Recognition: unknown
Hybrid Policy Distillation for LLMs
Pith reviewed 2026-05-10 00:38 UTC · model grok-4.3
The pith
Hybrid Policy Distillation merges forward and reverse KL divergences with mixed sampling to improve knowledge transfer in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We break down existing KD methods and reformulate them as a reweighted log-likelihood objective at the token level. We further propose Hybrid Policy Distillation (HPD), which integrates the complementary advantages of forward and reverse KL to balance mode coverage and mode-seeking, and combines off-policy data with lightweight, approximate on-policy sampling. We validate HPD on long-generation math reasoning as well as short-generation dialogue and code tasks, demonstrating improved optimization stability, computational efficiency, and final performance across diverse model families and scales.
What carries the argument
Hybrid Policy Distillation (HPD), a hybrid objective that blends forward and reverse KL divergences with off-policy plus approximate on-policy data to control mode coverage versus mode-seeking behavior.
If this is right
- Distillation runs become more stable and require fewer gradient steps to reach good performance.
- Smaller models achieve higher accuracy on long-form reasoning and short-form generation with the same teacher signals.
- The unified reweighted log-likelihood view lets researchers swap divergence choices without redesigning the entire training loop.
- Approximate on-policy sampling reduces the need for expensive full-rollout sampling during distillation.
- The same recipe applies across model scales and families without architecture-specific changes.
Where Pith is reading between the lines
- The hybrid objective may generalize to other autoregressive generation settings such as summarization or translation where mode coverage matters.
- Lightweight on-policy approximation could be replaced by even cheaper estimators such as cached teacher logits if the performance gap stays small.
- The token-level reweighting perspective might reveal why some existing distillation recipes succeed or fail on specific data distributions.
- If mixing weights prove robust, HPD could become a default recipe for compressing frontier models into deployable sizes.
Load-bearing premise
A simple linear combination of forward and reverse KL terms can be tuned once and will remain stable and effective across tasks without introducing new optimization problems or demanding heavy per-task retuning.
What would settle it
Run HPD against pure forward-KL and pure reverse-KL baselines on a fixed math-reasoning benchmark using identical hyperparameters and data budgets; if HPD shows no consistent win in final accuracy or training stability, the hybrid claim fails.
Figures
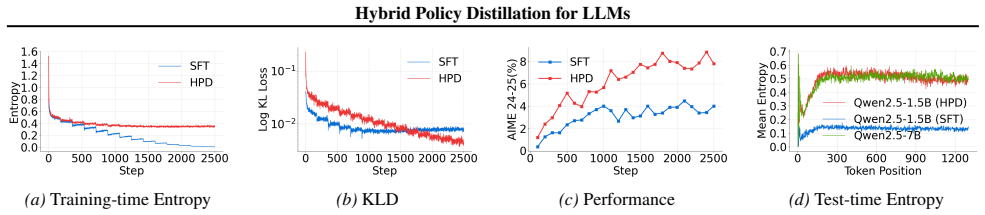


read the original abstract
Knowledge distillation (KD) is a powerful paradigm for compressing large language models (LLMs), whose effectiveness depends on intertwined choices of divergence direction, optimization strategy, and data regime. We break down the design of existing KD methods and present a unified view that establishes connections between them, reformulating KD as a reweighted log-likelihood objective at the token level. We further propose Hybrid Policy Distillation (HPD), which integrates the complementary advantages of forward and reverse KL to balance mode coverage and mode-seeking, and combines off-policy data with lightweight, approximate on-policy sampling. We validate HPD on long-generation math reasoning as well as short-generation dialogue and code tasks, demonstrating improved optimization stability, computational efficiency, and final performance across diverse model families and scales. The code related to this work is available at https://github.com/zwhong714/Hybrid-Policy-Distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a unified reformulation of knowledge distillation for LLMs as a token-level reweighted log-likelihood objective. It proposes Hybrid Policy Distillation (HPD), which combines forward and reverse KL divergences to balance mode coverage and mode-seeking while integrating off-policy data with lightweight approximate on-policy sampling. The approach is validated on long-generation math reasoning tasks as well as short-generation dialogue and code tasks, with claims of improved optimization stability, computational efficiency, and final performance across model families and scales. Code is released at https://github.com/zwhong714/Hybrid-Policy-Distillation.
Significance. If the hybrid objective delivers stable gains without new instabilities or extensive per-task retuning, HPD could offer a practical and more general alternative to existing KD methods for LLMs. The public code release is a clear strength that aids reproducibility and adoption.
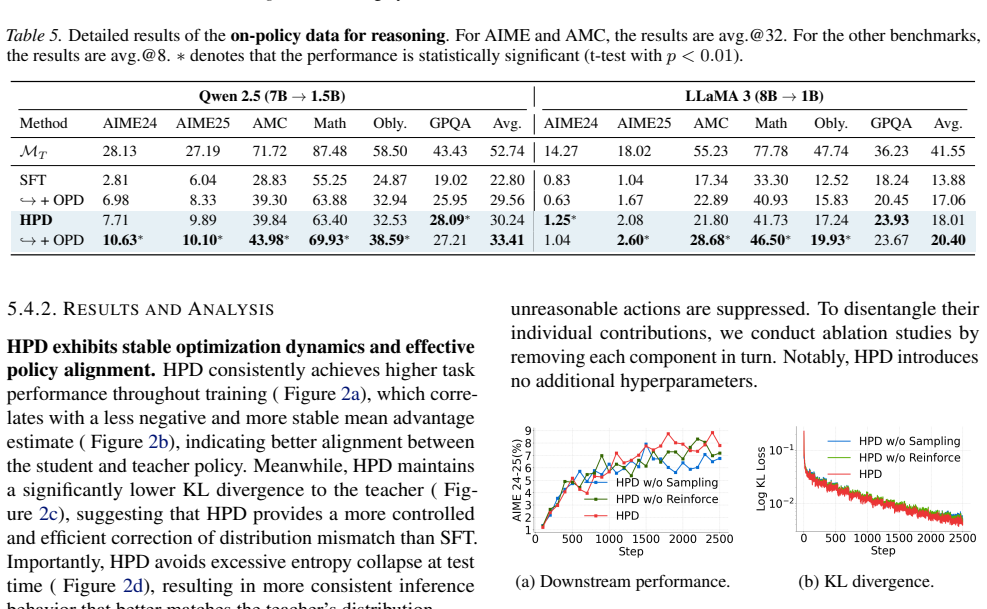
major comments (2)
- [Abstract] Abstract and validation summary: the central performance claims (improved stability, efficiency, and final performance) are asserted without any reported baselines, error bars, statistical tests, or experimental details. This prevents evaluation of whether the hybrid formulation actually achieves the claimed benefits on the math reasoning, dialogue, and code tasks.
- [Hybrid Policy Distillation formulation] Hybrid objective (as introduced in the proposed method): the formulation relies on a free KL mixing coefficient between forward and reverse terms plus an on-policy sampling fraction. No derivation, sensitivity analysis, or cross-task ablation demonstrates robustness of this choice across long-generation vs. short-generation regimes, which directly bears on the claim of balanced advantages without new instabilities or extensive retuning.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation summary: the central performance claims (improved stability, efficiency, and final performance) are asserted without any reported baselines, error bars, statistical tests, or experimental details. This prevents evaluation of whether the hybrid formulation actually achieves the claimed benefits on the math reasoning, dialogue, and code tasks.
Authors: The abstract provides a concise overview of the contributions and high-level results, as is standard. The full manuscript reports detailed comparisons against baselines (including forward KL, reverse KL, and other KD variants), performance metrics, and task-specific results in Section 4 (Experiments) and the appendices, covering GSM8K for long-generation math reasoning as well as dialogue and code benchmarks for short-generation tasks. Error bars from multiple runs and statistical details are included in the main results tables. To directly address the concern, we will revise the abstract to incorporate key quantitative highlights and explicit pointers to the experimental sections. revision: partial
-
Referee: [Hybrid Policy Distillation formulation] Hybrid objective (as introduced in the proposed method): the formulation relies on a free KL mixing coefficient between forward and reverse terms plus an on-policy sampling fraction. No derivation, sensitivity analysis, or cross-task ablation demonstrates robustness of this choice across long-generation vs. short-generation regimes, which directly bears on the claim of balanced advantages without new instabilities or extensive retuning.
Authors: Section 3 derives the hybrid objective from the unified token-level reweighted log-likelihood view, showing how the mixing coefficient combines forward KL (for mode-seeking stability) and reverse KL (for mode coverage) while the on-policy fraction integrates lightweight sampling with off-policy data. The specific coefficient and fraction values are selected based on the theoretical balance and initial validation across regimes. We agree that explicit sensitivity analysis and cross-task ablations would further substantiate the robustness claim. We will add a dedicated subsection with these ablations, evaluating the mixing coefficient and sampling fraction on both long-generation math tasks and short-generation dialogue/code tasks to confirm generalization without extensive per-task retuning. revision: yes
Circularity Check
No circularity: reformulation and hybrid proposal are independent design choices
full rationale
The paper first presents a unified reformulation of existing KD methods as a token-level reweighted log-likelihood objective, then introduces HPD as a new hybrid objective that combines forward and reverse KL with off-policy plus approximate on-policy data. No equations or steps in the abstract or described claims reduce the proposed HPD (or its mixing) to fitted inputs by construction, self-citations, or renamed known results. The mixing weights and sampling approximations are presented as explicit design choices whose benefits are validated empirically across tasks and model scales. This matches the default expectation of a self-contained derivation with no load-bearing reductions.
Axiom & Free-Parameter Ledger
free parameters (2)
- KL mixing coefficient
- on-policy sampling fraction
axioms (1)
- domain assumption Forward KL and reverse KL possess complementary advantages in mode coverage versus mode-seeking.
Forward citations
Cited by 1 Pith paper
-
SOD: Step-wise On-policy Distillation for Small Language Model Agents
SOD reweights on-policy distillation strength step-by-step using divergence to stabilize tool use in small language model agents, yielding up to 20.86% gains and 26.13% on AIME 2025 for a 0.6B model.
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning , year=
Improving Open-Ended Text Generation via Adaptive Decoding , author=. Forty-first International Conference on Machine Learning , year=
-
[2]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
When Speed Kills Stability: Demystifying
Liu, Jiacai and Li, Yingru and Fu, Yuqian and Wang, Jiawei and Liu, Qian and Shen, Yu , year =. When Speed Kills Stability: Demystifying
-
[4]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
Sequence-level knowledge distillation , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[5]
Jongwoo Ko and Tianyi Chen and Sungnyun Kim and Tianyu Ding and Luming Liang and Ilya Zharkov and Se-Young Yun , booktitle=. Disti. 2025 , url=
2025
-
[6]
arXiv preprint arXiv:2505.17508 , year=
On the design of kl-regularized policy gradient algorithms for llm reasoning , author=. arXiv preprint arXiv:2505.17508 , year=
-
[7]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Preventing catastrophic forgetting and distribution mismatch in knowledge distillation via synthetic data , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[8]
The Twelfth International Conference on Learning Representations , year=
WizardCoder: Empowering Code Large Language Models with Evol-Instruct , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Rethinking kullback-leibler divergence in knowledge distillation for large language models , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[10]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[11]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Tinybert: Distilling bert for natural language understanding , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[12]
Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259, 2025
Rl's razor: Why online reinforcement learning forgets less , author=. arXiv preprint arXiv:2509.04259 , year=
-
[13]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[14]
2025 , eprint=
OpenThoughts: Data Recipes for Reasoning Models , author=. 2025 , eprint=
2025
-
[15]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al
A Comedy of Estimators: On KL Regularization in RL Training of LLMs , author=. arXiv preprint arXiv:2512.21852 , year=
-
[16]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. arXiv preprint arXiv:2402.14008 , year=
work page internal anchor Pith review arXiv
-
[17]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review arXiv
-
[18]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[19]
arXiv preprint arXiv:2307.15190 , year=
F-divergence minimization for sequence-level knowledge distillation , author=. arXiv preprint arXiv:2307.15190 , year=
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Policy Gradient Methods for Reinforcement Learning with Function Approximation , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2024 , url =
Learning to reason with LLMs , author=. 2024 , url =
2024
-
[23]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Better Estimation of the Kullback--Leibler Divergence Between Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[26]
2025 , eprint=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. 2025 , eprint=
2025
-
[27]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[28]
The Twelfth International Conference on Learning Representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
MiniLLM: On-Policy Distillation of Large Language Models
Minillm: Knowledge distillation of large language models , author=. arXiv preprint arXiv:2306.08543 , year=
work page internal anchor Pith review arXiv
-
[30]
arXiv preprint arXiv:2305.15717 , year =
The false promise of imitating proprietary llms , author=. arXiv preprint arXiv:2305.15717 , year=
-
[31]
Proceedings of the AAAI conference on artificial intelligence , volume=
Improved knowledge distillation via teacher assistant , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[32]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Reinforcement learning finetunes small subnetworks in large language models, 2025
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models , author=. arXiv preprint arXiv:2505.11711 , year=
-
[34]
Rethinking conventional wisdom in machine learning: From generalization to scaling
Rethinking conventional wisdom in machine learning: From generalization to scaling , author=. arXiv preprint arXiv:2409.15156 , year=
-
[35]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , booktitle =. Is Your Code Generated by Chat. 2023 , url =
2023
-
[37]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review arXiv
-
[38]
LightPAFF: A two-stage distillation framework for pre-training and fine-tuning , author=. arXiv preprint arXiv:2004.12817 , year=
-
[39]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[40]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
DeepSeek-Coder: When the Large Language Model Meets Programming--The Rise of Code Intelligence , author=. arXiv preprint arXiv:2401.14196 , year=
work page internal anchor Pith review arXiv
-
[41]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline , author=. arXiv preprint arXiv:2406.11939 , year=
-
[43]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[44]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[45]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Length-controlled alpacaeval: A simple way to debias automatic evaluators , author=. arXiv preprint arXiv:2404.04475 , year=
work page internal anchor Pith review arXiv
-
[46]
Advances in Neural Information Processing Systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Distillm: Towards streamlined distillation for large language models , author=. arXiv preprint arXiv:2402.03898 , year=
-
[48]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
On the efficacy of knowledge distillation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[49]
arXiv preprint arXiv:2506.12704 , year=
Flexible Realignment of Language Models , author=. arXiv preprint arXiv:2506.12704 , year=
-
[50]
arXiv preprint arXiv:2410.18640 , year=
Weak-to-strong preference optimization: Stealing reward from weak aligned model , author=. arXiv preprint arXiv:2410.18640 , year=
-
[51]
The Fourteenth International Conference on Learning Representations , year=
Proximal Supervised Fine-Tuning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[52]
2025 , url =
Open R1: A fully open reproduction of DeepSeek-R1 , author=. 2025 , url =
2025
-
[53]
2023 , eprint=
UltraFeedback: Boosting Language Models with High-quality Feedback , author=. 2023 , eprint=
2023
-
[54]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[55]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[56]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[57]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[58]
2025 , url=
Guanghui Wang and Zhiyong Yang and Zitai Wang and Shi Wang and Qianqian Xu and Qingming Huang , booktitle=. 2025 , url=
2025
-
[59]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Nature , volume=
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[62]
2020 , howpublished =
Schulman, John , title =. 2020 , howpublished =
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.