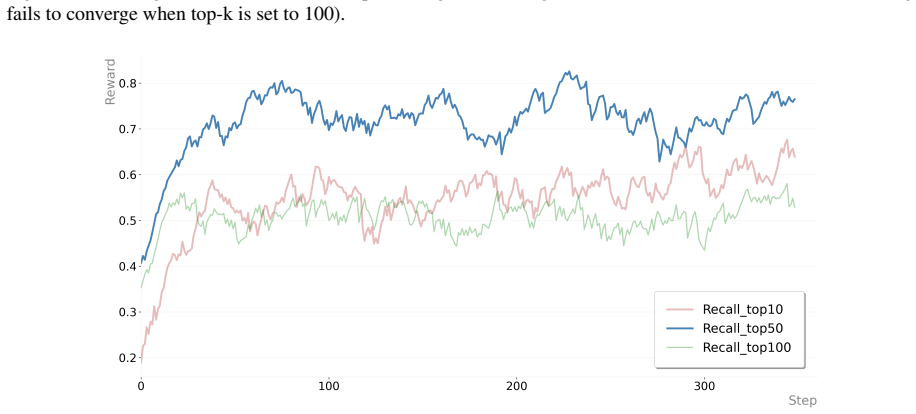
Recognition: unknown
AFMRL: Attribute-Enhanced Fine-Grained Multi-Modal Representation Learning in E-commerce
Pith reviewed 2026-05-10 00:51 UTC · model grok-4.3
The pith
AFMRL improves fine-grained multimodal product representations by using MLLM-generated attributes to guide contrastive training and reinforce generation via retrieval rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
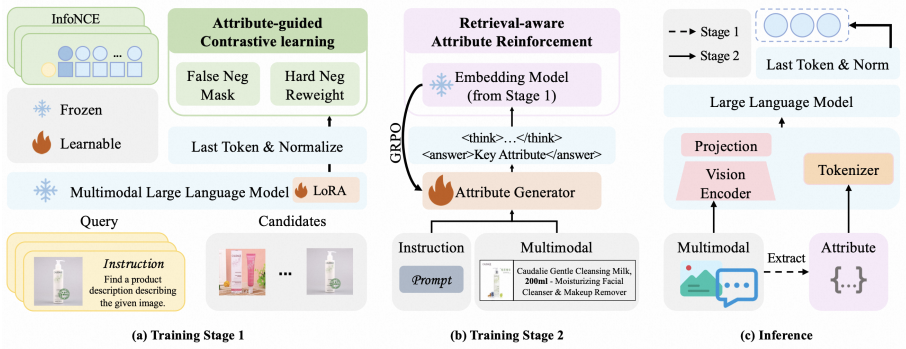
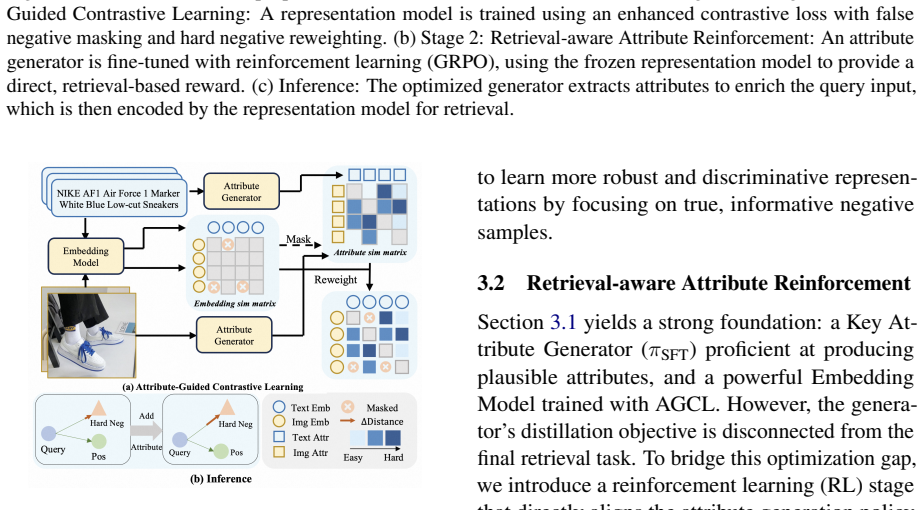
AFMRL defines product fine-grained understanding as an attribute generation task. It leverages the generative power of MLLMs to extract key attributes from product images and text, then applies a two-stage training framework: Attribute-Guided Contrastive Learning uses those attributes to identify hard samples and filter noisy false negatives during image-text contrastive training, while Retrieval-aware Attribute Reinforcement treats post-integration retrieval gains as a reward signal to fine-tune the MLLM's attribute generation.
What carries the argument
The two-stage loop of Attribute-Guided Contrastive Learning (AGCL) for hard-negative selection and Retrieval-aware Attribute Reinforcement (RAR) that turns retrieval performance into a reward for the MLLM.
If this is right
- The method reaches state-of-the-art results on multiple downstream product retrieval tasks.
- Generative models can be harnessed to supply fine-grained supervisory signals that advance representation learning.
- Hard-negative mining and reward-based fine-tuning can be combined in a single training pipeline for multimodal data.
- Performance gains hold across large-scale retail datasets without requiring manual attribute annotations.
Where Pith is reading between the lines
- The same attribute-retrieval loop could be tested on non-retail multimodal tasks such as medical image-report matching where fine distinctions also matter.
- If MLLM attribute quality varies by product category, the reinforcement stage might need category-specific reward scaling to remain stable.
- An explicit check of attribute accuracy on a held-out validation set before each reinforcement round could prevent error amplification in the feedback loop.
Load-bearing premise
The generated attributes from the MLLM are accurate and stable enough to serve as reliable guidance for selecting hard negatives and as a consistent reward signal without adding systematic noise.
What would settle it
Ablating both AGCL and RAR on the same large-scale e-commerce datasets and finding no statistically significant gain over plain contrastive baselines would falsify the central claim.
Figures







read the original abstract
Multimodal representation is crucial for E-commerce tasks such as identical product retrieval. Large representation models (e.g., VLM2Vec) demonstrate strong multimodal understanding capabilities, yet they struggle with fine-grained semantic comprehension, which is essential for distinguishing highly similar items. To address this, we propose Attribute-Enhanced Fine-Grained Multi-Modal Representation Learning (AFMRL), which defines product fine-grained understanding as an attribute generation task. It leverages the generative power of Multimodal Large Language Models (MLLMs) to extract key attributes from product images and text, and enhances representation learning through a two-stage training framework: 1) Attribute-Guided Contrastive Learning (AGCL), where the key attributes generated by the MLLM are used in the image-text contrastive learning training process to identify hard samples and filter out noisy false negatives. 2) Retrieval-aware Attribute Reinforcement (RAR), where the improved retrieval performance of the representation model post-attribute integration serves as a reward signal to enhance MLLM's attribute generation during multimodal fine-tuning. Extensive experiments on large-scale E-commerce datasets demonstrate that our method achieves state-of-the-art performance on multiple downstream retrieval tasks, validating the effectiveness of harnessing generative models to advance fine-grained representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AFMRL, which frames fine-grained multimodal understanding in e-commerce as an attribute generation task. It uses MLLMs to extract key product attributes from images and text, then applies a two-stage framework: Attribute-Guided Contrastive Learning (AGCL) to leverage these attributes for hard-negative mining and false-negative filtering during contrastive training, followed by Retrieval-aware Attribute Reinforcement (RAR) that treats post-AGCL retrieval gains as a reward signal to fine-tune the MLLM. The central claim is that this yields state-of-the-art results on multiple downstream retrieval tasks over large-scale e-commerce datasets.
Significance. If the experimental claims hold after proper validation, the work would be significant for showing how generative MLLM capabilities can be closed-looped into representation learning to address fine-grained semantic gaps in VLMs, particularly for e-commerce retrieval where distinguishing near-identical items matters. The two-stage design is a concrete attempt to turn attribute generation into a trainable signal rather than a static preprocessing step.
major comments (3)
- [Abstract] Abstract: The central SOTA claim is asserted without any mention of the specific datasets, baselines (e.g., VLM2Vec or other multimodal retrievers), evaluation metrics, ablation studies, or statistical significance tests. This absence makes it impossible to assess whether the reported gains are load-bearing or reproducible, directly undermining evaluation of the method's effectiveness.
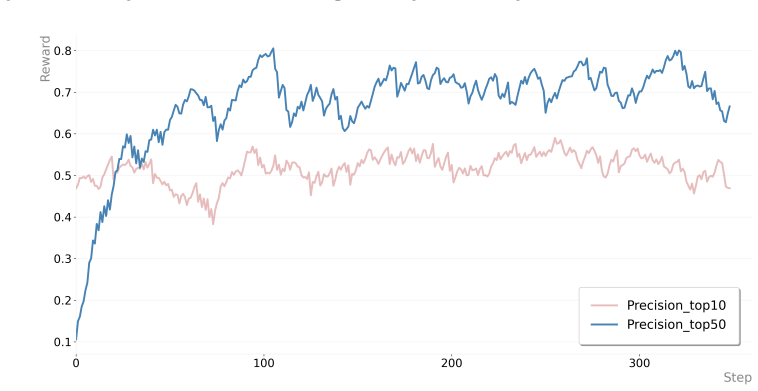
- [RAR stage] RAR stage (as described in the abstract and method): The reward signal is defined as the representation model's own retrieval performance after attribute integration. This creates an explicit self-reinforcing loop between the representation model and the MLLM whose independence from the original training distribution and stability against noisy rewards is not analyzed or bounded.
- [AGCL and attribute generation] AGCL and attribute generation (method description): Hard-negative selection and false-negative filtering rest entirely on MLLM-generated attributes, yet no accuracy validation, human evaluation, inter-annotator agreement, or even simple precision/recall metrics on the generated attributes are reported. Inaccurate or unstable attributes would systematically corrupt both the contrastive loss and the RAR reward, rendering the two-stage pipeline unreliable.
minor comments (2)
- [Abstract] The abstract introduces the acronyms AGCL and RAR without first spelling them out on initial use, which reduces immediate readability.
- [Method] Notation for the reward function in RAR and the attribute-guided loss in AGCL should be formalized with explicit equations rather than prose descriptions to allow precise reproduction.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the manuscript. Below, we provide point-by-point responses to the major comments and indicate the revisions made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central SOTA claim is asserted without any mention of the specific datasets, baselines (e.g., VLM2Vec or other multimodal retrievers), evaluation metrics, ablation studies, or statistical significance tests. This absence makes it impossible to assess whether the reported gains are load-bearing or reproducible, directly undermining evaluation of the method's effectiveness.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to better evaluate the claims. In the revised manuscript, we have updated the abstract to name the large-scale e-commerce datasets used, reference the primary baselines including VLM2Vec and other multimodal retrievers, specify the evaluation metrics (Recall@K variants), and note the ablation studies along with statistical significance testing reported in the experiments section. revision: yes
-
Referee: [RAR stage] RAR stage (as described in the abstract and method): The reward signal is defined as the representation model's own retrieval performance after attribute integration. This creates an explicit self-reinforcing loop between the representation model and the MLLM whose independence from the original training distribution and stability against noisy rewards is not analyzed or bounded.
Authors: We acknowledge the referee's point about the self-reinforcing loop in the RAR stage and the lack of formal analysis on independence and stability. In the revision, we have added a dedicated paragraph in the method section that discusses the use of a held-out validation set for computing the reward signal to promote independence from the training distribution. We also report empirical observations from our training runs showing stable performance gains without divergence or reward hacking, providing practical evidence of robustness even if a theoretical bound is not derived. revision: partial
-
Referee: [AGCL and attribute generation] AGCL and attribute generation (method description): Hard-negative selection and false-negative filtering rest entirely on MLLM-generated attributes, yet no accuracy validation, human evaluation, inter-annotator agreement, or even simple precision/recall metrics on the generated attributes are reported. Inaccurate or unstable attributes would systematically corrupt both the contrastive loss and the RAR reward, rendering the two-stage pipeline unreliable.
Authors: We recognize that the absence of direct validation metrics for the MLLM-generated attributes represents a gap in the original submission. The manuscript relies on downstream retrieval improvements as indirect evidence of attribute utility, since systematic errors in attributes would not produce the observed gains over strong baselines. To address the concern, we have added qualitative examples of generated attributes in the experiments section along with a discussion of how the RAR stage iteratively refines initial attribute noise. A comprehensive human evaluation with inter-annotator agreement is beyond the scope of the current work and is noted as future research. revision: partial
Circularity Check
No significant circularity detected; method is a standard two-stage training loop with external experimental validation.
full rationale
The paper proposes AFMRL as an empirical method consisting of AGCL (using MLLM attributes for hard-negative mining in contrastive loss) followed by RAR (using post-AGCL retrieval metrics as RL reward to fine-tune the MLLM). This loop is a deliberate design choice analogous to standard RLHF or self-training pipelines and does not reduce any claimed result to its inputs by construction. No equations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. Central claims rest on downstream retrieval experiments on large-scale e-commerce datasets, which constitute independent evidence rather than tautological re-derivation. The absence of reported attribute accuracy metrics is a correctness/empirical gap, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal LLMs can reliably extract task-relevant fine-grained attributes from product images and text
- domain assumption Retrieval performance can serve as a stable and informative reward signal for improving attribute generation
invented entities (2)
-
Attribute-Guided Contrastive Learning (AGCL)
no independent evidence
-
Retrieval-aware Attribute Reinforcement (RAR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ICLR , year=
VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks , author=. ICLR , year=
-
[2]
2006 IEEE computer society conference on computer vision and pattern recognition (CVPR'06) , volume=
Dimensionality reduction by learning an invariant mapping , author=. 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR'06) , volume=. 2006 , organization=
2006
-
[3]
Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021) , pages=
Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup , author=. Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021) , pages=
2021
-
[4]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proceedings of the 41st International Conference on Machine Learning , pages=
MagicLens: self-supervised image retrieval with open-ended instructions , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[7]
arXiv preprint arXiv:2407.12580 , year=
E5-v: Universal embeddings with multimodal large language models , author=. arXiv preprint arXiv:2407.12580 , year=
-
[8]
arXiv preprint arXiv:2505.05071 (2025) 5, 7, 9, 11, 12, 13, 20, 21, 22
FG-CLIP: Fine-Grained Visual and Textual Alignment , author=. arXiv preprint arXiv:2505.05071 , year=
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning instance-level representation for large-scale multi-modal pretraining in e-commerce , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
Advances in Neural Information Processing Systems , volume=
Easy Regional Contrastive Learning of Expressive Fashion Representations , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[12]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Gallerygpt: Analyzing paintings with large multimodal models , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[13]
Cheng, Mingyue and Chen, Yiheng and Liu, Qi and Liu, Zhiding and Luo, Yucong and Chen, Enhong , title =. 2025 , isbn =. doi:10.1145/3701551.3703499 , booktitle =
-
[14]
Advances in Neural Information Processing Systems , volume=
Cogvlm: Visual expert for pretrained language models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Llavanext: Improved reasoning, ocr, and world knowledge , author=
-
[16]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Colpali: Efficient document retrieval with vision language models , author=. arXiv preprint arXiv:2407.01449 , year=
-
[18]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
RWKV-CLIP: A Robust Vision-Language Representation Learner , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[19]
arXiv preprint arXiv:2504.16801 , year=
Decoupled Global-Local Alignment for Improving Compositional Understanding , author=. arXiv preprint arXiv:2504.16801 , year=
-
[20]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Eva-clip: Improved training techniques for clip at scale , author=. arXiv preprint arXiv:2303.15389 , year=
work page internal anchor Pith review arXiv
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Alip: Adaptive language-image pre-training with synthetic caption , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Clip-cid: Efficient clip distillation via cluster-instance discrimination , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vila: On pre-training for visual language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-2: Grounding multimodal large language models to the world , author=. arXiv preprint arXiv:2306.14824 , year=
work page internal anchor Pith review arXiv
-
[25]
European Conference on Computer Vision , pages=
Llava-grounding: Grounded visual chat with large multimodal models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[26]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review arXiv
-
[27]
arXiv preprint arXiv:2404.05961 , year=
Llm2vec: Large language models are secretly powerful text encoders , author=. arXiv preprint arXiv:2404.05961 , year=
-
[28]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Ctrl-o: language-controllable object-centric visual representation learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[29]
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Nv-embed: Improved techniques for training llms as generalist embedding models , author=. arXiv preprint arXiv:2405.17428 , year=
work page internal anchor Pith review arXiv
-
[30]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Fine-tuning llama for multi-stage text retrieval , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[31]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Generative Modeling of Class Probability for Multi-Modal Representation Learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[32]
Retrieve anything to augment large language models
Retrieve anything to augment large language models , author=. arXiv preprint arXiv:2310.07554 , year=
-
[33]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
FLAME: Frozen Large Language Models Enable Data-Efficient Language-Image Pre-training , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[34]
Llm2clip: Powerful language model unlocks richer visual representation , author=. arXiv preprint arXiv:2411.04997 , year=
-
[35]
European conference on computer vision , pages=
Long-clip: Unlocking the long-text capability of clip , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[36]
Advances in Neural Information Processing Systems , volume=
Image captioners are scalable vision learners too , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
When and why vision-language models behave like bags-of-words, and what to do about it? , author=. arXiv preprint arXiv:2210.01936 , year=
-
[38]
Advances in neural information processing systems , volume=
Align before fuse: Vision and language representation learning with momentum distillation , author=. Advances in neural information processing systems , volume=
-
[39]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
M5product: Self-harmonized contrastive learning for e-commercial multi-modal pretraining , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
arXiv preprint arXiv:2410.20109 , year=
Give: Guiding visual encoder to perceive overlooked information , author=. arXiv preprint arXiv:2410.20109 , year=
-
[42]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Flair: Vlm with fine-grained language-informed image representations , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[43]
arXiv preprint arXiv:2505.15877 , year=
Highlighting What Matters: Promptable Embeddings for Attribute-Focused Image Retrieval , author=. arXiv preprint arXiv:2505.15877 , year=
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Bridging Modalities: Improving Universal Multimodal Retrieval by Multimodal Large Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
M ega P airs: Massive Data Synthesis for Universal Multimodal Retrieval
Zhou, Junjie and Xiong, Yongping and Liu, Zheng and Liu, Ze and Xiao, Shitao and Wang, Yueze and Zhao, Bo and Zhang, Chen Jason and Lian, Defu. M ega P airs: Massive Data Synthesis for Universal Multimodal Retrieval. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025....
-
[46]
Cheng, Mingyue and Tao, Xiaoyu and Liu, Qi and Zhang, Hao and Chen, Yiheng and Lian, Defu , title =. 2025 , isbn =. doi:10.1145/3701551.3703498 , booktitle =
-
[47]
Companion Proceedings of the ACM Web Conference 2024 , pages=
Notellm: A retrievable large language model for note recommendation , author=. Companion Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[48]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[49]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Deepseek-vl: towards real-world vision-language understanding , author=. arXiv preprint arXiv:2403.05525 , year=
work page internal anchor Pith review arXiv
-
[50]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.