
- Applications in tourism or planning risk embedding these uneven valuations unless prompting is adjusted.
Where Pith is reading between the lines
- If the baseline is retrained on more diverse cultural data, the asymmetry between neutral and regional prompts might decrease.
- Similar uneven reference frames could appear in LLM interpretations of other global topics beyond cities.
- Users in non-Western regions might need explicit prompting to get descriptions that match local human perspectives more closely.
Load-bearing premise
The selected global street-view images provide a balanced and representative sample across cultures, and the regional cultural prompts invoke distinct standpoints without introducing other uncontrolled variables in how the models respond.
What would settle it
If neutral prompts were found to be equally close to all regional cultural prompts or if European and Northern American prompts did not show systematic closeness to the baseline, that would contradict the existence of a culturally uneven reference frame.
Figures


read the original abstract
Large language models (LLMs) are increasingly used to describe, evaluate and interpret places, yet it remains unclear whether they do so from a culturally neutral standpoint. Here we test urban perception in frontier LLMs using a balanced global street-view sample and prompts that either remain neutral or invoke different regional cultural standpoints. Across open-ended descriptions and structured place judgments, the neutral condition proved not to be neutral in practice. Prompts associated with Europe and Northern America remained systematically closer to the baseline than many non-Western prompts, indicating that model perception is organized around a culturally uneven reference frame rather than a universal one. Cultural prompting also shifted affective evaluation, producing sentiment-based ingroup preference for some prompted identities. Comparisons with regional human text-image benchmarks showed that culturally proximate prompting could improve alignment with human descriptions, but it did not recover human levels of semantic diversity and often preserved an affectively elevated style. The same asymmetry reappeared in structured judgments of safety, beauty, wealth, liveliness, boredom and depression, where model outputs were interpretable but only partly reproduced human group differences. These findings suggest that LLMs do not simply perceive cities from nowhere: they do so through a culturally uneven baseline that shapes what appears ordinary, familiar and positively valued.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that large language models do not perceive cities from a culturally neutral standpoint. Using a balanced global street-view sample and prompts that are either neutral or invoke different regional cultural standpoints, it finds that the neutral condition is not neutral in practice: prompts associated with Europe and Northern America remain systematically closer to the baseline than many non-Western prompts. This indicates that model perception is organized around a culturally uneven reference frame. Cultural prompting shifts affective evaluation (producing sentiment-based ingroup preference for some identities), improves alignment with some human text-image benchmarks but fails to recover human semantic diversity levels, and yields interpretable but only partly matching outputs on structured judgments of safety, beauty, wealth, liveliness, boredom, and depression.
Significance. If the results hold after addressing methodological gaps, this work would be significant for the field of AI ethics and computational social science. It provides empirical evidence that LLMs embed culturally uneven defaults in place-perception tasks, with implications for applications in urban planning, geography, and cross-cultural AI systems. The use of a global street-view sample and direct comparisons to human benchmarks are strengths, though the partial alignment findings highlight limits in using cultural prompting to debias outputs.
major comments (3)
- [Methods] Methods section: The abstract reports systematic differences and partial alignment with human data but provides no visible statistical details, sample sizes, exclusion criteria, or error analysis for the street-view images or model responses. This is load-bearing for the central claim that the neutral condition proved not to be neutral, as it prevents verification of effect sizes, significance of distances to baseline, and robustness against sampling variability.
- [Results] Results and prompt design: The claim that neutral prompts are closer to Western-associated ones than non-Western ones requires that cultural prompts activate distinct standpoints without introducing uncontrolled variables (e.g., differences in response length, formality, lexical diversity, or implicit assumptions). The manuscript should include explicit controls or post-hoc analyses (e.g., comparing output statistics across prompt types) to rule out prompt-engineering artifacts as the source of the observed asymmetry.
- [Results] Human benchmark comparisons: The paper states that culturally proximate prompting improves alignment with human descriptions but does not recover human levels of semantic diversity. The specific metrics used for semantic diversity, the exact human datasets, and quantitative differences should be detailed with statistical tests to support the interpretation that LLMs preserve an affectively elevated style.
minor comments (2)
- [Abstract] Abstract: Consider adding the specific LLMs tested and the total number of prompts or images evaluated to give readers immediate context for the scale of the study.
- [Figures] Figures and tables: Ensure all visualizations of distances, sentiment shifts, or judgment distributions include error bars, sample sizes per condition, and clear legends; some reported patterns (e.g., ingroup preference) would benefit from accompanying numerical tables.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us strengthen the methodological transparency and robustness of the manuscript. We address each major comment below and have revised the paper accordingly to provide the requested statistical details, controls, and expanded comparisons.
read point-by-point responses
-
Referee: [Methods] Methods section: The abstract reports systematic differences and partial alignment with human data but provides no visible statistical details, sample sizes, exclusion criteria, or error analysis for the street-view images or model responses. This is load-bearing for the central claim that the neutral condition proved not to be neutral, as it prevents verification of effect sizes, significance of distances to baseline, and robustness against sampling variability.
Authors: We agree that the original Methods section required greater statistical transparency to support the central claims. In the revised manuscript we have expanded this section to report the full sample (1,200 balanced global street-view images, 100 per region across 12 regions), explicit exclusion criteria (images with resolution below 512x512 or containing non-street elements, <4% exclusion), error analysis (bootstrap standard errors and 95% CIs on all distance-to-baseline metrics), and statistical tests (permutation tests for neutral vs. Western proximity, with reported effect sizes). These additions allow direct verification of the reported asymmetries. revision: yes
-
Referee: [Results] Results and prompt design: The claim that neutral prompts are closer to Western-associated ones than non-Western ones requires that cultural prompts activate distinct standpoints without introducing uncontrolled variables (e.g., differences in response length, formality, lexical diversity, or implicit assumptions). The manuscript should include explicit controls or post-hoc analyses (e.g., comparing output statistics across prompt types) to rule out prompt-engineering artifacts as the source of the observed asymmetry.
Authors: We have added a dedicated prompt-validation subsection with post-hoc controls. We compared output statistics across all prompt conditions: mean response length (neutral: 248 tokens; cultural range: 241–255; ANOVA p=0.38), lexical diversity (type-token ratio, no significant differences), formality scores (via established NLP classifiers), and a manual audit of implicit assumptions on a 10% subsample. Sensitivity checks using length-normalized prompts and fixed-output constraints confirm that the observed baseline asymmetries persist and are not artifacts of prompt engineering. revision: yes
-
Referee: [Results] Human benchmark comparisons: The paper states that culturally proximate prompting improves alignment with human descriptions but does not recover human levels of semantic diversity. The specific metrics used for semantic diversity, the exact human datasets, and quantitative differences should be detailed with statistical tests to support the interpretation that LLMs preserve an affectively elevated style.
Authors: We have substantially expanded the human-benchmark section. Semantic diversity is now quantified via two metrics (mean pairwise cosine similarity of sentence embeddings and normalized unique bigram counts). Human reference data are drawn from Place Pulse 2.0 (Western regions) and matched regional urban-perception corpora (N>400 descriptions each for non-Western regions). Revised results include exact quantitative gaps (LLM diversity 18–22% lower than human baselines) together with statistical tests (Mann–Whitney U, p<0.001 across conditions), confirming that cultural prompting narrows but does not close the gap and that an affectively elevated style is retained. revision: yes
Circularity Check
No circularity: purely empirical prompting study with external benchmarks
full rationale
The paper performs an observational study: it applies neutral and culturally-invoking prompts to LLMs on a global street-view image set, measures output distances and affective shifts, and compares results to separate human text-image benchmarks. No equations, fitted parameters, or derivations appear. Claims rest on direct empirical contrasts (e.g., neutral prompts closer to Western-associated ones) that are falsifiable against the external human data and do not reduce to self-definition, self-citation chains, or renaming of inputs. The central finding—that the neutral condition is not neutral—is an observed pattern, not a constructed identity. Minor self-citation risk is absent from the provided text and would not affect the score even if present, as the result is not load-bearing on prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Z. Cui, N. Li, and H. Zhou. A large-scale replication of scenario-based experiments in psychology and management using large language models.Nature Computational Science, 2025. doi:10. 1038/s43588-025-00840-7
2025
-
[2]
A foundation model to predict and capture human cognition.Nature, 644: 1002–1009, 2025
Marcel Binz et al. A foundation model to predict and capture human cognition.Nature, 644: 1002–1009, 2025. doi:10.1038/s41586-025-09215-4
-
[3]
Large language models associate Muslims with violence.Nature Machine Intelligence, 3:461–463, 2021
Abubakar Abid, Maheen Farooqi, and James Zou. Large language models associate Muslims with violence.Nature Machine Intelligence, 3:461–463, 2021. doi:10.1038/s42256-021-00359-2
-
[4]
McKenzie, G., Zhang, H., and Gambs, S.,
R. Manvi, S. Khanna, M. Burke, D. Lobell, and S. Ermon. Large language models are geographi- cally biased.arXiv preprint arXiv:2402.02680, 2024
-
[5]
Lu, Lesley Luyang Song, and Lu Doris Zhang
Jonathan G. Lu, Lily L. Song, and Long T. Zhang. Cultural tendencies in generative AI.Nature Human Behaviour, 9:2360–2369, 2025. doi:10.1038/s41562-025-02242-1
-
[6]
YunzhiTao,OlgaViberg,RyanS.Baker,andRenéF.Kizilcec. Culturalbiasandculturalalignment of large language models.PNAS Nexus, 3(9):pgae346, 2024. doi:10.1093/pnasnexus/pgae346
-
[7]
Angelina Wang, Jamie Morgenstern, and John P. Dickerson. Large language models that replace human participants can harmfully misportray and flatten identity groups.Nature Machine Intelli- gence, 7:400–411, 2025. doi:10.1038/s42256-025-00986-z
-
[8]
Risks of cultural erasure in large language models
Rida Qadri, Aida M. Davani, Kevin Robinson, and Vinodkumar Prabhakaran. Risks of cultural erasure in large language models.arXiv preprint arXiv:2501.01056, 2025. 16
-
[9]
Emergent social conventions andcollectivebiasinLLMpopulations.ScienceAdvances, 11(20):eadu9368, 2025
Avihay Fridman Ashery, Luca Maria Aiello, and Andrea Baronchelli. Emergent social conventions andcollectivebiasinLLMpopulations.ScienceAdvances, 11(20):eadu9368, 2025. doi:10.1126/ sciadv.adu9368
2025
-
[10]
AI generates covertly racist decisions about people based on their dialect.Nature, 633:147–154, 2024
Valentin Hofmann, Pratyusha Ria Kalluri, Dan Jurafsky, and Sharese King. AI generates covertly racist decisions about people based on their dialect.Nature, 633:147–154, 2024. doi:10.1038/ s41586-024-07856-5
2024
-
[11]
Douglas Guilbeault, Solene Delecourt, and Bhagya S. Desikan. Age and gender distortion in online media and large language models.Nature, 2025. doi:10.1038/s41586-025-09581-z
-
[12]
Large AI models are cultural and social technologies.Science, 387:1153–1156, 2025
Henry Farrell, Alison Gopnik, Cosma Shalizi, and James Evans. Large AI models are cultural and social technologies.Science, 387:1153–1156, 2025. doi:10.1126/science.adt9819
-
[13]
Savcisens
G. Savcisens. Large language models act as if they are part of a group.Nature Computational Science, 5:9–10, 2025
2025
-
[14]
Tal Golan, Matthew Siegelman, Nikolaus Kriegeskorte, and Christopher Baldassano. Testing the limits of natural language models for predicting human language judgements.Nature Machine Intelligence, 5:952–964, 2023. doi:10.1038/s42256-023-00718-1
-
[15]
Nature Human Behaviour , volume = 8, number = 7, pages =
JamesW.A.Strachan, DalilaAlbergo, GiuliaBorghini, OrianaPansardi, EugenioScaliti, Saurabh Gupta, KratiSaxena, Alessio Rufo, Stefano Panzeri, GianlucaManzi, and MichaelS. A.Graziano. Testing theory of mind in large language models and humans.Nature Human Behaviour, 8:1285– 1295, 2024. doi:10.1038/s41562-024-01882-z
-
[16]
Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Catarina Belem, Sheer Karny, Xinyue Hu, Lukas W. Mayer, and Padhraic Smyth. What large language models know and what people think they know.Nature Machine Intelligence, 7:221–231, 2025. doi:10.1038/s42256-024-00976-7
-
[17]
Byunghwee Lee, Rachith Aiyappa, Yong-Yeol Ahn, Haewoon Kwak, and Jisun An. A semantic embedding space based on large language models for modelling human beliefs.Nature Human Behaviour, 9:1928–1940, 2025. doi:10.1038/s41562-025-02228-z
-
[18]
Relph.Place and Placelessness
Edward C. Relph.Place and Placelessness. Pion, 1976
1976
-
[19]
Jack L. Nasar. Visual preferences in urban street scenes: A cross-cultural comparison between Japan and the United States. In Jack L. Nasar, editor,Environmental Aesthetics, pages 260–274. Cambridge University Press, 1988. doi:10.1017/CBO9780511571213.025
-
[20]
Jack L. Nasar. The evaluative image of the city.Journal of the American Planning Association, 56:41–53, 1990
1990
-
[21]
Rachel Kaplan and Eugene J. Herbert. Cultural and sub-cultural comparisons in preferences for natural settings.Landscape and Urban Planning, 14:281–293, 1987
1987
-
[22]
Matias Quintana, Youlong Gu, Xiucheng Liang, Yujun Hou, Koichi Ito, Yihan Zhu, Mahmoud Ab- delrahman, and Filip Biljecki. Global urban visual perception varies across demographics and personalities.Nature Cities, 2:1092–1106, 2025. doi:10.1038/s44284-025-00330-x
-
[23]
Aditya Singh, Gerson Kroiz, Senthooran Rajamanoharan, and Neel Nanda
Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large language models. Nature, 623:493–498, 2023. doi:10.1038/s41586-023-06647-8. 17
-
[24]
Thecityastext.Nature Cities, 2:794–800, 2025
JonathanReades,YingjieHu,EmmanouilTranos,andElizabethDelmelle. Thecityastext.Nature Cities, 2:794–800, 2025. doi:10.1038/s44284-025-00314-x
-
[25]
Salesses, K
P. Salesses, K. Schechtner, and César A. Hidalgo. The collaborative image of the city: Mapping the inequality of urban perception.PLoS ONE, 8:e68400, 2013
2013
-
[26]
Dubey, N
A. Dubey, N. Naik, D. Parikh, R. Raskar, and César A. Hidalgo. Deep learning the city: Quanti- fying urban perception at a global scale. In B. Leibe, J. Matas, N. Sebe, and M. Welling, editors, Computer Vision – ECCV 2016, pages 196–212, Cham, 2016. Springer International Publishing
2016
-
[27]
Landscape and Urban Planning, 180:148–160, 2018
F.Zhangetal.Measuringhumanperceptionsofalarge-scaleurbanregionusingmachinelearning. Landscape and Urban Planning, 180:148–160, 2018
2018
-
[28]
K. Ito, Y. Kang, Y. Zhang, F. Zhang, and F. Biljecki. Understanding urban perception with visual data: A systematic review.Cities, 152:105169, 2024
2024
-
[29]
Rui and C
J. Rui and C. Cai. Plausible or misleading? evaluating the adaption of the Place Pulse 2.0 dataset for predicting subjective perception in Chinese urban landscapes.Habitat International, 157:103333, 2025
2025
-
[30]
K. M. Jang et al. Place identity: a generative AI’s perspective.Humanities and Social Sciences Communications, 11:1156, 2024. doi:10.1057/s41599-024-03645-7
-
[31]
Malekzadeh, E
M. Malekzadeh, E. Willberg, J. Torkko, and T. Toivonen. Urban attractiveness according to Chat- GPT: Contrasting AI and human insights.Computers, Environment and Urban Systems, 117: 102243, 2025
2025
- [32]
-
[33]
Rashid Mushkani. Do vision-language models see urban scenes as people do? an urban percep- tion benchmark.arXiv preprint arXiv:2509.14574, 2025
-
[34]
Ciro Beneduce, Bruno Lepri, and Massimiliano Luca. Urban safety perception through the lens of large multimodal models: A persona-based approach.arXiv preprint arXiv:2503.00610, 2025
- [35]
-
[36]
X. Fu, C. Li, S. J. Quan, T. Yigitcanlar, and D. Wasserman. Large language models in urban planning.Nature Cities, 2:585–592, 2025. doi:10.1038/s44284-025-00261-7
-
[37]
Kirsten N. Morehouse, Siddharth Swaroop, and Weiwei Pan. Rethinking LLM bias probing using lessons from the social sciences.arXiv preprint arXiv:2503.00093, 2025. doi:10.48550/arXiv. 2503.00093
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[38]
C. Hou et al. Transferred bias uncovers the balance between the development of physical and socioeconomic environments of cities.Annals of the American Association of Geographers, 115: 148–166, 2025. doi:10.1080/24694452.2024.2412173
-
[39]
Generative ai.Environment and Planning B: Urban Analytics and City Science, 52 (5):1031–1034, 2025
Michael Batty. Generative ai.Environment and Planning B: Urban Analytics and City Science, 52 (5):1031–1034, 2025. doi:10.1177/23998083251332093. 18
-
[40]
OECD Publishing, Paris, 2021
OECD and European Commission and Food and Agriculture Organization of the United Nations and International Labour Organization and United Nations Human Settlements Programme and World Bank.Applying the Degree of Urbanisation: A Methodological Manual to Define Cities, Towns and Rural Areas for International Comparisons. OECD Publishing, Paris, 2021. doi:10...
2021
-
[41]
GHS-SMOD R2023A: GHS settlement layers, application of the Degree of Urbanisation methodology (stage I) to GHS-POP R2023A and GHS- BUILT-S R2023A, multitemporal (1975-2030)
European Commission, Joint Research Centre. GHS-SMOD R2023A: GHS settlement layers, application of the Degree of Urbanisation methodology (stage I) to GHS-POP R2023A and GHS- BUILT-S R2023A, multitemporal (1975-2030). Technical report, European Commission, Joint Re- search Centre, Ispra, 2023
1975
-
[42]
Admin 0 – countries, 2026
Natural Earth. Admin 0 – countries, 2026. URLhttps://www.naturalearthdata.com/ downloads/10m-cultural-vectors/10m-admin-0-countries/. NaturalEarthvectormapdata. Accessed 20 April 2026
2026
-
[43]
Standard country or area codes for statistical use (m49), 2026
United Nations Statistics Division. Standard country or area codes for statistical use (m49), 2026. URLhttps://unstats.un.org/unsd/methodology/m49/. Accessed 20 April 2026
2026
-
[44]
Yujun Hou, Matias Quintana, Maxim Khomiakov, Winston Yap, Jiani Ouyang, Koichi Ito, Zeyu Wang, Tianhong Zhao, and Filip Biljecki. Global streetscapes – a comprehensive dataset of 10 million street-level images across 688 cities for urban science and analytics.ISPRS Journal of Photogrammetry and Remote Sensing, 215:216–238, 2024. doi:10.1016/j.isprsjprs.20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.