Recognition: unknown
Cortex 2.0: Grounding World Models in Real-World Industrial Deployment
Pith reviewed 2026-05-10 00:46 UTC · model grok-4.3
The pith
Cortex 2.0 shifts from reactive vision-language-action control to generating and scoring candidate trajectories in visual latent space before acting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cortex 2.0 generates candidate future trajectories in visual latent space, scores them for expected success and efficiency, then commits only to the highest-scoring candidate. This plan-and-act approach allows the system to outperform state-of-the-art reactive Vision-Language-Action models across single-arm and dual-arm platforms on tasks including pick and place, item and trash sorting, screw sorting, and shoebox unpacking, particularly in unstructured environments with heavy clutter, frequent occlusions, and contact-rich manipulation.
What carries the argument
Generation and scoring of candidate trajectories in visual latent space to select the best plan before acting.
Load-bearing premise
That trajectories scored highly in the visual latent space will translate to successful and efficient real-world executions on physical robots amid changing object arrangements.
What would settle it
A head-to-head test on a fresh industrial task with new object distributions and clutter patterns where the success rate of trajectories chosen by Cortex 2.0 is not higher than that of a reactive baseline.
Figures


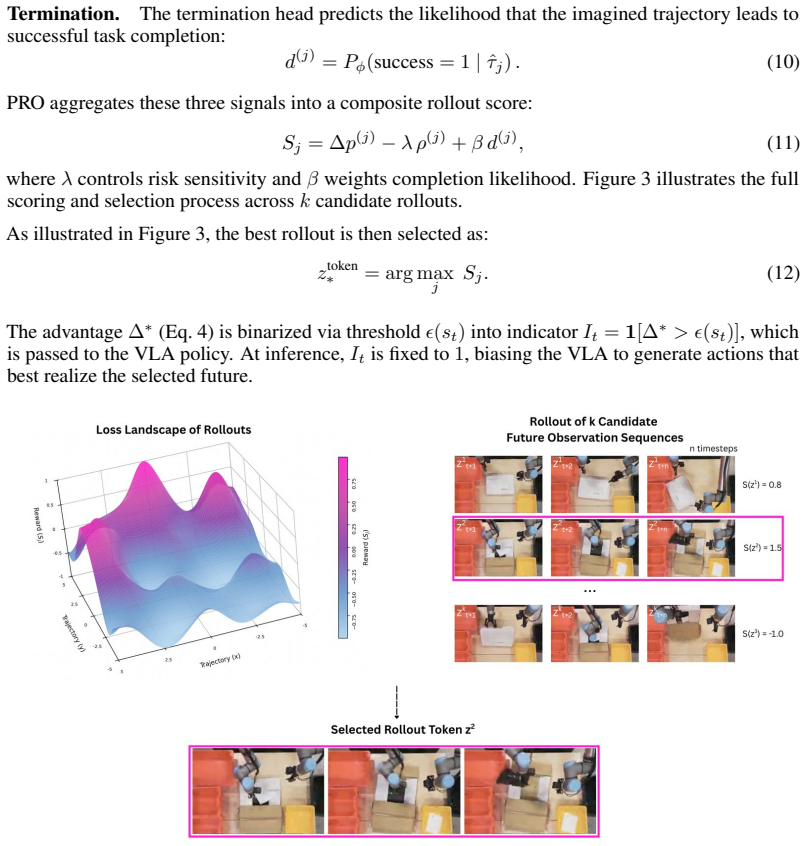










read the original abstract
Industrial robotic manipulation demands reliable long-horizon execution across embodiments, tasks, and changing object distributions. While Vision-Language-Action models have demonstrated strong generalization, they remain fundamentally reactive. By optimizing the next action given the current observation without evaluating potential futures, they are brittle to the compounding failure modes of long-horizon tasks. Cortex 2.0 shifts from reactive control to plan-and-act by generating candidate future trajectories in visual latent space, scoring them for expected success and efficiency, then committing only to the highest-scoring candidate. We evaluate Cortex 2.0 on a single-arm and dual-arm manipulation platform across four tasks of increasing complexity: pick and place, item and trash sorting, screw sorting, and shoebox unpacking. Cortex 2.0 consistently outperforms state-of-the-art Vision-Language-Action baselines, achieving the best results across all tasks. The system remains reliable in unstructured environments characterized by heavy clutter, frequent occlusions, and contact-rich manipulation, where reactive policies fail. These results demonstrate that world-model-based planning can operate reliably in complex industrial environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cortex 2.0, a world-model-based planning system for industrial robotic manipulation. It generates candidate future trajectories in visual latent space, scores them for expected success and efficiency, and executes only the highest-scoring candidate. The authors evaluate the system on single-arm and dual-arm platforms across four tasks of increasing complexity (pick and place, item and trash sorting, screw sorting, shoebox unpacking) and claim consistent outperformance over state-of-the-art Vision-Language-Action baselines, with particular reliability in unstructured environments featuring heavy clutter, frequent occlusions, and contact-rich manipulation.
Significance. If the results hold, the work would demonstrate that latent-space world models can be grounded for reliable long-horizon planning in real industrial settings, providing a concrete alternative to reactive VLA policies that fail under compounding errors. This would strengthen the case for deploying planning-based approaches in contact-rich, partially observable domains.
major comments (2)
- [Evaluation and Experiments (results on the four tasks)] The central claim that Cortex 2.0 'consistently outperforms' VLA baselines and 'remains reliable' in unstructured settings rests on the unverified assumption that trajectories scored in visual latent space accurately rank real-world success and efficiency. In heavy clutter, occlusions, and contact-rich manipulation, visual latents typically discard precise 3D geometry, mass, friction, and partial-observability information; without a dedicated validation (e.g., correlation between latent scores and physical outcomes or failure-mode analysis), outperformance cannot be attributed to the world-model planner.
- [Abstract and Results sections] No quantitative results, error bars, baseline implementations, or scoring-function details are supplied to support the outperformance claim across the four tasks. This absence prevents assessment of whether the reported gains are statistically meaningful or task-specific.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly defined the success and efficiency metrics used for trajectory scoring.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We address each of the major comments point-by-point below, providing clarifications and indicating revisions to the manuscript.
read point-by-point responses
-
Referee: [Evaluation and Experiments (results on the four tasks)] The central claim that Cortex 2.0 'consistently outperforms' VLA baselines and 'remains reliable' in unstructured settings rests on the unverified assumption that trajectories scored in visual latent space accurately rank real-world success and efficiency. In heavy clutter, occlusions, and contact-rich manipulation, visual latents typically discard precise 3D geometry, mass, friction, and partial-observability information; without a dedicated validation (e.g., correlation between latent scores and physical outcomes or failure-mode analysis), outperformance cannot be attributed to the world-model planner.
Authors: We agree that explicit validation of the latent scoring mechanism is important for attributing the observed outperformance to the world-model planner. The current manuscript demonstrates this through end-to-end task performance, but to address the concern directly, we will include in the revised version a quantitative correlation study between the predicted scores and measured success/efficiency metrics, as well as an analysis of failure cases where high-scoring trajectories led to suboptimal outcomes. This will clarify the grounding of the visual latents for the specific industrial tasks. revision: yes
-
Referee: [Abstract and Results sections] No quantitative results, error bars, baseline implementations, or scoring-function details are supplied to support the outperformance claim across the four tasks. This absence prevents assessment of whether the reported gains are statistically meaningful or task-specific.
Authors: The manuscript does present quantitative success rates for Cortex 2.0 and the VLA baselines across the four tasks in the results section. However, we acknowledge that error bars, detailed baseline specifications, and the precise scoring function equations are not fully detailed. We will revise the abstract to include key quantitative highlights, add error bars to the performance tables and figures, specify the baseline implementations (including model versions and training details), and expand the methods section with the complete scoring function formulation. These additions will enable a full statistical evaluation of the results. revision: yes
Circularity Check
No circularity in claimed derivation or predictions
full rationale
The paper presents an empirical robotic system (Cortex 2.0) that generates and scores trajectories in visual latent space before execution. No equations, first-principles derivations, or 'predictions' of new quantities from fitted parameters appear in the provided text. Performance claims rest on experimental comparisons across tasks rather than any self-referential reduction or self-citation chain that would force the result by construction. The central assumption (latent scores predict real-world outcomes) is an empirical hypothesis open to falsification, not a definitional tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A Vision- Language-Action Model with Open-World Generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. RT-1: Robotics Transformer for Real-World Control at Scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[5]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. PaLM-E: An Embodied Multimodal Language Model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Open X- 17 Embodiment: Robotic Learning Datasets and RT-X Models
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open X- 17 Embodiment: Robotic Learning Datasets and RT-X Models. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[7]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets.arXiv preprint arXiv:2109.13396, 2021
work page internal anchor Pith review arXiv 2021
-
[8]
Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 1(2):6, 2023
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning Interactive Real-World Simulators.arXiv preprint arXiv:2310.06114, 1(2):6, 2023
-
[9]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos World Foundation Model Platform for Physical AI.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Octo: An Open-Source Generalist Robot Policy
Oier Mees, Dibya Ghosh, Karl Pertsch, Kevin Black, Homer Rich Walke, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An Open-Source Generalist Robot Policy. InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024, 2024
2024
-
[11]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An Open-Source Vision-Language-Action Model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
MolmoAct: Action Reasoning Models that can Reason in Space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. MolmoAct: Action Reasoning Models That Can Reason in Space.arXiv preprint arXiv:2508.07917, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, and Jiangmiao Pang. F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions.arXiv preprint arXiv:2509.06951, 2025
-
[15]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. FAST: Efficient Action Tokenization for Vision-Language- Action Models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. GR00T N1: An Open Foundation Model for Generalist Humanoid Robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Cortex: Bridging Vision, Language, and Action with Discrete Plans and Tokens
Sereact. Cortex: Bridging Vision, Language, and Action with Discrete Plans and Tokens. Sereact Technical Blog, September 2025. URL https://sereact.ai/posts/ cortex-bridging-vision-language-and-action-with-discrete-plans-and-tokens
2025
-
[18]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[19]
Denoising Diffusion Probabilistic Models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[20]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow Matching for Generative Modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building Normalizing Flows with Stochastic Interpolants. InInternational Conference on Learning Representations, 2023
2023
-
[22]
Boffi, and Eric Vanden-Eijnden
Michael Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic Interpolants: A Unifying Framework for Flows and Diffusions.Journal of Machine Learning Research, 26 (209):1–80, 2025
2025
-
[23]
arXiv preprint arXiv:2602.03310 (2026)
Songming Liu, Bangguo Li, Kai Ma, Lingxuan Wu, Hengkai Tan, Xiao Ouyang, Hang Su, and Jun Zhu. RDT2: Exploring the Scaling Limit of UMI Data Towards Zero-Shot Cross- Embodiment Generalization.arXiv preprint arXiv:2602.03310, 2026
-
[24]
David Ha and Jürgen Schmidhuber. World Models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018. 18
work page internal anchor Pith review arXiv 2018
-
[25]
Deep Visual Foresight for Planning Robot Motion
Chelsea Finn and Sergey Levine. Deep Visual Foresight for Planning Robot Motion. In2017 IEEE International Conference on Robotics and Automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[26]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering Atari with Discrete World Models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review arXiv 2010
-
[27]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering Diverse Domains Through World Models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
IRASim: A Fine-Grained World Model for Robot Manipulation
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. IRASim: A Fine-Grained World Model for Robot Manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9834–9844, 2025
2025
-
[29]
Strengthening Generative Robot Policies through Predictive World Modeling, May 2025
Han Qi et al. Strengthening Generative Robot Policies Through Predictive World Modeling. arXiv preprint arXiv:2502.00622, 2025
-
[30]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Chenhao Li et al. Robotic World Model: A Neural Network Simulator for Robust Policy Optimization in the Real World.arXiv preprint arXiv:2501.10100, 2025
-
[33]
Adelson, and Sergey Levine
Roberto Calandra, Andrew Owens, Dinesh Jayaraman, Justin Lin, Wenzhen Yuan, Jitendra Malik, Edward H. Adelson, and Sergey Levine. More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch.IEEE Robotics and Automation Letters, 2018
2018
-
[34]
Michelle A. Lee, Yuke Zhu, Peter Zachares, Matthew Tan, Krishnan Srinivasan, Silvio Savarese, Li Fei-Fei, Animesh Garg, and Jeannette Bohg. Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks.IEEE Transactions on Robotics, 36 (3):582–596, June 2020. ISSN 1941-0468. doi: 10.1109/TRO.2019.2959445. URL http: //dx.doi....
-
[35]
Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al
Homer Rich Walke, Kevin Black, Tony Z. Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. BridgeData V2: A Dataset for Robot Learning at Scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
2023
-
[36]
DROID: A Large-Scale In-The-Wild Robot Manipu- lation Dataset, 2024
Alexander Khazatsky, Karl Pertsch, and ... DROID: A Large-Scale In-The-Wild Robot Manipu- lation Dataset, 2024
2024
-
[37]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xu Huang, Shu Jiang, et al. AgiBot World Colosseo: A Large-Scale Manipulation Platform for Scalable and Intelligent Embodied Systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Jianlan Luo, Charles Xu, Xinyang Geng, Gilbert Feng, Kuan Fang, Liam Tan, Stefan Schaal, and Sergey Levine. Multistage Cable Routing Through Hierarchical Imitation Learning.IEEE Transactions on Robotics, 40:1476–1491, 2024. ISSN 1941-0468. doi: 10.1109/TRO.2024. 3353075. URLhttp://dx.doi.org/10.1109/TRO.2024.3353075
-
[39]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InRobotics: Science and Systems, 2023
2023
-
[40]
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z. Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better.arXiv preprint arXiv:2505.23705, 2025
-
[41]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots. InRobotics: Science and Systems (RSS), 2024. 19
2024
-
[42]
LeRobot: State-of-the-Art Machine Learning for Real-World Robotics in PyTorch
Remi Cadene, Simon Alibert, Alexander Soare, Quentin Gallouedec, Adil Zouitine, Steven Palma, Pepijn Kooijmans, Michel Aractingi, Mustafa Shukor, Dana Aubakirova, Martino Russi, Francesco Capuano, Caroline Pascale, Jade Choghari, Jess Moss, and Thomas Wolf. LeRobot: State-of-the-Art Machine Learning for Real-World Robotics in PyTorch. https: //github.com/...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.