Recognition: unknown
From Scene to Object: Text-Guided Dual-Gaze Prediction
Pith reviewed 2026-05-10 00:58 UTC · model grok-4.3
The pith
A new dual-branch VLM framework predicts driver attention at the object level using text guidance rather than scene-level heatmaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
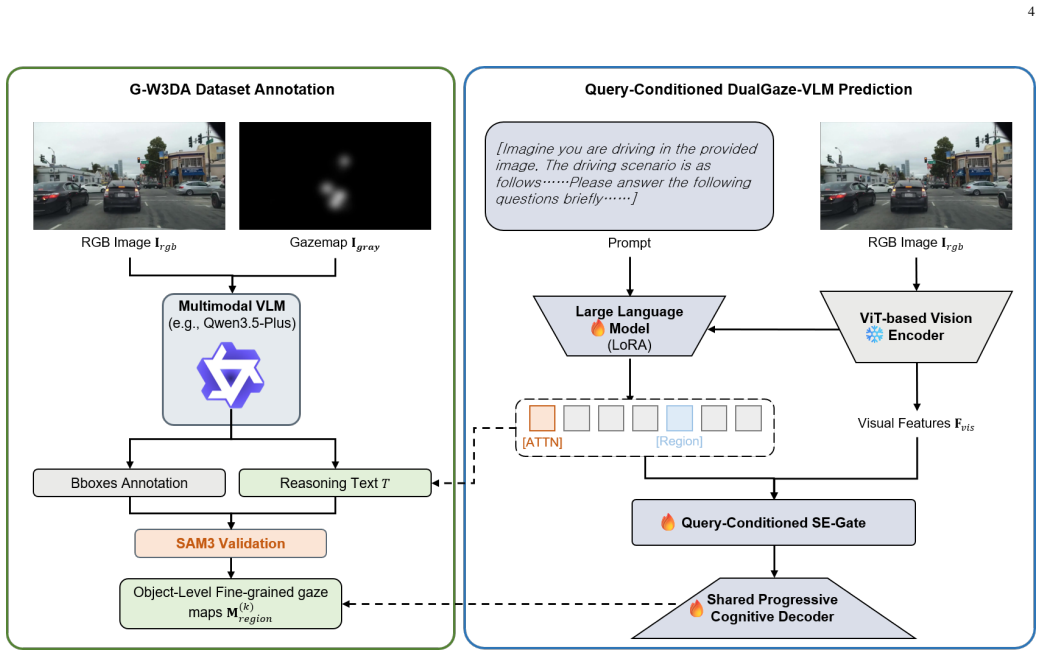
The paper claims that integrating a multimodal LLM with SAM3 under cross-validation creates reliable object-level ground truth masks from scene-level data, and that a dual-branch architecture extracting hidden states from semantic queries and applying a Condition-Aware SE-Gate for feature modulation enables precise intent-driven spatial anchoring, yielding up to 17.8 percent gains in similarity metrics on the W3DA benchmark and 88.22 percent authenticity in human visual Turing tests.
What carries the argument
The Condition-Aware SE-Gate, which takes semantic query hidden states to dynamically modulate visual features for intent-driven object anchoring.
If this is right
- Object-level gaze data enables VLMs to perform semantic reasoning without text-vision decoupling.
- The dual-branch design supports precise anchoring of attention to specific objects in safety-critical driving scenes.
- Generated heatmaps pass human authenticity checks at high rates, indicating they capture rational cognitive priors.
- The data construction pipeline can be applied to convert existing scene-level datasets into object-level ones.
- Improved metrics in safety scenarios suggest better support for human-like decision making in autonomous driving.
Where Pith is reading between the lines
- The approach could generalize to other text-conditioned vision tasks where scene-level labels currently limit model precision.
- Object-level attention maps might serve as more interpretable priors for downstream planning modules in robotics.
- If the data pipeline proves robust, it could reduce reliance on expensive manual object annotations in attention research.
- Testing the same architecture on non-driving gaze datasets would reveal whether the dual-branch mechanism is domain-specific.
Load-bearing premise
That multimodal LLMs plus SAM3 under cross-validation can generate accurate object-level masks that remove annotation hallucinations and serve as trustworthy training targets.
What would settle it
A new driver attention dataset with independently verified object-level masks where DualGaze-VLM fails to exceed prior scene-level models in spatial alignment metrics.
Figures







read the original abstract
Interpretable driver attention prediction is crucial for human-like autonomous driving. However, existing datasets provide only scene-level global gaze rather than fine-grained object-level annotations, inherently failing to support text-grounded cognitive modeling. Consequently, while Vision-Language Models (VLMs) hold great potential for semantic reasoning, this critical data limitations leads to severe text-vision decoupling and visual-bias hallucinations. To break this bottleneck and achieve precise object-level attention prediction, this paper proposes a novel dual-branch gaze prediction framework, establishing a complete paradigm from data construction to model architecture. First, we construct G-W3DA, a object-level driver attention dataset. By integrating a multimodal large language model with the Segment Anything Model 3 (SAM3), we decouple macroscopic heatmaps into object-level masks under rigorous cross-validation, fundamentally eliminating annotation hallucinations. Building upon this high-quality data foundation, we propose the DualGaze-VLM architecture. This architecture extracts the hidden states of semantic queries and dynamically modulates visual features via a Condition-Aware SE-Gate, achieving intent-driven precise spatial anchoring. Extensive experiments on the W3DA benchmark demonstrate that DualGaze-VLM consistently surpasses existing state-of-the-art (SOTA) models in spatial alignment metrics, notably achieving up to a 17.8% improvement in Similarity (SIM) under safety-critical scenarios. Furthermore, a visual Turing test reveals that the attention heatmaps generated by DualGaze-VLM are perceived as authentic by 88.22% of human evaluators, proving its capability to generate rational cognitive priors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address limitations in scene-level driver gaze datasets by constructing G-W3DA, an object-level attention dataset via MLLM + SAM3 integration under cross-validation to eliminate hallucinations, and introduces DualGaze-VLM, a dual-branch VLM architecture using semantic query states and a Condition-Aware SE-Gate for text-guided object-level prediction. It reports up to 17.8% SIM improvement over SOTA on W3DA and 88.22% human authenticity in a visual Turing test.
Significance. If the object-level masks prove accurate and the gains hold with proper controls, the work could meaningfully advance text-grounded, interpretable attention modeling for autonomous driving by shifting from global heatmaps to object-centric cognitive priors, with the Turing test providing useful human validation.
major comments (2)
- [§3 (Dataset Construction, implied)] §3 (Dataset Construction, implied): The assertion that MLLM + SAM3 under 'rigorous cross-validation' 'fundamentally eliminat[es] annotation hallucinations' to yield reliable object-level masks for G-W3DA is load-bearing for all downstream claims, yet no quantitative validation (IoU, precision, recall, or inter-annotator agreement vs. human ground truth) or failure-case analysis is referenced. Without these, residual semantic errors could explain the reported 17.8% SIM gain and 88.22% Turing-test result rather than the proposed architecture.
- [Experimental section (implied)] Experimental section (implied): The abstract states that DualGaze-VLM 'consistently surpasses existing state-of-the-art models' with a specific 17.8% SIM improvement under safety-critical scenarios, but provides no information on the exact baselines, dataset splits, number of runs, error bars, or statistical significance tests. This absence prevents assessment of whether the central performance claim is robust.
minor comments (1)
- [Abstract] Abstract: 'this critical data limitations leads' contains a subject-verb agreement error and should read 'this critical data limitation leads'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below, agreeing that additional quantitative details are needed to strengthen the claims. We will incorporate the suggested revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: The assertion that MLLM + SAM3 under 'rigorous cross-validation' 'fundamentally eliminat[es] annotation hallucinations' to yield reliable object-level masks for G-W3DA is load-bearing for all downstream claims, yet no quantitative validation (IoU, precision, recall, or inter-annotator agreement vs. human ground truth) or failure-case analysis is referenced. Without these, residual semantic errors could explain the reported 17.8% SIM gain and 88.22% Turing-test result rather than the proposed architecture.
Authors: We agree that quantitative validation metrics are essential to substantiate the reliability of G-W3DA. While Section 3 describes the cross-validation procedure with MLLM and SAM3 to detect and correct hallucinations, we did not report numerical results such as IoU, precision, recall, or inter-annotator agreement against human annotations, nor a dedicated failure-case analysis. This omission weakens the load-bearing claim. In the revision, we will add a new subsection (3.3) presenting these metrics computed on a held-out human-annotated subset, along with examples of detected hallucinations and corrections. We expect these additions to confirm that residual errors do not account for the performance gains. revision: yes
-
Referee: The abstract states that DualGaze-VLM 'consistently surpasses existing state-of-the-art models' with a specific 17.8% SIM improvement under safety-critical scenarios, but provides no information on the exact baselines, dataset splits, number of runs, error bars, or statistical significance tests. This absence prevents assessment of whether the central performance claim is robust.
Authors: The experimental section (Section 4) specifies the W3DA benchmark, the safety-critical scenario subset, and the compared SOTA baselines (including their original implementations). However, we acknowledge the absence of explicit details on the number of runs, error bars, and statistical tests, which limits assessment of robustness. We will revise Section 4.2 and the abstract to include: (i) the precise train/test splits, (ii) mean and standard deviation over 5 independent runs, and (iii) p-values from paired t-tests against the strongest baseline. These changes will make the 17.8% SIM improvement claim fully verifiable. revision: yes
Circularity Check
No circularity; empirical claims rest on novel dataset and architecture
full rationale
The paper introduces G-W3DA via MLLM+SAM3 integration with cross-validation for object-level masks, then DualGaze-VLM with semantic query hidden states and Condition-Aware SE-Gate modulation. Performance is reported via experiments (17.8% SIM gain, 88.22% Turing test) on W3DA benchmark. No equations, derivations, or predictions appear that reduce by construction to fitted inputs or self-citations. Central claims derive from new data construction and model design rather than self-referential loops, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hammerdrive: A task- aware driving visual attention model,
P. V . Amadori, T. Fischer, and Y . Demiris, “Hammerdrive: A task- aware driving visual attention model,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 5573–5585, 2021
2021
-
[2]
Dada-2000: Can driving accident be predicted by driver attentionƒ analyzed by a benchmark,
J. Fang, D. Yan, J. Qiao, J. Xue, H. Wang, and S. Li, “Dada-2000: Can driving accident be predicted by driver attentionƒ analyzed by a benchmark,” in2019 IEEE Intelligent Transportation Systems Confer- ence (ITSC). IEEE, 2019, pp. 4303–4309
2000
-
[3]
Predicting driver attention in critical situations,
Y . Xia, D. Zhang, J. Kim, K. Nakayama, K. Zipser, and D. Whitney, “Predicting driver attention in critical situations,” inAsian conference on computer vision. Springer, 2018, pp. 658–674
2018
-
[4]
Dr (eye) ve: a dataset for attention-based tasks with applications to autonomous and assisted driving,
S. Alletto, A. Palazzi, F. Solera, S. Calderara, and R. Cucchiara, “Dr (eye) ve: a dataset for attention-based tasks with applications to autonomous and assisted driving,” inProceedings of the ieee conference on computer vision and pattern recognition workshops, 2016, pp. 54–60
2016
-
[5]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
F. Zhu, R. Wang, S. Nie, X. Zhang, C. Wu, J. Hu, J. Zhou, J. Chen, Y . Lin, J.-R. Wenet al., “Llada 1.5: Variance-reduced preference optimization for large language diffusion models,”arXiv preprint arXiv:2505.19223, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment,
K. Renz, L. Chen, E. Arani, and O. Sinavski, “Simlingo: Vision-only closed-loop autonomous driving with language-action alignment,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 11 993–12 003
2025
-
[8]
A deep multi-level network for saliency prediction,
M. Cornia, L. Baraldi, G. Serra, and R. Cucchiara, “A deep multi-level network for saliency prediction,” in2016 23rd International Conference on Pattern Recognition (ICPR). IEEE, 2016, pp. 3488–3493. 13
2016
-
[9]
Where does the driver look? top- down-based saliency detection in a traffic driving environment,
T. Deng, K. Yang, Y . Li, and H. Yan, “Where does the driver look? top- down-based saliency detection in a traffic driving environment,”IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 7, pp. 2051–2062, 2016
2051
-
[10]
Predicting the driver’s focus of attention: The dr (eye) ve project,
A. Palazzi, D. Abati, F. Solera, R. Cucchiaraet al., “Predicting the driver’s focus of attention: The dr (eye) ve project,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 7, pp. 1720– 1733, 2018
2018
-
[11]
Medirl: Predicting the visual attention of drivers via maximum entropy deep inverse reinforcement learning,
S. Baee, E. Pakdamanian, I. Kim, L. Feng, V . Ordonez, and L. Barnes, “Medirl: Predicting the visual attention of drivers via maximum entropy deep inverse reinforcement learning,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 178–13 188
2021
-
[12]
Scout+: Towards practical task-driven drivers’ gaze prediction,
I. Kotseruba and J. K. Tsotsos, “Scout+: Towards practical task-driven drivers’ gaze prediction,” in2024 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2024, pp. 1927–1932
2024
-
[13]
Fblnet: Feedback loop network for driver attention prediction,
Y . Chen, Z. Nan, and T. Xiang, “Fblnet: Feedback loop network for driver attention prediction,” inProceedings of the IEEE/CVF interna- tional conference on computer vision, 2023, pp. 13 371–13 380
2023
-
[14]
Behavior- aware knowledge-embedded model for driver attention prediction,
Y . Zhou, C. Gou, Z. Guo, Y . Cheng, and H. J. Chang, “Behavior- aware knowledge-embedded model for driver attention prediction,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[15]
Unsupervised self-driving attention prediction via uncertainty mining and knowledge embedding,
P. Zhu, M. Qi, X. Li, W. Li, and H. Ma, “Unsupervised self-driving attention prediction via uncertainty mining and knowledge embedding,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 8558–8568
2023
-
[16]
Salm 2: An extremely lightweight saliency mamba model for real-time cognitive awareness of driver attention,
C. Zhao, W. Mu, X. Zhou, W. Liu, F. Yan, and T. Deng, “Salm 2: An extremely lightweight saliency mamba model for real-time cognitive awareness of driver attention,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 2, 2025, pp. 1647–1655
2025
-
[18]
arXiv preprint arXiv:2512.24331 (2025) 4
W. Wei, Z. Luo, L. Feng, and V . E. Liong, “Spatial-aware vision lan- guage model for autonomous driving,”arXiv preprint arXiv:2512.24331, 2025
-
[20]
How do drivers allocate their potential attention? driving fixation prediction via convolu- tional neural networks,
T. Deng, H. Yan, L. Qin, T. Ngo, and B. Manjunath, “How do drivers allocate their potential attention? driving fixation prediction via convolu- tional neural networks,”IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 5, pp. 2146–2154, 2019
2019
-
[21]
Maad: A model and dataset for
D. Gopinath, G. Rosman, S. Stent, K. Terahata, L. Fletcher, B. Argall, and J. Leonard, “Maad: A model and dataset for” attended awareness” in driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3426–3436
2021
-
[22]
Gaze360: Physically unconstrained gaze estimation in the wild,
P. Kellnhofer, A. Recasens, S. Stent, W. Matusik, and A. Torralba, “Gaze360: Physically unconstrained gaze estimation in the wild,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6912–6921
2019
-
[23]
Do low birth weight infants not see eyes? face recognition in infancy,
M. Yamamoto, Y . Konishi, I. Kato, K. Koyano, S. Nakamura, T. Nishida, and T. Kusaka, “Do low birth weight infants not see eyes? face recognition in infancy,”Brain and Development, vol. 43, no. 2, pp. 186– 191, 2021
2021
-
[24]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132–7141
2018
-
[25]
Learning to predict where humans look,
T. Judd, K. Ehinger, F. Durand, and A. Torralba, “Learning to predict where humans look,” in2009 IEEE 12th International Conference on Computer Vision, 2009, pp. 2106–2113
2009
-
[26]
Analysis of scores, datasets, and models in visual saliency prediction,
A. Borji, H. R. Tavakoli, D. N. Sihite, and L. Itti, “Analysis of scores, datasets, and models in visual saliency prediction,” in2013 IEEE International Conference on Computer Vision, 2013, pp. 921–928
2013
-
[27]
A model of saliency-based visual at- tention for rapid scene analysis,
L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual at- tention for rapid scene analysis,”IEEE Transactions on pattern analysis and machine intelligence, vol. 20, no. 11, pp. 1254–1259, 1998
1998
-
[28]
Exploiting the gbvs for saliency aware gaze heatmaps,
D. Geisler, D. Weber, N. Castner, and E. Kasneci, “Exploiting the gbvs for saliency aware gaze heatmaps,” inACM Symposium on Eye Tracking Research and Applications, 2020, pp. 1–5
2020
-
[29]
Deep gaze i: Boosting saliency prediction with feature maps trained on imagenet,
M. K ¨ummerer, L. Theis, and M. Bethge, “Deep gaze i: Boosting saliency prediction with feature maps trained on imagenet,”arXiv preprint arXiv:1411.1045, 2014
-
[30]
Deepgaze iie: Calibrated prediction in and out-of-domain for state-of-the-art saliency modeling,
A. Linardos, M. K ¨ummerer, O. Press, and M. Bethge, “Deepgaze iie: Calibrated prediction in and out-of-domain for state-of-the-art saliency modeling,” inProceedings of the ieee/cvf international conference on computer vision, 2021, pp. 12 919–12 928
2021
-
[31]
Visual saliency prediction using a mixture of deep neural networks,
S. F. Dodge and L. J. Karam, “Visual saliency prediction using a mixture of deep neural networks,”IEEE Transactions on Image Processing, vol. 27, no. 8, pp. 4080–4090, 2018
2018
-
[32]
Fbnet: Feedback-recursive cnn for saliency detection,
G. Ding, N. ˙Imamo˘glu, A. Caglayan, M. Murakawa, and R. Nakamura, “Fbnet: Feedback-recursive cnn for saliency detection,” in2021 17th International Conference on Machine Vision and Applications (MVA). IEEE, 2021, pp. 1–5
2021
-
[33]
A convnet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 976–11 986
2022
-
[34]
Erfnet: Effi- cient residual factorized convnet for real-time semantic segmentation,
E. Romera, J. M. Alvarez, L. M. Bergasa, and R. Arroyo, “Erfnet: Effi- cient residual factorized convnet for real-time semantic segmentation,” IEEE Transactions on Intelligent Transportation Systems, vol. 19, no. 1, pp. 263–272, 2017
2017
-
[35]
Gazexplain: Learning to predict natu- ral language explanations of visual scanpaths,
X. Chen, M. Jiang, and Q. Zhao, “Gazexplain: Learning to predict natu- ral language explanations of visual scanpaths,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 314–333
2024
-
[36]
Where, what, why: Towards explainable driver attention prediction,
Y . Zhou, J. Tang, X. Xiao, Y . Lin, L. Liu, Z. Guo, H. Fei, X. Xia, and C. Gou, “Where, what, why: Towards explainable driver attention prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2675–2685
2025
-
[37]
Fsdam: Few- shot driving attention modeling via vision-language coupling,
K. Hamid, C. Cui, K. A. Akbar, Z. Wang, and N. Liang, “Fsdam: Few- shot driving attention modeling via vision-language coupling,”arXiv preprint arXiv:2511.12708, 2025
-
[38]
A. M. Turing,Computing Machinery and Intelligence. Dordrecht: Springer Netherlands, 2009, pp. 23–65. [Online]. Available: https: //doi.org/10.1007/978-1-4020-6710-5 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.