Recognition: unknown
Dual Causal Inference: Integrating Backdoor Adjustment and Instrumental Variable Learning for Medical VQA
Pith reviewed 2026-05-10 00:02 UTC · model grok-4.3
The pith
A dual causal method combines backdoor adjustment with instrumental variable learning to remove both visible and hidden biases from medical visual question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
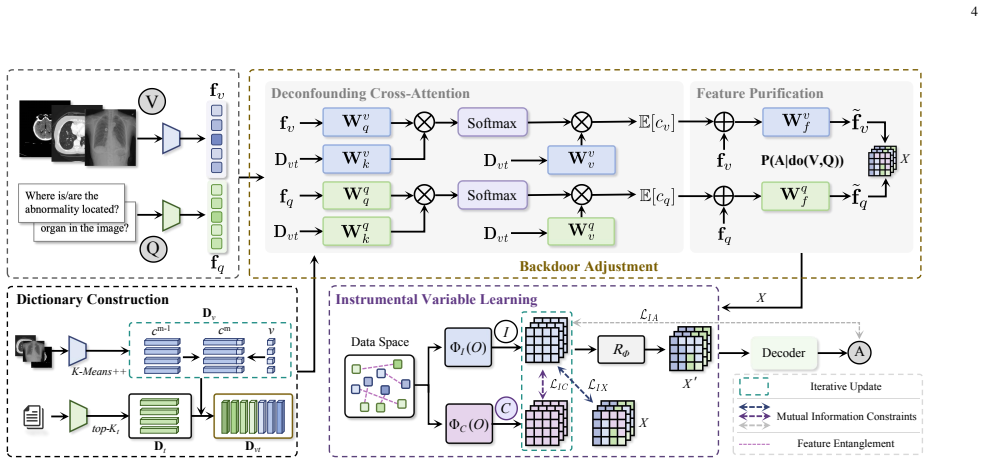
DCI is the first unified architecture that integrates Backdoor Adjustment and Instrumental Variable learning to jointly tackle both observable and unobserved confounders in MedVQA, extracting deconfounded representations that capture genuine causal relationships through a structural causal model and mutual information constraints.
What carries the argument
The structural causal model that applies backdoor adjustment to observable cross-modal biases while learning a valid instrumental variable from a shared latent space under mutual information constraints.
Load-bearing premise
The mutual information constraints are sufficient to produce an instrumental variable that is independent of unobserved confounders while still informative for the multimodal representations.
What would settle it
Evaluation on a dataset where new unobserved confounders are deliberately injected and the mutual information constraints fail to isolate them, resulting in performance no better than non-causal baselines.
Figures


read the original abstract
Medical Visual Question Answering (MedVQA) aims to generate clinically reliable answers conditioned on complex medical images and questions. However, existing methods often overfit to superficial cross-modal correlations, neglecting the intrinsic biases embedded in multimodal medical data. Consequently, models become vulnerable to cross-modal confounding effects, severely hindering their ability to provide trustworthy diagnostic reasoning. To address this limitation, we propose a novel Dual Causal Inference (DCI) framework for MedVQA. To the best of our knowledge, DCI is the first unified architecture that integrates Backdoor Adjustment (BDA) and Instrumental Variable (IV) learning to jointly tackle both observable and unobserved confounders. Specifically, we formulate a Structural Causal Model (SCM) where observable cross-modal biases (e.g., frequent visual and textual co-occurrences) are mitigated via BDA, while unobserved confounders are compensated using an IV learned from a shared latent space. To guarantee the validity of the IV, we design mutual information constraints that maximize its dependence on the fused multimodal representations while minimizing its associations with the unobserved confounders and target answers. Through this dual mechanism, DCI extracts deconfounded representations that capture genuine causal relationships. Extensive experiments on four benchmark datasets, SLAKE, SLAKE-CP, VQA-RAD, and PathVQA, demonstrate that our method consistently outperforms existing approaches, particularly in out-of-distribution (OOD) generalization. Furthermore, qualitative analyses confirm that DCI significantly enhances the interpretability and robustness of cross-modal reasoning by explicitly disentangling true causal effects from spurious cross-modal shortcuts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dual Causal Inference (DCI), a unified framework for Medical Visual Question Answering (MedVQA) that integrates Backdoor Adjustment (BDA) to mitigate observable cross-modal biases and Instrumental Variable (IV) learning to handle unobserved confounders within a Structural Causal Model (SCM). An IV is learned from a shared latent space and regularized via mutual information constraints that aim to maximize dependence on fused multimodal representations while minimizing associations with unobserved confounders and target answers. Experiments on SLAKE, SLAKE-CP, VQA-RAD, and PathVQA report consistent gains over baselines, with emphasis on improved out-of-distribution generalization and interpretability.
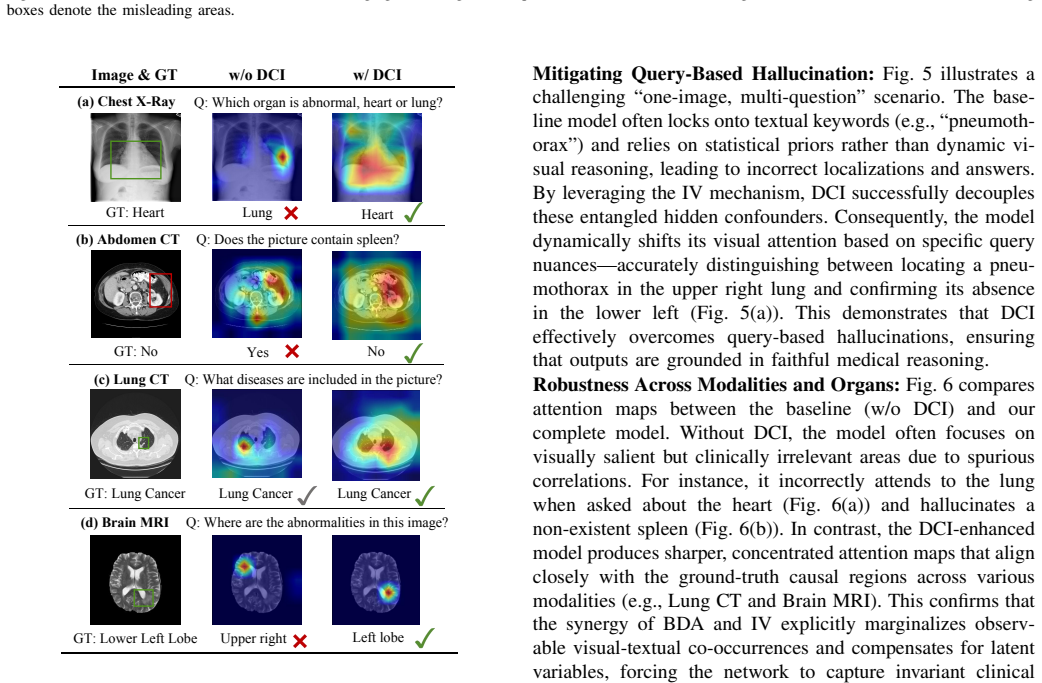
Significance. If the deconfounding claims hold, the work would offer a practical route to more reliable MedVQA systems by explicitly separating causal effects from spurious correlations in multimodal medical data, which could improve robustness in clinical settings where unobserved factors such as imaging artifacts or prior knowledge are common.
major comments (2)
- [Abstract and Methods (IV construction)] Abstract and Methods (IV construction): The mutual information constraints are asserted to guarantee a valid IV satisfying relevance, independence from unobserved confounders, and the exclusion restriction. However, because MI estimation in neural networks is variational and approximate, the manuscript must supply either an identification proof under the SCM or empirical bounds showing that the learned latent satisfies the three IV conditions; without these, the deconfounding guarantee does not necessarily follow from the stated penalties.
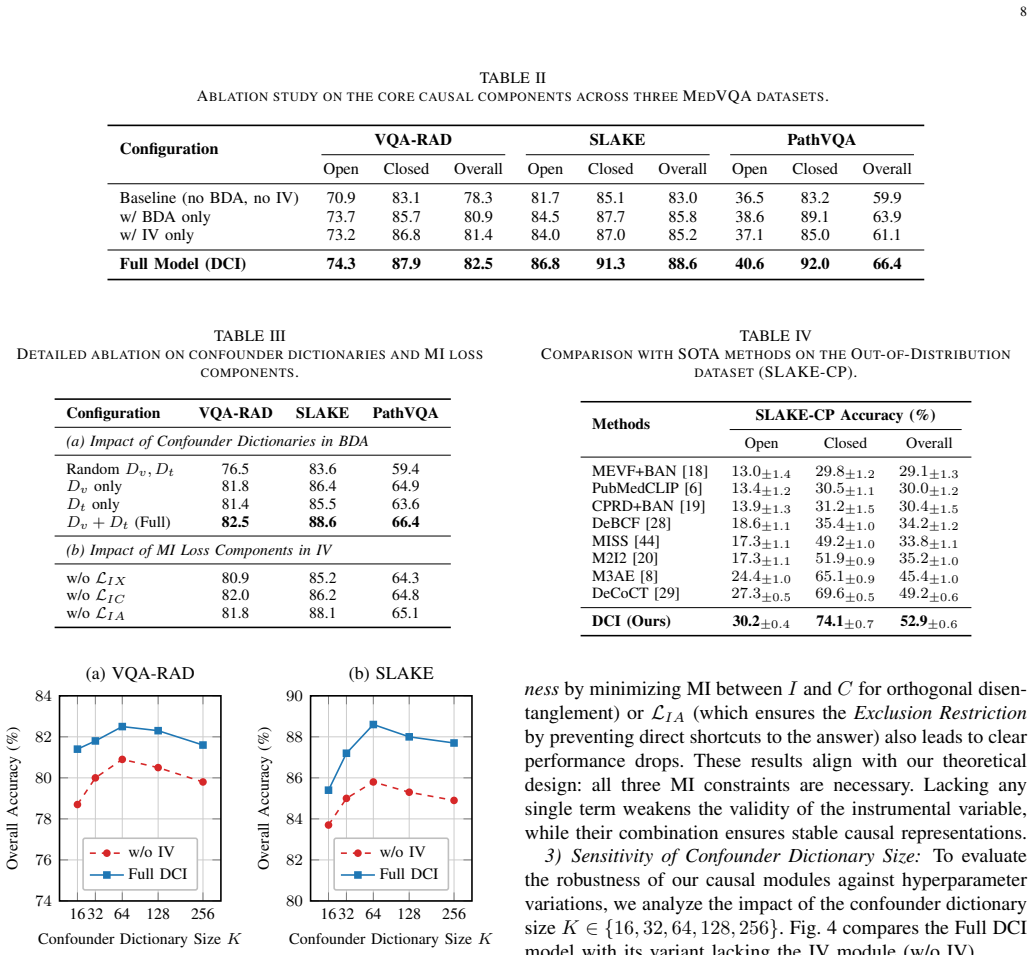
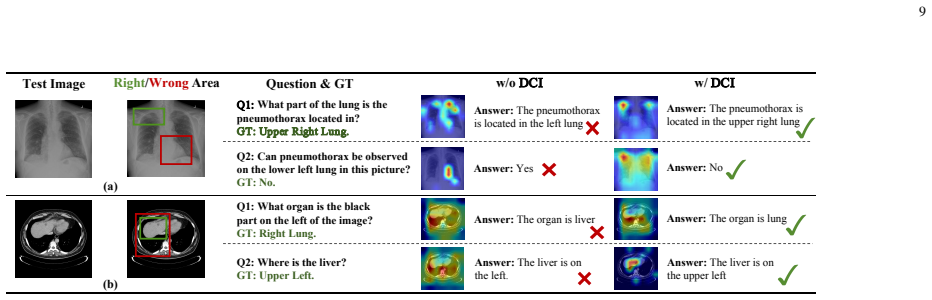
- [Experiments section] Experiments section: While outperformance on four benchmarks including OOD splits is reported, the absence of ablations that isolate the incremental contribution of the BDA module versus the IV module, or of statistical tests comparing against strong multimodal baselines, leaves open the possibility that gains arise from other architectural choices rather than the dual causal mechanism.
minor comments (2)
- [Abstract] The abstract states that DCI is 'the first unified architecture' integrating BDA and IV; a brief citation to the closest prior causal MedVQA works would strengthen this positioning.
- [Methods] Notation for the shared latent space and the precise form of the MI terms (e.g., which estimators are used) should be introduced earlier and used consistently in the methods description.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment point-by-point below, indicating the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract and Methods (IV construction): The mutual information constraints are asserted to guarantee a valid IV satisfying relevance, independence from unobserved confounders, and the exclusion restriction. However, because MI estimation in neural networks is variational and approximate, the manuscript must supply either an identification proof under the SCM or empirical bounds showing that the learned latent satisfies the three IV conditions; without these, the deconfounding guarantee does not necessarily follow from the stated penalties.
Authors: We agree that the variational approximation of mutual information means the constraints provide only an empirical proxy rather than a strict guarantee. In the revised manuscript we will add a new subsection (Methods 3.4) containing (i) a proof sketch under the SCM showing how the three MI penalties encourage relevance, independence from U, and exclusion, and (ii) empirical bounds obtained by reporting the estimated MI values together with sensitivity analyses on the learned latent across all four datasets. These additions will make the deconfounding claim more rigorous. revision: yes
-
Referee: Experiments section: While outperformance on four benchmarks including OOD splits is reported, the absence of ablations that isolate the incremental contribution of the BDA module versus the IV module, or of statistical tests comparing against strong multimodal baselines, leaves open the possibility that gains arise from other architectural choices rather than the dual causal mechanism.
Authors: We concur that component-wise ablations and statistical significance tests are necessary to attribute gains specifically to the dual causal design. In the revised Experiments section we will add (i) three controlled variants—DCI without BDA, DCI without IV, and full DCI—evaluated on SLAKE, SLAKE-CP, VQA-RAD, and PathVQA (including OOD splits), and (ii) paired statistical tests (McNemar’s test and Wilcoxon signed-rank test with p-values) against the strongest multimodal baselines. The new tables will quantify the incremental benefit of each module. revision: yes
Circularity Check
No significant circularity detected in the derivation chain
full rationale
The paper formulates an SCM for MedVQA, applies BDA for observable confounders, and introduces an IV from a shared latent space whose validity is enforced by mutual information constraints that maximize dependence on fused representations while minimizing links to confounders and answers. This design choice produces deconfounded representations as the optimization outcome, but the provided text contains no equations demonstrating that the final causal claims or predictions are identical to the fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing steps. The central architecture is presented as a novel integration with external benchmark validation, rendering the derivation self-contained rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A Structural Causal Model accurately captures the observable and unobserved confounding structure in multimodal medical data.
invented entities (1)
-
Instrumental variable learned from shared latent space
no independent evidence
Forward citations
Cited by 1 Pith paper
-
LiteMedCoT-VL: Parameter-Efficient Adaptation for Medical Visual Question Answering
LiteMedCoT-VL distills chain-of-thought from a 235B model to 2B VLMs via LoRA, reaching 64.9% accuracy on PMC-VQA and beating a 4B zero-shot baseline by 11 points.
Reference graph
Works this paper leans on
-
[1]
Multiscale feature extraction and fusion of image and text in vqa,
S. Lu, Y . Ding, M. Liu, Z. Yin, L. Yin, and W. Zheng, “Multiscale feature extraction and fusion of image and text in vqa,”International Journal of Computational Intelligence Systems, vol. 16, no. 1, p. 54, 2023
2023
-
[2]
From Images to Textual Prompts: Zero-shot Visual Question Answering with Frozen Large Language Models ,
J. Guo, J. Li, D. Li, A. M. Huat Tiong, B. Li, D. Tao, and S. Hoi, “ From Images to Textual Prompts: Zero-shot Visual Question Answering with Frozen Large Language Models ,” inCVPR, 2023, pp. 10 867–10 877
2023
-
[3]
Cross modality bias in visual question answering: A causal view with possible worlds vqa,
A. V osoughi, S. Deng, S. Zhang, Y . Tian, C. Xu, and J. Luo, “Cross modality bias in visual question answering: A causal view with possible worlds vqa,”IEEE TMM, vol. 26, pp. 8609–8624, 2024
2024
-
[4]
Pmc-llama: toward building open-source language models for medicine,
C. Wu, W. Lin, X. Zhang, Y . Zhang, W. Xie, and Y . Wang, “Pmc-llama: toward building open-source language models for medicine,”Journal of the American Medical Informatics Association, vol. 31, no. 9, pp. 1833–1843, 2024
2024
-
[5]
X. Zhang, C. Wu, Z. Zhao, W. Lin, Y . Zhang, Y . Wang, and W. Xie, “Pmc-vqa: Visual instruction tuning for medical visual question answer- ing,”arXiv preprint arXiv:2305.10415, 2023
-
[6]
Pubmedclip: How much does clip benefit visual question answering in the medical domain?
S. Eslami, C. Meinel, and G. De Melo, “Pubmedclip: How much does clip benefit visual question answering in the medical domain?” in Findings of the Association for Computational Linguistics: EACL 2023, 2023, pp. 1151–1163
2023
-
[7]
Masked vision and language pre-training with unimodal and multimodal contrastive losses for medical visual question answering,
P. Li, G. Liu, J. He, Z. Zhao, and S. Zhong, “Masked vision and language pre-training with unimodal and multimodal contrastive losses for medical visual question answering,” inMICCAI. Springer, 2023, pp. 374–383
2023
-
[8]
Multi-modal masked autoencoders for medical vision-and-language pre-training,
Z. Chen, Y . Du, J. Hu, Y . Liu, G. Li, X. Wan, and T.-H. Chang, “Multi-modal masked autoencoders for medical vision-and-language pre-training,” inMICCAI. Springer, 2022, pp. 679–689
2022
-
[9]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day,
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,”NeurIPS, vol. 36, pp. 28 541– 28 564, 2023
2023
-
[10]
Chest x-ray image classification: a causal perspective,
W. Nie, C. Zhang, D. Song, Y . Bai, K. Xie, and A.-A. Liu, “Chest x-ray image classification: a causal perspective,” inMICCAI. Springer, 2023, pp. 25–35
2023
-
[11]
Cross-modal causal relational reasoning for event-level visual question answering,
Y . Liu, G. Li, and L. Lin, “Cross-modal causal relational reasoning for event-level visual question answering,”IEEE TPAMI, vol. 45, pp. 11 624–11 641, 2022
2022
-
[12]
Mitigating inherent bias of answer heuristic based frameworks in knowledge-based visual question answering,
J. Lu, M. Jiang, J. Kong, D. Zhuang, and M. Lu, “Mitigating inherent bias of answer heuristic based frameworks in knowledge-based visual question answering,”IEEE TMM, vol. 28, pp. 1744–1755, 2026
2026
-
[13]
Enhanced reasoning via multimodal llms and collaborative inference,
Z. Wen, M. Tan, Y . Wang, Q. Wu, and Q. Wu, “Enhanced reasoning via multimodal llms and collaborative inference,”IEEE TMM, vol. 27, pp. 7166–7178, 2025
2025
-
[14]
Causal inference in statistics: An overview,
J. Pearl, “Causal inference in statistics: An overview,”Statistics Surveys, vol. 3, pp. 96–146, 2009
2009
-
[15]
Causal attention for vision- language tasks,
X. Yang, H. Zhang, G. Qi, and J. Cai, “Causal attention for vision- language tasks,” inCVPR, 2021, pp. 9847–9857
2021
-
[16]
Open-ended medical visual question answering through prefix tuning of language models,
T. Van Sonsbeek, M. M. Derakhshani, I. Najdenkoska, C. G. Snoek, and M. Worring, “Open-ended medical visual question answering through prefix tuning of language models,” inMICCAI. Springer, 2023, pp. 726–736
2023
-
[17]
Pmc-clip: Contrastive language-image pre-training using biomedical documents,
W. Lin, Z. Zhao, X. Zhang, C. Wu, Y . Zhang, Y . Wang, and W. Xie, “Pmc-clip: Contrastive language-image pre-training using biomedical documents,” inMICCAI. Springer, 2023, pp. 525–536
2023
-
[18]
Overcoming data limitation in medical visual question answering,
B. D. Nguyen, T.-T. Do, B. X. Nguyen, T. Do, E. Tjiputra, and Q. D. Tran, “Overcoming data limitation in medical visual question answering,” inMICCAI. Springer, 2019, pp. 522–530
2019
-
[19]
Contrastive pre-training and representation distillation for medical visual question answering based on radiology images,
B. Liu, L.-M. Zhan, and X.-M. Wu, “Contrastive pre-training and representation distillation for medical visual question answering based on radiology images,” inMICCAI. Springer, 2021, pp. 210–220
2021
-
[20]
Self-supervised vision- language pretraining for medial visual question answering,
P. Li, G. Liu, L. Tan, J. Liao, and S. Zhong, “Self-supervised vision- language pretraining for medial visual question answering,” in2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI). IEEE, 2023, pp. 1–5
2023
-
[21]
Amam: an attention-based multimodal alignment model for medical visual question answering,
H. Pan, S. He, K. Zhang, B. Qu, C. Chen, and K. Shi, “Amam: an attention-based multimodal alignment model for medical visual question answering,”Knowledge-Based Systems, vol. 255, p. 109763, 2022
2022
-
[22]
A dual-attention learning network with word and sentence embedding for medical visual question answering,
X. Huang and H. Gong, “A dual-attention learning network with word and sentence embedding for medical visual question answering,”IEEE Transactions on Medical Imaging, vol. 43, no. 2, pp. 832–845, 2023
2023
-
[23]
Localized questions in medical visual question answering,
S. Tascon-Morales, P. M ´arquez-Neila, and R. Sznitman, “Localized questions in medical visual question answering,” inMICCAI. Springer, 2023, pp. 361–370
2023
-
[24]
Motor: Multimodal optimal transport via grounded retrieval in medical visual question answering,
M. A. Shaaban, T. J. Saleem, V . R. K. Papineni, and M. Yaqub, “Motor: Multimodal optimal transport via grounded retrieval in medical visual question answering,” inMICCAI. Springer, 2025, pp. 459–469
2025
-
[25]
Causal interven- tion for weakly-supervised semantic segmentation,
D. Zhang, H. Zhang, J. Tang, X.-S. Hua, and Q. Sun, “Causal interven- tion for weakly-supervised semantic segmentation,” inNeurIPS, vol. 33. Curran Associates, Inc., 2020, pp. 655–666
2020
-
[26]
Multi-label chest x-ray image classification via category disentangled causal learning,
Q. Li, M. Liu, R. Chang, W. Nie, S. Bai, and A. Liu, “Multi-label chest x-ray image classification via category disentangled causal learning,” IEEE Transactions on Artificial Intelligence, 2025
2025
-
[27]
Cross- modal causal representation learning for radiology report generation,
W. Chen, Y . Liu, C. Wang, J. Zhu, G. Li, C.-L. Liu, and L. Lin, “Cross- modal causal representation learning for radiology report generation,” IEEE TIP, vol. 34, pp. 2970–2985, 2025
2025
-
[28]
Debiasing medical visual question answering via counterfactual training,
C. Zhan, P. Peng, H. Zhang, H. Sun, C. Shang, T. Chen, H. Wang, G. Wang, and H. Wang, “Debiasing medical visual question answering via counterfactual training,” inMICCAI. Springer, 2023, pp. 382–393
2023
-
[29]
Eliminating language bias for medical visual question answering with counterfactual contrastive training,
X. Wan, Q. Teng, J. Chen, Y . Lu, D. Yuan, and Z. Liu, “Eliminating language bias for medical visual question answering with counterfactual contrastive training,” inMICCAI. Springer, 2025, pp. 194–204
2025
-
[30]
Counterfactual causal-effect intervention for interpretable medical visual question answering,
L. Cai, H. Fang, N. Xu, and B. Ren, “Counterfactual causal-effect intervention for interpretable medical visual question answering,”IEEE Transactions on Medical Imaging, vol. 43, no. 12, pp. 4430–4441, 2024
2024
-
[31]
Cimb- mvqa: Causal intervention on modality-specific biases for medical visual question answering,
B. Liu, L. Liu, J. Ding, X. Yang, W. Peng, and L. Liu, “Cimb- mvqa: Causal intervention on modality-specific biases for medical visual question answering,”Medical Image Analysis, p. 103850, 2025
2025
-
[32]
Instrumental variable learning for chest x-ray classification,
W. Nie, C. Zhang, D. Song, Y . Bai, K. Xie, and A. Liu, “Instrumental variable learning for chest x-ray classification,” in2023 IEEE Interna- tional Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2023, pp. 4506–4512
2023
-
[33]
Instrumental variable-driven domain generalization with unobserved confounders,
J. Yuan, X. Ma, R. Xiong, M. Gong, X. Liu, F. Wu, L. Lin, and K. Kuang, “Instrumental variable-driven domain generalization with unobserved confounders,”ACM Transactions on Knowledge Discovery from Data, vol. 17, no. 8, pp. 1–21, 2023
2023
-
[34]
Instrumental variables in causal inference and machine learning: A survey,
A. Wu, K. Kuang, R. Xiong, and F. Wu, “Instrumental variables in causal inference and machine learning: A survey,”ACM Computing Surveys, vol. 57, no. 11, pp. 1–36, 2025
2025
-
[35]
Unbiased visual question answering by leveraging instrumental variable,
Y . Pan, J. Liu, L. Jin, and Z. Li, “Unbiased visual question answering by leveraging instrumental variable,”IEEE TMM, vol. 26, pp. 6648–6662, 2024
2024
-
[36]
Long-tailed classification by keeping the good and removing the bad momentum causal effect,
K. Tang, J. Huang, and H. Zhang, “Long-tailed classification by keeping the good and removing the bad momentum causal effect,” inNeurIPS, vol. 33. Curran Associates, Inc., 2020, pp. 1513–1524
2020
-
[37]
An introduction to causal inference,
J. Pearl, “An introduction to causal inference,”The international journal of biostatistics, vol. 6, no. 2, p. 7, 2010
2010
-
[38]
Show, attend and tell: Neural image caption generation with visual attention,
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y . Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” inICML. PMLR, 2015, pp. 2048–2057
2015
-
[39]
Club: A contrastive log-ratio upper bound of mutual information,
P. Cheng, W. Hao, S. Dai, J. Liu, Z. Gan, and L. Carin, “Club: A contrastive log-ratio upper bound of mutual information,” inICML. PMLR, 2020, pp. 1779–1788
2020
-
[40]
A dataset of clinically generated visual questions and answers about radiology images,
J. J. Lau, S. Gayen, A. Ben Abacha, and D. Demner-Fushman, “A dataset of clinically generated visual questions and answers about radiology images,”Scientific data, vol. 5, no. 1, pp. 1–10, 2018
2018
-
[41]
Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering,
B. Liu, L.-M. Zhan, L. Xu, L. Ma, Y . Yang, and X.-M. Wu, “Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering,” in2021 IEEE 18th international symposium on biomedical imaging (ISBI). IEEE, 2021, pp. 1650–1654
2021
-
[42]
X. He, Y . Zhang, L. Mou, E. Xing, and P. Xie, “Pathvqa: 30000+ questions for medical visual question answering,”arXiv preprint arXiv:2003.10286, 2020
-
[43]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
Miss: A generative pre-training and fine-tuning approach for med-vqa,
J. Chen, D. Yang, Y . Jiang, Y . Lei, and L. Zhang, “Miss: A generative pre-training and fine-tuning approach for med-vqa,” inInternational Conference on Artificial Neural Networks. Springer, 2024, pp. 299–313
2024
-
[45]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inICCV, 2017, pp. 618–626
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.