Recognition: unknown
SAKE: Self-aware Knowledge Exploitation-Exploration for Grounded Multimodal Named Entity Recognition
Pith reviewed 2026-05-09 23:51 UTC · model grok-4.3
The pith
SAKE lets multimodal models measure their own uncertainty to decide when external knowledge retrieval is actually needed for recognizing and grounding entities in image-text pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
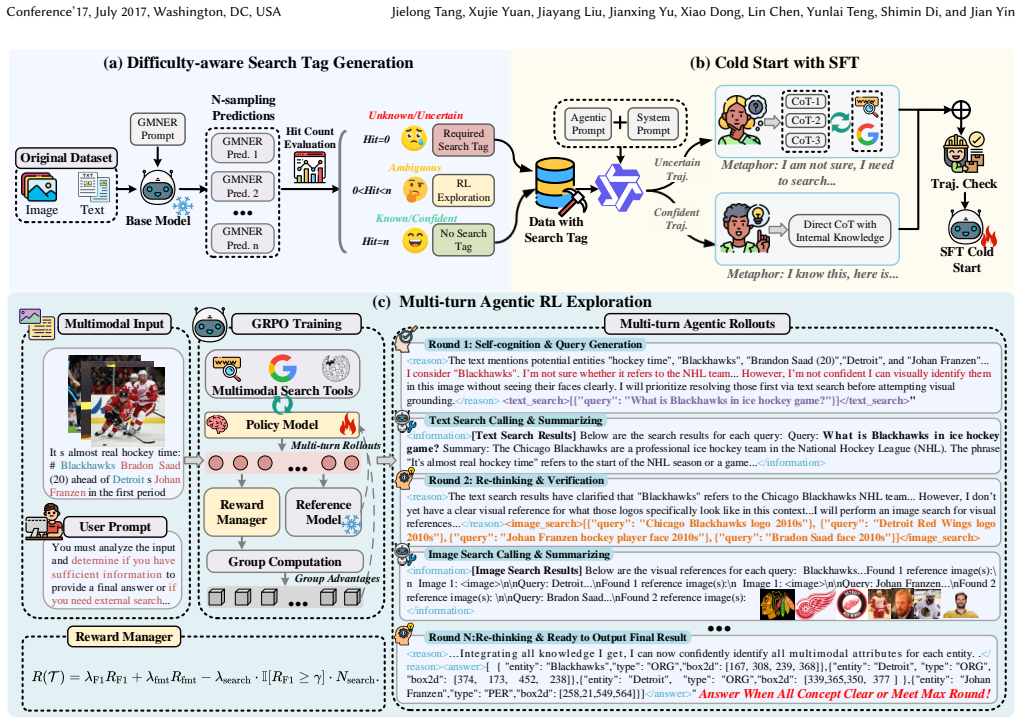
SAKE is an end-to-end agentic framework that harmonizes internal knowledge exploitation and external knowledge exploration through self-aware reasoning and adaptive search tool invocation, implemented via a two-stage process of difficulty-aware search tag generation for supervised fine-tuning followed by agentic reinforcement learning with a hybrid reward that discourages unnecessary retrieval.
What carries the argument
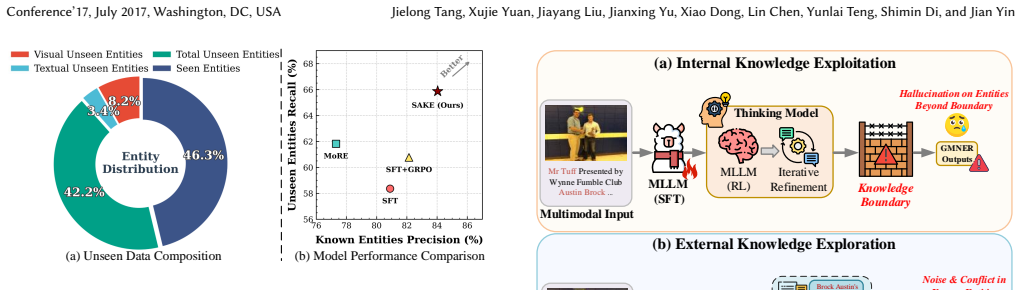
Difficulty-aware Search Tag Generation, which quantifies entity-level uncertainty via multiple forward samplings to create explicit knowledge-gap signals that guide when to invoke external search tools.
If this is right
- The model reduces errors on known entities by avoiding noisy or conflicting external evidence.
- Performance rises on long-tailed and unseen entities where internal knowledge alone is insufficient.
- The reinforcement learning stage shifts the model from rigid imitation of search behavior to selective, self-aware tool use.
- The two-stage training produces an explicit Chain-of-Thought dataset that embeds basic self-awareness capabilities.
Where Pith is reading between the lines
- The same uncertainty-sampling plus selective-retrieval pattern could be applied to other multimodal tasks that encounter out-of-distribution content.
- If the uncertainty signals prove reliable they might serve as a lightweight way to trigger external verification in any large multimodal model without full agentic retraining.
- Testing whether the learned policy transfers to different base multimodal models or to non-social-media image-text domains would reveal the generality of the self-awareness mechanism.
Load-bearing premise
That repeated sampling of the model's outputs can produce uncertainty signals that truly indicate missing knowledge rather than being misled by the model's own hallucinations or sampling noise.
What would settle it
Running the full SAKE pipeline on the two social media GMNER benchmarks and finding that accuracy and grounding performance show no meaningful gain over strong baselines that either always retrieve external knowledge or never retrieve it.
Figures









read the original abstract
Grounded Multimodal Named Entity Recognition (GMNER) aims to extract named entities and localize their visual regions within image-text pairs, serving as a pivotal capability for various downstream applications. In open-world social media platforms, GMNER remains challenging due to the prevalence of long-tailed, rapidly evolving, and unseen entities. To tackle this, existing approaches typically rely on either external knowledge exploration through heuristic retrieval or internal knowledge exploitation via iterative refinement in Multimodal Large Language Models (MLLMs). However, heuristic retrieval often introduces noisy or conflicting evidence that degrades precision on known entities, while solely internal exploitation is constrained by the knowledge boundaries of MLLMs and prone to hallucinations. To address this, we propose SAKE, an end-to-end agentic framework that harmonizes internal knowledge exploitation and external knowledge exploration via self-aware reasoning and adaptive search tool invocation. We implement this via a two-stage training paradigm. First, we propose Difficulty-aware Search Tag Generation, which quantifies the model's entity-level uncertainty through multiple forward samplings to produce explicit knowledge-gap signals. Based on these signals, we construct SAKE-SeCoT, a high-quality Chain-of-Thought dataset that equips the model with basic self-awareness and tool-use capabilities through supervised fine-tuning. Second, we employ agentic reinforcement learning with a hybrid reward function that penalizes unnecessary retrieval, enabling the model to evolve from rigid search imitation to genuine self-aware decision-making about when retrieval is truly necessary. Extensive experiments on two widely used social media benchmarks demonstrate SAKE's effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAKE, an end-to-end agentic framework for Grounded Multimodal Named Entity Recognition (GMNER) that harmonizes internal knowledge exploitation and external knowledge exploration via self-aware reasoning and adaptive search tool invocation. It uses a two-stage training paradigm: (1) Difficulty-aware Search Tag Generation, which quantifies entity-level uncertainty through multiple forward samplings to build the SAKE-SeCoT Chain-of-Thought dataset for supervised fine-tuning; (2) agentic reinforcement learning with a hybrid reward function that penalizes unnecessary retrieval to foster genuine self-aware decisions. The authors claim this addresses limitations of heuristic retrieval (noise) and pure internal exploitation (hallucinations) and demonstrate effectiveness on two social media benchmarks.
Significance. If the self-aware uncertainty signals and hybrid-reward RL successfully enable adaptive tool use without propagating hallucinations, SAKE would represent a meaningful advance in agentic multimodal systems for open-world GMNER, where long-tailed and evolving entities are common. It could influence downstream applications in social media analysis by providing a principled exploitation-exploration balance, with potential for broader impact in uncertainty-aware MLLM agents.
major comments (2)
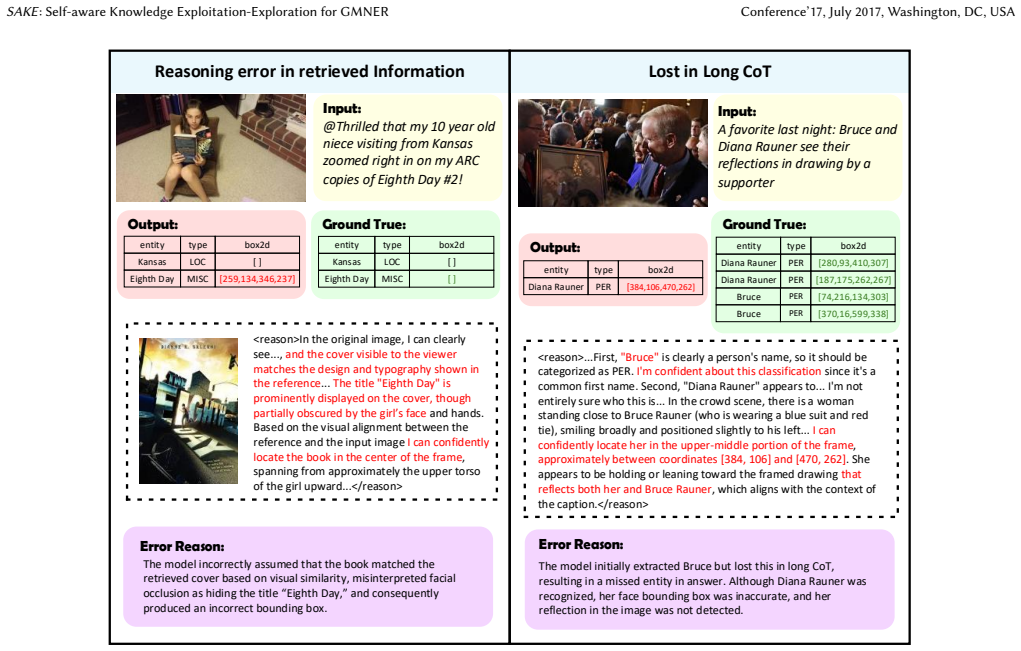
- [Difficulty-aware Search Tag Generation] Difficulty-aware Search Tag Generation section: the procedure of using multiple forward samplings to produce entity-level uncertainty signals for knowledge-gap detection is presented as the foundation for self-awareness and SAKE-SeCoT construction, yet no ablation or validation is provided to show these signals distinguish missing knowledge from MLLM hallucinations or sampling variance; this assumption is load-bearing for the entire two-stage pipeline and the claimed adaptive behavior.
- [Agentic reinforcement learning stage] Agentic reinforcement learning stage: the hybrid reward function is claimed to evolve the model from rigid search imitation to genuine self-aware decision-making about retrieval necessity, but this evolution presupposes that the uncertainty signals from stage 1 are causally reliable; without empirical confirmation that the signals are not confounded by stochasticity, the RL objective risks optimizing on noisy or misleading labels.
minor comments (2)
- [Abstract] Abstract: the statement that 'extensive experiments on two widely used social media benchmarks demonstrate SAKE's effectiveness' lacks any quantitative metrics, baseline comparisons, or ablation summaries, reducing the reader's ability to gauge the strength of the empirical support.
- [Method overview] Method overview: terms such as 'SAKE-SeCoT' and the precise formulation of the hybrid reward are introduced without immediate cross-references to their definitions or equations, which could be clarified for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our two-stage training paradigm. We address each major comment below and commit to revisions that provide the requested empirical validation without altering the core claims of the manuscript.
read point-by-point responses
-
Referee: [Difficulty-aware Search Tag Generation] Difficulty-aware Search Tag Generation section: the procedure of using multiple forward samplings to produce entity-level uncertainty signals for knowledge-gap detection is presented as the foundation for self-awareness and SAKE-SeCoT construction, yet no ablation or validation is provided to show these signals distinguish missing knowledge from MLLM hallucinations or sampling variance; this assumption is load-bearing for the entire two-stage pipeline and the claimed adaptive behavior.
Authors: We acknowledge that the original manuscript lacks a dedicated ablation isolating the uncertainty signals from hallucinations versus sampling variance. The multiple forward samplings follow standard uncertainty quantification practices in LLMs, where disagreement across samples serves as a proxy for knowledge gaps. Overall benchmark gains and the construction of SAKE-SeCoT provide indirect support, but we agree this is insufficient for the load-bearing claim. In the revision we will add an ablation study that (i) compares uncertainty-derived tags against random and heuristic baselines on a held-out subset and (ii) reports correlation between low-consensus entities and ground-truth rarity or missing knowledge indicators. revision: yes
-
Referee: [Agentic reinforcement learning stage] Agentic reinforcement learning stage: the hybrid reward function is claimed to evolve the model from rigid search imitation to genuine self-aware decision-making about retrieval necessity, but this evolution presupposes that the uncertainty signals from stage 1 are causally reliable; without empirical confirmation that the signals are not confounded by stochasticity, the RL objective risks optimizing on noisy or misleading labels.
Authors: The referee correctly notes the causal dependency between stages. While the hybrid reward penalizes unnecessary retrieval and the RL phase allows outcome-driven refinement, the initial labels from stage 1 could indeed be affected by sampling stochasticity. We will therefore include in the revision (i) stability analysis of uncertainty estimates across multiple random seeds and temperatures and (ii) a comparison of decision patterns before and after RL to demonstrate that the final policy exhibits adaptive, non-imitative retrieval behavior beyond what SFT alone produces. revision: yes
Circularity Check
No circularity in SAKE framework derivation
full rationale
The paper describes an empirical two-stage training pipeline for an agentic framework: Difficulty-aware Search Tag Generation via multiple forward samplings to create SAKE-SeCoT for SFT, followed by agentic RL with a hybrid reward. No equations, predictions, or first-principles results are presented that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Central claims rest on benchmark experiments rather than internal consistency loops, with no load-bearing uniqueness theorems or ansatzes imported from prior author work. This is a standard methodological proposal without mathematical circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal large language models have knowledge boundaries and are prone to hallucinations when relying solely on internal knowledge.
- domain assumption Heuristic retrieval often introduces noisy or conflicting evidence that degrades precision on known entities.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Ross Girshick. 2015. Fast r-cnn. InProceedings of the IEEE international conference on computer vision. 1440–1448
2015
-
[5]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. 2024. Openai o1 system card.arXiv preprint arXiv:2412.16720(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung
-
[10]
InFindings of the Association for Computational Linguistics: EMNLP 2023
Towards mitigating LLM hallucination via self reflection. InFindings of the Association for Computational Linguistics: EMNLP 2023. 1827–1843
2023
-
[11]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516(2025)
work page internal anchor Pith review arXiv 2025
-
[12]
Fan Li, Jianxing Yu, Jielong Tang, Wenqing Chen, Hanjiang Lai, Yanghui Rao, and Jian Yin. 2025. Answering Complex Geographic Questions by Adaptive Reasoning with Visual Context and External Commonsense Knowledge. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 25498–25514
2025
-
[13]
Jinyuan Li, Han Li, Zhuo Pan, Di Sun, Jiahao Wang, Wenkun Zhang, and Gang Pan. 2023. Prompting ChatGPT in MNER: Enhanced Multimodal Named Entity Recognition with Auxiliary Refined Knowledge. InFindings of the Association for Computational Linguistics: EMNLP 2023. 2787–2802
2023
- [14]
-
[15]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025. Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366(2025)
work page internal anchor Pith review arXiv 2025
-
[16]
Ziyan Li, Jianfei Yu, Jia Yang, Wenya Wang, Li Yang, and Rui Xia. 2024. Generative Multimodal Data Augmentation for Low-Resource Multimodal Named Entity Recognition. InACM Multimedia 2024
2024
-
[17]
Xinkui Lin, Yuhui Zhang, Yongxiu Xu, Kun Huang, Hongzhang Mu, Yubin Wang, Gaopeng Gou, Li Qian, Li Peng, Wei Liu, et al . 2025. MAKAR: a Multi-Agent framework based Knowledge-Augmented Reasoning for Grounded Multimodal Named Entity Recognition. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 6121–6141
2025
-
[18]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[19]
Jintao Liu, Chenglong Liu, and Kaiwen Wei. 2024. Multi-view prompt for fine- grained multimodal named entity recognition and grounding. InECAI 2024. IOS Press, 2693–2700
2024
-
[20]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al . 2023. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499(2023)
work page internal anchor Pith review arXiv 2023
-
[21]
Rosenblum
Ye Liu, Hui Li, Alberto Garcia-Duran, Mathias Niepert, Daniel Onoro-Rubio, and David S. Rosenblum. 2019. MMKG: Multi-modal Knowledge Graphs. InThe Semantic Web. Springer International Publishing, Cham, 459–474
2019
-
[22]
Di Lu, Leonardo Neves, Vitor Carvalho, Ning Zhang, and Heng Ji. 2018. Visual Attention Model for Name Tagging in Multimodal Social Media. InACL. 1990– 1999
2018
- [23]
-
[24]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[25]
Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems36 (2023), 46534–46594
2023
- [26]
-
[27]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al
-
[28]
Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332(2021)
work page internal anchor Pith review arXiv 2021
- [29]
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybridflow: A flexible and Conference’17, July 2017, Washington, DC, USA Jielong Tang, Xujie Yuan, Jiayang Liu, Jianxing Yu, Xiao Dong, Lin Chen, Yunlai Teng, Shimin Di, and Jian Yin efficient rlhf framework. InProceedings of the Twenti...
2025
-
[32]
Jielong Tang, Zhenxing Wang, Ziyang Gong, Jianxing Yu, Xiangwei Zhu, and Jian Yin. 2025. Multi-grained query-guided set prediction network for grounded multimodal named entity recognition. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25246–25254
2025
-
[33]
Jielong Tang, Yang Yang, Jianxing Yu, Zhen-Xing Wang, Haoyuan Liang, Liang Yao, and Jian Yin. 2025. UnCo: Uncertainty-Driven Collaborative Framework of Large and Small Models for Grounded Multimodal NER. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, ...
2025
-
[34]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. 2025. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599(2025)
work page internal anchor Pith review arXiv 2025
-
[35]
Jieming Wang, Ziyan Li, Jianfei Yu, Li Yang, and Rui Xia. 2023. Fine-grained multimodal named entity recognition and grounding with a generative frame- work. InProceedings of the 31st ACM International Conference on Multimedia. 3934–3943
2023
-
[36]
Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. 2022. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. InInternational Conference on Machine Learning. PMLR, 23318–23340
2022
-
[37]
Xinyu Wang, Jiong Cai, Yong Jiang, Pengjun Xie, Kewei Tu, and Wei Lu. 2022. Named Entity and Relation Extraction with Multi-Modal Retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2022. 5925–5936
2022
-
[38]
Xinyu Wang, Min Gui, Yong Jiang, Zixia Jia, Nguyen Bach, Tao Wang, Zhongqiang Huang, and Kewei Tu. 2022. ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies. 3176–3189
2022
-
[39]
Ziqi Wang, Chen Zhu, Zhi Zheng, Xinhang Li, Tong Xu, Yongyi He, Qi Liu, Ying Yu, and Enhong Chen. 2024. Granular Entity Mapper: Advancing Fine- grained Multimodal Named Entity Recognition and Grounding. InFindings of the Association for Computational Linguistics: EMNLP 2024. 3211–3226
2024
-
[40]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
- [41]
-
[42]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[43]
Jianfei Yu, Jing Jiang, Li Yang, and Rui Xia. 2020. Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Trans- former. InACL. 3342–3352
2020
-
[44]
Jianfei Yu, Ziyan Li, Jieming Wang, and Rui Xia. 2023. Grounded multimodal named entity recognition on social media. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9141–9154
2023
-
[45]
Zhuocheng Yu, Bingchan Zhao, Yifan Song, Sujian Li, and Zhonghui He. 2025. ISR: Self-Refining Referring Expressions for Entity Grounding. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 30702–30714
2025
-
[46]
Li Yuan, Yi Cai, Bingshan Zhu, Zhenghao Liu, Zikun Deng, Qing Li, and Tao Wang. 2026. Visual Knowledge-Enhanced LLaVA for Fine-Grained Multimodal Named Entity Recognition and Grounding.IEEE Transactions on Audio, Speech and Language Processing34 (2026), 781–795
2026
-
[47]
Dong Zhang, Suzhong Wei, Shoushan Li, Hanqian Wu, Qiaoming Zhu, and Guodong Zhou. 2021. Multi-modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance. InAAAI, Vol. 35. 14347–14355
2021
-
[48]
Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. 2021. Vinvl: Revisiting visual representations in vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5579–5588
2021
-
[49]
Qi Zhang, Jinlan Fu, Xiaoyu Liu, and Xuanjing Huang. 2018. Adaptive Co- attention Network for Named Entity Recognition in Tweets. InAAAI, Vol. 32
2018
-
[50]
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, et al . 2025. Swift: a scalable lightweight infrastructure for fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 29733–29735
2025
- [51]
-
[52]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. 2025. DeepEyes: Incentivizing" Thinking with Images" via Reinforcement Learning.arXiv preprint arXiv:2505.14362(2025). A Statistics of SAKE-SeCoT The SAKE-SeCoT dataset (see Figure 8) is designed to enable the base model to recognize its own knowledge gaps and...
work page internal anchor Pith review arXiv 2025
-
[53]
increase-then-decrease
introduces a LLM-based pipeline utilizing visual entailment and entity expansion expressions to mitigate weak image-text corre- lations and the semantic gap between named entities and referring expressions.UnCo[ 30] proposes a collaborative framework be- tween large and small models, utilizing the parametric knowledge of MLLMs to iteratively rectify uncer...
2017
-
[54]
(link: https://fcbayern.com/en) FC Bayern Munich - Official Website | FCB Official website of the German Football Record Champion FC Bayern Munich Tickets, News, Store & more Discover the world of FCB now
-
[55]
(link: https://www.instagram.com/fcbayern/) Originals since 1900 Säbener Straße 51-57, München · Admin on a mission · A Champions League matchday with the FC Bayern Admin · Perfect goal from
1900
-
[56]
query":
(link: )Bayern is a German professional sports club based in Munich, Bavaria. They are most known for their men's professional football team, who play in the... <reason>The search results have clarified that "Bayern" refers to... While I now understand its identity, I need to consider whether I can visually locate it in the image. The image shows... but I...
2017
-
[57]
Get rewarded for spending just a few
(link: https://crowdtap.com/) Crowdtap can be your go-to side hustle. Get rewarded for spending just a few
-
[58]
what is Crowdtap: what is InSite:
(link: https://whop.com/blog/crowdtap-review/) Crowdtap is a paid survey app that was founded in 2009 ... what is Crowdtap: what is InSite:
2009
-
[59]
(link: https://en.wikipedia.org/wiki/Insite) Insite is a supervised drug injection site in the Downtown Eastside
-
[60]
query":
(link: https://www.youtube.com/watch?v=qTVJKRUkh5Y) What is INSITE? A COLLABORATIVE SITE AUDIT software... ... <reason>The text search results helped clarify the nature of...However, now that I understand what these entities represent conceptually, I realize I still lack visual confirmation for grounding them in the image... I m not certain if InSite has ...
2017
-
[61]
What named entities are there in the original text?
-
[62]
What are the types of these entities?
-
[63]
Only output one nearest entity type
What are the regions (4D absolute coordinates of bounding boxes) of these entities in the image? - Important note: If the entity cannot be precisely located at a specific region within the image set the bounding box to '[]'. Only output one nearest entity type. - Here are three examples you can refer to. [Examples] - Please output your final results accor...
2017
-
[64]
**Extraction**: Identify named entities from the text belonging to specific types
-
[65]
If an entity is mentioned in the text but not visible or cannot be precisely located in the image, set its `box2d` to an empty list `[]`
**Grounding**: Locate these entities in the image with a 2D bounding box `[x1, y1, x2, y2]` (absolute coordinates). If an entity is mentioned in the text but not visible or cannot be precisely located in the image, set its `box2d` to an empty list `[]`. **Entity Types:** [Corresponding Entity Type Definition] --- ### Execution Protocol You must analyze th...
-
[66]
List all entities found in the text based on **Entity Types**
-
[67]
Ay Ziggy Zoomba
For each entity, evaluate two distinct states: * **Conceptual Understanding**: Do you know *what* this entity is based on the text? (e.g., Is "Ay Ziggy Zoomba" a song, a person, or a place?) * **Visual Recognition**: Do you know *what it looks like* to identify it in the image? (e.g., Do you know what the "1000 Lakes Rally" logo or "Kevin Durant" looks like?)
-
[68]
query":
Determine the immediate next step based on the gaps identified. **Step 2: Decision & Action** Based on your analysis, choose **exactly one** of the following actions. You must prioritize resolving Conceptual Gaps first. * **Priority 1: Resolve Conceptual Gaps (Text Search)** * **Condition**: You do not know the definition, category, or context of one or m...
2017
-
[69]
New York
**Validation & Filtering (CRITICAL)**: Based on the search results and your own knowledge, determine if the extracted text is a valid Named Entity. * *Action*: If the search results imply the text span is just a common verb, adjective, or irrelevant fragment, mark it as **NOISE** and discard it. * *Action*: If the text is a valid entity but the boundaries...
-
[70]
Correct the type if necessary
**Type Correction**: Does the search result contradict the initial type? (e.g., "Amazon" is the river [LOC], not the company [ORG]). Correct the type if necessary
-
[71]
query":
**Visual Gap Check**: For the *remaining valid* entities that are physical/visible objects, do you possess the specific visual features (face, logo, distinct shape) required to locate them in the original image? **Step 2: Decision Process & Action (Choose only ONE)** * **Option 1: Resolve Visual Recognition Gaps (Image Search)** * **Condition**: After fil...
2017
-
[72]
The logo features a red triangle,
**Reference Analysis**: Look at the search result images and incorporate your own knowledge. Identify key visual features of the entity (e.g., "The logo features a red triangle," or "The person has grey hair")
-
[73]
entity":
**Grounding**: Scan the **original input image** for these specific features. * If found: Estimate the bounding box `[x1, y1, x2, y2]`. * If not found: Conclude the entity is not present. **Step 2: Final Output** Synthesize all information (Original Text + Text Search Context + Image Search Visuals) to generate the final answer. **Constraints:** * If the ...
2017
-
[74]
**Validate**: Confirm entities based on search results
-
[75]
{user_text}
**Visual Check**: * If an entity is marked as **[FORCE IMAGE SEARCH]**, you MUST state in `<reason>` that you don't know its specific visual details (face, logo, etc.) to find it in the image. **Generate `<image_search>`**. * If an entity is marked as **[NO SEARCH]** or **[FORCE TEXT SEARCH]** (and text search is done), assume you are now ready to ground ...
2017
-
[76]
If an entity is marked [FORCE TEXT SEARCH], you MUST state uncertainty about its definition/category in <reason> and generate a <text_search> query
-
[77]
If an entity is marked [FORCE IMAGE SEARCH], note it, but always prioritize Text Search if any conceptual gap exists
-
[78]
### Task Simulate the instructions below
If an entity is marked [NO SEARCH], assume full knowledge. ### Task Simulate the instructions below. ### Output Requirement Follow this format strictly: <reason> [Entity analysis and enforced uncertainty based on tags] </reason> Choose ONE action only: <text_search> OR <image_search> OR <answer> --- ### Simulation Instructions {user_prompt_content} SECOT ...
-
[79]
Express uncertainty naturally (e.g., I m not sure what this is, I should check. )
-
[80]
Just reason and act naturally
Do not explain meta-reasons for actions. Just reason and act naturally. **Output Format** Strictly follow the XML structure requested by the user. SAKE: Self-aware Knowledge Exploitation-Exploration for GMNER Conference’17, July 2017, Washington, DC, USA SAKE-SECOT VALIDATE PROMPTS You are an expert evaluator for Multimodal AI Agents. Judge an agent s Cha...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.