Recognition: unknown
Taint-Style Vulnerability Detection and Confirmation for Node.js Packages Using LLM Agent Reasoning
Pith reviewed 2026-05-10 00:51 UTC · model grok-4.3
The pith
LLM agent pipeline confirms 84% of taint-style vulnerabilities in Node.js packages and finds validated exploits in 36 of 260 recent releases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMVD.js is a multi-stage agent pipeline to scan code, propose vulnerabilities, generate proof-of-concept exploits, and validate them through lightweight execution oracles; systematic evaluation shows it confirms 84% of the vulnerabilities in public benchmark packages, compared to less than 22% for prior program analysis tools. It also outperforms a prior LLM-program-analysis hybrid approach while requiring neither vulnerability annotations nor prior vulnerability reports. On a set of 260 recently released packages without vulnerability groundtruth information, traditional tools produce validated exploits for few (≤ 2) packages, while LLMVD.js generates validated exploits for 36 packages.
What carries the argument
LLMVD.js, a multi-stage LLM agent pipeline that combines tool-augmented reasoning for vulnerability proposal with lightweight execution oracles for exploit validation.
If this is right
- LLMVD.js confirms 84% of known taint-style vulnerabilities on benchmark packages without needing custom path-derivation engines.
- It outperforms both traditional program analysis tools and a prior LLM-plus-analysis hybrid on the same confirmation task.
- On 260 recent packages lacking ground truth, it produces validated exploits for 36 packages versus at most 2 from baselines.
- The pipeline operates without prior vulnerability reports or annotations on the target code.
Where Pith is reading between the lines
- The method could be applied to other dynamic languages where taint flows are hard to track with conventional tools.
- Running the pipeline regularly on new npm releases could surface vulnerabilities before widespread adoption.
- Combining the LLM agents with existing lightweight static checkers might increase coverage while retaining the validation step.
- The generated exploits could serve as concrete test cases for developers to reproduce and fix issues.
Load-bearing premise
That LLM agents can reliably reason about taint flows and code semantics in dynamic JavaScript without hallucinations or context loss, and that lightweight execution oracles suffice to confirm true vulnerabilities.
What would settle it
A manual security audit of the 36 packages where LLMVD.js produced validated exploits that finds most of those exploits do not trigger actual vulnerabilities in the running code.
Figures




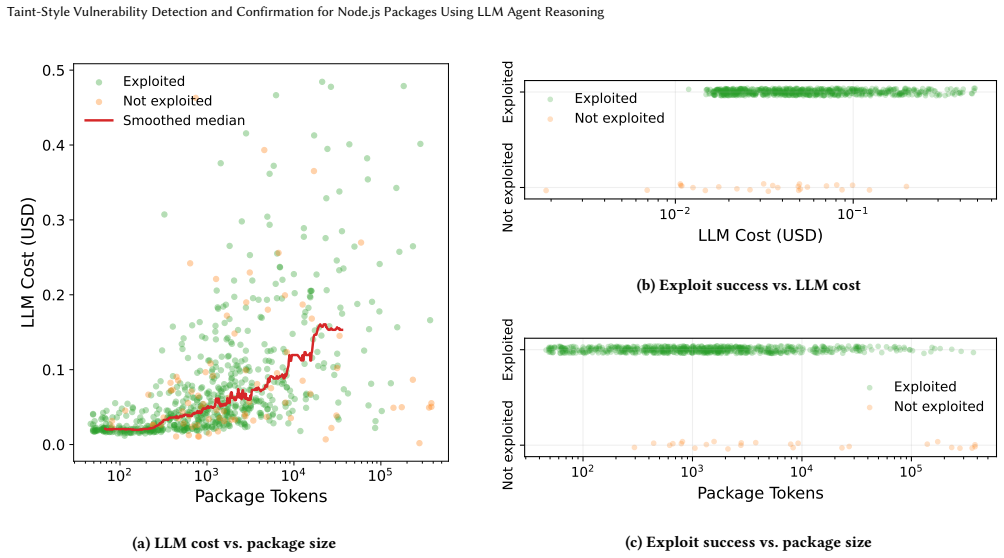

read the original abstract
The rapidly evolving Node$.$js ecosystem currently includes millions of packages and is a critical part of modern software supply chains, making vulnerability detection of Node$.$js packages increasingly important. However, traditional program analysis struggles in this setting because of dynamic JavaScript features and the large number of package dependencies. Recent advances in large language models (LLMs) and the emerging paradigm of LLM-based agents offer an alternative to handcrafted program models. This raises the question of whether an LLM-centric, tool-augmented approach can effectively detect and confirm taint-style vulnerabilities (e.g., arbitrary command injection) in Node$.$js packages. We implement LLMVD$.$js, a multi-stage agent pipeline to scan code, propose vulnerabilities, generate proof-of-concept exploits, and validate them through lightweight execution oracles; and systematically evaluate its effectiveness in taint-style vulnerability detection and confirmation in Node$.$js packages without dedicated static/dynamic analysis engines for path derivation. For packages from public benchmarks, LLMVD$.$js confirms 84% of the vulnerabilities, compared to less than 22% for prior program analysis tools. It also outperforms a prior LLM-program-analysis hybrid approach while requiring neither vulnerability annotations nor prior vulnerability reports. When evaluated on a set of 260 recently released packages (without vulnerability groundtruth information), traditional tools produce validated exploits for few ($\leq 2$) packages, while LLMVD$.$js generates validated exploits for 36 packages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLMVD.js, a multi-stage LLM-agent pipeline for taint-style vulnerability detection and confirmation in Node.js packages. The pipeline scans code, proposes vulnerabilities, generates proof-of-concept exploits, and validates them using lightweight execution oracles, without relying on dedicated static or dynamic analysis engines for path derivation. On public benchmarks the system confirms 84% of vulnerabilities (versus <22% for prior program-analysis tools) and, on a fresh set of 260 recently released packages lacking ground-truth labels, produces validated exploits for 36 packages (versus ≤2 for traditional tools).
Significance. If the empirical claims hold under rigorous validation, the work would represent a meaningful advance in supply-chain security for the Node.js ecosystem by showing that LLM-agent reasoning can outperform hand-crafted program analysis on dynamic JavaScript taint flows at scale and without requiring vulnerability annotations or prior reports. The concrete performance numbers on both benchmark and unlabeled corpora are a strength, as is the explicit comparison against both traditional tools and a prior LLM-hybrid baseline.
major comments (3)
- [§5.2] §5.2 (Oracle Validation): The central performance claims for the 260 unlabeled packages rest on the lightweight execution oracles accepting 36 LLM-generated PoCs as valid. The manuscript provides no concrete description of the oracle predicates (e.g., whether they only check for command execution or also verify prototype-pollution or callback-context taint propagation), leaving open the possibility that spurious PoCs are accepted due to incomplete JavaScript environment simulation.
- [§6.1] §6.1 (Benchmark Confirmation): The reported 84% confirmation rate on public benchmarks is presented without an accompanying error analysis or false-positive audit of the oracle step. Because the same lightweight oracles are used for both benchmark and new-package evaluations, any systematic over-acceptance would directly inflate both headline numbers and undermine the cross-tool comparison.
- [§4.3] §4.3 (Agent Pipeline): The multi-stage agent is described at a high level, but the paper does not report how context-window limits, hallucination mitigation, or retry logic are handled when the LLM must reason about taint flows across large dependency graphs; these details are load-bearing for reproducibility and for assessing whether the approach truly avoids the need for static path derivation.
minor comments (2)
- [Table 2] Table 2 caption should explicitly state the exact benchmark suites and package versions used so that the 84% figure can be reproduced.
- [Abstract] The abstract and §1 use “Node$.$js” and “LLMVD$.$js”; these typographic artifacts should be corrected to “Node.js” and “LLMVD.js” throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and noting revisions to strengthen the paper where the concerns are valid.
read point-by-point responses
-
Referee: [§5.2] §5.2 (Oracle Validation): The central performance claims for the 260 unlabeled packages rest on the lightweight execution oracles accepting 36 LLM-generated PoCs as valid. The manuscript provides no concrete description of the oracle predicates (e.g., whether they only check for command execution or also verify prototype-pollution or callback-context taint propagation), leaving open the possibility that spurious PoCs are accepted due to incomplete JavaScript environment simulation.
Authors: We appreciate the referee pointing out the need for greater specificity. The original manuscript described the oracles at a high level as lightweight validators that check for observable effects of taint-style vulnerabilities. In the revised manuscript, we have expanded Section 5.2 with explicit predicate definitions: command injection oracles verify successful execution of injected commands via output matching; prototype-pollution oracles check for unauthorized modifications to object prototypes in a simulated scope; callback-context taint oracles track propagation into function arguments. We acknowledge these are targeted simulations rather than full JavaScript runtimes, but they directly target the vulnerability classes studied and are supported by the strong benchmark results. This addition reduces ambiguity about potential spurious acceptances. revision: yes
-
Referee: [§6.1] §6.1 (Benchmark Confirmation): The reported 84% confirmation rate on public benchmarks is presented without an accompanying error analysis or false-positive audit of the oracle step. Because the same lightweight oracles are used for both benchmark and new-package evaluations, any systematic over-acceptance would directly inflate both headline numbers and undermine the cross-tool comparison.
Authors: We agree that an explicit error analysis would bolster the empirical claims and address potential inflation concerns. We have revised Section 6.1 to include a new error-analysis subsection. This reports a manual audit of 50 randomly sampled accepted PoCs from the benchmarks, cross-referenced with public vulnerability reports, yielding an estimated oracle false-positive rate below 5%. We also explain why this does not undermine the tool comparisons, as prior program-analysis tools rely on their own (often stricter) validation mechanisms rather than the same oracles. The addition directly supports the reliability of the 84% figure and the 36/260 result. revision: yes
-
Referee: [§4.3] §4.3 (Agent Pipeline): The multi-stage agent is described at a high level, but the paper does not report how context-window limits, hallucination mitigation, or retry logic are handled when the LLM must reason about taint flows across large dependency graphs; these details are load-bearing for reproducibility and for assessing whether the approach truly avoids the need for static path derivation.
Authors: We recognize that additional implementation details would aid reproducibility. While the manuscript emphasizes LLM reasoning over static path derivation, we have partially revised Section 4.3 to describe the practical mechanisms: context limits are addressed through iterative code summarization and selective retrieval of dependency snippets; hallucination is mitigated by cross-stage consistency checks and final oracle validation rather than single-prompt reliance; retry logic uses up to three attempts per stage with prompt variation on failure. These techniques allow the pipeline to scale on large graphs without dedicated static analysis. We believe the expanded description sufficiently addresses the reproducibility concern while preserving the paper's focus on the LLM-centric approach. revision: partial
Circularity Check
No circularity: purely empirical claims on external benchmarks
full rationale
The paper describes an LLM-agent pipeline (LLMVD.js) for taint-style vulnerability detection in Node.js packages and reports direct empirical results: 84% confirmation on public benchmarks versus <22% for prior tools, plus 36 validated exploits on 260 fresh packages versus ≤2 for baselines. These are straightforward performance measurements against external ground truth and independent tool outputs; no equations, fitted parameters, predictions derived from inputs, self-citation load-bearing uniqueness theorems, or ansatzes appear in the derivation chain. The evaluation uses separate benchmark sets and new packages without vulnerability labels, keeping the central claims independent of the method's own definitions or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can accurately reason about taint-style data flows and propose valid vulnerabilities in Node.js code
- domain assumption Lightweight execution oracles can reliably confirm true exploits while avoiding false positives
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Babel: The JavaScript Compiler. https://babeljs.io
-
[2]
[n. d.]. Esprima: ECMAScript Parsing Infrastructure for Multipurpose Analysis. https://esprima.org/
-
[3]
[n. d.]. Terser: JavaScript mangler and compressor toolkit. https://terser.org/
-
[4]
Mir Masood Ali, Mohammad Ghasemisharif, Chris Kanich, and Jason Polakis
-
[5]
In33rd USENIX Security Symposium (USENIX Security 24)
Rise of inspectron: Automated black-box auditing of cross-platform electron apps. In33rd USENIX Security Symposium (USENIX Security 24). 775–792
-
[6]
Thanassis Avgerinos, Sang Kil Cha, Alexandre Rebert, Edward J Schwartz, Mav- erick Woo, and David Brumley. 2014. Automatic exploit generation.Commun. ACM57, 2 (2014), 74–84
2014
-
[7]
Masudul Hasan Masud Bhuiyan, Adithya Srinivas Parthasarathy, Nikos Vasilakis, Michael Pradel, and Cristian-Alexandru Staicu. 2023. SecBench. js: An executable security benchmark suite for server-side JavaScript. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1059–1070
2023
-
[9]
Tiago Brito, Mafalda Ferreira, Miguel Monteiro, Pedro Lopes, Miguel Barros, José Fragoso Santos, and Nuno Santos. 2023. Study of javascript static analysis tools for vulnerability detection in node. js packages.IEEE Transactions on Reliability72, 4 (2023), 1324–1339
2023
-
[10]
Darion Cassel, Nuno Sabino, Min-Chien Hsu, Ruben Martins, and Limin Jia. 2025. NODEMEDIC-FINE: Automatic Detection and Exploit Synthesis for Node. js Vulnerabilities. InProceedings of the 2025 Network and Distributed System Security Symposium (NDSS’25). doi, Vol. 10
2025
-
[11]
Darion Cassel, Wai Tuck Wong, and Limin Jia. 2023. Nodemedic: End-to-end analysis of node. js vulnerabilities with provenance graphs. In2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P). IEEE, 1101–1127
2023
-
[12]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Brian Chess and Gary McGraw. 2004. Static analysis for security.IEEE security & privacy2, 6 (2004), 76–79
2004
-
[14]
Edmund Clarke, Orna Grumberg, Somesh Jha, Yuan Lu, and Helmut Veith. 2003. Counterexample-guided abstraction refinement for symbolic model checking. Journal of the ACM (JACM)50, 5 (2003), 752–794
2003
-
[15]
Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: An efficient SMT solver. In International conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 337–340
2008
-
[16]
Alexandre Decan, Tom Mens, and Eleni Constantinou. 2018. On the impact of security vulnerabilities in the npm package dependency network. InProceedings of the 15th international conference on mining software repositories. 181–191
2018
-
[17]
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. 2024. {PentestGPT}: Evaluating and harnessing large language models for automated penetration testing. In33rd USENIX Security Symposium (USENIX Security 24). 847–864
2024
-
[18]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineer- ing: Survey and open problems. In2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 31–53
2023
-
[19]
Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan. 2023. Automated repair of programs from large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 13 Ronghao Ni, Mihai Christodorescu, and Limin Jia 1469–1481
2023
-
[20]
Chongzhou Fang, Ning Miao, Shaurya Srivastav, Jialin Liu, Ruoyu Zhang, Ruijie Fang, Ryan Tsang, Najmeh Nazari, Han Wang, Houman Homayoun, et al. 2024. Large language models for code analysis: Do {LLMs} really do their job?. In 33rd USENIX Security Symposium (USENIX Security 24). 829–846
2024
- [21]
-
[22]
Mafalda Ferreira, Miguel Monteiro, Tiago Brito, Miguel E Coimbra, Nuno Santos, Limin Jia, and José Fragoso Santos. 2024. Efficient static vulnerability analysis for javascript with multiversion dependency graphs.Proceedings of the ACM on Programming Languages8, PLDI (2024), 417–441
2024
- [23]
-
[24]
Zhiyong Guo, Mingqing Kang, VN Venkatakrishnan, Rigel Gjomemo, and Yinzhi Cao. 2024. ReactAppScan: Mining React Application Vulnerabilities via Compo- nent Graph. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 585–599
2024
- [25]
- [26]
- [27]
-
[28]
Zihao Jin, Shuo Chen, Yang Chen, Haixin Duan, Jianjun Chen, and Jianping Wu. 2023. A Security Study about Electron Applications and a Programming Methodology to Tame DOM Functionalities.. InNDSS
2023
-
[29]
Mingqing Kang, Yichao Xu, Song Li, Rigel Gjomemo, Jianwei Hou, VN Venkatakr- ishnan, and Yinzhi Cao. 2023. Scaling javascript abstract interpretation to detect and exploit node. js taint-style vulnerability. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 1059–1076
2023
-
[30]
Hee Yeon Kim, Ji Hoon Kim, Ho Kyun Oh, Beom Jin Lee, Si Woo Mun, Jeong Hoon Shin, and Kyounggon Kim. 2022. DAPP: automatic detection and analysis of prototype pollution vulnerability in Node. js modules.International Journal of Information Security21, 1 (2022), 1–23
2022
-
[31]
Raula Gaikovina Kula, Daniel M German, Ali Ouni, Takashi Ishio, and Katsuro Inoue. 2018. Do developers update their library dependencies? An empirical study on the impact of security advisories on library migration.Empirical Software Engineering23, 1 (2018), 384–417
2018
-
[32]
Carl E Landwehr, Alan R Bull, John P McDermott, and William S Choi. 1994. A taxonomy of computer program security flaws.ACM Computing Surveys (CSUR) 26, 3 (1994), 211–254
1994
-
[33]
Tan Khang Le, Saba Alimadadi, and Steven Y Ko. 2024. A study of vulnerabil- ity repair in javascript programs with large language models. InCompanion Proceedings of the ACM Web Conference 2024. 666–669
2024
- [34]
-
[35]
Jie Lin and David Mohaisen. 2025. From large to mammoth: A comparative evaluation of large language models in vulnerability detection. InProceedings of the 2025 Network and Distributed System Security Symposium (NDSS)
2025
-
[36]
Filipe Marques, Mafalda Ferreira, André Nascimento, Miguel E Coimbra, Nuno Santos, Limin Jia, and José Fragoso Santos. 2025. Automated Exploit Generation for Node. js Packages.Proceedings of the ACM on Programming Languages9, PLDI (2025), 1341–1366
2025
-
[37]
Ruijie Meng, Martin Mirchev, Marcel Böhme, and Abhik Roychoudhury. 2024. Large language model guided protocol fuzzing. InProceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS), Vol. 2024
2024
- [38]
-
[39]
Yu Nong, Haoran Yang, Long Cheng, Hongxin Hu, and Haipeng Cai. 2025. {APPATCH}: Automated adaptive prompting large language models for {Real- World} software vulnerability patching. In34th USENIX Security Symposium (USENIX Security 25). 4481–4500
2025
-
[40]
Christoforos Ntantogian, Panagiotis Bountakas, Dimitris Antonaropoulos, Con- stantinos Patsakis, and Christos Xenakis. 2021. NodeXP: NOde. js server-side JavaScript injection vulnerability DEtection and eXPloitation.Journal of Infor- mation Security and Applications58 (2021), 102752
2021
-
[41]
Marc Ohm, Henrik Plate, Arnold Sykosch, and Michael Meier. 2020. Backstabber’s knife collection: A review of open source software supply chain attacks. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. Springer, 23–43
2020
-
[42]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2025. Asleep at the keyboard? assessing the security of github copilot’s code contributions.Commun. ACM68, 2 (2025), 96–105
2025
-
[43]
Marco Pistoia, Satish Chandra, Stephen J Fink, and Eran Yahav. 2007. A survey of static analysis methods for identifying security vulnerabilities in software systems.IBM systems journal46, 2 (2007), 265–288
2007
- [44]
-
[45]
Koushik Sen, Swaroop Kalasapur, Tasneem Brutch, and Simon Gibbs. 2013. Jalangi: A selective record-replay and dynamic analysis framework for JavaScript. InProceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering. 488–498
2013
-
[46]
Xiangmin Shen, Lingzhi Wang, Zhenyuan Li, Yan Chen, Wencheng Zhao, Dawei Sun, Jiashui Wang, and Wei Ruan. 2025. Pentestagent: Incorporating llm agents to automated penetration testing. InProceedings of the 20th ACM Asia Conference on Computer and Communications Security. 375–391
2025
-
[47]
Ze Sheng, Zhicheng Chen, Shuning Gu, Heqing Huang, Guofei Gu, and Jeff Huang. 2025. Llms in software security: A survey of vulnerability detection techniques and insights.Comput. Surveys58, 5 (2025), 1–35
2025
- [48]
-
[49]
Chao Wang, Ronny Ko, Yue Zhang, Yuqing Yang, and Zhiqiang Lin. 2023. Taint- mini: Detecting flow of sensitive data in mini-programs with static taint analysis. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 932–944
2023
-
[50]
Dawei Wang, Geng Zhou, Li Chen, Dan Li, and Yukai Miao. 2024. Prophetfuzz: Fully automated prediction and fuzzing of high-risk option combinations with only documentation via large language model. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 735–749
2024
-
[51]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review arXiv 2024
- [52]
-
[53]
HanXiang Xu, ShenAo Wang, Ningke Li, Kailong Wang, Yanjie Zhao, Kai Chen, Ting Yu, Yang Liu, and HaoYu Wang. 2024. Large language models for cyber se- curity: A systematic literature review.ACM Transactions on Software Engineering and Methodology(2024)
2024
-
[54]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[55]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[56]
Zidong Zhang, Qinsheng Hou, Lingyun Ying, Wenrui Diao, Yacong Gu, Rui Li, Shanqing Guo, and Haixin Duan. 2024. Minicat: Understanding and detecting cross-page request forgery vulnerabilities in mini-programs. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 525–539
2024
-
[57]
Xiaogang Zhu, Wei Zhou, Qing-Long Han, Wanlun Ma, Sheng Wen, and Yang Xiang. 2025. When software security meets large language models: A survey. IEEE/CAA Journal of Automatica Sinica12, 2 (2025), 317–334
2025
- [58]
-
[59]
]child_process['\
Markus Zimmermann, Cristian-Alexandru Staicu, Cam Tenny, and Michael Pradel. 2019. Small world with high risks: A study of security threats in the npm ecosystem. In28th USENIX Security symposium (USENIX security 19). 995–1010. 14 Taint-Style Vulnerability Detection and Confirmation for Node.js Packages Using LLM Agent Reasoning Appendix A Regular Expressi...
2019
-
[60]
Start by getting the file tree or listing files to understand the structure↩→
-
[61]
Search for patterns related to <VULN_TYPE>
-
[62]
Read suspicious files to analyze the code
-
[63]
Identify exact locations (file + line number) of vulnerabilities↩→
-
[64]
Determine which public APIs can reach these vulnerabilities↩→
-
[65]
You can call this multiple times as you discover items
Call submit_findings(findings=[...]) with structured arguments (NO JSON STRINGS). You can call this multiple times as you discover items. ↩→ ↩→
-
[66]
optional
When you are completely done adding findings, call finish(summary="...optional...") to end the run. ↩→ ↩→ FINDINGS FORMAT (submit_findings arguments): - findings: [ { "vuln_type": "<VULN_TYPE>", "file": "relative/path/to/file.js", "line": 42, "description": "Brief description", "evidence": "Code snippet showing the issue",↩→ "reachable_apis": ["api1", "ap...
-
[67]
Read the code at the reported location
-
[68]
Trace data flow to see if user input can reach the vulnerable sink↩→
-
[69]
Check for any input validation or sanitization
-
[70]
Determine if the vulnerability is actually exploitable↩→
-
[71]
Detailed explanation with evidence
Submit your verdict with detailed reasoning IMPORTANT - LIBRARY/PACKAGE ATTACK SURFACE: - When analyzing npm packages/libraries, EXPORTED functions (exports.*, module.exports) are the attack surface ↩→ ↩→ - If a vulnerable function is exported (even with no callers in the codebase), it IS reachable by external code ↩→ ↩→ - Focus on: Can user-controlled in...
-
[72]
Identify the entry point (URL, function, API)
-
[73]
Determine parameter names and how to provide them
-
[74]
Understand required format/structure of the payload↩→
-
[75]
Identify any validation to bypass
-
[76]
Detailed natural language description of exploitation requirements
Define success criteria for the exploit CONSTRAINTS FORMAT (submit_constraints arguments): - constraints: "Detailed natural language description of exploitation requirements" (REQUIRED) ↩→ ↩→ - entry_point: "How to reach the vulnerability" - parameters: ["param1", "param2"] - payload_format: "Required format for the payload" Be specific and actionable - t...
-
[77]
Read the vulnerable code to understand it
-
[78]
Craft exploit code that imports the module: const mod = require('./index');↩→
-
[79]
↩→ ↩→ ↩→ ↩→
Execute the exploit using execute_javascript - Only if you truly need a background service (e.g., start a server), use start_persistent_process, inspect with check_persistent_process, and always call kill_persistent_process when finished. ↩→ ↩→ ↩→ ↩→
-
[80]
Verify success (check file creation, output, etc.)↩→
-
[81]
If import fails, check the exact filename and try again↩→
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.