Recognition: 2 theorem links
· Lean TheoremLiteMedCoT-VL: Parameter-Efficient Adaptation for Medical Visual Question Answering
Pith reviewed 2026-05-12 03:35 UTC · model grok-4.3
The pith
A 2B vision-language model with distilled chain-of-thought reasoning outperforms larger models on medical visual question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LiteMedCoT-VL is a pipeline that transfers chain-of-thought reasoning from a 235B teacher model to 2B student models by fine-tuning on explanation-enriched data using LoRA. All inference happens without image captions to simulate direct clinical interpretation. On the PMC-VQA benchmark the method reaches 64.9 percent accuracy, 11 points above the zero-shot 4B baseline and ahead of other published systems. This shows that reasoning distillation lets small models match or beat larger ones on medical tasks.
What carries the argument
The chain-of-thought distillation pipeline that enriches data with teacher explanations and applies parameter-efficient adaptation to the student model.
Load-bearing premise
The chain-of-thought explanations from the large teacher model are accurate enough and transfer cleanly to the small model during fine-tuning without adding errors or missing key medical insights.
What would settle it
The adapted 2B model would fail to show improved accuracy or would produce inconsistent reasoning chains compared to the teacher on held-out medical images.
Figures




read the original abstract
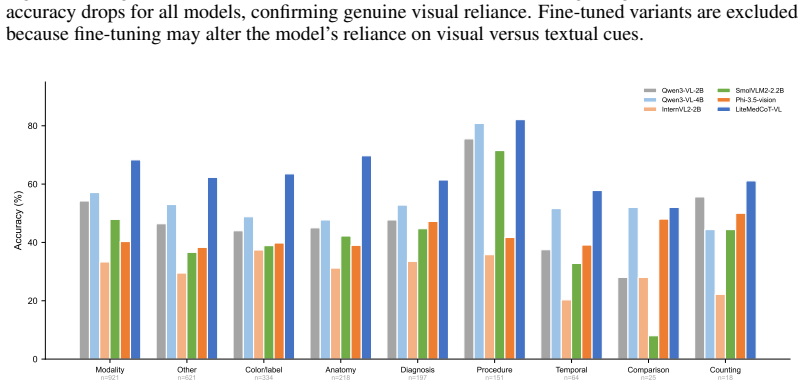
The reasoning gap between large and compact vision-language models (VLMs) limits the deployment of medical AI on portable clinical devices. Compact VLMs of 2--4B parameters can run on resource-constrained hardware but lack the multi-step reasoning capacity needed for interpretable clinical decision support. Existing knowledge distillation methods transfer answers without the reasoning process behind them. Medical visual question answering (VQA) serves as a testbed for this problem, as it requires models to integrate visual evidence with clinical knowledge through structured reasoning chains. We introduce LiteMedCoT-VL, a pipeline that transfers chain-of-thought reasoning from a 235B teacher model to 2B student models through LoRA-based fine-tuning on explanation-enriched training data. All inference is conducted without image captions by default, simulating the clinical scenario in which a physician interprets a medical image directly without an accompanying radiology report. On the PMC-VQA benchmark, LiteMedCoT-VL achieves 64.9% accuracy, exceeding the zero-shot Qwen3-VL-4B baseline of 53.9% by 11.0 percentage points and outperforming all published baselines. This result indicates that a 2B model with reasoning distillation can match or exceed models with twice the parameters. Visual grounding analysis shows that the model relies on image content rather than exploiting textual priors. Our code is publicly available at https://anonymous.4open.science/r/LiteMedCoT-VL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiteMedCoT-VL, a pipeline for parameter-efficient adaptation of 2B-parameter vision-language models to medical visual question answering. It distills chain-of-thought reasoning from a 235B teacher model via LoRA fine-tuning on explanation-enriched VQA data, with all inference performed without image captions. On the PMC-VQA benchmark the method reports 64.9% accuracy, an 11-point gain over the zero-shot Qwen3-VL-4B baseline of 53.9% and outperformance of all published baselines. The authors conclude that reasoning distillation enables compact models to match or exceed larger models and release code publicly.
Significance. If the reported gains are shown to stem specifically from CoT transfer rather than standard supervised fine-tuning, the work would be significant for enabling interpretable medical VQA on resource-constrained hardware. The public code release is a clear strength that supports reproducibility and further research.
major comments (2)
- [Experiments] Experiments section: the central claim that the 11pp accuracy lift (64.9% vs. 53.9%) results from chain-of-thought reasoning distillation is not supported by any ablation that compares the full explanation-enriched training set against an otherwise identical LoRA fine-tuning run using only question-answer pairs. Without this control the necessity of the 235B teacher, the CoT component, and the specific pipeline remains unestablished.
- [Methods] Methods section: the manuscript provides no description of the teacher prompt engineering used to generate the CoT explanations, no statistical significance tests on the benchmark results, and no explicit controls or analysis for data leakage between the teacher-generated data and the PMC-VQA test set. These omissions directly affect the reliability of the transfer claim.
minor comments (2)
- [Abstract / Experiments] The abstract and results text should explicitly state the exact number of training examples and the LoRA hyperparameters (rank, alpha, dropout) used in the reported runs.
- [Results] Figure captions and the visual-grounding analysis paragraph would benefit from clearer description of how attention or grounding metrics were computed and what baseline they are compared against.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have reviewed each point carefully and provide the following point-by-point responses. We agree that additional controls and details are needed to strengthen the claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that the 11pp accuracy lift (64.9% vs. 53.9%) results from chain-of-thought reasoning distillation is not supported by any ablation that compares the full explanation-enriched training set against an otherwise identical LoRA fine-tuning run using only question-answer pairs. Without this control the necessity of the 235B teacher, the CoT component, and the specific pipeline remains unestablished.
Authors: We agree that the current experiments do not isolate the contribution of the CoT explanations from standard supervised fine-tuning on QA pairs. In the revised manuscript we will add a direct ablation: an otherwise identical LoRA fine-tuning run on the same 2B model using only question-answer pairs (no explanations). The accuracy difference between this control and the full explanation-enriched run will be reported to substantiate the specific benefit of reasoning distillation. revision: yes
-
Referee: [Methods] Methods section: the manuscript provides no description of the teacher prompt engineering used to generate the CoT explanations, no statistical significance tests on the benchmark results, and no explicit controls or analysis for data leakage between the teacher-generated data and the PMC-VQA test set. These omissions directly affect the reliability of the transfer claim.
Authors: We will expand the Methods section with the exact prompts used to elicit CoT explanations from the 235B teacher. We will also add statistical significance testing (e.g., bootstrap confidence intervals or McNemar’s test) for the reported accuracy gains. For data leakage, we will include an explicit analysis checking for any overlap between the teacher-generated training instances and the PMC-VQA test set, together with a description of the generation protocol that avoids using test data. revision: yes
Circularity Check
No circularity: empirical benchmark results are self-contained
full rationale
The paper describes a LoRA-based distillation pipeline that enriches VQA training data with chain-of-thought explanations from a 235B teacher and reports measured accuracy (64.9%) on the external PMC-VQA benchmark against zero-shot baselines. No equations, parameter fits, or uniqueness theorems are presented; the central claim is an empirical comparison that does not reduce to any input by construction. No self-citations are invoked as load-bearing premises, and the method is described without renaming known results or smuggling ansatzes. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank, alpha, and dropout
axioms (1)
- domain assumption Chain-of-thought explanations generated by the 235B teacher are sufficiently accurate and generalizable to serve as training targets for the student.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LiteMedCoT-VL, a pipeline that transfers chain-of-thought reasoning from a 235B teacher model to 2B student models through LoRA-based fine-tuning on explanation-enriched training data.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On the PMC-VQA benchmark, LiteMedCoT-VL achieves 64.9% accuracy...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S Kevin Zhou, Hayit Greenspan, Christos Davatzikos, James S Duncan, Bram Van Ginneken, Anant Madabhushi, Jerry L Prince, Daniel Rueckert, and Ronald M Summers. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises.Proceedings of the IEEE, 109(5):820–838, 2021
work page 2021
-
[2]
Deep learning models in medical image analysis.Journal of Oral Bio- sciences, 64(3):312–320, 2022
Masayuki Tsuneki. Deep learning models in medical image analysis.Journal of Oral Bio- sciences, 64(3):312–320, 2022
work page 2022
-
[3]
Yuxiao Gao, Yang Jiang, Yanhong Peng, Fujiang Yuan, Xinyue Zhang, and Jianfeng Wang. Medical image segmentation: A comprehensive review of deep learning-based methods.To- mography, 11(5):52, 2025
work page 2025
-
[4]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[5]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun- Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021
work page 2021
-
[6]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625– 5644, 2024
work page 2024
-
[8]
Peng Wang, Wenpeng Lu, Chunlin Lu, Ruoxi Zhou, Min Li, and Libo Qin. Large language model for medical images: A survey of taxonomy, systematic review, and future trends.Big Data Mining and Analytics, 8(2):496, 2025
work page 2025
-
[9]
Visual–language foundation models in medicine.The Visual Computer, 41(4):2953–2972, 2025
Chunyu Liu, Yixiao Jin, Zhouyu Guan, Tingyao Li, Yiming Qin, Bo Qian, Zehua Jiang, Yi- lan Wu, Xiangning Wang, Ying Feng Zheng, et al. Visual–language foundation models in medicine.The Visual Computer, 41(4):2953–2972, 2025
work page 2025
-
[10]
Bin Sheng, Zhouyu Guan, Lee-Ling Lim, Zehua Jiang, Nestoras Mathioudakis, Jiajia Li, Ruhan Liu, Yuqian Bao, Yong Mong Bee, Ya-Xing Wang, et al. Large language models for diabetes care: Potentials and prospects.Science bulletin, 69(5):583–588, 2024
work page 2024
-
[11]
Knowledge distillation: A survey.International journal of computer vision, 129(6):1789–1819, 2021
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey.International journal of computer vision, 129(6):1789–1819, 2021
work page 2021
-
[12]
Amir M Mansourian, Rozhan Ahmadi, Masoud Ghafouri, Amir Mohammad Babaei, Ela- heh Badali Golezani, Zeynab Yasamani Ghamchi, Vida Ramezanian, Alireza Taherian, Kimia Dinashi, Amirali Miri, et al. A comprehensive survey on knowledge distillation.arXiv preprint arXiv:2503.12067, 2025
-
[13]
Lin Fan, Yafei Ou, Zhipeng Deng, Pengyu Dai, Hou Chongxian, Jiale Yan, Yaqian Li, Kai- wen Long, Xun Gong, Masayuki Ikebe, et al. Step-cot: Stepwise visual chain-of-thought for medical visual question answering.arXiv preprint arXiv:2603.13878, 2026
-
[14]
Sonali Sharma, Jin Long, George Shih, Sarah Eid, Christian Bluethgen, Francine L Jacob- son, Emily B Tsai, Ahmed M Alaa, Curtis P Langlotz, Global Radiology Consortium, et al. Chexthought: A global multimodal dataset of clinical chain-of-thought reasoning and visual attention for chest x-ray interpretation.arXiv preprint arXiv:2604.26288, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Improving Medical VQA through Trajectory-Aware Process Supervision
Halil Ibrahim Gulluk and Olivier Gevaert. Improving medical vqa through trajectory-aware process supervision.arXiv preprint arXiv:2605.04064, 2026. 14
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Yuexi Du, Jinglu Wang, Shujie Liu, Nicha C Dvornek, and Yan Lu. Care: Towards clinical ac- countability in multi-modal medical reasoning with an evidence-grounded agentic framework. arXiv preprint arXiv:2603.01607, 2026
-
[17]
Zhongzhen Huang, Linjie Mu, Yakun Zhu, Xiangyu Zhao, Shaoting Zhang, and Xiaofan Zhang. Elicit and enhance: Advancing multimodal reasoning in medical scenarios.arXiv preprint arXiv:2505.23118, 2025
-
[18]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-vqa: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415, 2023
-
[19]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Sandra Jardim, João António, and Carlos Mora. Image thresholding approaches for medi- cal image segmentation-short literature review.Procedia Computer Science, 219:1485–1492, 2023
work page 2023
-
[21]
Mohammad R Salmanpour, Somayeh Sadat Mehrnia, Sajad Jabarzadeh Ghandilu, Zhino Safahi, Sonya Falahati, Shahram Taeb, Ghazal Mousavi, Mehdi Maghsudi, Ahmad Shariftabrizi, Ilker Hacihaliloglu, et al. Handcrafted vs. deep radiomics vs. fusion vs. deep learning: A comprehensive review of machine learning-based cancer outcome prediction in pet and spect imagin...
work page 2026
-
[22]
Chao Chen, Nor Ashidi Mat Isa, and Xin Liu. A review of convolutional neural network based methods for medical image classification.Computers in biology and medicine, 185:109507, 2025
work page 2025
-
[23]
Carina Albuquerque, Roberto Henriques, and Mauro Castelli. Deep learning-based object detection algorithms in medical imaging: Systematic review.Heliyon, 11(1), 2025
work page 2025
-
[24]
Deep convolutional neural networks in medical image analysis: A review.Information, 16(3):195, 2025
Ibomoiye Domor Mienye, Theo G Swart, George Obaido, Matt Jordan, and Philip Ilono. Deep convolutional neural networks in medical image analysis: A review.Information, 16(3):195, 2025
work page 2025
-
[25]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L Yuille, and Yuyin Zhou. Transunet: Transformers make strong encoders for medical image segmentation.arXiv preprint arXiv:2102.04306, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Swin-unet: Unet-like pure transformer for medical image segmentation
Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, and Manning Wang. Swin-unet: Unet-like pure transformer for medical image segmentation. InEuropean conference on computer vision, pages 205–218. Springer, 2022
work page 2022
-
[27]
Transformers in medical image analysis.Intelligent Medicine, 3(1):59–78, 2023
Kelei He, Chen Gan, Zhuoyuan Li, Islem Rekik, Zihao Yin, Wen Ji, Yang Gao, Qian Wang, Junfeng Zhang, and Dinggang Shen. Transformers in medical image analysis.Intelligent Medicine, 3(1):59–78, 2023
work page 2023
-
[28]
Generative models in medical visual question answering: A survey.Applied Sciences, 15(6):2983, 2025
Wenjie Dong, Shuhao Shen, Yuqiang Han, Tao Tan, Jian Wu, and Hongxia Xu. Generative models in medical visual question answering: A survey.Applied Sciences, 15(6):2983, 2025
work page 2025
-
[29]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[30]
Flava: A foundational language and vision alignment model
Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 15638–15650, 2022
work page 2022
-
[31]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36: 28541–28564, 2023. 15
work page 2023
-
[32]
Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021
work page 2021
-
[33]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286, 2020
work page internal anchor Pith review arXiv 2003
-
[34]
Asma Ben Abacha, Mourad Sarrouti, Dina Demner-Fushman, Sadid A Hasan, and Henning Müller. Overview of the vqa-med task at imageclef 2021: Visual question answering and generation in the medical domain. InProceedings of the CLEF 2021 Conference and Labs of the Evaluation Forum-working notes. 21-24 September 2021, 2021
work page 2021
-
[35]
Knowledge distillation based on transformed teacher matching
Kaixiang Zheng and En-Hui Yang. Knowledge distillation based on transformed teacher matching.arXiv preprint arXiv:2402.11148, 2024
-
[36]
Student-friendly knowledge distillation
Mengyang Yuan, Bo Lang, and Fengnan Quan. Student-friendly knowledge distillation. Knowledge-Based Systems, 296:111915, 2024
work page 2024
-
[37]
Muyu Wang, Shiyu Fan, Yichen Li, Binyu Gao, Zhongrang Xie, and Hui Chen. Robust multi- modal fusion architecture for medical data with knowledge distillation.Computer methods and programs in biomedicine, 260:108568, 2025
work page 2025
-
[38]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianfeng Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101, 2024
work page 2024
-
[40]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299, 2025
work page internal anchor Pith review arXiv 2025
-
[41]
Comt: Chain-of-medical-thought reduces hallucination in medical report gener- ation
Yue Jiang, Jiawei Chen, Dingkang Yang, Mingcheng Li, Shunli Wang, Tong Wu, Ke Li, and Lihua Zhang. Comt: Chain-of-medical-thought reduces hallucination in medical report gener- ation. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[42]
Large language models are reasoning teach- ers
Namgyu Ho, Laura Schmid, and Se-Young Yun. Large language models are reasoning teach- ers. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 14852–14882, 2023
work page 2023
-
[43]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in lan- guage models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[45]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
work page 2019
-
[46]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021. 16
work page 2021
-
[47]
Unipelt: A unified framework for parameter-efficient language model tuning
Yuning Mao, Lambert Mathias, Rui Hou, Amjad Almahairi, Hao Ma, Jiawei Han, Scott Yih, and Madian Khabsa. Unipelt: A unified framework for parameter-efficient language model tuning. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6253–6264, 2022
work page 2022
-
[48]
A survey on lora of large language models.Frontiers of Computer Science, 19(7):197605, 2025
Yuren Mao, Yuhang Ge, Yijiang Fan, Wenyi Xu, Yu Mi, Zhonghao Hu, and Yunjun Gao. A survey on lora of large language models.Frontiers of Computer Science, 19(7):197605, 2025
work page 2025
-
[49]
Egor V olkov, Vadim Sechin, and Alexey Averkin. Visual-language model fine-tuning via lora for structed medical reports generating for lung x-ray skans. In2025 XXVIII International Conference on Soft Computing and Measurements (SCM), pages 438–442. IEEE, 2025
work page 2025
-
[50]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
Mohammad Asadi, Jack W O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Fardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
-
[51]
MedVR: Annotation-Free Medical Visual Reasoning via Agentic Reinforcement Learning
Zheng Jiang, Heng Guo, Chengyu Fang, Changchen Xiao, Xinyang Hu, Lifeng Sun, and Min- feng Xu. Medvr: Annotation-free medical visual reasoning via agentic reinforcement learning. arXiv preprint arXiv:2604.08203, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
arXiv preprint arXiv:2510.10052 (2025)
Kaitao Chen, Shaohao Rui, Yankai Jiang, Jiamin Wu, Qihao Zheng, Chunfeng Song, Xiaosong Wang, Mu Zhou, and Mianxin Liu. Think twice to see more: Iterative visual reasoning in medical vlms.arXiv preprint arXiv:2510.10052, 2025
-
[53]
Zibo Xu, Qiang Li, Ke Lu, Jin Wang, Weizhi Nie, and Yuting Su. Dual causal inference: Integrating backdoor adjustment and instrumental variable learning for medical vqa.arXiv preprint arXiv:2604.20306, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Anas Zafar, Leema Krishna Murali, and Ashish Vashist. Beyond accuracy: Evaluating visual grounding in multimodal medical reasoning.arXiv preprint arXiv:2603.03437, 2026
-
[55]
Hallucination benchmark in medical visual question answering.arXiv preprint arXiv:2401.05827, 2024
Jinge Wu, Yunsoo Kim, and Honghan Wu. Hallucination benchmark in medical visual question answering.arXiv preprint arXiv:2401.05827, 2024
-
[56]
Liangyu Chen, James Burgess, Jeffrey J Nirschl, Orr Zohar, and Serena Yeung-Levy. The impact of image resolution on biomedical multimodal large language models.arXiv preprint arXiv:2510.18304, 2025
-
[57]
arXiv preprint arXiv:2505.16964 (2025)
Suhao Yu, Haojin Wang, Juncheng Wu, Luyang Luo, Jingshen Wang, Cihang Xie, Pranav Rajpurkar, Carl Yang, Yang Yang, Kang Wang, et al. Medframeqa: A multi-image medical vqa benchmark for clinical reasoning.arXiv preprint arXiv:2505.16964, 2025
-
[58]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. Openflamingo: An open- source framework for training large autoregressive vision-language models.arXiv preprint arXiv:2308.01390, 2023
work page internal anchor Pith review arXiv 2023
-
[59]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5 (1):180251, 2018. 17
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.